【Python】Python学习----第一模块笔记
1、python是什么?
python是动态解释型的强类型定义语言。
python官方版本的解释器是CPython。该解释器使用C语言开发。
当前主要使用3.x版本的python。
2、第一个python程序
>>> print("Hello World!")
Hello World!
Linux下使用./xxx.py执行python执行python程序,在文件开头添加如下代码:
#!/usr/bin/env python
3、字符编码
英文编码系统:ASCII,可以表示255个字符
中文编码系统:GB2312(1980,7445个字符)-->GBK1.0(1995,21886个字符,中文Windows默认编码)-->GB18030(2000)
Unicode:万国码,世界统一的一种编码系统
UTF-8:Unicode的子集,对Unicode进行优化
python 3.x版本的默认编码是UTF-8。如需要定义程序文件的编码在开头添加# -*- coding: 字符编码 -*-语句。
e.g:
# -*- coding: utf-8 -*-
4、变量
a = 1
#声明一个变量,变量名a,值为1
定义变量的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名:
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
- 变量名最好能让人明了该变量是用来做什么的
5、程序中的注释
# 单行注释 '''多行注释''' or """多行注释"""
6、用户交互
input用来接收用户的输入
e.g:
>>> a = input("请输入:")
请输入:123
>>> print(a)
123注意:input默认的数据类型为字符型,使用int()可以将其转换为整型
使用type()可以查看变量的数据类型,e.g:
>>> a = "abc"
>>> print(type(a))
<class 'str'>输出小技巧:格式化输出
e.g:
name = "Python"
age = 28
print("Name is %s,Age is %s"%(name,age)) #%s字符串 %d 整数 %f 浮点
print("Name is {_name},Age is {_age}".format(_name=name,_age=age)) #结果
Name is Python,Age is 28
Name is Python,Age is 28小技巧:密文输入
需导入getpass模块,使输入的内容不可见
e.g:
>>> getpass.getpass("请输入密码:")
请输入密码: #看不见我看不见我
'assdfghh'7、if…else语句
if 条件: #如果
代码块
else: #否则
代码块if 条件: #如果
代码块
elif 条件: #或者
代码块
else: #否则
代码块8、while循环
while 条件:
代码块#continue 跳出本次循环,进入下次循环
#break 结束整个循环
python中while可以搭配else使用,e.g:
a = 5
while a<6:
if a/2 == 1:
break
a += 1
else:
print("我就是else!") #结果
我就是else!9、for循环
e.g:
for i in range(3):
print(i)
i += 1#结果
0
1
2for i in range(1,3):
print(i)
i += 1 #结果
1
2for i in range(1,5,2):
print(i)
i += 1 #结果
1
3for循环中也有continue和break方法
10、python中的模块
Python有非常丰富和强大的标准库和第三方库
import 模块
#程序开头加上该代码,加载某个模块,接下去就可以使用该模块提供的功能
11、python数据类型
