Facebook 新开源了 2 个东西,一个语音识别系统(wav2letter++)和一个机器学习库(flashlight)
A new fully convolutional approach to automatic speech recognition and wav2letter++, the fastest state-of-the-art end-to-end speech recognition system available. The approach leverages convolutional neural networks (CNNs) for acoustic modeling and language modeling, and is reproducible, thanks to the toolkits we are releasing jointly.
HOW IT WORKS:
CNN architectures are competitive with recurrent architectures for tasks in which modeling long-range dependencies is important, such as language modeling, machine translation, and speech synthesis. In end-to-end speech recognition, however, recurrent architectures are still more prevalent for both acoustic and language modeling.
The Facebook AI Research (FAIR) Speech team is sharing the first fully convolutional speech recognition system. From the waveform to the final word transcription, the learnable parts of the system are composed only of convolutional layers. This yields performance that’s competitive with that of recurrent architectures.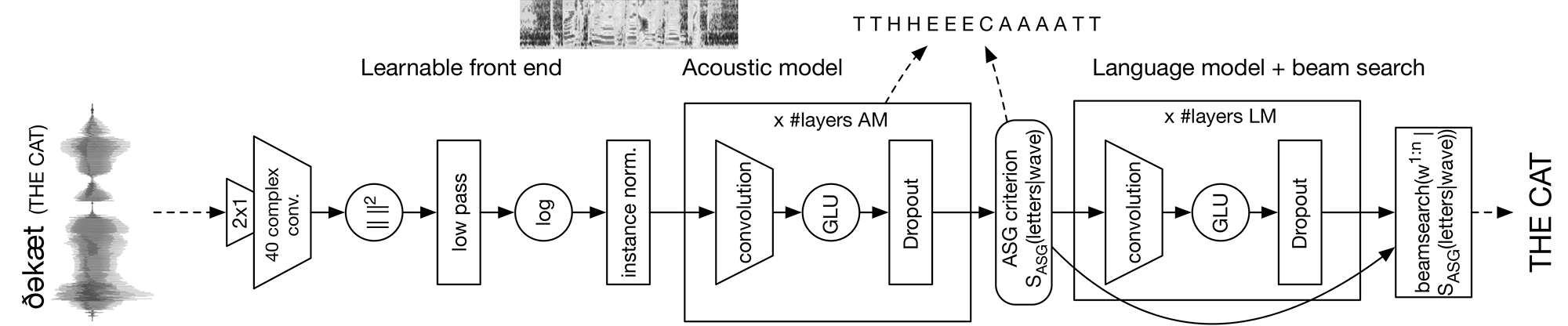
We are also releasing flashlight, a fast, flexible standalone machine learning library designed by the FAIR Speech team and the creators of Torch and DeepSpeech. It features just-in-time compilation with modern C++, targeting both CPU and GPU backends for maximum efficiency and scale. The wav2letter++ toolkit is built on top of flashlight. We are releasing both frameworks jointly with this research to enable reproducibility.
WHY IT MATTERS:
End-to-end speech recognition makes it easy to scale to multiple languages. Also, learning directly from raw speech is a promising avenue in settings where audio quality is highly variable. High-performance frameworks such as wav2letter++ enable fast iteration, which is often an important factor in successful research and model tuning on new data sets and tasks.
READ THE FULL PAPERS:
Wav2letter++: The fastest open source speech recognition system and Fully Convolutional Speech Recognition
Facebook 新开源了 2 个东西,一个语音识别系统(wav2letter++)和一个机器学习库(flashlight)的更多相关文章
- 一个iOS6系统bug+一个iOS7系统bug
先看实际工作中遇到的两个bug:(1)iPhone Qzone有一个导航栏背景随着页面滑动而渐变的体验,当页面滑动到一定距离时,会改变导航栏上title文本的颜色,但是有一个莫名其妙的bug,如下:
- Facebook开源最先进的语音系统wav2letter++
最近,Facebook AI Research(FAIR)宣布了第一个全收敛语音识别工具包wav2letter++.该系统基于完全卷积方法进行语音识别,训练语音识别端到端神经网络的速度是其他框架的两倍 ...
