论文笔记之:Deep Reinforcement Learning with Double Q-learning
Deep Reinforcement Learning with Double Q-learning
Google DeepMind
Abstract
主流的 Q-learning 算法过高的估计在特定条件下的动作值。实际上,之前是不知道是否这样的过高估计是 common的,是否对性能有害,以及是否能从主体上进行组织。本文就回答了上述的问题,特别的,本文指出最近的 DQN 算法,的确存在在玩 Atari 2600 时会 suffer from substantial overestimations。本文提出了 double Q-learning algorithm 可以很好的降低观测到的 overestimation 问题,而且在几个游戏上取得了更好的效果。
Introduction
强化学习的目标是对序列决策问题能够学习到一个好的策略,通过优化一个累计未来奖励信号。Q-learning 是最著名的 RL 学习算法之一,但是由于其在预测动作值的时候包含一个最大化的步骤,所以导致会出现过高的预测值,使得学习到不实际的高动作值。
在之前的工作中,将 overestimation 的问题归咎于 不够灵活的函数估计 以及 noise。本文统一了这些观点,并且表明 当动作值预测的不准确的时候,就会出现 overestimation,而不管估计误差的来源。当然,在学习的过程中,出现不准确的值估计也是正常的,这也说明 overestimation 可能比之前所看的情况更加普遍。
如果overestimation 的确出现,那么这个开放的问题的确会影响实际的性能。过于优化的值估计在一个问题中是不必要的,如果所有的值都比相对动作参考要均匀的高被保存了,那么我们就不会相信得到的结果策略会更差了。此外,有时候 optimistic 是一件好事情:optimistic in the face of uncertainty is a well-known exploration technique. 然而,如果当预测并且均匀,不集中在 state上,那么他们可能对结果的策略产生坏的影响。Thrun 等人给出了特定的例子,即:导致次优的策略。
为了测试在实际上是否会出现 overestimation,我们探讨了最近 DQN 算法的性能。关于 DQN 可以参考相关文章,此处不赘述了。可能比较奇怪的是,这种 DQN设置 仍然存在过高的估计动作的 value 这种情况。
作者表明,在 Double Q-learning算法背后的idea,可以很好的和任意的函数估计相结合,包括神经网络,我们利用此构建了新的算法,称: Double DQN。本文算法不但可以产生更加精确的 value estimation,而且在几个游戏上得到了更高的分数。这样表明,在 DQN上的确存在 overestimation 的问题,并且最好将其降低或者说消除。
Background
为了解决序列决策问题,我们学习对每一个动作的最优值的估计,定义为:当采取该动作,并且以后也采用最优的策略时,期望得到的将来奖励的总和。在给定一个策略 $\pi$ 之后,在状态 s下的一个动作 a 的真实值为:
$Q_{\pi}(s, a) = E[R_1 + \gamma R_2 + ... | S_0 =s, A_0 = a, \pi]$,
最优的值就是 $Q_*(s, a) = max_{\pi} Q_{\pi}(s, a)$。一个优化的策略就是从每一个状态下选择最高值动作。
预测最优动作值 可以利用 Q-learning算法。大部分有意思的问题都无法在所有状态下都计算出其动作值。相反,我们学习一个参数化的动作函数 Q(s, a; \theta_t)。在状态St下,采取了动作 $A_t$之后标准的 Q-learning 更新,然后观测到奖励 $R_{t+1}$以及得到转换后的状态 $S_{t+1}$:

其中,目标 $Y_t^Q$ 的定义为:

这个更新非常类似于随机梯度下降,朝向 target value $Y^Q_t$ 更新当前值 Q(S_t, A_t; \theta_t)。
Deep Q-Networks.
一个DQN是一个多层的神经网络,给定一个状态 s,输出一个动作值的向量 $Q(s, *; \theta)$,其中,$\theta$ 是网络的参数。对于一个 n维 的状态空间,动作空间是 m 个动作,神经网络是一个函数将其从 n维空间映射到 m维。两个重要的点分别是 target network 的使用 以及 experience replay的使用。target network,参数为 $\theta^-$,和 online的网络一样,除了其参数是从 online network 经过 某些 steps之后拷贝下来的。目标网络是:
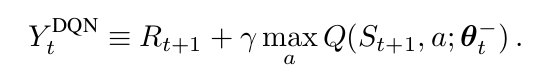
对于 experience replay,观测到的 transitions 都被存贮起来,并且随机的从其中进行采样,用来更新网络。target network 和 experience replay 都明显的改善了最终的 performance。
Double Q-learning
在标准的 Q-learning 以及 DQN 上的 max operator,用相同的值来选择和评价一个 action。这使得其更偏向于选择 overestimated values,导致次优的估计值。为了防止此现象,我们可以从评价中将选择独立出来,这就是 Double Q-learning 背后的 idea。
在最开始的 Double Q-learning算法中,通过随机的赋予每一个 experience 来更新两个 value functions 中的一个 来学习两个value function,如此,就得到两个权重的集合,$\theta$ 以及 $\theta '$。对于每一次更新,其中一个权重集合用来决定贪婪策略,另一个用来决定其 value。做一个明确的对比,我们可以首先排解 selection 和 evaluation,重写公式2,得到:

