solr6.6 配置自带中文分词
1、配置solrconfig.xml
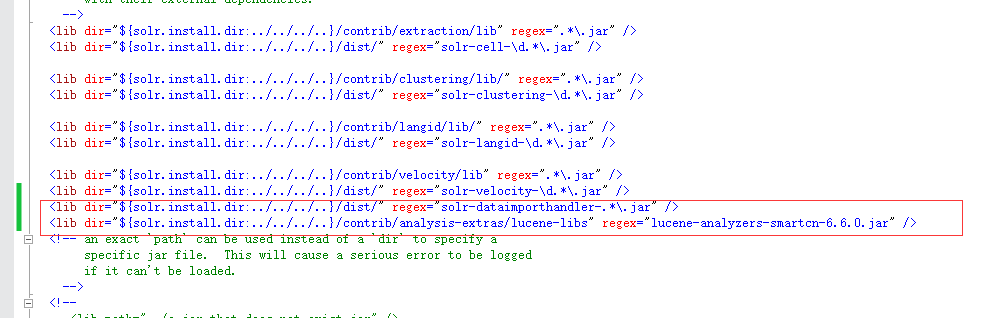
solr的自带中文分词包在solr-6.6.0\contrib\analysis-extras\lucene-libs下

修改solrconfig.xml增加
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*\.jar" />
<lib dir="${solr.install.dir:../../../..}/contrib/analysis-extras/lucene-libs" regex="lucene-analyzers-smartcn-6.6.0.jar" />
2、配置data-config.xml
建立data-config.xml文件,配置如下:
<dataConfig>
<dataSource type="BinFileDataSource"/>
<document>
<entity name="file" processor="FileListEntityProcessor" dataSource="null"
baseDir="D:/work/Solr/Import" fileName=".(doc)|(pdf)|(docx)|(txt)|(csv)|(json)|(xml)|(pptx)|(pptx)|(ppt)|(xls)|(xlsx)"
rootEntity="false"> <field column="file" name="id"/>
<!--<field column="file" name="fileType"/>
<field column="fileSize" name="fileSize"/>
<field column="fileLastModified" name="fileLastModified"/>
<field column="fileAbsolutePath" name="fileAbsolutePath"/>-->
<entity name="pdf" processor="TikaEntityProcessor"
url="${file.fileAbsolutePath}" format="text"> <field column="Author" name="author" meta="true"/>
<!-- in the original PDF, the Author meta-field name is upper-cased,
but in Solr schema it is lower-cased
--> <field column="title" name="title" meta="true"/>
<field column="text" name="text"/>
</entity>
</entity>
</document>
</dataConfig>
再修改solrconfig.xml配置文件,增加如下内容
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
3、修改配置文件
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
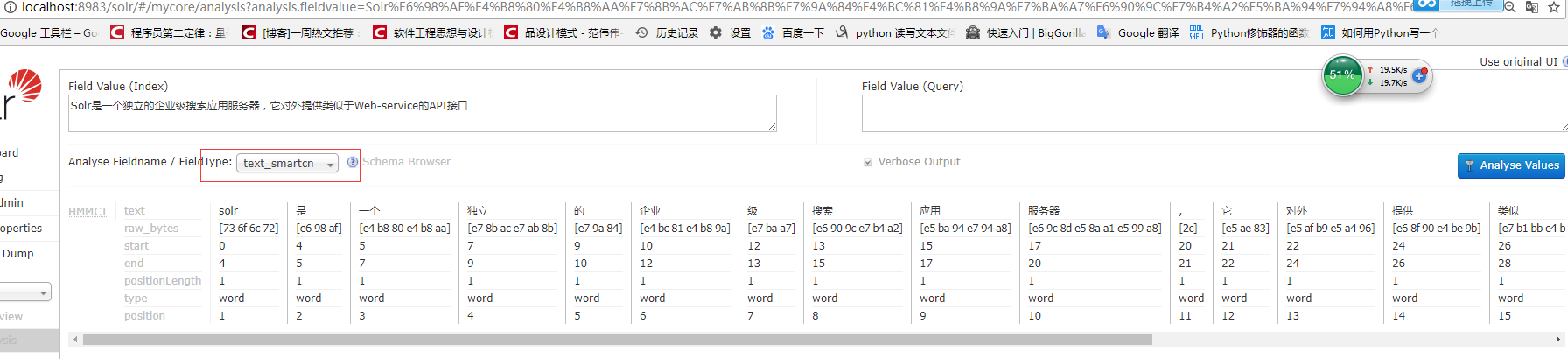
3、测试分析
solr6.6 配置自带中文分词的更多相关文章
- Solr6.6.0添加IK中文分词器
IK分词器就是一款中国人开发的,扩展性很好的中文分词器,它支持扩展词库,可以自己定制分词项,这对中文分词无疑是友好的. jar包下载链接:http://pan.baidu.com/s/1o85I15o ...
