【APUE】Chapter16 Network IPC: Sockets & makefile写法学习
16.1 Introduction
Chapter15讲的是同一个machine之间不同进程的通信,这一章内容是不同machine之间通过network通信,切入点是socket。
16.2 Socket Descriptors
socket抽象上是一个communication endpoint,具体就是一个int型变量。生成socket的函数如下:
int socket(int domain, int type, int protocol)
函数有点儿类似open,即打开一个socket descriptor。
函数返回的就是 socket descriptor(是file descriptor)的一种。
三个输入参数:
domain : 整数枚举类型,决定了nature of communication,其中包括address format
type : 整数枚举类型,决定了communication characterisitcs;主要包括SOCK_STREAM、SOCK_DGRAM两种;具体还没太理清楚,但是前者是需要server与client先connet再交换数据的,后者是可以直接在server与client之间交换数据的
protocol : 整数枚举类型,一般设为0(因为protocol一般跟domain+type匹配,前两个参数决定了,protocol参数就决定了)
在unix系统设计的时候,一些可以操作file descriptor的函数,也可以操作socket descriptor,比如:close dup dup2 read write等等。
但是socket有自己特殊的地方,socket是双向作用的,有接口函数用来关闭socket的某个方向上的功能。
int shutdown(int sockfd, int how)
how : 整数枚举类型,如果how是SHUT_RD,则关闭的是read功能;如果how是SHUT_RDWR,则关闭的是read和write。
已经有close可以关闭socket,为什么还要有shutdown这个函数呢?
(1)由于socket也是一种file,因此需要所有与socket相关的reference都关闭了才能真的把这个socket给close了。尤其在network这种情况下,往往一个socket会dup出来好多reference。而shutdown的操作不受到reference都关闭的限制。
(2)有时候,需要关闭单方面的操作,read或者write。
因为有了上面的需求,所以才开发出了shutdown这种接口函数。
16.3 Addressing
socket函数相当于在server端和client端分别产生communication endpoint,这个endpoint就是int类型的变量。(即,如果把server和client比作两个老城市,有了socket就相当于有了两个城市分别有了邮电局,有了邮电局就具备了通信的基本条件)
server和client两端光有socket还不够,要想在二者之间通信必须告诉socket“到哪”、“跟谁”、“怎么”通信。
这里“到哪”相当于找到address(即城市邮电局的总机号码),“跟谁”相当于找到port(即拨通了总机号码之后,去拨哪个分机号),“怎么”相当于通信的格式(即相当于电话线中电磁波怎么发送和接受)。
按照上述的思路,可以串起来这一章节的内容。
1. Byte Ordering
所有的通信都要约定最基础的底层的数据格式。其中byte ordering就是一个基础问题。
举例来说,简单说一个32-bits的整数,由4个byte来表示,0x
在真实的存储中可以有两种情况
(1)一种是真的按照上面16进制的顺序表示即从前往后存放的是0x04,0x03,0x02,0x01,这种叫little-endian。
(2)另一种存放的顺序正好相反,从前往后存放的是0x01,0x02,0x03,0x04,这种叫big-endian。
在真实的通信中,需要server和client都清楚对方发来的是什么样的byte ordering,只有双方都清楚了才能保证通信正常进行。(即,相当于双方写信,必须让对方知道,是“从左往右读、还是从右往左读”的约定)
值得注意的是TCP/IP protocol系列都是big-endian套路的,然后很多系统Processor architecture用的都是little-endian套路的(比如最常见的X86架构);因此,在进行程序不同machine 不同平台之间交换数据的时候,要注意是不是同样的字节续,跟网络续是否匹配。系统已经封装了几个函数供我们使用,来自动进行转换(htonl htons ntohl ntohs,其中h代表host,n代表network s表示16bit的short l表示32bit的long)。后面的例子中会体现这一点。
这个blog讲述的字节序、网络序比较易懂:http://songlee24.github.io/2015/05/02/endianess/。
2. Address Formats
用一种数据结构来表示不同的通信格式以及其内容。这种数据结构就是struct sockaddr。
struct sockaddr{
sa_family_t sa_family; /*address family*/
char sa_data[]; /*variable-length address*/
...
}
不同的系统可能对上面的某些成员可能会不同,通用的规则大概如下:
(1)sa_family这个参数一般都是格式确定的,这个标明地址格式。
(2)sa_data这个参数不同的系统实现所有不同,但是含义都是表达通信的地址具体内容。
3. Address Lookup
前面说过,要想完成通信必须知道通信双方的地址信息+端口信息(即邮局在哪里,具体是邮局的哪个窗口)。进行这种address lookup的方式有两种:
(1)直接给现成的。比如某台机器的ssh服务:IP为166.111.170.1 port为22,知道了这两项内容就找到了通信目的机器和端口,系统直接按照有效的IP和有效的端口号所指定的机器端口寻找通信目标。
(2)通过名称间接找。上面是最直接的地址查找方式,另一种更人性化的方式就是输入hostname和servicename,再映射到具体的IP数值和port数值上。(这类似叫一个人不会直接去叫他的身份证号,而是叫他的名字)。
因此引入一个重要的函数,可以兼容上面两种查找的方式,以及囊括了IP和port两项内容。
int getaddrinfo(const char *restrict host,
const char *restrict service,
const struct addrinfo *restrict hint,
struct addrinfo **restrict res);
前两个输入参数如下
(1)host : 如果host是合理的IP地址,就不去/etc/hosts中搜索了;否则,去/etc/hosts中去找hostname对应的IP地址。
(2)service : 如果service是合理的port数值,就不去/etc/services;否则,去/etc/services中去找services name对应的port数值。
第三个参数如下
(3)hint : 起到一个“过滤器”的作用。因为,符合host name + service name条件的address可能有多个;比如166.111.170.1:22这样的组合,符合条件的既有tcp也有udp的。通过/etc/services文件可以验证:

比如,我只想要所有services中只提供tcp通信的address,那么通过ip+port显然是无法做到的,因此可以通过在hint中设定过滤条件来达到目的。hint是一个struct addrinfo结构,具体成员和含义如下:
struct addrinfo{
int ai_flags; /*customize behavior*/
int ai_family; /*address family*/
int ai_socktype; /*socket type*/
int ai_protocol; /*protocol*/
socklen_t ai_addrlen; /*length in bytes of address*/
struct sockaddr *ai_addr; /*address*/
char *ai_canonname; /*canonical name of host*/
struct addrinfo *ai_next; /*next int the list*/
...
}
其中,ai_socktype是一个重要的过滤选项,后面跟着例子一起看。
(4)res : 这是一个result-valued argument,即执行这个函数最终希望获得的内容。这个res最终指向一个addrinfo的链表头元素。即满足“host+service+hint过滤”的所有address集合。
下面看一个例子,体会一下这一部分的内容:
#include "apue.h"
#if defined(SOLARIS)
#include <netinet/in.h>
#endif
#include <netdb.h>
#include <arpa/inet.h>
#if defined(BSD)
#include <sys/socket.h>
#include <netinet/in.h>
#endif void print_family(struct addrinfo *aip)
{
printf(" family ");
switch (aip->ai_family){
case AF_INET:
printf("inet");
break;
case AF_INET6:
printf("inet6");
break;
case AF_UNIX:
printf("unix");
break;
case AF_UNSPEC:
printf("unspecified");
break;
default:
printf("unkown");
}
} void print_type(struct addrinfo *aip)
{
printf(" type ");
switch (aip->ai_socktype){
case SOCK_STREAM:
printf("stream");
break;
case SOCK_DGRAM:
printf("datagram");
break;
case SOCK_SEQPACKET:
