基于Python语言使用RabbitMQ消息队列(五)
Topics
在前面教程中我们改进了日志系统,相比较于使用fanout类型交易所只能傻瓜一样地广播,我们用direct获得了选择性接收日志的能力。
虽然使用direct类型交易所改进了我们的系统,但它仍然有所限制——它不能做基于多重条件(multiple criteria)的路由。
在日志系统中我们可能不只是想要基于严重级别来订阅日志。也想要基于产生日志的来源。你可能从unix的系统日志工具(syslog unix tool)知道了这个概念,它就是基于严重级别 (info/warn/crit…)和设施(auth/cron/kern…)来路由日志的。
这会给我们很大灵活性——我们可能只想监听来自于‘cron’的严重错误(critical errors)和来自‘kern’的所有日志。
为了在我们的日志系统中实现这个功能我们需要了解更复杂的topic类型交易所。
Topic 交易所
发往topic类型交易所的消息不能只有一个独断的路由键(routing_key)——它必须是个词汇列表,词与词之间由‘.’来界定。可以是任何词汇,但通常它们指定了一些与消息相关联的特性。一些有效的路由键例子:”stock.usd.nyse”, “nyse.vmw”, “quick.orange.rabbit”,只要你想,在路由键里可以加尽可能多的词汇,上限是255 bytes。
绑定键必须是同样的形式。topic交易所背后的逻辑与direct类似——使用特定路由键发送的消息会传递给所有拥有匹配的绑定键的队列。但对于绑定键有两种重要的特殊情形:
“*” (star) 正好代替一个词.
“#” (hash) 能代替零个或多个词.
可以很容易地用一个例子解释: 
在这个例子中我们发送的消息都是描述动物的。将要发送的消息的路由键包含三个词(两个点号)。第一个词描述的是敏捷性,第二个词是颜色,第三个词是种类:“<敏捷性>.<颜色>.<种类>”。
我们创建了三个绑定: Q1 绑定键是 “.orange.” , Q2 是 “..rabbit” 和 “lazy.#”.
这些绑定可以总结为:
- Q1 对所有橙色(orange)动物感兴趣.
- Q2想要知道关于rabbits的每件事情, 和关于lazy 类型动物的所有.
路由键设置为 “quick.orange.rabbit” 的消息会同时传送给两个队列。消息”lazy.orange.elephant” 也会传送给两个队列。”quick.orange.fox”会传送给第一个队列。”lazy.brown.fox”只会传送给第二个队列。”quick.brown.fox” 不匹配任何绑定,所以它会被忽略。
如果我们破坏约定,发送带有一个词或四个词的消息绑定,像”orange”或者”quick.orange.male.rabbit”,会发生什么呢?当然,由于这些消息不匹配任何绑定会被丢失。
另一方面即便 “lazy.orange.male.rabbit”, 有4个词,但它匹配最后一个绑定,所以它会被传送给第二个队列。
Topic 交易所
Topic 交易所很强大并且可以拥有其他类型交易所的的表现
当一个队列使用了“#”绑定键它就会接收所有消息,不管是什么路由键。此时就像是fanout类型交易所。 当在绑定中没有使用特殊字符 “*”
(star) 和 “#” (hash) topic交易所就跟direct交易所一样。
整合
我们将在日志系统中使用topic交易所。假设日志的路由键有两个词 “场所.严重级别”。
代码同之前的教程中几乎相同
emit_log_topic.py完整代码:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 2 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
receive_log_topic.py完整代码:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
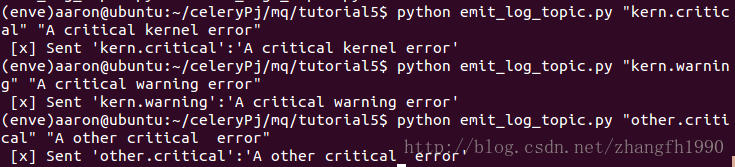
我在Ubuntu终端开启了四个控制台,其中三个接收日志,日志的接收和发送情况如图:
接收所有日志

