scrapy初体验 - 安装遇到的坑及第一个范例
scrapy,python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。scrapy的安装稍显麻烦,不过按照以下步骤去进行,相信你也能很轻松的安装使用scrapy。
安装python2.7
scrapy1.0.3暂时只支持python2.7
# wget https://www.python.org/ftp/python/2.7.6/Python-2.7.6.tgz
[root@rocket software]# tar -zxvf Python-2.7.6.tgz # 解压
[root@rocket software]# cd Python-2.7.6
[root@rocket software]# mkdir /usr/local/python27 # 创建安装目录
[root@rocket software]# ./configure --prefix=/usr/local/python27
[root@rocket software]# make
[root@rocket software]# make install
# 目前安装的版本是2.6,需要替换成2.7
[root@rocket software]# mv /usr/bin/python /usr/bin/python2.6.6
[root@rocket software]# ln -s /usr/local/python27/bin/python /usr/bin/python
这里需要注意的是,由于原有系统安装的是python2.6,升级了python2.7,那么yum也会出问题
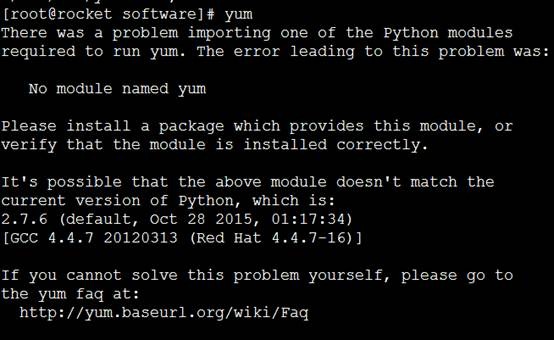
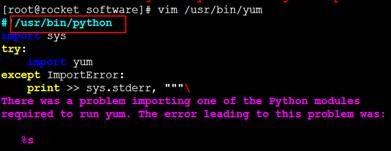
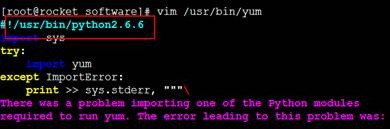
需要修改yum使用python2.6的版本
安装setuptools
进入官网,下载到本地,解压
https://pypi.python.org/pypi/setuptools#downloads
[root@rocket software]# cd setuptools-18.1
[root@rocket setuptools-18.1]# python setup.py install
安装pip
进入官网,下载到本地,解压
https://pypi.python.org/pypi/pip#downloads
[root@rocket software]# cd pip-7.1.2
[root@rocket pip-7.1.2]# python setup.py install
安装Twisted
进入官网,下载到本地,解压
wget https://pypi.python.org/packages/source/T/Twisted/Twisted-15.4.0.tar.bz2
[root@rocket software]# cd Twisted-15.4.0
[root@rocket Twisted-15.4.0]# python setup.py install
安装scrapy
pip install scrapy
在这个过程中,遇到以下问题
1 pip安装模块警告InsecurePlatformWarning: A true SSLContext object is not available.