printf("seqpacket");
break;
case SOCK_RAW:
printf("raw");
break;
default:
printf("unknown (%d)", aip->ai_socktype);
}
} void print_flags(struct addrinfo *aip)
{
printf(" flags ");
if (aip->ai_flags == ) {
printf("");
}
else {
if (aip->ai_flags & AI_PASSIVE) {
printf(" passive");
}
if (aip->ai_flags & AI_CANONNAME) {
printf(" canon");
}
if (aip->ai_flags & AI_NUMERICHOST) {
printf(" numhost");
}
if (aip->ai_flags & AI_NUMERICSERV) {
printf(" numserv");
}
if (aip->ai_flags & AI_V4MAPPED) {
printf(" v4mapped");
}
if (aip->ai_flags & AI_ALL) {
printf(" all");
}
}
} void print_protocol(struct addrinfo *aip)
{
printf(" protocol ");
switch (aip->ai_protocol) {
case :
printf("default");
break;
case IPPROTO_TCP:
printf("TCP");
break;
case IPPROTO_UDP:
printf("UDP");
break;
case IPPROTO_RAW:
printf("raw");
break;
default:
printf("unknown (%d)", aip->ai_protocol);
}
} int main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
struct sockaddr_in *sinp;
const char *addr;
int err;
char abuf[INET_ADDRSTRLEN]; if (argc != ) {
err_quit("usage: %s nodename servcie", argv[]);
}
hint.ai_flags = AI_CANONNAME;
hint.ai_family = ;
hint.ai_socktype = ;
hint.ai_protocol = ;
hint.ai_addrlen = ;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL; /*getaddrinfo功能是找特定host 特定service的addrinfo信息*/
/*argv[1] : host
*argv[2] : service
hint : 过滤用的addrinfo模板
ailist : linked list存放所有符合条件的addrinfo structure*/
if ((err = getaddrinfo(argv[], argv[], &hint, &ailist))!=) {
err_quit("getaddrinfo error: %s", gai_strerror(err));
} for (aip = ailist; aip != NULL; aip = aip->ai_next)
{
print_flags(aip);
print_family(aip);
print_type(aip);
print_protocol(aip);
printf("\n\thost %s", aip->ai_canonname ? aip->ai_canonname:"-");
if (aip->ai_family == AF_INET) { /*只关心ipv4这个family的addrinfo信息*/
sinp = (struct sockaddr_in *)aip->ai_addr; /*取出socket address信息*/
addr = inet_ntop(AF_INET, &sinp->sin_addr, abuf, INET_ADDRSTRLEN);
printf(" address %s", addr ? addr : "unkown");
printf(" port %d", ntohs(sinp->sin_port));
}
printf("\n");
}
exit();
}
在我的机器上实验结果如下:
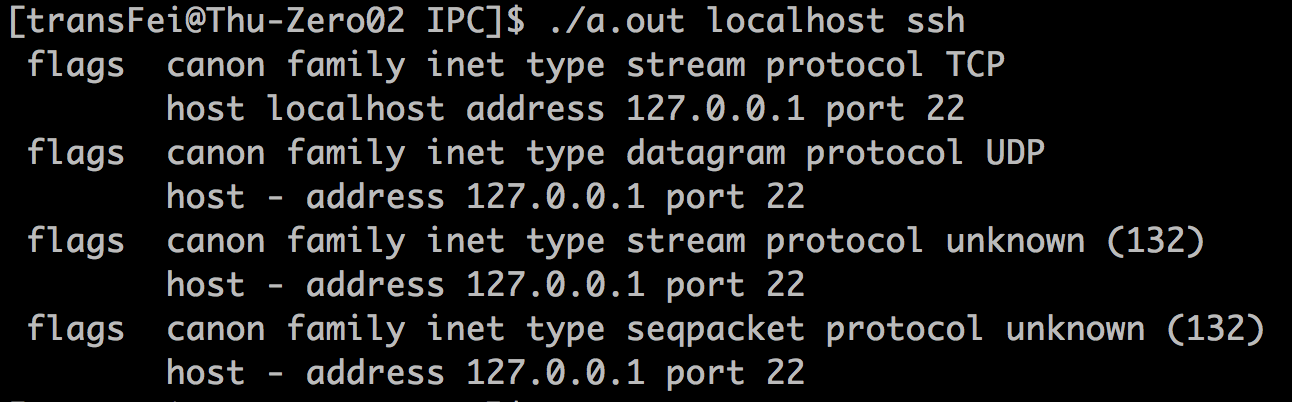
可以看到,tcp和udp以及后面跟了两个其他的内容(具体我不了解)。
对line117代码做修改:ai_socktype = SOCK_STREAM,结果如下:

这样hint的过滤功能就体现出来了。
这里用到一个转换函数inet_ntop
const char *inet_ntop(int domain, const void *restrict addr, char *restrict str, socklen_t size)
这个函数将addrinfo所指的address转化成一个字符串,并返回字符串的地址。
在上面的例子中,IPV4的地址是作为一个unit32_t整形存在系统中的。因此,我们做如下的代码改动(line145 line146增加两行)

结果如下:

暂时忽略中间出现的几个struct数据结构,只关注最后输出的tmp.s_addr。这是一个unit32_t类型的变量,占4个byte;那么其值是16777343是如何得到的呢?这个地址肯定是与127.0.0.1是等价的。
我们先写一个小程序,如下:
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h> int main(int argc, char *argv[])
{
uint32_t num = ;
char l = *((char *)&num);
char h = *((char *)&num+);
printf("low address byte:%d\n",l);
printf("high address byte:%d\n",h);
return ;
}
执行结果如下:

因此在系统中地址由小到大,以此存放的4个byte为:127、0、0、1。我用的是Linux系统,按照little-endian原则,地址最小排在最低的byte(127),地址最大的排在最高的byte(1),因此有了如下的计算公式:1*256*256*256 + 127 = 16777343。 这个unit32_t类型的值也就得到了。
前面提过,如果前两个参数host和service输入的不是name,而是有效的数值,getaddrinfo也能处理并返回结果。测试结果如下:
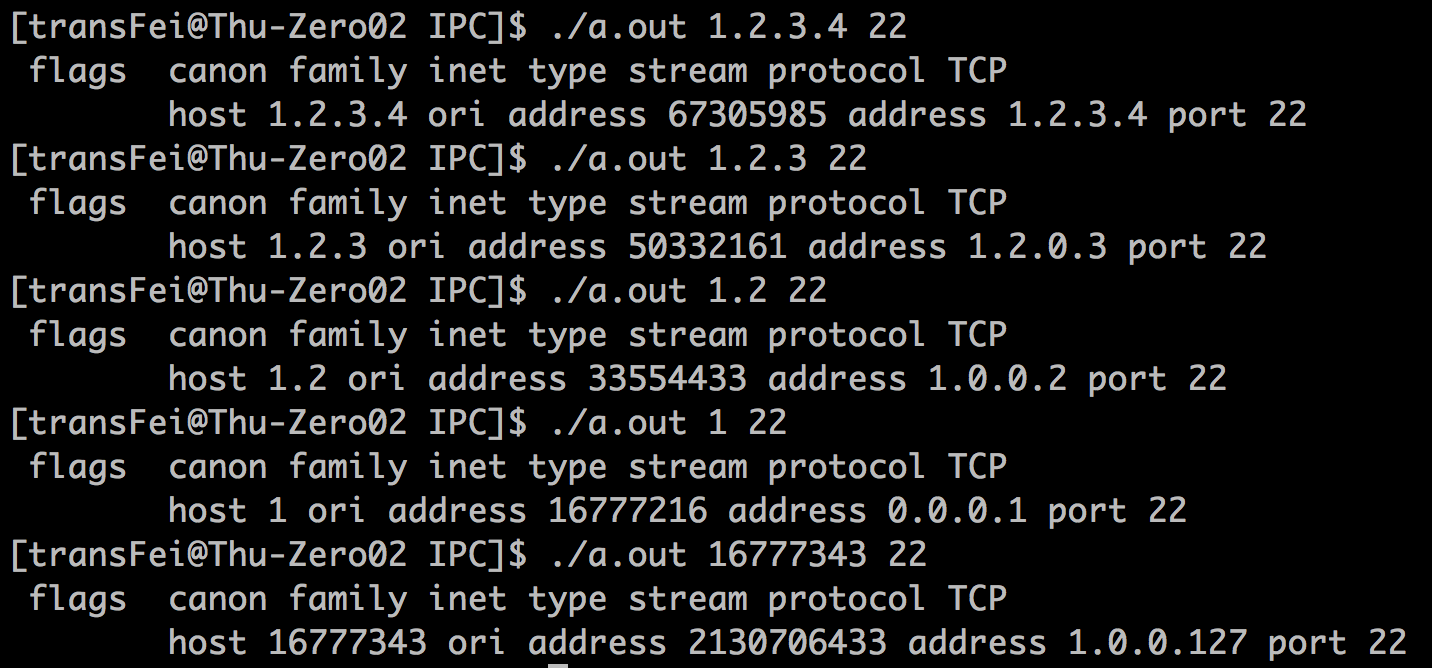
可以得到如下结论:
A. 如果输入的是有效的数值,那么getaddrinfo就不会去/etc/hosts和/etc/services中用name去分别找主机的地址和端口号,而是用一种约定的套路去进行地址的转换。
B. 这种特定的方法就是,用4bytes存放一个IP。如果输出的是number-and-dots这种格式,那么会进行如下转换(可以man inet_aton来查看)
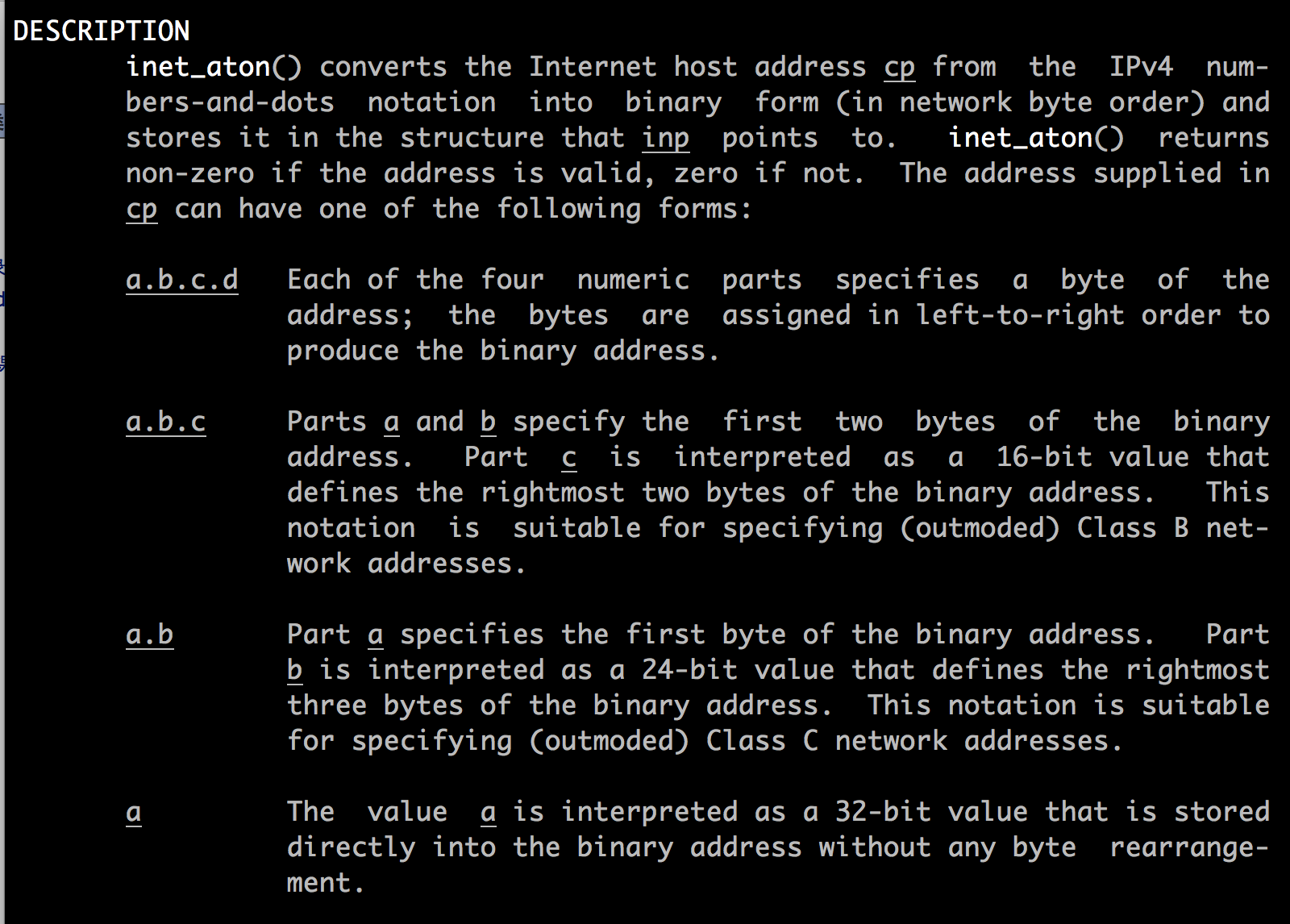
(1) 前三种情况a.b.c.d、a.b.c、a.b都好说,number-and-dots从左往右,一段对应一ip的一个byte;如果不够4段了,最后那段的数字就升级为16bits或者24bits的,最前面段的数还照常。
(2)如果就是光秃秃一个数,那它就必须全部顶上,升级为32bits的。因此客观上“1”就被解释成了0.0.0.1,但为什么不是1.0.0.0呢?前面说过TCP/IP是big-endian的,因此一个32bits的数字1,最高8bits的值是1,而最高8bits的值被当成了IP最后一段的值,因此也就是被系统结石为0.0.0.1了。同理,16777343,按照同样的方法就被解释成了1.0.0.127。通过这个例子,对order byte有个印象,遇到问题了知道去查找各种转换函数就OK了。
4. Associating Address with Sockets
要想理解好这个部分,需要去详细读unix network programming (unp)volume 1 chapter 4。个人觉得Richard Stevens把network相关的精髓都写在了unp这本书上;而apue这本书的network部分只能做一个提纲挈领的参考;否则,不具备相关基础,直接看apue比较困难。
最主要的是介绍了一个函数:bind函数
int bind(int sockfd, const struct sockaddr *addr, socklen_t len)
可以这么理解这个函数的设计思路:16.2讲的是socket;16.3.1 16.3.2 16.3.3讲的是address的问题;16.4.4就把socket和address给串起来了。
这个bind的作用是让socket的操作与sockaddr指向的地址上。而且书上还说这个bind操作在server端是必须的,但是在client端不是必须的。这两点第一次接触理解起来比较抽象,我的具体理解就是:
(1)socket就相当于一个接线员(它具备接线的能力,负责哪个线路都OK),sockaddr相当于综合了总机号(ip)和分机号(port)的信息;而bind做的事情就是个让“接线员”把它后面提供的服务接到这个“总机号+分机号”
(2)由于server端要持续提供service,并且每次一定要保证让client能够通过固定的ip+port找到服务,因此server端的socket一定要与ip+port绑定,意思就是告诉server端其他的服务“这个IP的这个端口被我占用了”。
(3)轮到client端,是不需要bind这个操作的。这就相当于一个客户在本地邮电局,并且知道拨通哪个总机号和分机号就能接通异地邮电局的特定的服务;因此,他只需要找到一个接线员(client端socket)并且告诉接线员对方的总机(server端的ip)号和分机号(server端的port);这个接线员(client端socket)就可以在自家邮电局选一个能跟对方(server端)拨通号码的总机(client端ip)号和分机号(client端port)即可,不用非得指定一定是是自家哪个总机号(比如client端有多个网卡,多个ip,找一个能用的就行)和分机号(有多个port可用,选一个能用的就OK了)。