接收级别为critical日志

接收产生自kernel日志

日志的发送
基于Python语言使用RabbitMQ消息队列(五)的更多相关文章
- 基于Python语言使用RabbitMQ消息队列(六)
远程过程调用(RPC) 在第二节里我们学会了如何使用工作队列在多个工人中分布时间消耗性任务. 但如果我们想要运行存在于远程计算机上的方法并等待返回结果该如何去做呢?这就不太一样了,这种模式就是常说的远 ...
- 基于Python语言使用RabbitMQ消息队列(一)
介绍 RabbitMQ 是一个消息中间人(broker): 它接收并且发送消息. 你可以把它想象成一个邮局: 当你把想要寄出的信放到邮筒里时, 你可以确定邮递员会把信件送到收信人那里. 在这个比喻中, ...
- 基于Python语言使用RabbitMQ消息队列(四)
路由 在上一节我们构建了一个简单的日志系统.我们能够广播消息给很多接收者. 在本节我们将给它添加一些特性——我们让它只订阅所有消息的子集.例如,我们只把严重错误(critical error)导入到日 ...
- 基于Python语言使用RabbitMQ消息队列(三)
发布/订阅 前面的教程中我们已经创建了一个工作队列.在一个工作队列背后的假设是每个任务恰好会传递给一个工人.在这一部分里我们会做一些完全不同的东西——我们会发送消息给多个消费者.这就是所谓的“发布/订 ...
- 基于Python语言使用RabbitMQ消息队列(二)
工作队列 在第一节我们写了程序来向命名队列发送和接收消息 .在本节我们会创建一个工作队列(Work Queue)用来在多个工人(worker)中分发时间消耗型任务(time-consuming tas ...
- python学习之-- RabbitMQ 消息队列
记录:异步网络框架:twisted学习参考:www.cnblogs.com/alex3714/articles/5248247.html RabbitMQ 模块 <消息队列> 先说明:py ...
- Python并发编程-RabbitMQ消息队列
RabbitMQ队列 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. MQ全称为Message Queue, 消息队列 ...
- Python RabbitMQ消息队列
python内的队列queue 线程 queue:不同线程交互,不能夸进程 进程 queue:只能用于父进程与子进程,或者同一父进程下的多个子进程,进行交互 注:不同的两个独立进程是不能交互的. ...
- 基于ASP.NET Core 5.0使用RabbitMQ消息队列实现事件总线(EventBus)
文章阅读请前先参考看一下 https://www.cnblogs.com/hudean/p/13858285.html 安装RabbitMQ消息队列软件与了解C#中如何使用RabbitMQ 和 htt ...
随机推荐
- 实用篇如何使用github(本地、远程)满足基本需求
一.结构: |--工作区 |--版本库 |--stage——add,可以每个添加到暂存区 |--master——commit 一次性提交到版本库 ...
- OpenGL纹理上下颠倒翻转的三种解决办法
http://blog.csdn.net/narutojzm1/article/details/51940817 综述 在使用OpenGL函数加载纹理到图形时,经常遇到纹理上下颠倒的问题.原因是因为O ...
- 网络:W5500 UDP数据包格式注意事项
1. 主题 使用W5500测试UDP功能,发现收到的数据包和wireshark抓包的数据不同. 原来W5500接收寄存器的数据包并不是网络上的数据流,而是经过内部处理后展现出来的. 对于这个问题目前 ...
- Django基础知识MTV
Django简介 Django是使用Python编写的一个开源Web框架.可以用它来快速搭建一个高性能的网站. Django也是一个MVC框架.但是在Django中,控制器接受用户输入的部分由框架自行 ...
- goseq
goseq是一个R包,用于寻找GO terms,即基因富集分析. GO terms是标准化描述基因或基因产物的词汇,包括三方面,cellular component,molecular funcito ...
- nodejs文件追加内容
const fs = require("fs"); // fs.appendFile 追加文件内容 // 1, 参数1:表示要向那个文件追加内容,只一个文件的路径 // 2, 参数 ...
- INSPIRED启示录 读书笔记 - 第34章 恐惧、贪婪、欲望
消费者购买产品大多源于情感需求 企业级消费者出于恐惧和贪婪购买产品:如果不买这款产品,竞争对手会超过我,黑客会攻破我的防火墙,客户将弃我而去:如果买了,会赚得更多,省得更多 大众消费者购买产品的原因更 ...
- L1范数与L2范数正则化
2018-1-26 虽然我们不断追求更好的模型泛化力,但是因为未知数据无法预测,所以又期望模型可以充分利用训练数据,避免欠拟合.这就要求在增加模型复杂度.提高在可观测数据上的性能表现得同时,又需要兼顾 ...
- Kubernetes 部署Weave Scope监控
yaml下载地址: https://cloud.weave.works/k8s/scope.yaml?k8s-version=? 目前有以下几个版本: ["v1.4"," ...
- HDU 2430 Beans (单调队列+公式化简)
题意:给你n袋豆子,每袋都有w[i]个豆子,接着任选连续任意个袋子的豆子合在一起放入容量为p的多个袋子里(每个袋子必须放满),问剩余的豆子数<=k时,能放满最多的袋子的个数 题解:个数与p都比较 ...