mongodb持久化
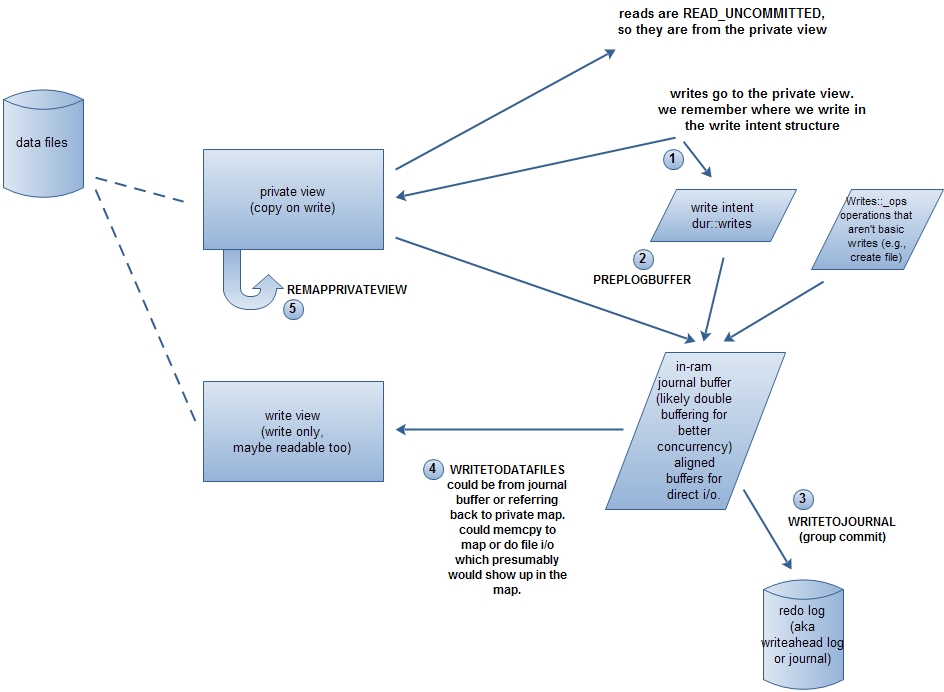
先上一张图(根据此处重画),看完下面的内容应该可以理解。
mongodb使用内存映射的方式来访问和修改数据库文件,内存由操作系统来管理。开启journal的情况,数据文件映射到内存2个view:private view和write view。对write view的更新会刷新到磁盘,而对private view的更新不刷新到磁盘。写操作先修改private view,然后批量提交(groupCommit),修改write view。
WriteIntent
发生写操作时,会记录修改的内存地址和大小,由结构WriteIntent表示。
/** Declaration of an intent to write to a region of a memory mapped view
* We store the end rather than the start pointer to make operator< faster
* since that is heavily used in set lookup.
*/
struct WriteIntent { /* copyable */
void *p; // intent to write up to p
unsigned len; // up to this len void* end() const { return p; }
bool operator < (const WriteIntent& rhs) const { return end() < rhs.end(); } // 用于排序
};
WriteIntent
查看代码会发现大量的类似调用,这就是保存WriteIntent。
getDur().writing(..)
getDur().writingPtr(...)
CommitJob
CommitJob保存未批量提交的WriteIntent和DurOp,目前只使用一个全局对象commitJob。对于不修改数据库文件的操作,如创建文件(FileCreatedOp)、删除库(DropDbOp),不记录WriteIntent,而是记录DurOp。
ThreadLocalIntents
由于mongodb是多线程程序,同时操作CommitJob需要加锁(groupCommitMutex)。为了避免频繁加锁,使用了线程局部变量
/** so we don't have to lock the groupCommitMutex too often */
class ThreadLocalIntents {
enum { N = };
std::vector<dur::WriteIntent> intents;
};
ThreadLocalIntents
WriteIntent先存放到intents里,当intents的大小达到N时,就添加到CommitJob里,这时候要才需要加锁。添加intents到CommitJob时,会对重叠的内存地址段进行合并,减少WriteIntent的数量。当然,CommitJob也会对添加的WriteIntent进行检查是否重复添加。这里有一个问题,如果intents的大小没有达到N,是不是永远都不添加到CommitJob里呢?不会。因为每次写操作,必须先获得'w'锁(库的写锁)或者'W'锁(全局写锁),当释放锁的时候,也会把intents添加到全局的数组里。
何时groupCommit
写操作会先修改private view,并保存WriteIntent到CommitJob。但是private view是不持久化的,CommitJob保存的WriteIntent何时groupCommit?