数字:int(整型)、float(浮点)、complex(复数)
布尔值:True 、False
字符串:”Python”
12、python数据运算
算术运算
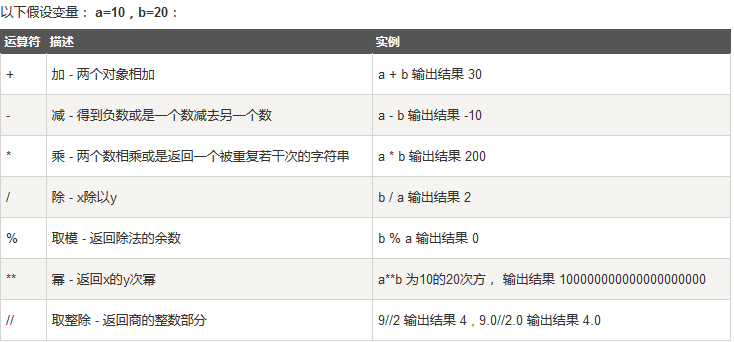
比较运算
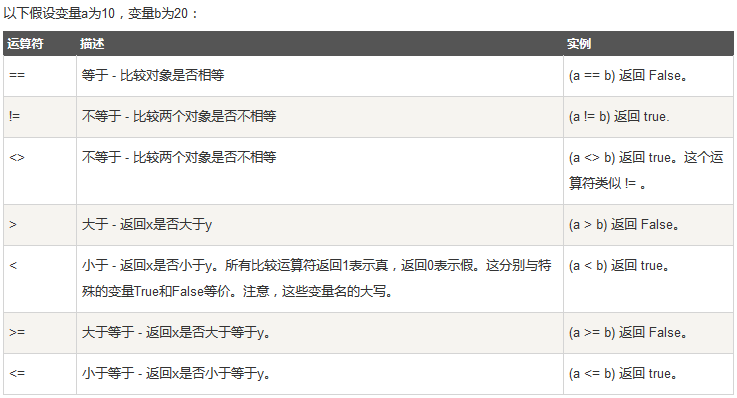
赋值运算
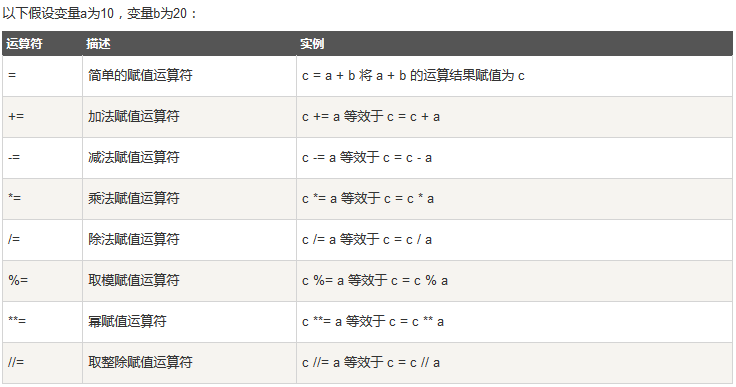
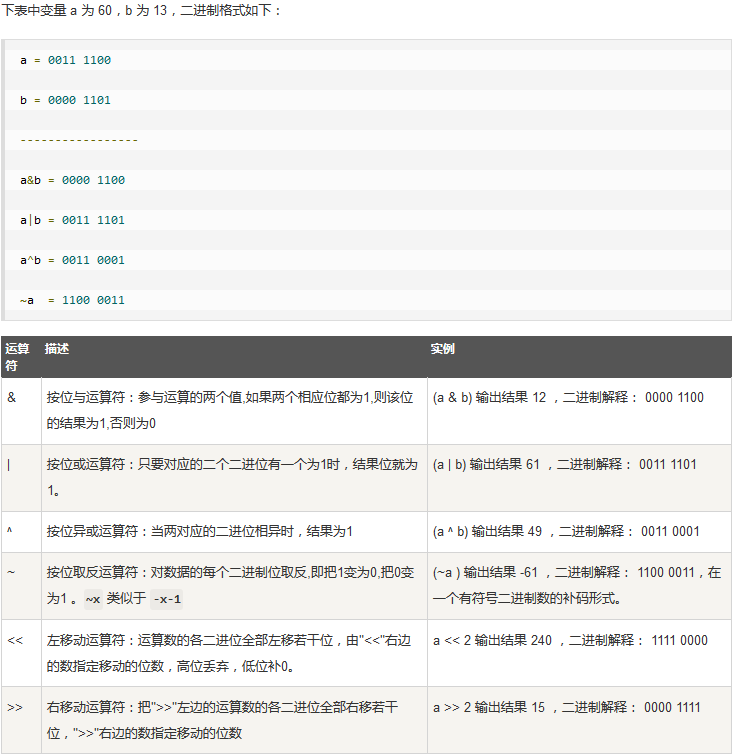
按位运算
逻辑运算

成员运算

身份运算

运算优先级
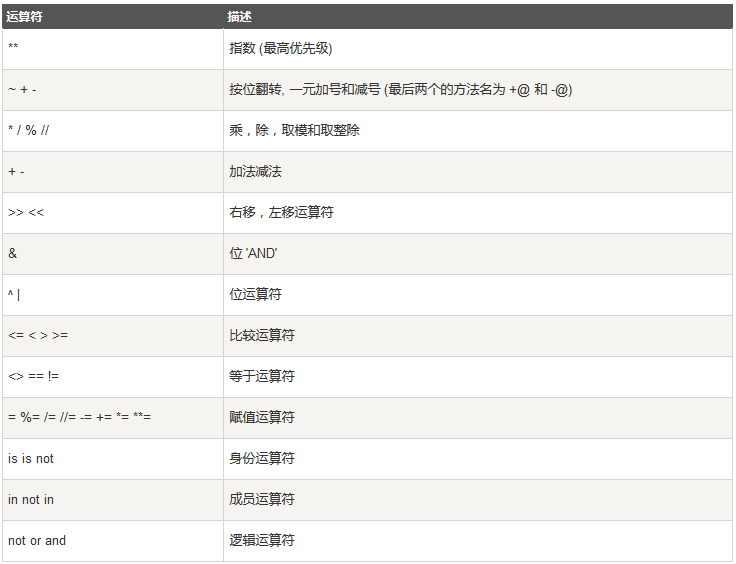
三元运算
e.g:
name = "Python"
if 1>0:
name = "Python"
else:
name = "JAVA"
print(name) #结果
Python name = "Python"
if 1 == 0:
name = "Python"
else:
name = "JAVA"
print(name) #结果
JAVA13、列表
列表是有序的,依靠下标来取值。
>>> name = ["Python","JAVA","C++"]
#定义一个列表 >>> name[0]
'Python'
>>> name[1]
'JAVA'
>>> name[-1]
'C++'
>>> name[-2]
'JAVA'
#通过列表的下标来取值,下标从0开始,负数下标从列表的最后一个开始计算,从-1开始切片
>>> name = ["Python","JAVA","C++","C","C#"]
>>> name[0:2]
['Python', 'JAVA']
#列表的切片,从下标0取到下标1(结束的位置不包括)
>>> name[:2]
['Python', 'JAVA']
#下标为0时可以不写 #注意负数下标
>>> name[-3:]
['C++', 'C', 'C#']
>>> name[-3:-1]
['C++', 'C']
#使用负数下标切片时,仍然从右到左计算,下标-1不写时,取到-1下标的值,写的时候则不包括-1下标的值 >>> name[0:-1:2]
['Python', 'C++']
>>> name[::2]
['Python', 'C++', 'C#']
#同上的负数下标,注意区别,第三个值为步长追加
>>> name.append("Perl")
>>> name
['Python', 'JAVA', 'C++', 'C', 'C#', 'Perl']插入新值
>>> name.insert(2,"Ruby")
>>> name
['Python', 'JAVA', 'Ruby', 'C++', 'C', 'C#', 'Perl']
>>> name.insert(-1,"Lisp")
>>> name
['Python', 'JAVA', 'Ruby', 'C++', 'C', 'C#', 'Lisp', 'Perl']
#将新值插入某个值之前修改
>>> name[2] = "PHP"
>>> name
['Python', 'JAVA', 'PHP', 'C++', 'C', 'C#', 'Lisp', 'Perl']删除
>>> name.remove("PHP")
>>> name
['Python', 'JAVA', 'C++', 'C', 'C#', 'Lisp', 'Perl']
>>> del name[5]
>>> name
['Python', 'JAVA', 'C++', 'C', 'C#', 'Perl']
>>> name.pop()
'Perl'
>>> name
['Python', 'JAVA', 'C++', 'C', 'C#']
>>> name.pop(3)
'C'
#pop不加下标时默认删除最后一个值,pop可以返回被删除的值
>>> name
['Python', 'JAVA', 'C++', 'C#']其他的一些方法
