mapreduce计算框架
一. MapReduce执行过程
- 分片:
(1)对输入文件进行逻辑分片,划分split(split大小等于hdfs的block大小)
(2)每个split分片文件会发往不同的Mapper节点进行分散处理 - mapper任务
(3)每个Mapper节点拿到split分片后,创建RecordReader,把分片数据解析成键值对<k1,v1>,每对<k1,v1>进行一次map操作形成<k2,v2>,此时的<k2,v2>存储在内存的环形缓冲区内(默认100m),当缓冲区达到80%时,就会把这个缓冲区内的全部数据写到linux磁盘文件中,形成溢写文件
(4)溢写的过程不是简单的磁盘拷贝,溢写线程会把缓冲区中的数据进行分组partition,一个分区交给一个reducer处理。分组过程默认由HashPartitioner类处理reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
(5)溢写线程把分组后的数据进行排序,形成分区内的有序数据,如果设置了combiner,此时对内存中的有序数据进行规约,规约后形成溢写文件保存在磁盘上。数据全部处理后,磁盘上会有很多的溢写文件,mapper端对每个分区内的文件不断地分组排序再规约,形成一个大的分区文件(规约是为了减小生成文件的大小,减少发往reduce的传输量)
3. reducer任务
(6)每个reducer负责处理一个分区文件的数据,所以reducer回去所有mapper节点,拷贝属于自己的分区文件。拷贝的文件先放到内存中,当超过缓冲区限制,reducer再次对数据进行排序合并,形成跨多个mapper的<k2,list<v2>>,再将其写入到磁盘中形成reduce的溢写文件
(7)随着溢写文件的增多,后台线程会把这些文件合并成一个大的有序的文件,之后reducer对该大文件的<k2,list<v2>>进行reduce函数处理
(8)把处理后的文件上传到hdfs中
二. hadoop序列化
- 实现Writable接口
(1)序列化:readFields(DataInput)
(2)反序列化:write(DataOutput)序列化
hadoop的数据类型是在网络上传输的序列化数据 ,底层用Dataoutput写出到网络上 ,DataInput读取网络传来的字节流
hadoop中已经定义好的数据类型只能写出基本类型,要传输自定义的类,就要自定义序列化类型// DataOutputStream写出int
public final void writeInt(int v) throws IOException {
out.write((v >>> 24) & 0xFF);
out.write((v >>> 16) & 0xFF);
out.write((v >>> 8) & 0xFF);
out.write((v >>> 0) & 0xFF);
incCount(4);
} // DataInputStream读取int
public final int readInt() throws IOException {
int ch1 = in.read();
int ch2 = in.read();
int ch3 = in.read();
int ch4 = in.read();
if ((ch1 | ch2 | ch3 | ch4) < 0)
throw new EOFException();
return ((ch1 << 24) + (ch2 << 16) + (ch3 << 8) + (ch4 << 0));
}
2. hadoop的序列化比java自定义的序列化效率高 ?
java自定义的序列化在序列化一个对象时,要把这个对象的父类关系全部序列化出去, hadoop的序列化,DataInput只序列化基本数据类型,减小网络传输的字节数
(1)hadoop自定义序列化要加上空参构造,反射获取对象时要用到,否则报no method异常
(2)Reduce时的context.write(k3,v3)会调用TextOutputFormat的writeObj(),里面会调用toString()方法
(3)序列化类的属性要给出setter方法,当序列化类没有toString()方法时,reduce输出文件中hashcode的值是一样的,证明是一个对象,一个对象输出的值却不一样,说明reduce中也在不停调用序列化类的set方法赋值
###三. Mapreduce二级排序
二级排序:hadoop在Mapper产生的数据发往reducer之前进行一次排序,按照k2排序,如果还希望按照v2排序,怎么做呢?