- 三个小白是如何在三个月内搭一个基于kaldi的嵌入式在线语音识别系统的
前面的博客里说过最近几个月我从传统语音(语音通信)切到了智能语音(语音识别).刚开始是学语音识别领域的基础知识,学了后把自己学到的写了PPT给组内同学做了presentation(语音识别传统方法(G ...
- 如何设计一个RPC系统
版权声明:本文由韩伟原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/162 来源:腾云阁 https://www.qclou ...
- 利用微软Speech SDK 5.1开发语音识别系统主要步骤
利用微软Speech SDK 5.1开发语音识别系统主要步骤 2009-09-17 10:21:09| 分类: 知识点滴|字号 订阅 微软语音识别分两种模式:文本识别模式和命令识别模式.此两种模式的 ...
- 开源语音识别系统 Simon
http://www.lupaworld.com/proj.php?mod=view&cid=&id=824 语音识别系统 Simon:Simon 是一个开源的语音识别系统,它不仅可以 ...
- PocketSphinx语音识别系统语言模型的训练和声学模型的改进
PocketSphinx语音识别系统语言模型的训练和声学模型的改进 zouxy09@qq.com http://blog.csdn.net/zouxy09 关于语音识别的基础知识和sphinx的知识, ...
- 使用monit搭建一个监控系统
上周用monit搭建或者说定制了一个监控系统,来监控服务器发生事情.当然了主要是监控异常,因为我们的产品属于服务器类型,很多进程都daemon,要不停的运行.我们搭建监控目的不过是出现问题能够及时的知 ...
- 用vue开发一个app(4,一个久等了的文章)H5直播平台登录注册(1)
我上一篇关于vue的文章和这一篇时间隔了有点久了.最近终于写完了. 因为我一直想写个有点实绩的东西,而不是随便写一个教程一样东西.结合最近在项目中学到的经验和我的一点创意. 首先介绍下这是个什么! H ...
随机推荐
- HDU - 3652 数位DP 套路题
题意:统计能被13整除和含有13的数的个数 解法没法好说的..学了前面两道直接啪出来了 PS.HDU深夜日常维护,没法交题,拿网上的代码随便对拍一下,输出一致 #include<bits/std ...
- FLUENT 流体计算应用教程
温正 清华大学出版 2013.1 子谓颜渊曰,用之则行,舍之则藏,惟我与尔有是夫! 非常合适的一本书. ...
- sublim text3中的一些设置
{ "dictionary": "Packages/Language - English/en_US.dic", "font_face&q ...
- PHP sprintf() 函数
PHP sprintf() 函数 先说下为什么要写这个函数的前言,这个是我在微信二次开发的一个token验证文档也就是示例文档看到的一个函数,当时非常不理解,于是查了百度,但是很多结果都很笼统,结果也 ...
- Maven系统学习
1. 1.1 何为构建? 编译.测试.运行.打包.部署等工作: Maven就是用软件的办法让这一系列工作自动化,只需要一条简单的命令,所有繁琐的工作就会自动完成: Maven最大的消除了构建的重复,抽 ...
- 理解 glibc malloc:主流用户态内存分配器实现原理
https://blog.csdn.net/maokelong95/article/details/51989081 Understanding glibc malloc 修订日志: 2017-03- ...
- [转]一种可以避免数据迁移的分库分表scale-out扩容方式
原文地址:http://jm-blog.aliapp.com/?p=590 目前绝大多数应用采取的两种分库分表规则 mod方式 dayofweek系列日期方式(所有星期1的数据在一个库/表,或所有?月 ...
- uwsgi服务启动、关闭、重启操作
1. 添加uwsgi相关文件 在之前的文章跟讲到过centos中搭建nginx+uwsgi+flask运行环境,本节就基于那一次的配置进行说明. 在www中创建uwsgi文件夹,用来存放uw ...
- mysql赋值表结构和数据
mysql中用命令行复制表结构的方法主要有一下几种: 1.只复制表结构到新表 CREATE TABLE 新表 SELECT * FROM 旧表 WHERE 1=2 或者 CREATE TABLE 新表 ...
- linux基础-wget、apt-get、yum的区别
Linux操作系统下安装与下载软件是Linux非常基本也非常重要的命令,分清wget.apt-get.yum的区别很重要. Linux操作系统主要分为两大类: RedHat系列:Redhat.Cent ...