>>> name.index("JAVA")
1
#返回值的下标 >>> name.count("C++")
1
#计数 >>> name
['Python', 'JAVA', 'C++', 'C#']
>>> name.reverse()
>>> name
['C#', 'C++', 'JAVA', 'Python']
#翻转整个列表 >>> name
['Python', 'JAVA', 'C++', 'C#']
>>> name.sort()
>>> name
['C#', 'C++', 'JAVA', 'Python']
#列表的排序 >>> a = ["a","b","c"]
>>> name.extend(a)
>>> name
['C#', 'C++', 'JAVA', 'Python', 'a', 'b', 'c']
#合并两个列表 >>> a.clear()
>>> a
[]
#清除整个列表的值 >>> name_copy = name.copy()
>>> name_copy
['C#', 'C++', 'JAVA', 'Python', 'a', 'b', 'c']
#复制列表列表的嵌套
>>> name = ["Python",[1,2,3],"JAVA","C++"]
>>> name
['Python', [1, 2, 3], 'JAVA', 'C++']
>>> name[1][2]
3列表的循环
name = ["Python","JAVA","C++"]
for i in name:
print(i) #结果
Python
JAVA
C++小技巧
name = ["Python","JAVA","C++"]
for index,item in enumerate(name):
print(index,item) #结果
0 Python
1 JAVA
2 C++#同时循环列表的下标及值
14、元组
元组是不可修改的列表,也叫只读列表
>>> name = ("Python","JAVA","C++")
>>> name
('Python', 'JAVA', 'C++')
#创建一个元组元组只有count与index
>>> name.count("C++")
1
>>> name.index("C++")
2list(),将元组转换为一个列表
>>> a = list(name)
>>> a
['Python', 'JAVA', 'C++']小技巧,无关元组
\033[31,32;1m%s\033[0m,对%s着色
15、字符串的常用操作
字符串可以使用下标和切片操作。
.upper()/lower() #返回一个新字符串,其中原字符串的所有字母都被相应地转换为大写或小写。
.startswith()/.endswith() #返回 True, 如果它们所调用的字符串以该方法传入的字符串开始或结束。
>>> a = "a:b:c:d:e:f"
>>> a.split(":")
['a', 'b', 'c', 'd', 'e', 'f']
a.strip() #删除字符串两边的空白字符(空格、制表符和换行符)
a.rstrip() #删除字符串右边的空白字符(空格、制表符和换行符)
a.lstrip() #删除字符串左边的空白字符(空格、制表符和换行符)
>>> a = "{'a':'b','c':'d'}"
>>> type(a)
<class 'str'>
>>> b = eval(a)
>>> b
{'a': 'b', 'c': 'd'}
>>> type(b)
<class 'dict'>
#将格式化的字符串转换成字典,同理可以转换列表跟元组
name = "Python"
name.capitalize() #首字母大写
name.casefold() #大写全部变小写
name.ljust(50,"-") #输出'Python---------------------------'