1. Reducer的iterator获取所有值进行内存排序,这样可能会导致内存溢出
2. 重新设计k2,利用hadoop进行排序
(1)k2设计成对象,对象内包含value属性
```java
public class SecondarySortingTemperatureMapper extends Mapper<LongWritable, Text, TemperaturePair, NullWritable> {
private TemperaturePair temperaturePair = new TemperaturePair();
private NullWritable nullValue = NullWritable.get();
private static final int MISSING = 9999;
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String yearMonth = line.substring(15, 21);
int tempStartPosition = 87;
if (line.charAt(tempStartPosition) == '+') {
tempStartPosition += 1;
}
int temp = Integer.parseInt(line.substring(tempStartPosition, 92));
if (temp != MISSING) {
temperaturePair.setYearMonth(yearMonth);
temperaturePair.setTemperature(temp);
context.write(temperaturePair, nullValue);
}
}
}
```
(2)k2实现实现WritableComparable接口,重写k2的compareTo方法,先比较k属性,k属性相同时比较v属性
```java
public int compareTo(TemperaturePair temperaturePair) {
int compareValue = this.yearMonth.compareTo(temperaturePair.getYearMonth());
if (compareValue == 0) {
compareValue = temperature.compareTo(temperaturePair.getTemperature());
}
return compareValue;
}
```
(3)k2重新设计后,还要保证详设计前一样,逻辑上相同的k要发到同一个reducer上,因此,重写partitioner的compare方法,return k2.k.hascode()%numPartitions
```java
public class TemperaturePartitioner extends Partitioner<TemperaturePair, NullWritable>{
@Override
public int getPartition(TemperaturePair temperaturePair, NullWritable nullWritable, int numPartitions) {
return temperaturePair.getYearMonth().hashCode() % numPartitions;
}
}
```
(4)数据抵达reducer时,会按照key分组,为了保证向重新设计k2前一样,分组时仅按照原始k分组,因此重写分组比较器
```java
public class YearMonthGroupingComparator extends WritableComparator {
public YearMonthGroupingComparator() {
super(TemperaturePair.class, true);
}
@Override
public int compare(WritableComparable tp1, WritableComparable tp2) {
TemperaturePair temperaturePair = (TemperaturePair) tp1;
TemperaturePair temperaturePair2 = (TemperaturePair) tp2;
return temperaturePair.getYearMonth().compareTo(temperaturePair2.getYearMonth());
}
}
```
###四.yarn的执行流程
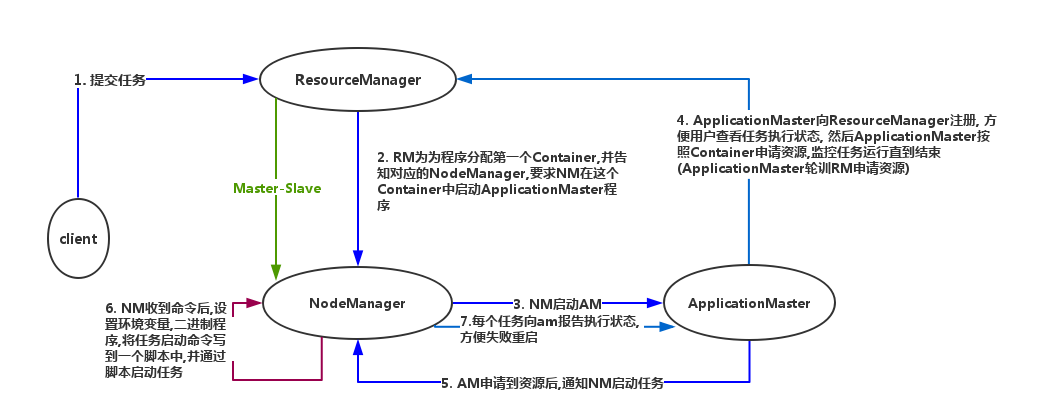mapreduce计算框架的更多相关文章
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
摘要: 通过前面的学习,大家已经了解了HDFS文件系统.有了数据,下一步就要分析计算这些数据,产生价值.接下来我们介绍Mapreduce计算框架,学习数据是怎样被利用的. 博主福利 给大家赠送一套ha ...