const unsigned UncommittedBytesLimit = (sizeof(void*)==) ? * * : * * ;
UncommittedBytesLimit
- durThread线程定期groupCommit,间隔时间可以由journalCommitInterval选项指定。默认是100毫秒(journal文件所在硬盘分区和数据文件所在硬盘相同)或者30毫秒。另外,如果有线程在等待groupCommit完成,或者未commit的字节数大于UncommittedBytesLimit / 2,会提前commit。
- 调用commitIfNeeded。如果未commit的字节数不小于UncommittedBytesLimit,或者是强制groupCommit,则执行groupCommit。
groupCommit的过程
1.PREPLOGBUFFER
首先是生成写操作日志(redo log)。对WriteIntent从小到大排序,这样可以对前后的WriteIntent进行重叠、重复的合并。对每个WriteIntent的地址,和每个数据文件的private view的基地址进行比较(private view的基地址已经排序,查找很快),找出其隶属的数据文件的标号。WriteIntent的地址减掉private view的基地址得到偏移,再从private view把修改的数据复制下来。这样数据文件标号、偏移、数据,形成一个JEntry。
2.WRITETOJOURNAL
把写操作日志压缩并写入journal文件。这一步完成之后,即使mongodb异常退出,数据也不会丢失了,因为可以根据journal文件中的写操作日志重建数据。关于journal文件可以参见这里。
3.WRITETODATAFILES
把所有写操作更新到write view中。后台线程DataFileSync会定期把write view刷新到磁盘中,默认是60秒,由syncdelay选项指定。
4.REMAPPRIVATEVIEW
private view是copy on write的,即在发生写时开辟新的内存,否则是和write view共用一块内存的。如果写操作很频繁,则private view会申请很多的内存,所以private view会remap,防止占用内存过多。并不是每次groupCommit都会remap,只有持有'W'锁的情况下才会remap。
durThread线程的定期groupCommit有三种情况会remap
- privateMapBytes >= UncommittedBytesLimit
- 前面9次groupCommit都没有ramap
- durOptions选项指定了DurAlwaysRemap
调用commitIfNeeded发生的groupCommit,如果持有持有'W'锁则remap。
remap的一个问题
在_REMAPPRIVATEVIEW()函数中,有这样一段代码
#if defined(_WIN32) || defined(__sunos__)
// Note that this negatively affects performance.
// We must grab the exclusive lock here because remapPrivateView() on Windows and
// Solaris need to grab it as well, due to the lack of an atomic way to remap a
// memory mapped file.
// See SERVER-5723 for performance improvement.
// See SERVER-5680 to see why this code is necessary on Windows.
// See SERVER-8795 to see why this code is necessary on Solaris.
LockMongoFilesExclusive lk;
#else
LockMongoFilesShared lk;
#endif
执行remap时,需要LockMongoFiles锁。win32下,这把锁是排他锁;而其他平台下(linux等)是共享锁。write view刷新到磁盘的时候,也需要LockMongoFiles共享锁。这样,在win32下,如果在执行磁盘刷新操作,则remap操作会被阻塞;而在执行remap之前,已经获得了'W'锁,这样会阻塞所有的读写操作。因此,在win32平台下,太多的写操作(写操作越多,remap越频繁)会导致整个数据库读写阻塞。
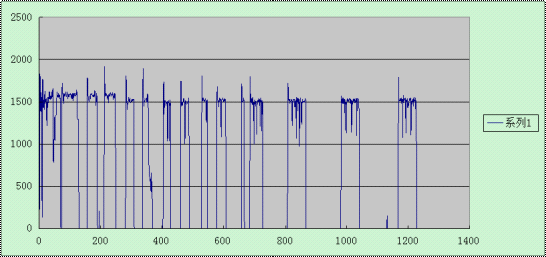
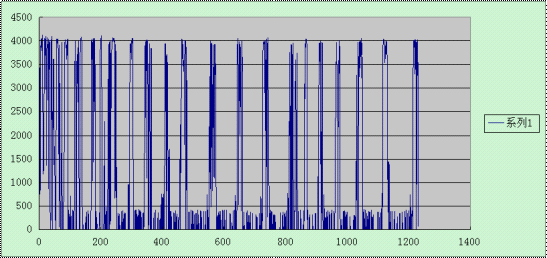
在win32和linux下做了一个测试,不停的插入大小为10k的记录。结果显示如下:上图win32平台,下图为linux平台;横坐标为时间轴,从0开始;纵坐标为每秒的插入次数。很明显的,linux平台的性能比win32好很多。
mongodb持久化的更多相关文章
- redis mongodb持久化的方式
目录 redis持久化方式(两种) RDB持久化 AOF持久化 两种持续化方式需要明确的问题 对比 MongoDB持久化方式 redis持久化方式(两种) RDB持久化 redis提供了RDB持久化的 ...