name.center(50,"-") #输出 '---------------------Python----------------------'
name..rjust(50,"-") #输出'--------------------Python'
name.count('t') #统计t出现次数
name.encode() #将字符串编码成bytes格式
name.endswith("n") #判断字符串是否以n结尾
"Pyt\thon".expandtabs(10) #输出'Pyt hon', 将\t转换成多长的空格
name.find('y') #查找y,找到返回其索引, 找不到返回-1
name.index('y') #返回y所在字符串的索引
'9aA'.isalnum() #判断是否是字母和数字
'9'.isdigit() #判断是否整数
name.isnumeric #方法检测字符串是否只由数字组成。这种方法是只针对unicode对象。
name.isprintable #判断是否为可打印字符串
name.isspace #判断是否为空格
name.istitle #判断是否首字母大写,其他字母小写
name.islower()/isupper() #判断是否为小写/大写
>>> "|".join(['Python', 'JAVA', 'C++'])
'Python|JAVA|C++'
>>> a = "a:b:c:d:e:f"
>>> a.partition(":")
('a', ':', 'b:c:d:e:f')
.replace(old,new,x) #将第x个字符替换
.swapcase #大小写互换
.zfill() #返回指定长度的字符串,原字符串右对齐,前面填充0
.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则
16、字典
字典:键-值(key - value),key唯一,无序
>>> a = {"福建":"福州","广东":"广州","江西":"南昌"}
>>> a
{'福建': '福州', '广东': '广州', '江西': '南昌'}
#创建一个字典
>>> a["广西"] = "南宁"
>>> a
{'福建': '福州', '广东': '广州', '江西': '南昌', '广西': '南宁'}
#增加
>>> a["广西"] = "广西"
>>> a
{'福建': '福州', '广东': '广州', '江西': '南昌', '广西': '广西'}
#修改
>>> a.pop("广西")
'广西'
>>> a
{'福建': '福州', '广东': '广州', '江西': '南昌'}
>>> del a["江西"]
>>> a
{'福建': '福州', '广东': '广州'}
#删除
>>> a = {"福建":"福州","广东":"广州","江西":"南昌"}
>>> a.popitem()
('江西', '南昌')
#随机删除
>>> a = {"福建":"福州","广东":"广州","江西":"南昌"}
>>> "福建" in a
True
#查找
>>> a.get("福建")
'福州'
>>> a["福建"]
'福州'
#取某个键的值,使用get方法如果键不存在则返回None,直接取键不存在则报错
>>> a.values()
dict_values(['福州', '广州', '南昌'])
>>> a.keys()
dict_keys(['福建', '广东', '江西'])
>>> a.items()
dict_items([('福建', '福州'), ('广东', '广州'), ('江西', '南昌')])
>>> b = list(a.items())
>>> b
[('福建', '福州'), ('广东', '广州'), ('江西', '南昌')]
#返回值可以用于循环
>>> a.setdefault("福建")
'福州'
>>> a.setdefault("福建","南宁")
'福州'
>>> a.setdefault("广西","南宁")
'南宁'