- Big Data(七)MapReduce计算框架
二.计算向数据移动如何实现? Hadoop1.x(已经淘汰): hdfs暴露数据的位置 1)资源管理 2)任务调度 角色:JobTracker&TaskTracker JobTracker: ...
- MR 01 - MapReduce 计算框架入门
目录 1 - 什么是 MapReduce 2 - MapReduce 的设计思想 2.1 如何海量数据:分而治之 2.2 方便开发使用:隐藏系统层细节 2.3 构建抽象模型:Map 和 Reduce ...
- Big Data(七)MapReduce计算框架(PPT截图)
一.为什么叫MapReduce? Map是以一条记录为单位映射 Reduce是分组计算
- MapReduce计算框架的核心编程思想
@ 目录 概念 MapReduce中常用的组件 概念 Job(作业) : 一个MapReduce程序称为一个Job. MRAppMaster(MR任务的主节点): 一个Job在运行时,会先启动一个进程 ...
- Hadoop中MapReduce计算框架以及HDFS可以干点啥
我准备学习用hadoop来实现下面的过程: 词频统计 存储海量的视频数据 倒排索引 数据去重 数据排序 聚类分析 ============= 先写这么多
- 开源图计算框架GraphLab介绍
GraphLab介绍 GraphLab 是由CMU(卡内基梅隆大学)的Select 实验室在2010 年提出的一个基于图像处理模型的开源图计算框架.框架使用C++语言开发实现. 该框架是面向机器学习( ...
- 从计算框架MapReduce看Hadoop1.0和2.0的区别
一.1.0版本 主要由两部分组成:编程模型和运行时环境. 编程模型为用户提供易用的编程接口,用户只需编写串行程序实现函数来实现一个分布式程序,其他如节点间的通信.节点失效,数据切分等,则由运行时环境完 ...
- Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐.用户行为分析等. Spark Streaming是建立在 ...
随机推荐
- JS的prototype的共享机制分析
function Super(){ } Super.prototype.aaa=[1,2,3]; Super.prototype.bbb=1; function Sub(){ Super.call(t ...
- 从开发的角度比较 ASP.NET Web 服务与 WCF
Windows Communication Foundation (WCF) 具有一个 ASP.NET 兼容模式选项,用户使用此选项可以对 WCF 应用程序进行编程和配置,使其像 ASP.NET We ...
- 半透明背景(兼容IE)
在CSS3中有rgba属性,可以很方便的实现背景透明,但对于IE家族来说却不是那么容易实现: FireFox.chrome.opera.safari 凡是对支持CSS3且支持W3标准的浏览器都可以现实 ...
- xfs文件系统
引用http://blog.chinaunix.net/uid-522675-id-4665059.html xfs文件系统使用总结 1.3 xfs相关常用命令xfs_admin: 调整 xfs 文件 ...
- oracle监控脚本
简单命令 1.显示服务器上的可用实例:ps -ef | grep smon2.显示服务器上的可用监听器:ps -ef | grep -i listener | grep -v grep3.查看Orac ...
- unity, 查看.anim中的动画曲线(和帧)
在场景里建一个gameObject,添加一个Animation组件,将.anim文件添加到Animation组件的Animations中,然后在Animation组件面板中选中.anim,然后 菜单- ...
- Linux -RAID
转自:http://www.cnblogs.com/xiaoluo501395377/archive/2013/05/25/3099464.html 硬盘类型 速度 SATA <150M/s S ...
- 微信网页授权获取用户基本信息--PHP
现在就说说怎么通过网页授权获取用户基本信息(国家,省,市,昵称)等. 必要条件: 1)公众号认证 2)有网页授权获取用户基本信息的权限接口 注意:最近有朋友说:在公众平台申请的测试号,会出现无法取到用 ...
- ant导入Zookeeper到Eclipse错误path contains invalid character
首先在Zookeeper源码目录执行 ant eclipse 遇到错误 path contains invalid character 可以修改\zookeeper\build.xml 文件加入 &l ...
- java中的分支
条件语句: if-else选择结构: if(条件块){ 代码块1 }else{ 代码块2 } ...