上述整个过程中,客户并不需要知道接线员是通过本地邮电局的哪个总机号+分机号去接通对方邮电局的服务的,只知道能接通就可以了。如果实在想知道,还可以通过getsockname函数来了解。
16.4 Connection Establishment
如果是connection-oriented network service,需要在server和client之间建立connection的关系。
1. 对于client端来说,建立联系的方法就是调用connect函数。具体如下:
int connect(int sockfd, const struct sockaddr *addr, socklen_t len)
这里的sockfd是client端建立的socket;addr是需要连接的server端的sockaddr信息。
2. 对于server端来说,建立联系的方法就是调用listen和accept函数。具体如下:
(1)listen函数对应的是client端server函数的请求,标明server端愿意接收与sockfd相关的connect请求
int listen(int sockfd, int backlog)
(2)accept函数有些地方需要注意一下,先看函数原型:
int accept(int sockfd, struct sockaddr *restrict addr, socklen_t *restrict len)
sockfd :server端提供具体service的socket file descriptor
addr & len : 这两个参数属于value-resulted argument参数;如果不为NULL,则函数执行之后,会指向发起连接请求的client端的address信息;如果为NULL,则没有作用。
还有一个重要的地方,accept函数的返回值也是一个socket file descriptor;这个socket fd的作用就是专门用来处理与发送请求的这个client的通信问题。那么,这个返回的socket fd与传入参数的sockfd是什么关系呢?这个部分我是看了后面的代码才看懂的。这里为了方便阐述,姑且把传入参数的sockfd叫做old fd,返回的sockfd叫做new fd:
a. old fd负责的事情比较专一,专门负责接收client发来的请求,重点在“接收”(相当于酒店的前台经理,来一个客人接待一下)
b. new fd负责的是具体提供服务的后续操作,重点在“服务”。(相当于酒店的服务员,把前台经理接收的客人带到具体的房间)
c. old fd每次负责接待完就OK了,剩下的服务的具体事情就交给new fd去做(前台经理接收一个客人之后,马上喊过来一个小弟服务员;然后经理继续干前台接待的事情,服务员小弟就去具体接待客人)这种结构就是典型的fork编程模型,后面的具体代码会看到。
16.5 Data Transfer
前面的工作都做好了之后,就可以传输数据了。
发送数据。
这里重点用了两个函数:
1. send函数
ssize_t send(int sockfd, const void *buf, size_t nbyte, int flags)
这个函数能使用的前提是server和client之间必须已经建立好连接。
2. sendto函数
ssize_t sendto(int sockfd, const void *buf, size_t nbytes, int flags, const struct *destaddr, socklen_t destlen)
这个函数在使用的时候可以不用管server和client之间是否建立好连接。
上面这两个函数,执行成功并返回了,并不意味这数据已经“送到了”,而仅仅是“送出去了”。
接收数据。
与发送对应,这里也用了两个函数:
recv函数 & recvfrom函数
ssize_t recv(int sockfd, void *buf, size_t nbytes, int flags)
ssize_t recvfrom(int sockfd, void *restrict buf, size_t len, int flags, struct sockaddr *restrict addr, socklen_t *restrict addrlen)
如果不关心数据的sender是谁,可以用recv;如果需要知道数据sender的信息,可以用recvfrom,sender的信息就存放在addr中了。
上面讲了那么多函数,用unix network programming volume 1 chapter 4中的一张图来做一下总结:
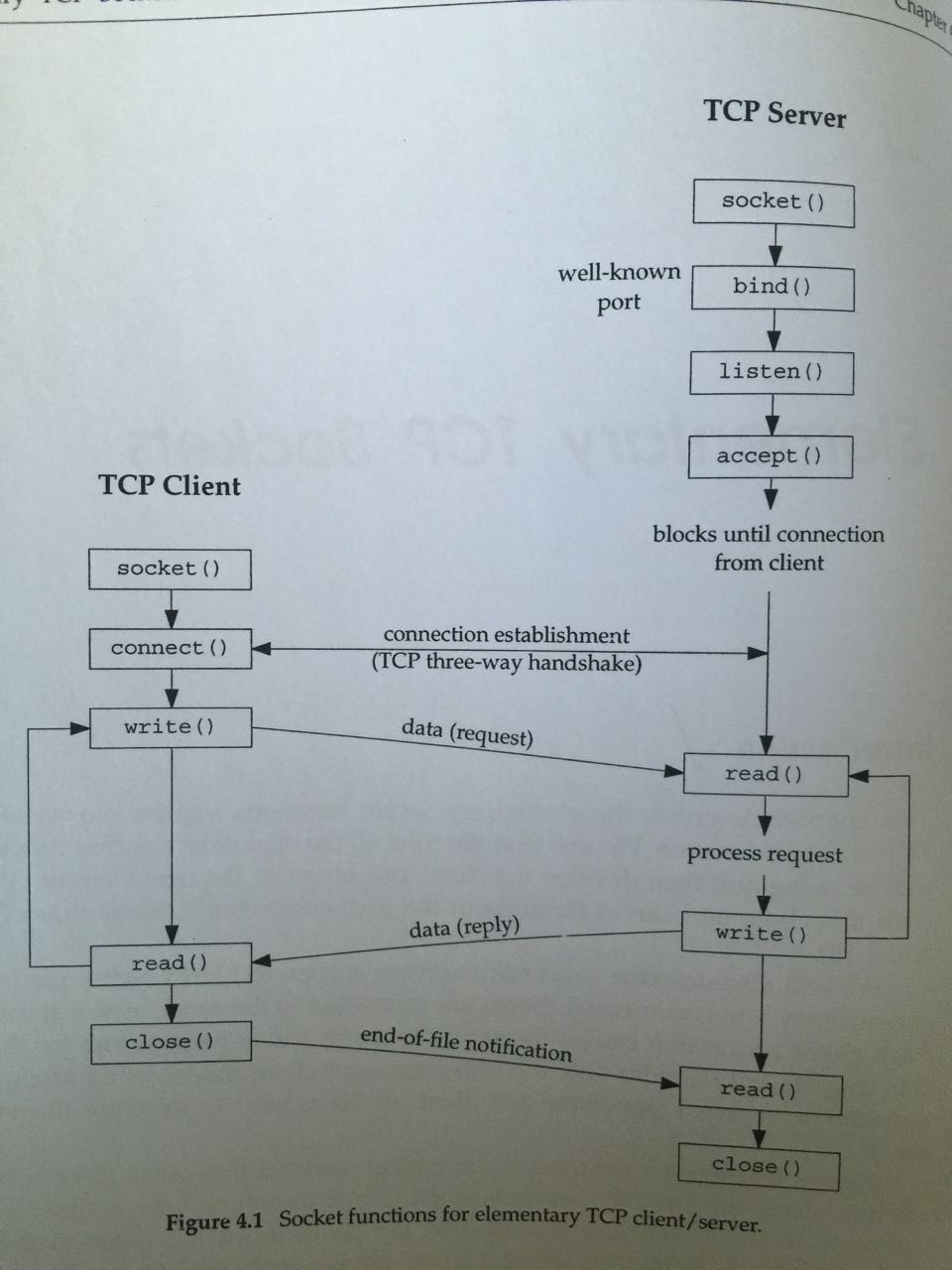
有了上面这个图,顶过很多文字解释,各个函数的调用顺序以及关系都比较清晰了。
16.7 server & client 通信综合例子
把这一章前面所有的内容综合到下面的例子中。
两个例子实现的功能都是一样的,就是client发起请求,获取server端uptime命令的执行结果,并且输出到client端的终端上;不同的在于一个是基于connetion的通信,一个是connectionless的通信。其中关于connection的通信还有两种不同的实现方法。这个例子虽然实现的功能简单,但是包含的细节还挺多的。第一次接触这样的程序,只能摸着石头过河,先给一个自己理解回头有问题再修正。
下面两个例子执行成功的前提是,需要在实验的机器上修改/etc/services文件,在后面加上两行,如下:

意思就是把我们之后要用到的service name及其端口号确定,这样就方便很多。这一步需要root权限,如果么有root权限还可以想其他办法。
例子一,基于connection的server & client通信
上代码之前,先总结一下server端和client端的执行流程:
1. server端做的事情就是:
(1)获得hostname
(2)使自己变成一个daemon process (用到chapter 13 daemon process的知识)
(3)获取所有这个'ruptime'服务的可用address(ip+port),并挑一个可用的address
(4)用这个地址以此执行socket bind listen操作,并返回可用的socket file descriptor(这个sockfd相当于前面提到的大堂经理)
(5)基于(4)返回的sockfd,监听client发来的请求;一旦收到了请求,则执行accept的操作,生成一个可以用的socket file descriptor(这个sockefd相当于前面提到的服务员小弟)
(6)接着就是想办在让uptime command执行,并且讲结果send回client端。有两种达到这个目的的方法:一种是利用popen函数实现;另一种是利用裸写fork实现。两种实现方法分别对应了server.c中的serve1函数和serve2函数。
(7)处理完客户端的这次请求,继续等着其他客户端发送请求
其中(4)被单独封装成一个initserver.c文件,其余的部分都在一个server.c文件中。具体代码如下:
initserver.c文件:
#include "cs.h"
#include <netdb.h>
#include <errno.h>
#include <sys/socket.h> int initserver(int type, const struct sockaddr *addr, socklen_t alen, int qlen)
{
int fd;
int err = ;
int reuse = ; if ((fd = socket(addr->sa_family, type, ))<) { /*根据family和type 让系统选择与这俩搭配的protocal*/
return -;
}
errno = err;
if (setsockopt(fd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(int))<) {
goto errout;
}
if (bind(fd, addr, alen)<) { /*将server相关的fd 与特定port绑定*/
printf("errno:%d %s\n", gai_strerror(errno));
goto errout;
}
if (type==SOCK_STREAM || type == SOCK_SEQPACKET) { /*如果是TCP的 再让server启动监听 并限定监听队列的最大长度是qlen*/
if (listen(fd, qlen)<) {
goto errout;
}
}
printf("1.1\n");
return fd;
errout:
err = errno;
close(fd);
errno = err;
return -;
}
server.c文件:
#include "cs.h"
#include <netdb.h>
#include <errno.h>
#include <syslog.h>
#include <sys/socket.h> #define BUFLEN 128
#define QLEN 10 /*设定server的监听队列长度*/ #ifndef HOST_NAME_MAX /*如果没有定义HOST_NAME_MAX 则给出一个默认值*/
#define HOST_NAME_MAX 256
#endif //extern int initserver(int, const struct sockaddr *, socklen_t, int); int serve1(int sockfd)
{
int clfd;
FILE *fp;
char buf[BUFLEN];
printf("3\n");
set_cloexec(sockfd);
printf("4\n");
for(;;)
{
printf("5\n");
if ((clfd = accept(sockfd, NULL, NULL))<) {
syslog(LOG_ERR, "ruptimed: accept error: %s", strerror(errno));
exit();
}
/*popen中用了pipe+fork+exec的编程模型 产生一个child process专门用来执行uptime命令