>>> a
{'福建': '福州', '广东': '广州', '江西': '南昌', '广西': '南宁'}
#不存在则增加,存在则返回该键的值
>>> b
{1, 2, 3}
>>> b = {1:2,3:4,5:6}
>>> a.update(b)
>>> a
{'福建': '福州', '广东': '广州', '江西': '南昌', '广西': '南宁', 1: 2, 3: 4, 5: 6}
#合并两个字典
>>> a = dict.fromkeys([1,2,3],"abc")
>>> a
{1: 'abc', 2: 'abc', 3: 'abc'}
a = {"福建":"福州","广东":"广州","江西":"南昌"}
for i in a:
print(i,a[i])
#字典的循环,结果
福建 福州
广东 广州
江西 南昌
17、集合
集合是一个无序的,不重复的数据组合。作用:
- 去重,把列表变成集合,自动去重
- 关系测试,取交集、并集等关系
s = set([3,5,9,10]) #创建一个数值集合
t = set("Hello") #创建一个唯一字符的集合
t.add('x') # 添加一项
s.update([10,37,42]) # 添加多项
t.remove('H') # 删除
len(s) #长度
s.copy() #返回 set “s”的一个浅复制
x in s #测试 x 是否是 s 的成员
x not in s #测试 x 是否不是 s 的成员
s.issubset(t)
s <= t
#测试是否 s 中的每一个元素都在 t 中
s.issuperset(t)
s >= t
#测试是否 t 中的每一个元素都在 s 中
s.union(t)
s | t
#返回一个新的 set 包含 s 和 t 中的每一个元素
s.intersection(t)
s & t
#返回一个新的 set 包含 s 和 t 中的公共元素
s.difference(t)
s - t
#返回一个新的 set 包含 s 中有但是 t 中没有的元素
s.symmetric_difference(t)
s ^ t
#返回一个新的 set 包含 s 和 t 中不重复的元素
18、文件操作
文件的常用操作
f = open("文件名","模式")
#打开文件,模式有以下几种:
r 只读模式(默认)
w 只写模式(文件不存在则建立,文件存在则覆盖)
a 追加模式(文件不存在则建立,文件存在则追加)
r+ 读写模式(可读可写可追加)
w+ 写读模式
a+ 追加读模式
rb、wb、ab 处理二进制文件
U 将\r \n \r\n自动转换成\n(与r或r+模式同时使用)
f.read() #读文件
f.readline() #读一行
f.readlines() #将文件每一行读如一个列表
f.write() #将内容写入文件
f.close() #关闭文件
f.tell() #返回指针位置,按文件中字符的个数计算
f.seek() #回到某个指针位置
f.encoding() #返回文件所使用的编码
文件的其他一些操作
f.readable() #判断文件是否可读
f.writeable() #判断文件是否可写
f.closed() #判断文件是否关闭
f.seekable() #判断是否可以移动指针
f.name() #返回文件名
f.isatty() #如果文件连接到一个终端设备返回 True,否则返回 False
f.flush() #将缓存内容写入硬盘
f.truncate() #从头开始截断文件
for line in f:
print(line)
#将文件一行行读入内存,一次只在内存中保存一行 with open("文件名","模式") as f:
#为防止打开文件之后忘记关闭,使用该方法在with代码块执行完毕之后自动关闭释放文件资源 with open("文件名","模式") as f1,open("文件名","模式") as f2:
#支持对多个文件进行操作
19、字符的编码与转码
encode:编码 decode:转码