- solr 中文分词器IKAnalyzer和拼音分词器pinyin
solr分词过程: Solr Admin中,选择Analysis,在FieldType中,选择text_en 左边框输入 “冬天到了天气冷了小明不想上学去了”,点击右边的按钮,发现对每个字都进行分词. ...
- Solr6.5配置中文分词IKAnalyzer和拼音分词pinyinAnalyzer (二)
之前在 Solr6.5在Centos6上的安装与配置 (一) 一文中介绍了solr6.5的安装.这篇文章主要介绍创建Solr的Core并配置中文IKAnalyzer分词和拼音检索. 一.创建Core: ...
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- Solr5.5.1 IK中文分词配置与使用
前言 用过Lucene.net的都知道,我们自己搭建索引服务器时和解决搜索匹配度的问题都用到过盘古分词.其中包含一个词典. 那么既然用到了这种国际化的框架,那么就避免不了中文分词.尤其是国内特殊行业比 ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- (转)全文检索技术学习(三)——Lucene支持中文分词
http://blog.csdn.net/yerenyuan_pku/article/details/72591778 分析器(Analyzer)的执行过程 如下图是语汇单元的生成过程: 从一个Re ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
随机推荐
- 进一步认识golang中的并发
如果你成天与编程为伍,那么并发这个名词对你而言一定特别耳熟.需要并发的场景太多了,例如一个聊天程序,如果你想让这个聊天程序能够同时接收信息和发送信息,就一定会用到并发,无论那是什么样的并发. 并发的意 ...
- linux驱动基础系列--Linux I2c驱动分析
前言 主要是想对Linux I2c驱动框架有一个整体的把控,因此会忽略协议上的某些细节,同时里面涉及到的一些驱动基础,比如平台驱动.设备模型.sysfs等也不进行详细说明原理,涉及到i2c协议部分也只 ...
- jQuery鼠标悬停文字渐隐渐现动画效果
jQuery鼠标悬停文字渐隐渐现动画效果 当时是做项目的时候用到的所以图片有些大,九张,真正要做图片不需要这么大 css样式 <style> *{ margin: 0; padding: ...
- Appium+python自动化28-name定位【转载】
本篇转自博客:上海-悠悠 前言 appium1.5以下老的版本是可以通过name定位的,新版本从1.5以后都不支持name定位了 一. name定位报错 1.最新版appium V1.7用name定位 ...
- serialVersionUID的作用(zz)
http://www.cnblogs.com/guanghuiqq/archive/2012/07/18/2597036.html 简单来说,Java的序列化机制是通过在运行时判断类的serialVe ...
- spring 整合Junit
主要参考: https://www.ibm.com/developerworks/cn/java/j-lo-springunitest/ http://www.cnblogs.com/rainisic ...
- WebApi 的三种寄宿方式 (二) - 宿主和控制器不在一个程序集
新建一个类库: SelfHost: 方法一: 1.添加对MyControllers类库的引用. 2.在控制台代码中加入一行代码: 当然,可以添加多个程序集.(记得引用) var config = ne ...
- Web应用漏洞评估工具Paros
Web应用漏洞评估工具Paros Paros是Kali Linux集成的一款Web应用漏洞评估工具.该工具提供HTTP会话分析.网络爬虫.漏洞扫描三大功能.首先借助HTTP代理模式,该工具可以实时 ...
- [COGS2479 && COGS2639]高维偏序(CDQ分治,bitset)
COGS2479:四维偏序. CDQ套CDQ CDQ:对a分治,对b排序,再对a打标记,然后执行CDQ2 CDQ2:对b分治,对c归并排序,对d树状数组. #include<cstdio> ...
- 【可持久化Trie】模板
总算找到个能看懂的了,orz Lavender. #define INF 2147483647 #define N 100001 #define MAXBIT 31 int root[N],ch[N* ...