* 而clfd是用来与client关联的socket 这个是不需要继承到child process中的 所以要通过设定flag位来控制*/
set_cloexec(clfd);
if ((fp = popen("/usr/bin/uptime","r"))==NULL) { /*架设与uptime关联的管道 'r'表示从uptime中读*/
sprintf(buf, "error: %s\n", strerror(errno));
send(clfd, buf, strlen(buf), );
}
else {
while (fgets(buf, BUFLEN, fp)!=NULL) { /*不断通过pipe从uptime中读数据*/
send(clfd, buf, strlen(buf), ); /*读到的数据向client发送数据*/
}
pclose(fp); /*pipe中的数据读完了*/
}
close(clfd); /*这次处理client的请求完毕 关闭与client连接的socket*/
}
} int serve2(int sockfd)
{
int clfd, status;
pid_t pid; set_cloexec(sockfd);
for(;;)
{
if ((clfd = accept(sockfd, NULL, NULL))<) {
syslog(LOG_ERR, "ruptimed: accept error: %s", strerror(errno));
exit();
};
if ((pid = fork())<) {
syslog(LOG_ERR, "ruptimed: fork error: %s", strerror(errno));
exit();
}
else if (pid==) {
/*1. 让server end的stdout和stderr都输出到client end
*2. stdin已经连着了/dev/null 不会有其他的输出影响server end*/
if (dup2(clfd, STDOUT_FILENO)!=STDOUT_FILENO ||
dup2(clfd, STDERR_FILENO)!=STDERR_FILENO) {
syslog(LOG_ERR, "ruptimed: unexpected error");
exit();
}
close(clfd);
execl("/usr/bin/uptime", "uptime", (char *));
syslog(LOG_ERR, "ruptimed: unexpected return from exec: %s", strerror(errno));
}
else {
close(clfd);
waitpid(pid, &status, );
} }
} int main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
int sockfd, err, n;
char *host; if (argc != ) {
err_quit("usage: ruptimed");
}
if ((n = sysconf(_SC_HOST_NAME_MAX))<) { /*host name的长度限制*/
n = HOST_NAME_MAX;
}
if ((host = malloc(n))==NULL) { /*分配一个足够长的存放host name的字符串*/
err_sys("malloc error");
}
if (gethostname(host, n)<) { /*获得host name*/
err_sys("gethostname error");
}
/*使得当前的执行的这个process成为daemon
* 传入的参数cmd有两个目的:
* 1. 这个daemon出错的时候 知道是哪个cmd出错了
* 2. daemon出错的时候 知道把syslog往哪里引*/
daemonize("ruptimed");
host = "localhost";
memset(&hint, , sizeof(hint));
hint.ai_flags = AI_CANONNAME;
hint.ai_family = ;
hint.ai_socktype = ;
hint.ai_addrlen = ;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL; if ((err = getaddrinfo(host, "ruptime", &hint, &ailist))!=) { /*ruptime 人为设定一个port*/
syslog(LOG_ERR, "ruptimed: getaddrinfo error: %s", gai_strerror(err));
exit();
}
printf("1\n");
for ( aip=ailist; aip!=NULL; aip=aip->ai_next)
{
printf("2\n");
if ((sockfd = initserver(SOCK_STREAM, aip->ai_addr, aip->ai_addrlen, QLEN))>=) {
serve2(sockfd); /*只对第一个返回的addrinfo执行serve操作*/
exit();
}
else {
printf("sockfd:%d\n",sockfd);
}
}
exit();
}
这里line 33和line 53用到的是set_cloexec函数也单独封装到一个setfd.c的文件中,具体如下:
#include "cs.h"
#include <fcntl.h> int
set_cloexec(int fd)
{
int val; if ((val = fcntl(fd, F_GETFD, )) < )
return(-); val |= FD_CLOEXEC; /* enable close-on-exec */ return(fcntl(fd, F_SETFD, val));
}
另外还有line 107的daemonize函数也被单独封装在一个daemonize.c的文件中,具体如下:
#include "cs.h"
#include <syslog.h>
#include <signal.h>
#include <fcntl.h>
#include <sys/resource.h> void
daemonize(const char *cmd)
{
int i, fd0, fd1, fd2;
pid_t pid;
struct rlimit rl;
struct sigaction sa; /*
* Clear file creation mask.
*/
umask(); /*
* Get maximum number of file descriptors.
*/
if (getrlimit(RLIMIT_NOFILE, &rl) < )
err_quit("%s: can't get file limit", cmd); /*
* Become a session leader to lose controlling TTY.
*/
if ((pid = fork()) < )
err_quit("%s: can't fork", cmd);
else if (pid != ) /* parent */
exit();
setsid(); /*
* Ensure future opens won't allocate controlling TTYs.
*/
sa.sa_handler = SIG_IGN;
sigemptyset(&sa.sa_mask);
sa.sa_flags = ;
if (sigaction(SIGHUP, &sa, NULL) < )
err_quit("%s: can't ignore SIGHUP", cmd);
if ((pid = fork()) < )
err_quit("%s: can't fork", cmd);
else if (pid != ) /* parent */
exit(); /*
* Change the current working directory to the root so
* we won't prevent file systems from being unmounted.
*/
if (chdir("/") < )
err_quit("%s: can't change directory to /", cmd); /*
* Close all open file descriptors.
*/
if (rl.rlim_max == RLIM_INFINITY)
rl.rlim_max = ;
for (i = ; i < rl.rlim_max; i++)
close(i); /*
* Attach file descriptors 0, 1, and 2 to /dev/null.
*/
fd0 = open("/dev/null", O_RDWR);
fd1 = dup();
fd2 = dup(); /*
* Initialize the log file.
*/
openlog(cmd, LOG_CONS, LOG_DAEMON);
if (fd0 != || fd1 != || fd2 != ) {
syslog(LOG_ERR, "unexpected file descriptors %d %d %d",
fd0, fd1, fd2);
exit();
}
}
上面的代码设计到的一些技术细节如下:
(1)守护进程daemon process。server.c中的line 107为什么要调用daemonize让当前进程变成守护进程?这个问题需要看过apue chapter13 daemon process才能完全理解(详情可见之前的学习笔记http://www.cnblogs.com/xbf9xbf/p/4923491.html)。
a. 什么是daemon process,为啥要给server端变成一个daemon?简单说,server端这个进程相当于一个纯粹的服务进程,不想受到任何terminal的影响(不会因为终端断了这个进程或者结束会话就挂了);这个进程的stdin stdout stderr都指向/dev/null这个黑洞(具体可以去google到底什么是/dev/null),不会主动受到stdin stdout stderr的影响;只要机器不断电,这个进程不被终止,就会一直在后台运行。综合以上几点,这个进程真的是非常沉默的躲在后台,像一个幽灵(daemon)一样在运行着。