GBK-->UTF-8:GBK--decode-->Unicode--encode-->UTF-8
UTF-8-->GBK:UTF-8--decode-->Unicode--encode—>GBK
两个不同编码相互转换都需要经过Unicode。
.decode(原编码)
.encode(转换后编码)
python 3.x默认为UTF-8编码。
在python 3.x中encode,在转码的同时还会把string变成bytes类型,decode在解码的同时还会把bytes变回string。
20、函数
使用函数的意义:
- 减少重复的代码
- 保持一致性,使代码更容易修改
- 使程序更容易扩展
def 函数名(形参):
'''文档描述'''
代码块
return #返回执行结果,可返回多个值,默认返回None
#定义一个函数
位置参数,关键字参数,默认参数,e.g:
def test(x,y):
print(x)
print(y)
return
test(1,2)
#位置参数,将函数所获得的参数按照一一对应的位置传入,输出结果为
1
2 def test(x,y):
print(x)
print(y)
return
test(x=1,y=2)
#关键字参数,按照关键字将值传入,输出结果为
1
2 def test(x,y):
print(x)
print(y)
return
test(1,y=2)
#位置参数与关键字参数一起使用,注意:关键字参数不能放在位置参数之前,输出结果为
1
2 def test(x,y,z=3):
print(x)
print(y)
print(z)
return
test(1,y=2)
#默认参数,直接在定义函数的时候赋值,可以在调用函数的时候修改,输出结果为
1
2
3
非固定参数
def test(*args):
print(args)
return
test(1,2)
test(1,2,3)
test(*[1,2,3,4])
#非固定参数,可以传入不同个数的参数,只能接受位置参数,以元组的方式输出,结果
(1, 2)
(1, 2, 3)
(1, 2, 3, 4) def test(**args):
print(args)
return
test(x=1,y=2)
test(x=1,y=2,z=3)
#非固定参数,以字典的方式输出,只接受关键字参数,结果
{'x': 1, 'y': 2}
{'x': 1, 'y': 2, 'z': 3}
21、作用域、局部与全局变量
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时,在定义局部变量的子程序内,局部变量起作用,在其它地方全局变量起作用
22、递归与高阶函数
递归
一个函数在内部调用自身,该函数即为递归函数
特性:
- 必须有一个明确的结束条件
- 每次进入更深一层递归时,问题规模相比上次递归都应该有所减少
- 递归效率不高,递归层次过多会导致栈溢出
高阶函数
变量可以指向函数,函数的参数能够接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数称为高阶函数。e.g:
def add(x,y,f):
return f(x)+f(y)
res = add(3,-6,abs)
print(res)
#结果
9
【Python】Python学习----第一模块笔记的更多相关文章
- Elasticsearch7.X 入门学习第一课笔记----基本概念
原文:Elasticsearch7.X 入门学习第一课笔记----基本概念 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https: ...
- Python爬虫学习第一记 (翻译小助手)
1 # Python爬虫学习第一记 8.24 (代码有点小,请放大看吧) 2 3 #实现有道翻译,模块一: $fanyi.py 4 5 import urllib.request 6 import u ...