- scrapy框架的另一种分页处理以及mongodb的持久化储存以及from_crawler类方法的使用
一.scrapy框架处理 1.分页处理 以爬取亚马逊为例 爬虫文件.py # -*- coding: utf-8 -*- import scrapy from Amazon.items import ...
- MongoDB丢数据问题的分析
坊间有很多传说MongoDB会丢数据.特别是最近有一个InfoQ翻译的Sven的一篇水文(为什么叫做水文?因为里面并没有他自己的原创,只是搜罗了一些网上的博客,炒了些冷饭吃),其中又提到了丢数据的事情 ...
- HBase、Redis、MongoDB、Couchbase、LevelDB主流 NoSQL 数据库的对比
最近小组准备启动一个 node 开源项目,从前端亲和力.大数据下的IO性能.可扩展性几点入手挑选了 NoSql 数据库,但具体使用哪一款产品还需要做一次选型. 我们最终把选项范围缩窄在 HBase.R ...
- Redis、Memcache和MongoDB的区别
>>Memcached Memcached的优点:Memcached可以利用多核优势,单实例吞吐量极高,可以达到几十万QPS(取决于key.value的字节大小以及服务器硬件性能,日常环境 ...
- Redis、Memcache与MongoDB的区别
>>Memcached Memcached的优点:Memcached可以利用多核优势,单实例吞吐量极高,可以达到几十万QPS(取决于key.value的字节大小以及服务器硬件性能,日常环境 ...
- redis和mongodb的比较
>>RedisRedis的优点:支持多种数据结构,如 string(字符串). list(双向链表).dict(hash表).set(集合).zset(排序set).hyperloglog ...
- 三个缓存数据库Redis、Memcache、MongoDB
>>Memcached Memcached的优点:Memcached可以利用多核优势,单实例吞吐量极高,可以达到几十万QPS(取决于key.value的字节大小以及服务器硬件性能,日常环境 ...
- Redis、Memcache和MongoDB
一.Memcached Memcached的优点:Memcached可以利用多核优势,单实例吞吐量极高,可以达到几十万QPS(取决于key.value的字节大小以及服务器硬件性能,日常环境中QPS高峰 ...
随机推荐
- a letter and a number
描述we define f(A) = 1, f(a) = -1, f(B) = 2, f(b) = -2, ... f(Z) = 26, f(z) = -26;Give you a letter x ...
- 亚马逊副总裁谈Marketplace平台的个性化服务
说到个性化,亚马逊无疑是挖掘与利用数据为消费者打造个性化网购体验的先驱之一.而现在,几乎所有的公司和网站都在利用更加个性化的推荐算法为用户提供更好的购物和浏览体验. 亚马逊近年来尤其重视将其个性化特性 ...
- Linux 网卡设备驱动程序设计(3)
三.网络子系统深度分析 用户程序通过网络发送这个网络数据包 通过 SCI 协议无关接口 协议栈 < UDP的实现 会选择路由 < IP的实现 会建立这个邻居子系统,建立邻居信 ...
- 关于在windows环境下配置xampp多站点问题
前言 由于开发要求,最近开始了php开发,于是就找到了xampp,wamp等集成环境,关于在windows下的xampp和wamp的配置,我过两天在写两篇分别阐述一下,下面就遇到的多站点的配置问题讲一 ...
- 【CSS3】---嵌入字体@font-face
@font-face能够加载服务器端的字体文件,让浏览器端可以显示用户电脑里没有安装的字体. 语法: @font-face { font-family : 字体名称; src : 字体文件在服务器上的 ...
- ruby学习--varaible
#全局变量 $global_variable=10 class Class1 def print_global() puts "Global variable in Class1 is #{ ...
- 六、Android学习笔记_JNI_c调用java代码
1.编写native方法(java2c)和非native方法(c2java): package com.example.provider; public class CallbackJava { // ...
- Part 1 some difference from asp.net to asp.net mvc4
Part 1 some difference from asp.net to asp.net mvc4 In MVC URL's are mapped to controller Action Met ...
- 百度编辑器ueditor前台代码高亮无法自动换行解决方法
这两天本站成功安装整合了百度编辑器ueditor,用着还挺不错,但是遇到了点小问题 问题描述: 在内容里面插入代码高亮显示,后台编辑器中是可以自动换行的,但是发表后,在前台查看,发现代码不能自动换 ...
- [转] 正则表达式 oracle
地址:http://www.cnblogs.com/Azhu/archive/2012/04/03/2431127.html 从oracle database 10gsql 开发指南中copy的. 正 ...