b. 要想实现daemon process需要一套流程,即daemonize.c文件中的这套流程。太多的细节不解释了,最主要的是daemonize.c中的line 67~68,这个daemon process的file descriptor中的0,1,2都被占用了(因为都指向/dev/null了)。如果对dup这样的技术细节还要深究,可以回顾apue chapter 3 FILE I/O的内容(详情可见之前的学习笔记http://www.cnblogs.com/xbf9xbf/p/4930496.html)。
(2)管道通信pipe。server.c中的line 33~44利用的是pipe的方式实现server端内部的IPC的。什么是pipe可以参见apue chapter15 IPC的pipe内容(详情可见之前的学习笔记http://www.cnblogs.com/xbf9xbf/p/5018177.html)。简单说,这部分代码就是在另开一个child process,并在新开的child process中执行/usr/bin/uptime这个命令,然后再利用pipe把uptime执行完成的结果读到parent process的buffer中,然后再send回client中。
a. 为什么要set_cloexec(clfd)?因为后面调用的popen函数,其内部实现机制用了fork+pipe+exec的机制。一旦有了fork和exec,就涉及到了parent process的memory layout复制到child process memory layout的问题。即,child process也可以有一个clfd,并且child process的clfd也与client关联的那个socket。如下图:
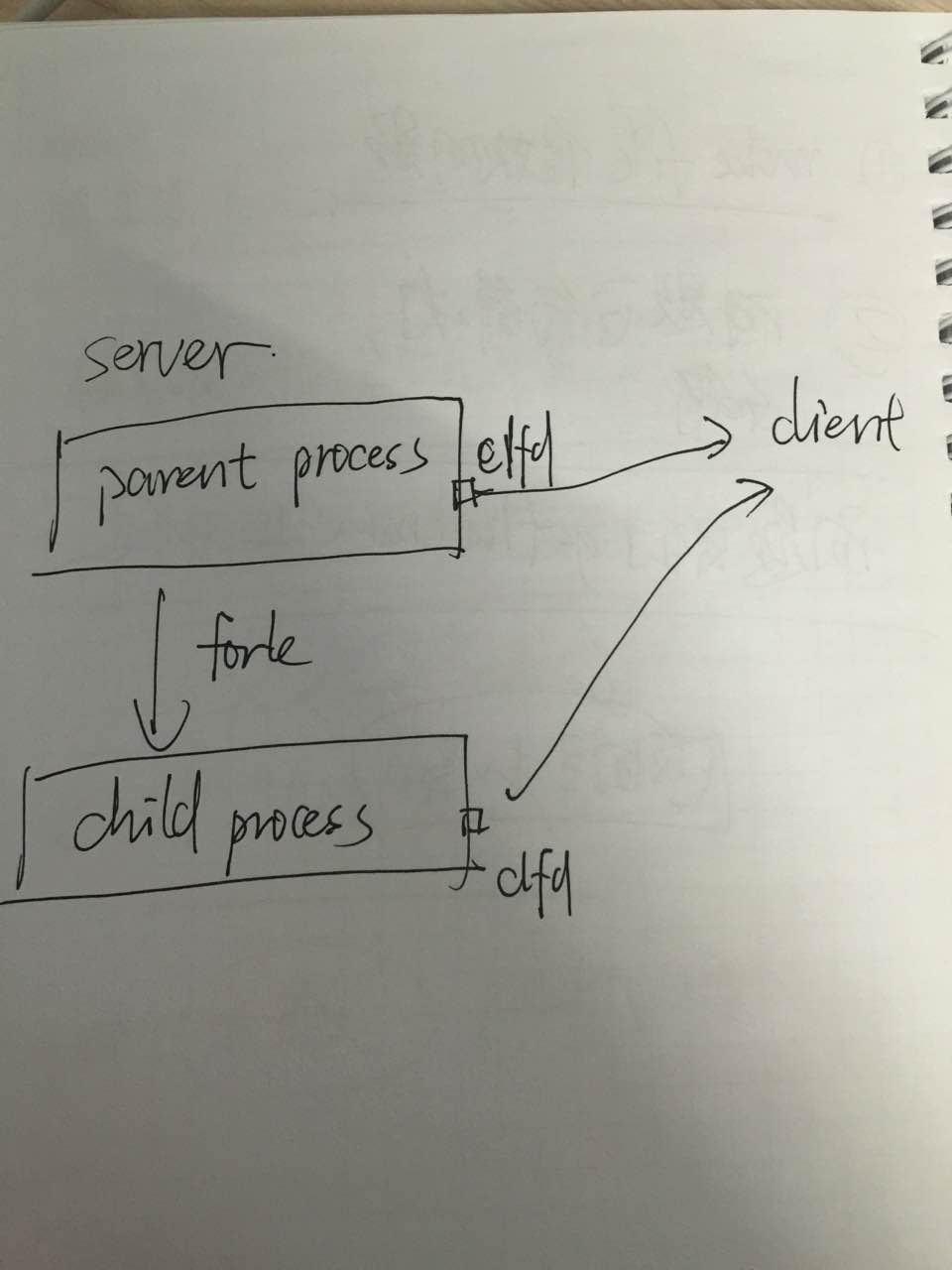
我们知道,child process的作用就是执行一个uptime command,是不需要跟client发生什么关联的。所以,可以通过set_cloexec这个函数来给clfd的flag置位。目的就是在fork+exec之后,将clfd给close了,这里的close并不是直接把sockfd给删除了,而是让其断开与某个client的联系。为了加深印象,截取了apue chapter 8的一段原文:

(3)另一种处理client请求的方式:fork+dup2。除了serve1函数中用pipe处理client请求的办法,在serve2中还介绍了一种fork+dup2的处理方法。
a. 先对比一下这serve1和serve2两种处理的方式:
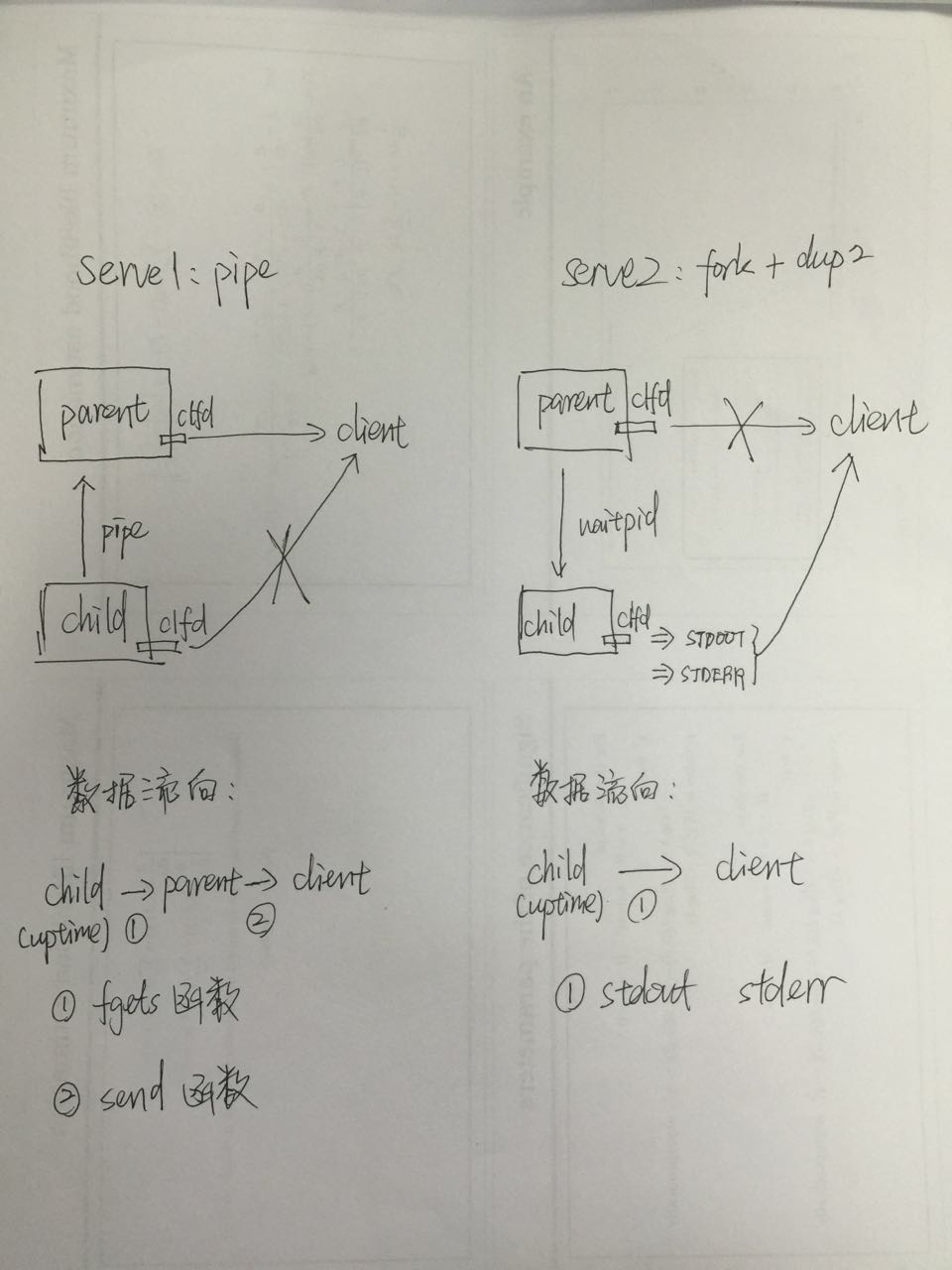
b. 分析一下serve2中fork+dup2方法的特点:减少了child到parent的数据传到中间过程,直接让child与client交换数据。书上还提到,如果child的执行时间太长,用serve2这种方式可能对效率产生影响。
c. 关于dup2的技术细节。回顾apue书上P543的popen函数实现(见之前chapter15 IPC的学习笔记http://www.cnblogs.com/xbf9xbf/p/5018177.html),凡是执行dup2(A, B)之前,都要检查A是否等于B。但是serve2中执行dup2函数却没有做这样的检查?不用检查的原因是因为clfd和STDOUT_FILENO以及STDERR_FILENO不可能相等。
(c1)在执行serve2之前已经执行了daemonize函数,daemonize函数的line66~78已经保证了0、1、2三个file descriptor都已经被占上了。因此child的file descriptor的0、1、2也都一定被占上了。
(c2)因此,再执行serve2的时候,0、1、2三个file descriptor都占上了,执行clfd = accept(..., ..., ...)的时候,系统要给clfd分配一个最小的非负可用的int值。显然0、1、2都已经被占上了,因此clfd至少从3开始取值,自然也就不可能和STDOUT(数值为1)、STDERR_FILENO(数值为2)冲突了。
这种技术细节要想理解,需要对daemonize的机制非常熟悉才可以。
2. client端做的事情就是:
(1)获取server端的IP和服务对应的port号(这里其实有点儿偷懒,因为server跟client是一台机器)
(2)用这个address执行socket和connect操作(如果一次不成功,就retry尝试connect)
(3)在connect成功后,用recv接收从server端发来的数据,并输出到终端
client.c文件如下:
#include "cs.h"
#include <netdb.h>
#include <errno.h>
#include <sys/socket.h> #define BUFLEN 128 //extern int connect_retry(int, int, int, const struct sockaddr *, socklen_t); void print_uptime(int sockfd)
{
int n;
char buf[BUFLEN];
while ((n=recv(sockfd, buf, BUFLEN, ))>) { /*从socket接收数据 直到全部收完为止*/
write(STDOUT_FILENO, buf, n);
}
if (n<) {
err_sys("recv error");
}
} int main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
int sockfd, err; if (argc != ) {
err_quit("usage: ruptime hostname");
}
memset(&hint, , sizeof(hint));
hint.ai_socktype = SOCK_STREAM;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL; if ((err = getaddrinfo(argv[],"ruptime", &hint, &ailist))!=) {
err_quit("getaddrinfo error: %s", gai_strerror(err));
}
for (aip=ailist; aip!=NULL; aip = aip->ai_next)
{
if ((sockfd = connect_retry(aip->ai_family, SOCK_STREAM,,aip->ai_addr,aip->ai_addrlen))<) {
err = errno;
}
else {
print_uptime(sockfd);
exit();
}
}
err_exit(err, "can't connect to %s", argv[]);
return -;
}
connect_retry.c文件具体如下:
#include "cs.h"
#include <sys/socket.h> #define MAXSLEEP 128 int connect_retry(int domain, int type, int protocol, const struct sockaddr *addr, socklen_t alen)
{
int numsec, fd;
for (numsec=; numsec<=MAXSLEEP; numsec<<=)
{
if ((fd = socket(domain, type, protocol))<) {
return -;
}
if (connect(fd, addr, alen)==) {
return fd;
}
close(fd);
if (numsec<=MAXSLEEP/) {
sleep(numsec);
}
}
return -;
}
client端的代码细节就是在connect_retry函数中,一旦一次连接不成功,并不能马上第二次连接:一是重新搞一个socket,二是等待一段时间再去connect。具体的原理参见apue书上P607。
上面讲述完了基于connection的client server通信的基本流程。
在server端,执行代码后可以看到多了一个守护进程(parent pid=1, tty=? ,pgid=sig典型的daemon process):
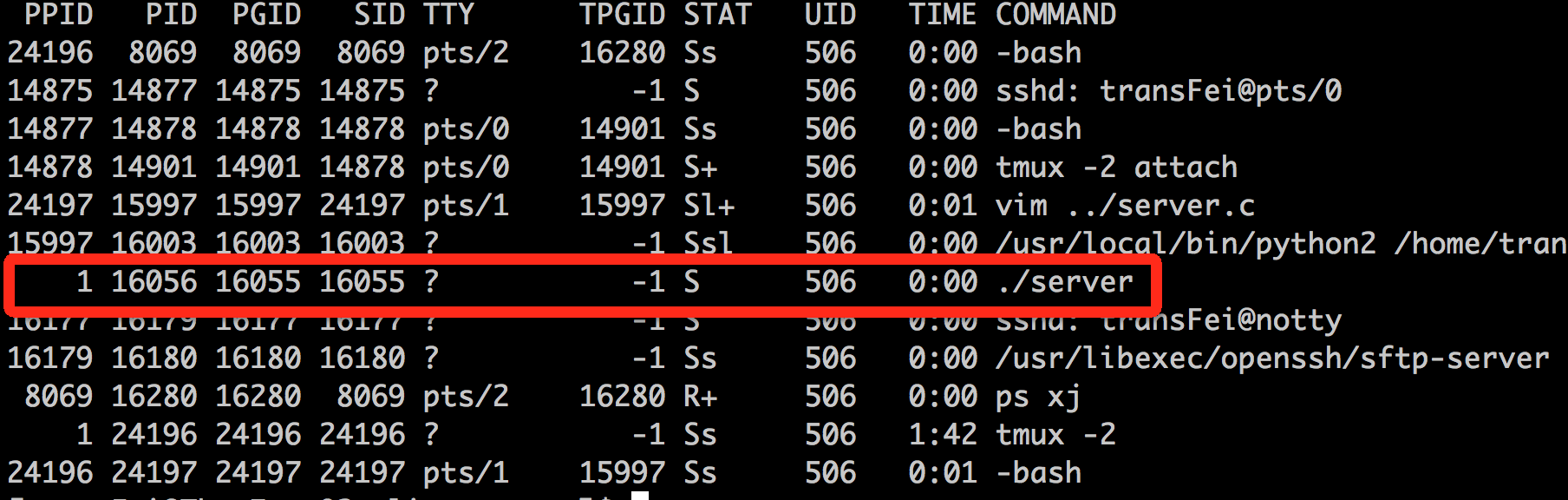
在client端,每执行一次代码,相当于向server端发送一个请求;接收到server返回的数据后,将结果显示到terminal上:

例子二,基于connectionless的server & client通信
对比connection的通信,connectionless通信少了connect和accept环节。
server端主要是server-dg.c代码:
#include "cs.h"
#include <netdb.h>
#include <errno.h>
#include <syslog.h>
#include <sys/wait.h> #define BUFLEN 128
#define MAXADDRLEN 256 #ifndef HOST_NAME_MAX
#define HOST_NAME_MAX 256
#endif void serve(int sockfd)
{
int n;
socklen_t alen;
FILE *fp;
char buf[BUFLEN];
char abuf[MAXADDRLEN];
struct sockaddr *addr = (struct sockaddr *)abuf; set_cloexec(sockfd);
for(;;)
{
alen = MAXADDRLEN;
/*1. 阻塞 等着client向这个地方发送数据
*2. 这里receive了多少数据不是关键 关键是获得client的addr信息*/
if ((n=recvfrom(sockfd,buf, BUFLEN, , addr, &alen))<) {
syslog(LOG_ERR, "ruptimed: recvfrom error: %s", strerror(errno));
exit();
}
if ((fp = popen("/usr/bin/uptime","r"))==NULL) {
/*出错了也知道往哪个client发送error信息*/
sprintf(buf, "error: %s\n", strerror(errno));