yum install python-devel libffi-devel openssl-devel
pip install pyopenssl ndg-httpsclient pyasn1
在运行pip就不会出现警告了
2 安装lxml失败
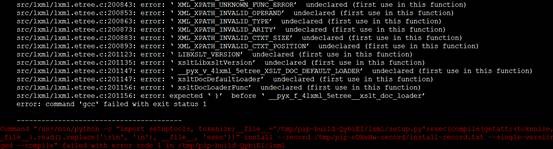
解决方法是先安装libxslt开发包:
yum install libxslt-devel
确认安装成功
[root@rocket software]# rpm -qa | grep libxml
libxml2-devel-2.7.6-20.el6.x86_64
libxml2-python-2.7.6-20.el6.x86_64
libxml2-2.7.6-20.el6.x86_64
3 安装cffi失败
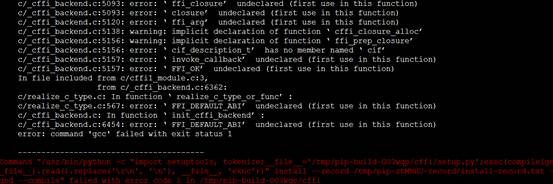
[root@rocket software]# yum -y install libffi-devel
[root@rocket software]# rpm -qa | grep libffi
libffi-3.0.5-3.2.el6.x86_64
libffi-devel-3.0.5-3.2.el6.x86_64
4 安装openssl失败

[root@rocket software]# yum -y install openssl-devel
[root@rocket software]# rpm -qa | grep openssl
openssl-devel-1.0.1e-42.el6.x86_64
openssl-1.0.1e-42.el6.x86_64
解决完以上几个问题后,重新执行
pip install scrapy
能够顺利安装成功。
确认安装成功
[root@rocket Twisted-15.4.0]# python
Python 2.7.6 (default, Oct 27 2015, 01:21:45)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-16)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import scrapy
没报错,安装成功。
开始第一个scrapy任务
详细介绍请参考
http://scrapy-chs.readthedocs.org/zh_CN/latest/intro/overview.html
[root@rocket scrapy]# scrapy startproject mininova

运行的时候报错,注意运行的时候,必须在mininova的主目录中运行,不然会报错
编写items.py
import scrapy class MininovaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
name = scrapy.Field()
description = scrapy.Field()
size = scrapy.Field()
编写spiders/mininova_spiders.py
from scrapy.spiders import CrawlSpider, Rule, Spider
from scrapy.linkextractors import LinkExtractor
import scrapy
from mininova.items import MininovaItem class MininovaSpider(scrapy.spiders.CrawlSpider):
name = 'mininova'
allowed_domains = ['mininova.org']
start_urls = ['http://www.mininova.org/today']
rules = [Rule(LinkExtractor(allow=['/tor/\d+']), 'parse_torrent')] def parse_torrent(self, response):
torrent = MininovaItem()
torrent['url'] = response.url
torrent['name'] = response.xpath("//h1/text()").extract()
torrent['description'] = response.xpath("//div[@id='description']").extract()
torrent['size'] = response.xpath("//div[@id='info-left']/p[2]/text()[2]").extract()
return torrent
运行
[root@rocket mininova]# pwd
/home/demo/scrapy/mininova
[root@rocket mininova]# scrapy crawl mininova -o scraped_data.json
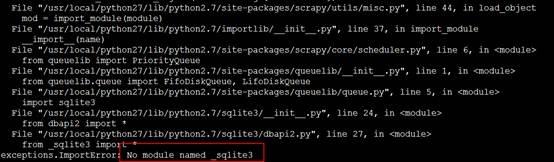
需要安装 sqlite-devel库,再重新编译安装Python
yum install sqlite-devel
[root@rocket software]# yum install sqlite-devel
[root@rocket software]# ./configure --prefix=/usr/local/python27
[root@rocket software]# make
[root@rocket software]# make install
这样就可以找到sqlite3的库了
[root@rocket software]# cd /usr/local/python27/lib/python2.7/lib-dynload/
[root@rocket lib-dynload]# ll|grep sql
-rwxr-xr-x. 1 root root 240971 Oct 28 01:17 _sqlite3.so
[root@rocket mininova]# scrapy crawl mininova -o scraped_data.json
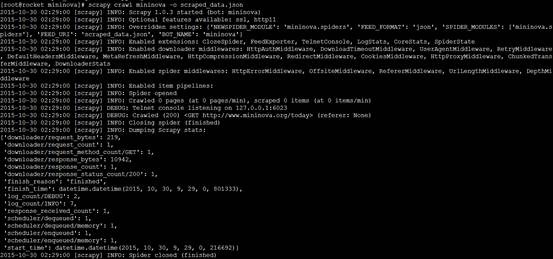
终于可以跑起来了。。
接下来我们将进一步对scrapy的工作原理进行分析,并给出更为实用的例子。
scrapy初体验 - 安装遇到的坑及第一个范例的更多相关文章
- Scrapy 初体验
开发笔记 Scrapy 初体验 scrapy startproject project_name 创建工程 scrapy genspider -t basic spider_name website. ...
- Scrapy初体验(一) 环境部署
系统选择centOs 7,Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, ...