那么, Double Q-learning error可以写为:
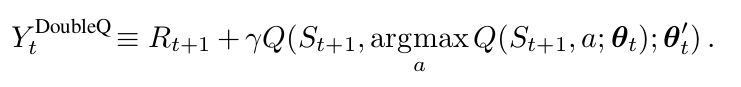 注意到 action 的选择,在 argmax,仍然属于 online weights $\theta_t$。这意味着,像 Q-learning一样,我们仍然可以根据当前值,利用贪婪策略进行 value 的估计。然而,我们利用第二个权重 $\theta _t '$来更加公平的评价该策略。第二个权重的集合,可以通过交换 两个权重的角色进行更新。
注意到 action 的选择,在 argmax,仍然属于 online weights $\theta_t$。这意味着,像 Q-learning一样,我们仍然可以根据当前值,利用贪婪策略进行 value 的估计。然而,我们利用第二个权重 $\theta _t '$来更加公平的评价该策略。第二个权重的集合,可以通过交换 两个权重的角色进行更新。
OverOptimism due to estimation errors:
论文笔记之:Deep Reinforcement Learning with Double Q-learning的更多相关文章
- 论文笔记——A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding
论文<A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding> Prunin ...
- 论文笔记:Deep feature learning with relative distance comparison for person re-identification
这篇论文是要解决 person re-identification 的问题.所谓 person re-identification,指的是在不同的场景下识别同一个人(如下图所示).这里的难点是,由于不 ...
- 论文笔记:Deep Residual Learning
之前提到,深度神经网络在训练中容易遇到梯度消失/爆炸的问题,这个问题产生的根源详见之前的读书笔记.在 Batch Normalization 中,我们将输入数据由激活函数的收敛区调整到梯度较大的区域, ...
- 论文笔记:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning NIPS18_tracking Type:Tracking-By-Detection 本篇论文地主 ...
- 论文笔记 — L2-Net: Deep Learning of Discriminative Patch Descriptor in Euclidean Space
论文: 本文主要贡献: 1.提出了一种新的采样策略,使网络在少数的epoch迭代中,接触百万量级的训练样本: 2.基于局部图像块匹配问题,强调度量描述子的相对距离: 3.在中间特征图上加入额外的监督: ...
- 论文笔记系列-iCaRL: Incremental Classifier and Representation Learning
导言 传统的神经网络都是基于固定的数据集进行训练学习的,一旦有新的,不同分布的数据进来,一般而言需要重新训练整个网络,这样费时费力,而且在实际应用场景中也不适用,所以增量学习应运而生. 增量学习主要旨 ...
- 【论文笔记】A review of applications in federated learning(综述)
A review of applications in federated learning Authors Li Li, Yuxi Fan, Mike Tse, Kuo-Yi Lin Keyword ...
- 论文笔记之:MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching
MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching CVPR 2015 本来都写到一半了,突然笔记本死机了 ...
- 论文笔记:Visual Question Answering as a Meta Learning Task
Visual Question Answering as a Meta Learning Task ECCV 2018 2018-09-13 19:58:08 Paper: http://openac ...
- 论文笔记(4)-Deep Boltzmann Machines
Deep Boltzmann Machines是hinton的学生写的,是在RBM基础上新提出的模型,首先看一下RBM与BM的区别 很明显可以看出BM是在隐含层各个节点以及输入层各个节点都是相互关联的 ...
随机推荐
- 2013年7月份第2周51Aspx源码发布详情
FineOffice自动化办公(OA)源码 2013-7-12 [ VS2010 ]源码描述:此源码使用fineui开发,作为村居使用的系统,所以命名为fineoffice,其实你在此基础上扩成CR ...
- c++的调试与运行
编译F9:运行F10:编译运行F11. 设置断点:在代码所在行的行首单击,该行即被加亮.注意:设置断点后,此时程序运行进入调试状态,要想运行程序,就不能使用F10或者F11,而是要使用F5调试,然后使 ...
- hdu4597 区间dp
//Accepted 1784 KB 78 ms //区间dp //dp[l1][r1][l2][r2] 表示a数列从l1到r1,b数列从l2到r2能得到的最大分值 // #include <c ...
- bistu新生-1005
#include "stdio.h"#include "string.h"int main(){ char ku[]={'0','1','2','3','4', ...
- Sql Server REPLACE函数的使用;SQL中 patindex函数的用法
Sql Server REPLACE函数的使用 REPLACE用第三个表达式替换第一个字符串表达式中出现的所有第二个给定字符串表达式. 语法REPLACE ( ''string_replace1'' ...
- python的变量作用域
import time global mark,sum def gaosi(Q): global sum,mark # 在 使用的时候防止隔离 也要声明一下 这个是全局变量 , 引用外面的值 sum+ ...
- Java最近版本新特性使用介绍
本文来自http://blog.csdn.net/liuxian13183/ ,引用必须注明出处! 在阅读<Thinking in Java>的过程中,并发这一章出现不少新特性,工作中也有 ...
- [数据结构]RMQ问题小结
RMQ问题小结 by Wine93 2014.1.14 1.算法简介 RMQ问题可分成以下2种 (1)静态RMQ:ST算法 一旦给定序列确定后就不在更新,只查询区间最大(小)值!这类问题可以用倍增 ...
- 【转】What is an entity system framework for game development?
What is an entity system framework for game development? Posted on 19 January 2012 Last week I relea ...
- [转]Why Not Paxos
http://blog.csdn.net/cszhouwei/article/details/38374603 Why Not Paxos Paxos算法是莱斯利·兰伯特(LeslieLamport, ...