sendto(sockfd, buf, strlen(buf), , addr, alen);
}
else {
if (fgets(buf, BUFLEN, fp)!=NULL) {
sendto(sockfd, buf, strlen(buf), , addr, alen);
}
pclose(fp);
}
}
} int main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
int sockfd, err, n;
char *host; if (argc != ) {
err_quit("usage: ruptimed");
}
if ((n=sysconf(_SC_HOST_NAME_MAX))<) {
n = HOST_NAME_MAX;
}
if ((host=malloc(n))==NULL) {
err_sys("malloc error");
}
if (gethostname(host,n)<) {
err_sys("gethostname error");
}
host = "localhost";
daemonize("ruptimed");
memset(&hint, , sizeof(hint));
hint.ai_flags = AI_CANONNAME;
hint.ai_socktype = SOCK_DGRAM;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL;
if ((err = getaddrinfo(host, "ruptime", &hint, &ailist))!=) {
syslog(LOG_ERR, "ruptimed: getaddrinfo error: %s", gai_strerror(err));
exit();
}
for (aip = ailist; aip!=NULL; aip=aip->ai_next)
{
if ((sockfd = initserver(SOCK_DGRAM, aip->ai_addr, aip->ai_addrlen,))>=) {
serve(sockfd);
exit();
}
}
exit();
}
上述server端的代码,调用initserver.c文件中的函数,执行了listen操作之后,就直接可以执行recvfrom接收从client端发来的数据。(当然,这里是一个最简单的情况,只要n>0即证明收到client端的数据,就知道client端发送了请求,要求获得server端的uptime command命令执行结果)。
client端的代码client-dg.c如下:
#include "cs.h"
#include <netdb.h>
#include <errno.h>
#include <sys/socket.h> #define BUFLEN 128
#define TIMEOUT 20 void sigalrm(int signo){} void print_uptime(int sockfd, struct addrinfo *aip)
{
int n;
char buf[BUFLEN]; buf[] = ;
if (sendto(sockfd, buf, , , aip->ai_addr, aip->ai_addrlen)<) {
err_sys("sendto error");
}
alarm(TIMEOUT);
if ((n=recvfrom(sockfd, buf, BUFLEN, , NULL, NULL))<) {
if (errno!=EINTR) {
alarm();
err_sys("recv error");
}
}
alarm();
write(STDOUT_FILENO, buf, n);
} int main(int argc, char *argv[])
{
struct addrinfo *ailist, *aip;
struct addrinfo hint;
int sockfd, err;
struct sigaction sa; if (argc != ) {
err_quit("usage: ruptime hostname");
}
sa.sa_handler = sigalrm;
sa.sa_flags = ;
sigemptyset(&sa.sa_mask);
if (sigaction(SIGALRM, &sa, NULL)<) {
err_sys("sigaction error");
}
memset(&hint, , sizeof(hint));
hint.ai_socktype = SOCK_DGRAM;
hint.ai_canonname = NULL;
hint.ai_addr = NULL;
hint.ai_next = NULL;
if ((err = getaddrinfo(argv[], "ruptime", &hint, &ailist))!=) {
err_quit("getaddrinfo error: %s", gai_strerror(err));
}
for (aip = ailist; aip != NULL; aip = aip->ai_next)
{
if ((sockfd = socket(aip->ai_family, SOCK_DGRAM, ))<) {
err = errno;
}
else {
print_uptime(sockfd, aip);
exit();
}
} fprintf(stderr, "can't contact %s: %s\n", argv[], strerror(err));
exit();
}
可以看到,client端的代码,只产生了socket,然后就直接执行sendto操作,再执行recvfrom操作了。这中间并没有connect以及retry的过程。
这种connectionless的方式有两点需要注意:
第一,这种connectless的通信方式对应的一定不能是TCP,可以是UDP。
第二,在设定hint参数的时候应该是SOCK_DGRAM而不是SOCK_STREAM。
第三,在/etc/services中一定要给ruptime这个服务注册一个udp协议通信版本。
最后,上两个其余的文件cs.h文件,以及error.c错误处理函数文件,这两个文件都是后面写makefile用到的。
error.c文件如下:
#include "cs.h"
#include <string.h>
#include <errno.h> /* for definition of errno */
#include <stdarg.h> /* ISO C variable aruments */ #define MAXLINE 4096 static void err_doit(int, int, const char *, va_list); /*
* Nonfatal error related to a system call.
* Print a message and return.
*/
void
err_ret(const char *fmt, ...)
{
va_list ap; va_start(ap, fmt);
err_doit(, errno, fmt, ap);
va_end(ap);
} /*
* Fatal error related to a system call.
* Print a message and terminate.
*/
void
err_sys(const char *fmt, ...)
{
va_list ap; va_start(ap, fmt);
err_doit(, errno, fmt, ap);
va_end(ap);
exit();
} /*
* Nonfatal error unrelated to a system call.
* Error code passed as explict parameter.
* Print a message and return.
*/
void
err_cont(int error, const char *fmt, ...)
{
va_list ap; va_start(ap, fmt);
err_doit(, error, fmt, ap);
va_end(ap);
} /*
* Fatal error unrelated to a system call.
* Error code passed as explict parameter.
* Print a message and terminate.
*/
void
err_exit(int error, const char *fmt, ...)
{
va_list ap; va_start(ap, fmt);
err_doit(, error, fmt, ap);
va_end(ap);
exit();
} /*
* Fatal error related to a system call.
* Print a message, dump core, and terminate.
*/
void
err_dump(const char *fmt, ...)
{
va_list ap; va_start(ap, fmt);
err_doit(, errno, fmt, ap);
va_end(ap);
abort(); /* dump core and terminate */
exit(); /* shouldn't get here */
} /*
* Nonfatal error unrelated to a system call.
* Print a message and return.
*/
void
err_msg(const char *fmt, ...)
{
va_list ap; va_start(ap, fmt);
err_doit(, , fmt, ap);
va_end(ap);
} /*
* Fatal error unrelated to a system call.
* Print a message and terminate.
*/
void
err_quit(const char *fmt, ...)
{
va_list ap; va_start(ap, fmt);
err_doit(, , fmt, ap);
va_end(ap);
exit();
} /*
* Print a message and return to caller.
* Caller specifies "errnoflag".
