智联招聘的python岗位数据结巴分词(一)
如何获取数据点击这里
- 下载之后的文件名为:all_results.csv
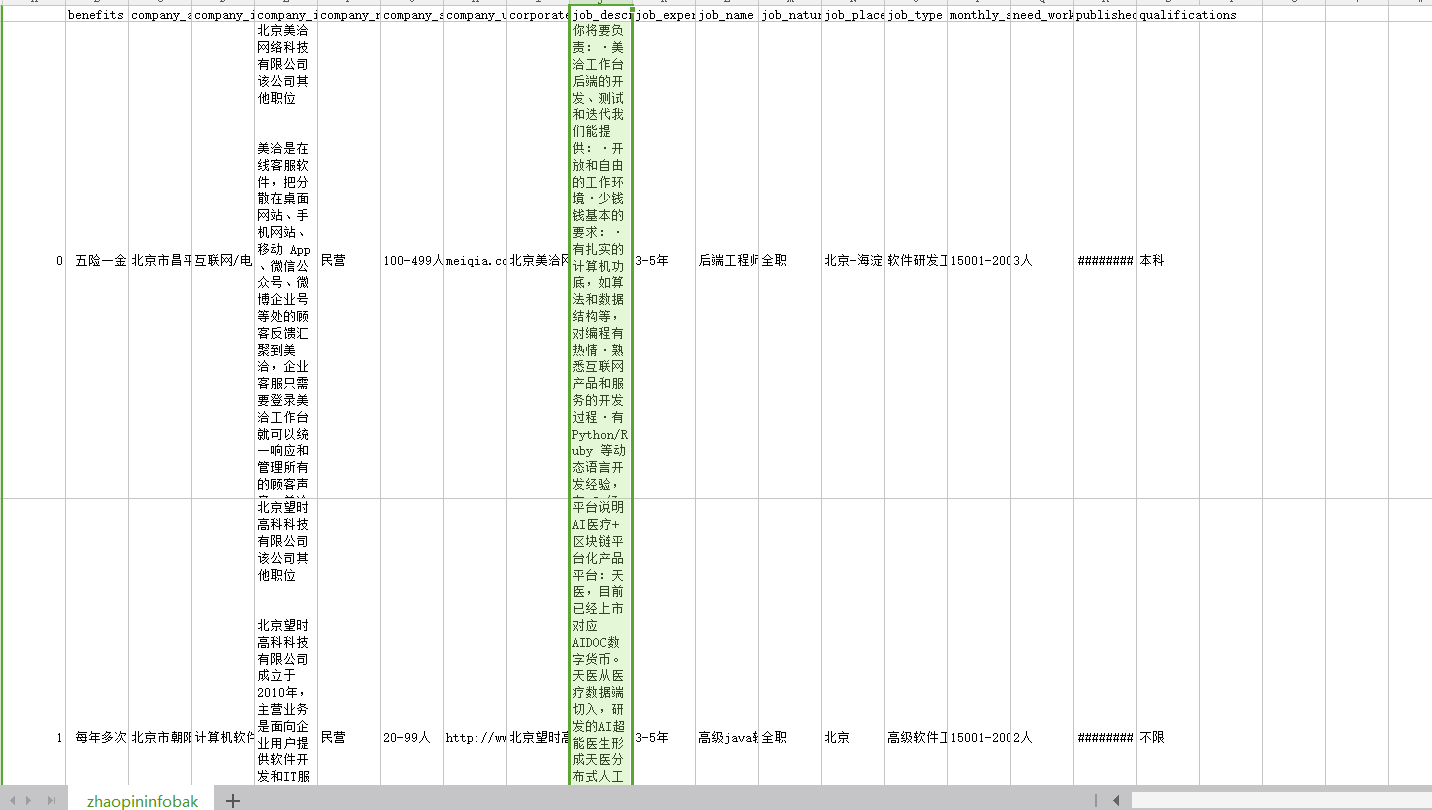
数据样式大概这样。然后下面我分析的是工作要求 也就是那边的绿框那一列。
- import csv
- import os
- import jieba
- import jieba.posseg as psg #posseg模块可以获取词性
- datapath=os.path.join(os.getcwd(),"all_results.csv")
- with open(datapath,'r',newline='',encoding='utf-8') as csvfile:
- # rows=csv.reader(csvfile)
- # headers = next(rows)
- # for i ,row in enumerate(rows):
- # if i%50==0:
- # print("正在处理第{}行数据".format(i))
- # job_required=row[8]
- # job_requirednew=job_required.strip().replace(" ","")
- # result_list.append(job_requirednew)
- rows=csv.DictReader(csvfile)
- result_list=[row['job_description'].strip().replace('\xa0','').replace('\r\n','') for row in rows]
- info_attr = [(x.word,x.flag) for x in psg.cut(''.join(result_list)) if len(x.word) >= 2] # 这里的x.word为词本身,x.flag为词性
- with open('out.txt','w+') as f:
- for x in info_attr:
- f.write('{0}\t{1}\n'.format(x[0],x[1]))
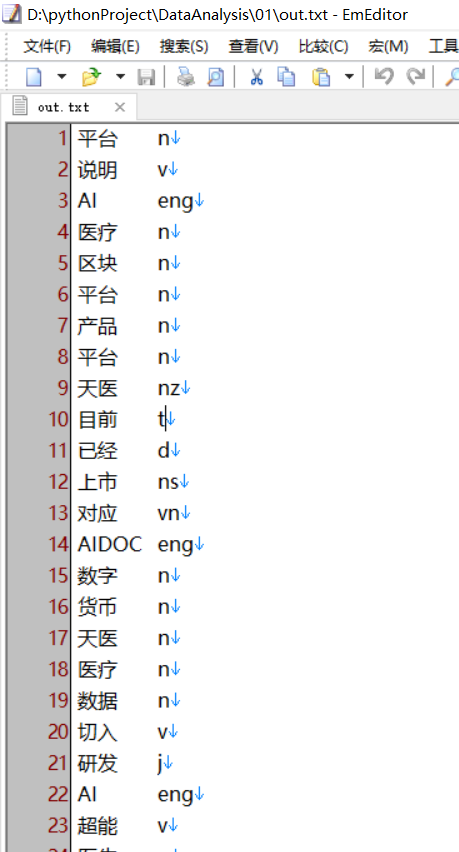
运行完上面的程序得到的文件结构如下
智联招聘的python岗位数据结巴分词(一)的更多相关文章
- 智联招聘的python岗位数据结巴分词(二)
上次获取第一次分词之后的内容了 但是数据数据量太大了 ,这时候有个模块就派上用场了collections模块的Counter类 Counter类:为hashable对象计数,是字典的子类. 然后使用m ...