- Serverless 初体验:快速开发与部署一个Hello World(Java版)
昨天被阿里云的这个酷炫大屏吸引了! 我等85后开发者居然这么少!挺好奇到底什么鬼东西都是90.95后在玩?就深入看了一下. 这是一个关于Serverless的体验活动,Serverless在国内一直都 ...
- 老司机实战Windows Server Docker:1 初体验之各种填坑
前言 Windows Server 2016正式版发布已经有近半年时间了,除了看到携程的同学分享了一些Windows Server Docker的实践经验,网上比较深入的资料,不管是中文或英文的,都还 ...
- MySQL初体验--安装MySQL
操作系统版本:redhat 6.7 64位 [root@mysql ~]# cat /etc/redhat-release Red Hat Enterprise Linux Server releas ...
- Cocos2d-x 3.4 初体验——安装教程
电脑系统window7 32位 1.首先从官网下载cocos2d-x并解压 http://cn.cocos2d-x.org/download/ 解压后的文件夹中有一个setup.py,双击运行.需要安 ...
- Jenkins初体验-安装与部署服务
一.概述 1.简介 在工作中接触到CD/CI,Devops相关的技术,本文记录Jenkins的基本使用.Jenkins是一款开源的持续集成工具,能够集成一套自动化部署任务. 目标 通过jenkins从 ...
- Jmeter的初体验--安装
准备工作 安装JMeter前需要安装配置好Java 一.安装 1.直接在官网下载安装即可,下载地址:http://jmeter.apache.org/download_jmeter.cgi,(Wind ...
- scrapy初体验
1. 构建scrapy项目 scrapy startproject ['项目名'] 在spiders下生成文件 cd spiders scrapy genspider douban_spider [' ...
随机推荐
- cpu压力测试
一.cpu压力测试 1.安装stress软件 sudo apt-get install stress #加压 nohup stress --cpu 8 & #查看cpu负载 top
- 转: HTTP Live Streaming直播(iOS直播)技术分析与实现
http://www.cnblogs.com/haibindev/archive/2013/01/30/2880764.html HTTP Live Streaming直播(iOS直播)技术分析与实现 ...
- msSQL使用表参数
使用表参数 表变量(Table Parameters)可以将整个表数据汇集成一个参数传递给存储过程或SQL语句.它的注意性能开销是将数据汇集成参数(O(数据量)). 定义了一个表参数jk_users_ ...
- 菜鸟调错(五)——jetty执行时无法保存文件
背景交代: 上一篇博客写的是用jetty和Maven做开发.測试.在使用的过程中遇到一个小问题.就是在jetty启动以后,改动了jsp.xml等文件无法保存. 错误信息: 解决方式: 到Maven库( ...
- Mybatis学习记录(二)----mybatis开发dao的方法
1 SqlSession使用范围 1.1 SqlSessionFactoryBuilder 通过SqlSessionFactoryBuilder创建会话工厂SqlSessionFactory 将Sq ...
- Android Exception18(Stuido debug .....)
这个问题比较诡异,在用android-studio debug的时候,第一次能正常使用,但是后面就不知道是什么鬼,每次debug都冒出来这个. 之后,重新新建一个项目就好了
- Nginx主动连接与被动连接的差别
1.主动连接是指Nginx主动发起的同上游server的连接:被动连接是指Nginx接收到的来自client主动发起的连接; 2.主动连接用ngx_peer_connection_t结构体表示:被动连 ...
- VB的第一个项目
前言-----本人也是刚刚接触VB,企业的VB代码基本能看的懂,但是自己开发,只能呵呵.一般在刚学习一门新的语言时,很容易发生一些自己相当然的认识错误,so,记下并分享开发学习的过程,望指正.--- ...
- ASP.NET MVC传递Model到视图的多种方式总结
ASP.NET MVC传递Model到视图的多种方式总结 有多种方式可以将数据传递到视图,如下所示: ViewData ViewBag PartialView TempData ViewModel T ...
- .net中数据缓存使用
今天 遇到一个问题 访问一个接口数据 基本上是固定的,于是想把数据 缓存下来...于是版本1 诞生了 private static ConcurrentDictionary<int, List& ...