- Python语言学习:模块
一.模块 1. 模块(Module):以.py结尾的文件,包含python对象定义和python语句.使代码段更容易理解和使用. 模块分为两种:标准库(直接导入的库)和第三方库(需要下载安装的库). ...
- 路飞学城Python爬虫课第一章笔记
前言 原创文章,转载引用务必注明链接.水平有限,如有疏漏,欢迎指正. 之前看阮一峰的博客文章,介绍到路飞学城爬虫课程限免,看了眼内容还不错,就兴冲冲报了名,99块钱满足以下条件会返还并送书送视频. 缴 ...
- Python基础学习(第一周)
Python是一门什么语言 编译型和解释型 通俗来讲,编译型就是一次性把所有程序写的代码都转换成机器可以识别的语言(机器语言),即可执行文件.exe: 解释型就是程序每执行到某一条指令,则会有有个称之 ...
- python新手---学习第一天
Python是一门跨平台.开源.免费的解释型高级动态编程语言,它支持伪编译将源代码转换成字节码来优化程序提高运行速度和对源码进行保密,并且支持使用py2exe.pyinstaller.cx_Freez ...
- python开发学习-day06(模块拾忆、面向对象)
s12-20160130-day06 *:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: ...
- Selenium+Python自动化测试学习问题总结笔记
1.问题描述:不能导入自定义类 错误内容:This inspection detects names that should resolve but don't. Due to dynamic dis ...
- Python爬虫学习==>第一章:Python3+Pip环境配置
前置操作 软件名:anaconda 版本:Anaconda3-5.0.1-Windows-x86_64清华镜像 下载链接:https://mirrors.tuna.tsinghua.edu.cn/ ...
随机推荐
- Co. - Microsoft - Windows - 通过任务计划,备份本地MySQL,数据上传Linux备份服务器
需求 客户为Windows系统,安装MySQL,需要每日备份数据库到指定目录,并且上传到公司的备份服务器(Linux). 1.使用mysqldump备份MySQL数据库,使用FTP上传到阿里云Linu ...
- DevOps - 配置管理 - Ansible
http://www.zsythink.net/archives/category/运维相关/ansible/
- 高级同步器:信号量Semaphore
引自:https://blog.csdn.net/Dason_yu/article/details/79734425 一.信号量一个计数信号量.从概念上讲,信号量维护了一个许可集.Semaphore经 ...
- 【路由和交换之H3C自导自演】
H3C配置自导自演 显示和维护及恢复 1:display display history-command :查看历史命令记录 display diagnostic-information :查看 ...
- Python学习:for 循环 与 range()函数
for 循环 For … in 语句是另一种循环语句,其特点是会在一系列对象上进行迭代(Iterates),即它会遍历序列中的每一个项目 注意: 1.else 部分是可选的.当循环中包含它时,它 ...
- C++远征之封装篇(下)-学习笔记
C++远征之封装篇(下) c++封装概述 下半篇依然围绕类 & 对象进行展开 将原本学过的简单元素融合成复杂的新知识点. 对象 + 数据成员 = 对象成员(对象作为数据成员) 对象 + 数组 ...
- 41-Individual authentication 模板
1-创建项目,进入vscode控制台,输出如下命令, uld表示指定mssqllocaldb E:\coding\netcore>dotnet new mvc -au Individual -u ...
- 【转】Django添加静态文件设置
STATIC_URL = '/statics/'STATIC_ROOT= os.path.join(BASE_DIR, 'statics')STATICFILES_DIRS = ( os.path.j ...
- c#一些常用的方法集合
是从一个asp.net mvc的项目里看到的.挺实用的. 通过身份证号码获取出生日期和性别 通过身份证号码获取出生日期和性别 #region 由身份证获得出生日期 public static stri ...
- 虚拟现实-VR-UE4-LEAP-Motion手势识别
点击打开链接今天到手一个新东西,LEAP手势识别仪. 关于LEAP Leap是一家面向PC以及Mac的体感控制器制造公司. 具体信息百度百科http://baike.baidu.com/link?ur ...