- 智联招聘的python岗位数据词云制作
# 根据传入的背景图片路径和词频字典.字体文件,生成指定名称的词云图片 def generate_word_cloud(img_bg_path, top_words_with_freq, font_p ...
- 智联招聘获取python岗位的数据
import requests from lxml import html import time import pandas as pd from sqlalchemy import create_ ...
- 用python抓取智联招聘信息并存入excel
用python抓取智联招聘信息并存入excel tags:python 智联招聘导出excel 引言:前一阵子是人们俗称的金三银四,跳槽的小朋友很多,我觉得每个人都应该给自己做一下规划,根据自己的进步 ...
- Python+selenium爬取智联招聘的职位信息
整个爬虫是基于selenium和Python来运行的,运行需要的包 mysql,matplotlib,selenium 需要安装selenium火狐浏览器驱动,百度的搜寻. 整个爬虫是模块化组织的,不 ...
- 用生产者消费模型爬取智联招聘python岗位信息
爬取python岗位智联招聘 这里爬取北京地区岗位招聘python岗位,并存入EXECEL文件内,代码如下: import json import xlwt import requests from ...
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- python爬取智联招聘职位信息(多进程)
测试了下,采用单进程爬取5000条数据大概需要22分钟,速度太慢了点.我们把脚本改进下,采用多进程. 首先获取所有要爬取的URL,在这里不建议使用集合,字典或列表的数据类型来保存这些URL,因为数据量 ...
- python爬取智联招聘职位信息(单进程)
我们先通过百度搜索智联招聘,进入智联招聘官网,一看,傻眼了,需要登录才能查看招聘信息 没办法,用账号登录进去,登录后的网页如下: 输入职位名称点击搜索,显示如下网页: 把这个URL:https://s ...
随机推荐
- Floatingip
浮动IP相关功能点: 模块 功能 描述 备注 FloatingIP 创建浮动IP 指定带宽大小创建单个/多个浮动IP 指定子网.指定IP创建浮动IP 绑定浮动IP,修改带宽 绑定浮动IP到指定 ...
- Paper Reading - Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge
Link of the Paper: https://arxiv.org/abs/1609.06647 A Correlative Paper: Show and Tell: A Neural Ima ...
- LeetCode - 3. Longest Substring Without Repeating Characters(388ms)
Given a string, find the length of the longest substring without repeating characters. Examples: Giv ...
- DES(Data Encryption Standard)数据加密标准
DES算法入口参数 DES算法的入口参数有三个:Key.Data.Mode.其中Key为7个字节共56位,是DES算法的工作密钥.Data为8个字节64位,是要被加密或解密的数据;Mode为DES的工 ...
- AtCoder Grand Contest 025 Problem D - Choosing Points
题目大意:输入$n,d1,d2$,你要找到$n^2$个整点 x, y 满足$0 \leqslant x, y<2n$.并且找到的任意两个点距离,既不是$\sqrt{d1}$,也不是 $\sqrt ...
- BZOJ2729 [HNOI2012]排队 【高精 + 组合数学】
题目链接 BZOJ2729 题解 高考数学题... 我们先把老师看做男生,女生插空站 如果两个老师相邻,我们把他们看做一个男生,女生插空站 对于\(n\)个男生\(m\)个女生的方案数: \[n!m! ...
- CF763B Timofey and Rectangles
题目戳这里. 首先答案肯定是YES,因为一个平面图肯定可以被4种颜色染色,关键是怎么输出方案. 由于4是一个特殊的数字\(4 = 2^2\),而我们还有一个条件就是边长为奇数,而奇数是会改变二进制位的 ...
- AOJ.559 丢失的数字
丢失的数字 Time Limit: 1000 ms Memory Limit: 64 MB Total Submission: 1552 Submission Accepted: 273 Descri ...
- 遇到问题---java---git下载的maven项目web用tomcat发布时不带子项目
遇到的情况是用git下载maven项目,然后用mvn eclipse:eclipse命令标记为eclipse项目之后,使用maven插件导入之后用tomcat发布运行,发现maven关联的几个子项目没 ...
- codeforces 1015E1&&E2
E1. Stars Drawing (Easy Edition) time limit per test 3 seconds memory limit per test 256 megabytes i ...