*/
static void
err_doit(int errnoflag, int error, const char *fmt, va_list ap)
{
char buf[MAXLINE]; vsnprintf(buf, MAXLINE-, fmt, ap);
if (errnoflag)
snprintf(buf+strlen(buf), MAXLINE-strlen(buf)-, ": %s",
strerror(error));
strcat(buf, "\n");
fflush(stdout); /* in case stdout and stderr are the same */
fputs(buf, stderr);
fflush(NULL); /* flushes all stdio output streams */
}
cs.h文件如下:
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include <string.h>
#include <sys/socket.h> int connect_retry(int, int, int, const struct sockaddr*, socklen_t);
void daemonize(const char *);
void err_ret(const char *,...);
void err_sys(const char *,...);
void err_exit(int, const char *,...);
void err_quit(const char *,...);
int initserver(int, const struct sockaddr*, socklen_t, int);
int set_cloexec(int);
16.8 makefile学习
1. 学习驱动力
(1)之前一直得过且过,不想学写makefile,都是把各种函数丢进一个c文件就直接编译链接运行了。
(2)但是上面的代码各个函数实在太多了:像initserver.c属于4个程序公用的库函数,如果不单独提炼出来,别说维护了,调试4份代码都很麻烦。于是下决心学习一下makefile。
2. 学习的过程如下
(1)看教程。比较幸运,发现了这个非常好的针对makefile的wiki:http://wiki.ubuntu.org.cn/跟我一起写Makefile。对我这样的初学者来说,这个教程深入浅出,有驱动有例子,看这一个入门足以。大概一天时间扫了一遍,100页的教程。本来想多写一些makefile的东西,后来还是放弃了。一则时间不太够,二则上面这个wiki写的已经非常好了,看一遍再动手足以。
(2)尝试写一个简单的例子。这里我入门的就是给lib文件夹下(包括daemonize.c,initserver.c,error.c,setfd.c,connect_retry.c)写了一个makefile。在写的过程中回头再看教程,再加深一下理解,完善第一个makefile。
(3)尝试稍微复杂一些的例子。这里我就是将server client通信的所有代码都组织成一个工程文件夹中:具体包括include文件夹(只有cs.h),lib文件夹(包括上面提到的5个.c文件),以及根目录下的4个文件(server.c client.c server-dg.c client-dg.c)。为什么要这么设计结构,因为apue书上给的源码就是这么设计的文件夹的,我如果也这么设计文件夹结构,就可以学习apue作者的makefile的写法。这个阶段属于提高阶段,光参考教程已经不够了,必须参照一些高手的工作,模仿并体会。
3. makefile的好处
(1)方便。写好makefile之后,编译链接自动执行,只要在工程跟目录下一个make命令就OK了。
(2)高效。makefile会自动检测工程中哪个文件更新了,并只重新编译链接与更新过的那个文件相关的其他文件,没受影响的不用重新编译链接。
(3)便于维护。如果makefile设计的好,工程中新增加一个库函数之类的,只需要在makefile里面做少量的修改,整个工程其余的部分不需要多大改动就可以继续运行
4. 成果
最后把自己学习之后写的makefile成果记录一下。首先看一下工程的文件夹结构:
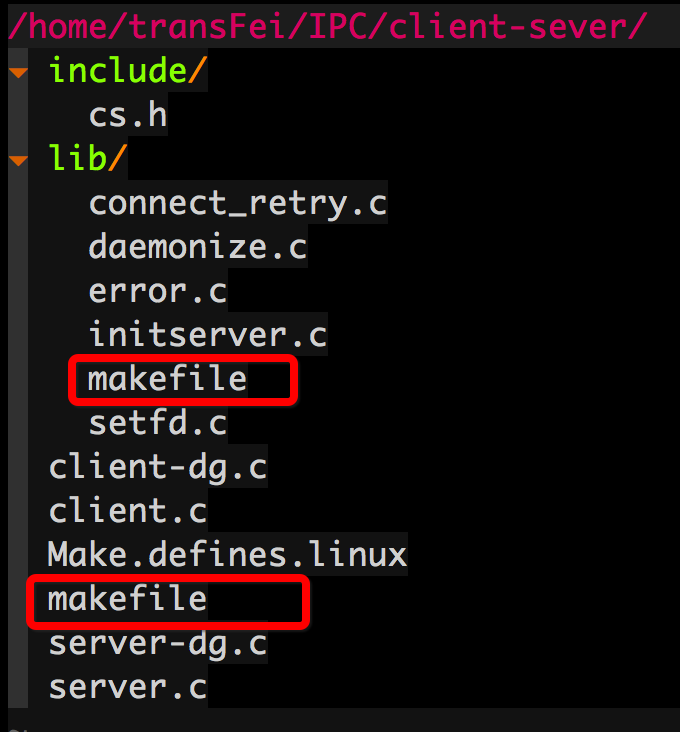
工程文件夹是client-server文件夹,其中包含lib和include两个子文件夹;各个文件夹的内容如上所示。
其中在lib目录下有一个makefile文件,这个makefile只管库函数的编译。最终的目标是将所有库函数都编译,并且封装到libcs.a的库文件中。
这个makefile的依赖关系比较简单,其内容如下所示(直接截图是vim彩色的,效果比直接文字黑白的看得清):

在工程根目录client-server文件夹下也有一个makefile,这个makefile是整个工程的总的makefile。即负责调用lib下的makefile编译库函数,而且负责检查工程中各个代码的依赖关系。其具体内容如下:
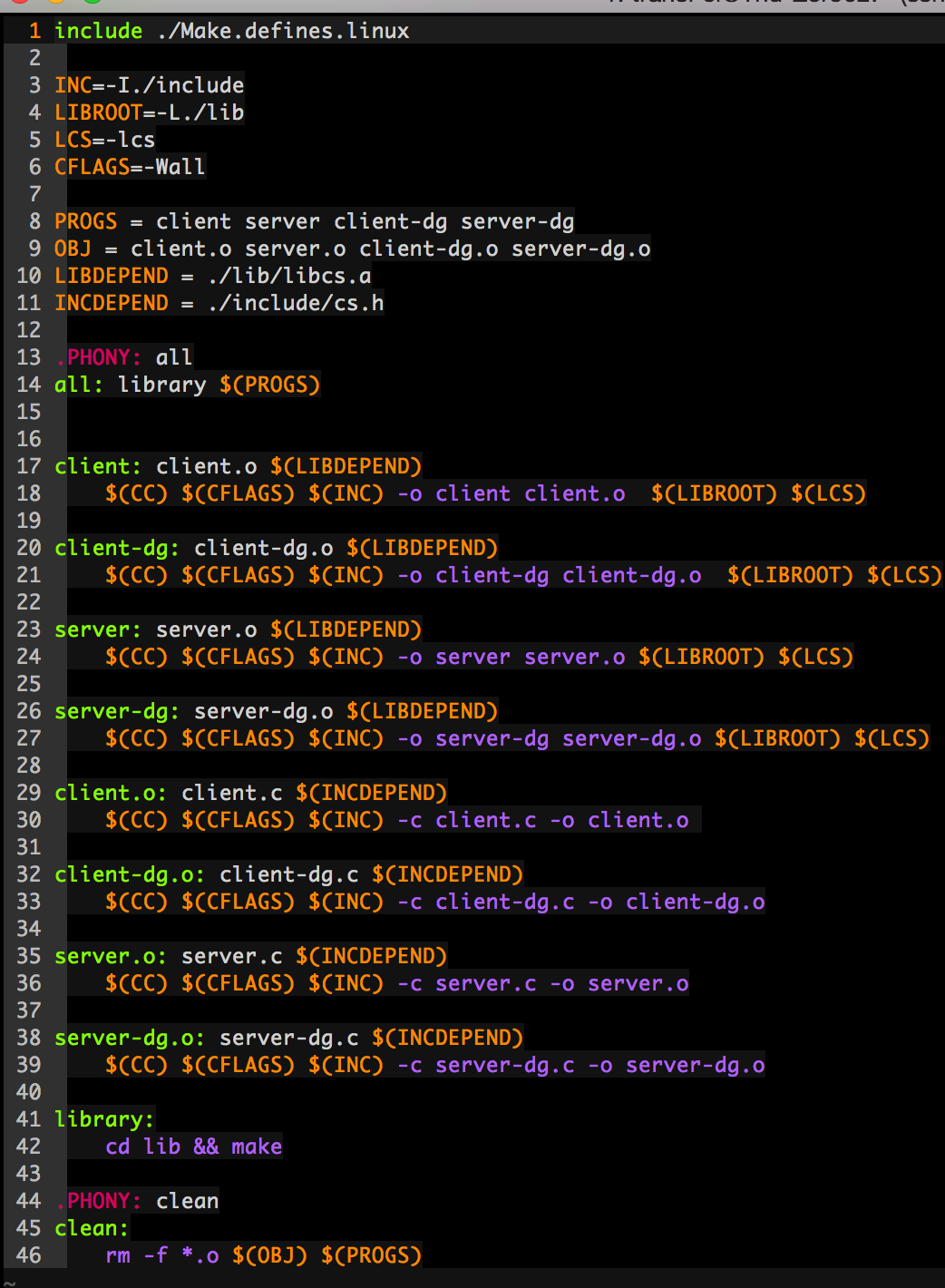
上面这个makefile写的过程还遇到写小问题,办法就是参照apue作者在书上源代码中写的makefile,模仿学习,并参照教材体会。这个makefile能实现基本的makefile的功能,但是设计上肯定还有很多可以改进的地方,留着以后再改。
最后还有一个文件,相当于是makefile的include文件,Make.defines.linux,内容如下:
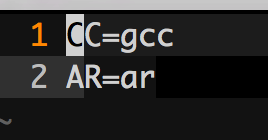
这个文件内容很简单,就是记录一些命令。其实还是效仿apue的作者写的,功能就是如果不同操作系统,这些参数可能会有所调整。
最后的最后再晒一下make的执行结果:
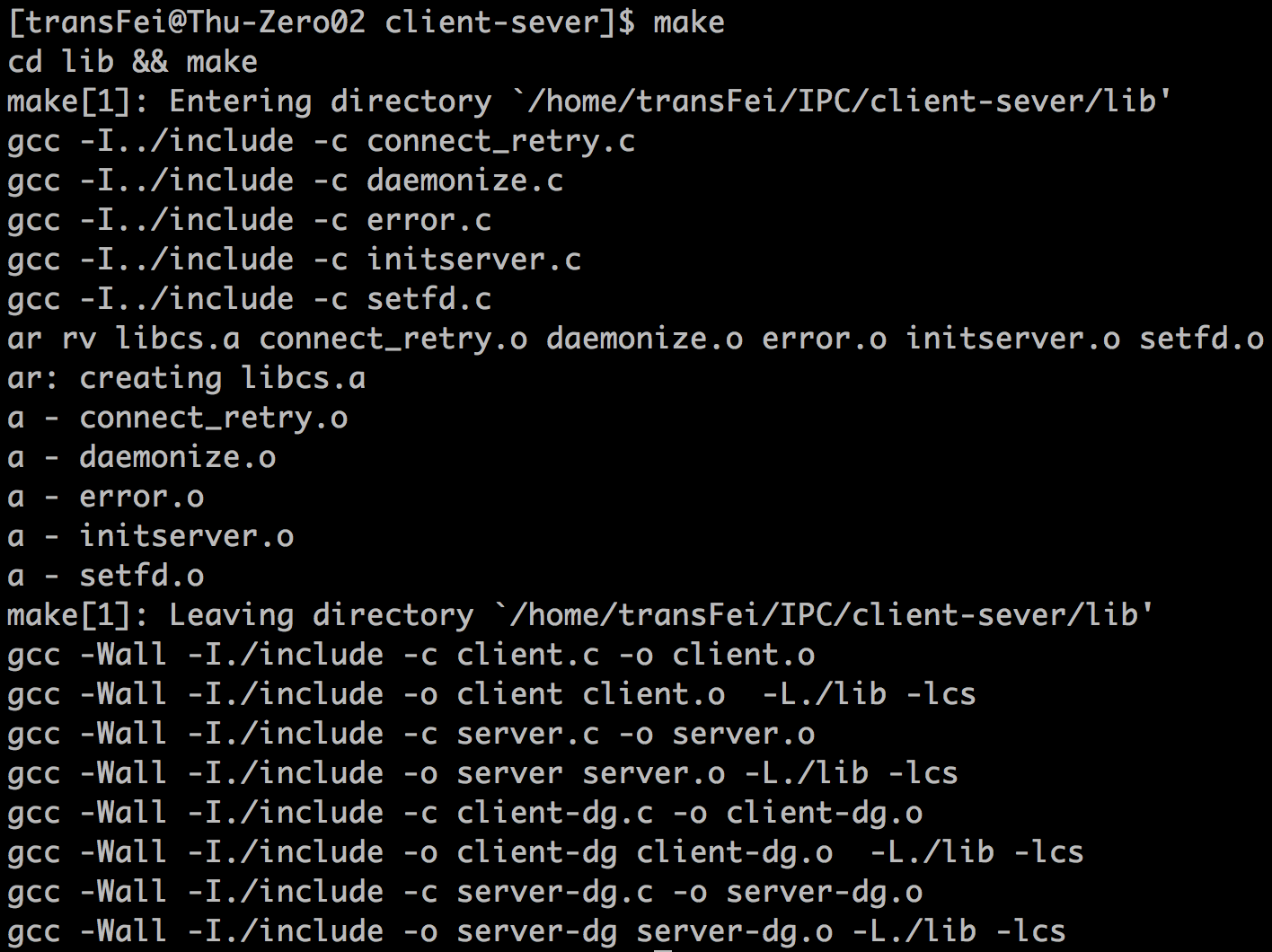
紧接着,如果我只对server.c文件做一些修改(加回车符),则再在根目录client-server下执行make效果如下:

可以看到,对其他文件没有重新编译,只对server.c及其相关的内容重新编译链接。
如果,我对lib/initserver.c中做些修改(还是加一个回车),则再在根目录client-server下执行make效果如下:
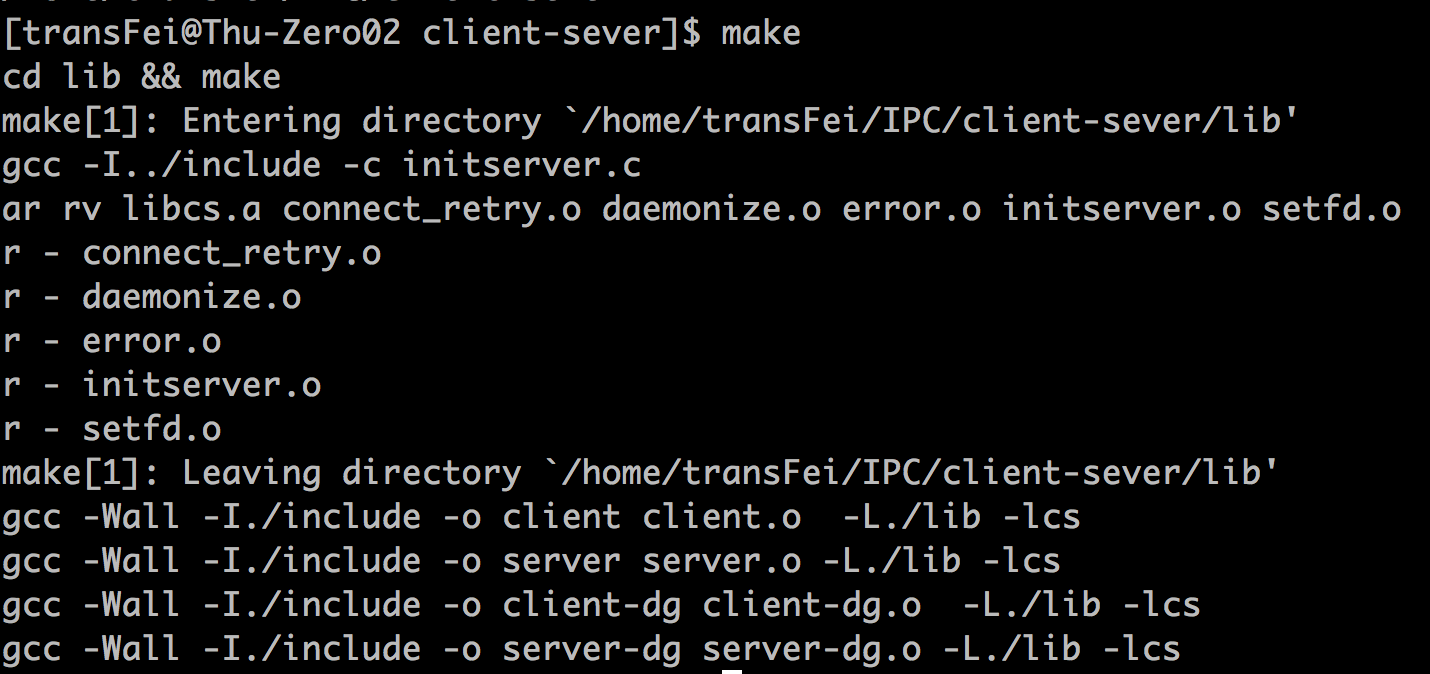
可以看到,首先lib中只有initserver.c文件重新编译了,并且libcs.a库文件重新打包了。又因为makefile中设定了根目录下四个程序与libcs.a的依赖关系,因此四个文件的链接过程全部重新执行了。但是,由于四个程序文件本身没有改动,所以四个文件的编译过程并么有重新执行。
通过上面的一些展示,可以感受写好makefile是很重要的,优秀的makefile设计可以给工程编译维护过程带来巨大的方便。
以上。
【APUE】Chapter16 Network IPC: Sockets & makefile写法学习的更多相关文章
- 转来的 cuda makefile 写法学习
原文作者:FreeAquar 原文出处:http://www.cnblogs.com/FreeAquar/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给 ...
- (十三) [终篇] 一起学 Unix 环境高级编程 (APUE) 之 网络 IPC:套接字
. . . . . 目录 (一) 一起学 Unix 环境高级编程 (APUE) 之 标准IO (二) 一起学 Unix 环境高级编程 (APUE) 之 文件 IO (三) 一起学 Unix 环境高级编 ...
- Unix 环境高级编程 (APUE) 之 网络 IPC:套接字
一起学 Unix 环境高级编程 (APUE) 之 网络 IPC:套接字 . . . . . 目录 (一) 一起学 Unix 环境高级编程 (APUE) 之 标准IO (二) 一起学 Unix 环境高级 ...
- Makefile基础学习
Makefile基础学习 理论知识 makefile关系到了整个工程的编译规则.一个工程中的源文件不计其数,并且按类型.功能.模块分别放在若干个目录中,makefile定义了一系列的规则来指定,哪些文 ...
- Makefile之写demo时的通用Makefile写法
Makefile之写demo时的通用Makefile写法[日期:2013-05-22] 来源:CSDN 作者:gqb666 [字体:大 中 小] 前面的一篇文章Makefile之大型工程项目子目录M ...
- Andrew's Blog / 《Network Programming with Go》学习笔记
第一章: Architecture(体系结构) Protocol Layers(协议层) ISO OSI Protocol 每层的功能: 网络层提供交换及路由技术 传输层提供了终端系统之间的数据透明传 ...
- Makefile的学习笔记
Makefile的学习笔记 标签: makefilewildcard扩展includeshellfile 2012-01-03 00:07 9586人阅读 评论(2) 收藏 举报 分类: Linux ...
- theos的makefile写法
theos的makefile写法与其他linux/unix环境下的makefile写法大同小异,但是对于makefile不熟悉的在导入一些dylib或者framework的时候就会变得很蛋疼. 对于f ...
- 运用Autoconf和Automake生成Makefile的学习之路
作为Linux下的程序开发人员,大家一定都遇到过Makefile,用make命令来编译自己写的程序确实是很方便.一般情况下,大家都是手工写一个简单Makefile,如果要想写出一个符合自由软件惯例的M ...
随机推荐
- HDU 4165 卡特兰
题意:有n个药片,每次吃半片,吃2n天,那么有多少种吃法. 分析:如果说吃半片,那么一定要吃过一整片,用 ) 表示吃半片,用 ( 表示吃整片,那么就是求一个正确的括号匹配方案数,即卡特兰数. 卡特兰数 ...
- 有趣的npx
在更新 npm 5.2.0 的时候发现会买一送一,自动安装了 npx. npx 会帮你执行依赖包里的二进制文件,也就是说 npx 会自动查找当前依赖包中的可执行文件, 如果找不到,就会去 PATH 里 ...
- 【洛谷P1272】 重建道路
重建道路 题目链接 一场可怕的地震后,人们用N个牲口棚(1≤N≤150,编号1..N)重建了农夫John的牧场.由于人们没有时间建设多余的道路,所以现在从一个牲口棚到另一个牲口棚的道路是惟一的.因此, ...
- 学习Node.js知识小结
什么是Node.js 官方解释:Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境. Node.js使用了一个事件驱动.非阻塞式I/O的模型( Node.js的特性 ...
- js 防抖 节流 JavaScript
实际工作中,通过监听某些事件,如scroll事件检测滚动位置,根据滚动位置显示返回顶部按钮:如resize事件,对某些自适应页面调整DOM的渲染:如keyup事件,监听文字输入并调用接口进行模糊匹配等 ...
- Python基础—01-认识python,编写第一个程序
认识python 发展历史:点此查看简介 就业方向: WEB.爬虫.运维.数据分析.机器学习.人工智能.... 版本选择 python2.7是最后一个py2的版本,2020年将不再提供支持 pytho ...
- [NOI2015]程序自动分析(并查集)
题目描述 在实现程序自动分析的过程中,常常需要判定一些约束条件是否能被同时满足. 考虑一个约束满足问题的简化版本:假设x1,x2,x3...代表程序中出现的变量,给定n个形如xi=xj或xi≠xj的变 ...
- .Net core NPOI导入导出Excel
最近在想.net core NPOI 导入导出Excel,一开始感觉挺简单的,后来真的遇到很多坑.所以还是写一篇博客让其他人少走一些弯路,也方便忘记了再重温一遍.好了,多的不说,直接开始吧. 在.Ne ...
- thinkphp5 分页带参数的解决办法
文档有说可以在paginate带参数,然后研究了下,大概就是这样的: $list=Db::name('member') ->where('member_name|member_mobile|se ...
- centos7中vsftp的搭建
开启vsftpd:service vsftpd start关闭vsftp:service vsftpd stop 安装vsftpd: yum -y install vsftpd 建立vsftpd帐号: ...