Elasticsearch学习笔记1
Json (JavaScript Object Notation),即JavaScript对象标记法,当前十分流行和常见的互联网数据传输格式,尤其是在前端领域。Json是一种用于数据交换的文本格式,目的是取代繁琐笨重的XML格式。Json是一种轻量级(Light-Weight)、基于文本的(Text-Based)、可读的(Human-Readable)格式,相比于XML格式更小。每个Json对象就是一个值,要么是简单类型的值,要么是复合类型的值,但是只能是一个值,不能是两个或多个的值,即每个Json文档只能包含一个值。
Json对值类型的严格规定:
- 复合类型的值只能是数组或对象,不能是函数、正则表达式对象、日期对象;
- 简单类型的值只有四种:字符型、数值(必须是十进制)、布尔型和null(不能使用NaN, Infinity, - Infinity和undefined);
- 字符串必须使用双引号表示,不能使用单引号;
- 对象的键名必须放在双引号里面;
- 数组或对象最后一个成员的后面,不能加逗号;
- 数组(Array)用方括号(“[]”)表示;
- 对象(Object)用大括号(”{}”)表示;
- 名称/值对(name/value)组合成数组和对象;
- 名称(name)置于双引号中,值(value)有字符串、数值、布尔值、null、对象和数组;
- 并列的数据之间用逗号(“,”)分隔。
例如:
//json对象
{
"name": "Geoff Lui",
"age": 26,
"isChinese": true
}
//“名称/值对”里,值可以是数组和对象
{
"name": "Geoff Lui",
"age": 26,
"isChinese": true,
"friends":["Lucy", "Lily", "Gwen"],
"Mother": {
"name": "Mary Lui",
"age": 54
}
}
Apache Lucene是一个开源的高性能、可扩展的信息检索(IR)引擎,提供了强大的数据检索能力,不仅能支持全文索引,也能提供多种其他类型的索引方式,来满足不同类型的查询需求。基于Lucene的开源项目有很多,最知名的有Elasticsearch和Solr,如果说Elasticsearch和Solr是一辆设计精美、性能卓越的跑车,那Lucene就是为其提供强大动力的引擎。
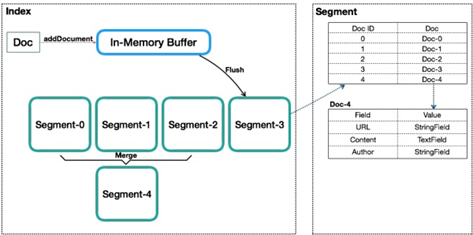
Index(索引)
类似数据库表的概念,但与传统表的概念有很大的不同。传统关系型数据库或者NoSQL数据库的表,在创建时至少要定义表的Scheme,定义表的主键或列等,会有一些明确定义的约束。Lucene的Index,则完全没有约束,Lucene的Index可以理解为一个文档收纳箱,可以往内部塞入新的文档,或者从里面拿出文档,但如果要修改里面的某个文档,则必须先拿出来修改后再塞回去。这个收纳箱可以塞入各种类型的文档,文档里的内容可以任意定义,Lucene都能对其进行索引。
Document(文档)
类似数据库内的行或者文档数据库内的文档的概念,一个Index内会包含多个Document。写入Index的Document会被分配一个唯一的ID,即Sequence Number(DocId)。
Field(字段)
一个Document会由一个或多个Field组成,Field是Lucene中数据索引的最小定义单位。Lucene提供多种不同类型的Field,例如StringField、TextField、LongFiled或NumericDocValuesField等,Lucene根据Field的类型(FieldType)来判断该数据要采用哪种类型的索引方式(Invert Index、Store Field、DocValues或N-dimensional等)。
Term和Term Dictionary
Lucene中索引和搜索的最小单位,一个Field会由一个或多个Term组成,Term是由Field经过Analyzer(分词)产生。Term Dictionary即Term词典,是根据条件查找Term的基本索引。
Segment
一个Index会由一个或多个sub-index构成,sub-index被称为Segment。Lucene在查询上只能提供近实时而非实时查询。
Lucene中的数据写入会先写内存的一个Buffer(不可读),当Buffer内数据到一定量后会被flush成一个Segment,每个Segment有自己独立的索引,可独立被查询,但数据永远不能被更改。这种模式避免了随机写,数据写入都是Batch和Append,能达到很高的吞吐量。Segment中写入的文档不可被修改,但可被删除,删除的方式也不是在文件内部原地更改,而是会由另外一个文件保存需要被删除的文档的DocID,保证数据文件不可被修改。Index的查询需要对多个Segment进行查询并对结果进行合并,还需要处理被删除的文档,为了对查询进行优化,Lucene会有策略对多个Segment进行合并。
Segment在被flush或commit之前,数据保存在内存中,是不可被搜索的,这就是为什么Lucene被称为提供近实时而非实时查询的原因。Lucene中数据搜索依赖构建的索引(例如倒排依赖Term Dictionary),Lucene中对数据索引的构建会在Segment flush时,而非数据实时写入时即构建,目的是为了构建最高效索引。
Sequence Number 也称 DocId
数据库内通过主键来唯一标识一行,而Lucene的Index通过DocId来唯一标识一个Doc。
- DocId实际上并不在Index内唯一,而是Segment内唯一,Lucene这么做主要是为了写入和压缩优化。既然在Segment内才唯一,又是怎么做到在Index级别来唯一标识一个Doc?方案很简单,Segment之间是有顺序的,举个简单的例子,一个Index内有两个Segment,每个Segment内分别有100个Doc,在Segment内DocId都是0-100,转换到Index级的DocId,需要将第二个Segment的DocId范围转换为100-200。
- DocId在Segment内唯一,取值从0开始递增。但不代表DocId取值一定是连续的,如果有Doc被删除,那可能会存在空洞。
- 一个文档对应的DocId可能会发生变化,主要是发生在Segment合并时。
Lucene内最核心的倒排索引,本质上就是Term到所有包含该Term的文档的DocId列表的映射。所以Lucene内部在搜索的时候会是一个两阶段的查询,第一阶段是通过给定的Term的条件找到所有Doc的DocId列表,第二阶段是根据DocId查找Doc。Lucene提供基于Term的搜索功能,也提供基于DocId的查询功能。
Lucene索引类型
Lucene中支持丰富的字段类型,每种字段类型确定了支持的数据类型以及索引方式,目前支持的字段类型包括LongPoint、TextField、StringField、NumericDocValuesField等。
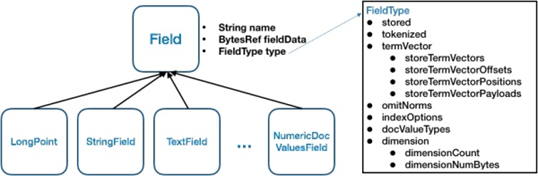
如图,Lucene中对于不同类型Field定义的一个基本关系,所有字段类都会继承自Field这个类,Field包含3个重要属性:name(String)、fieldsData(BytesRef)和type(FieldType)。name即字段的名称,fieldsData即字段值,所有类型的字段的值最终都会转换为二进制字节流来表示。type是字段类型,确定了该字段被索引的方式。
Elasticsearch学习笔记1的更多相关文章
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- elasticsearch学习笔记——相关插件和使用场景
logstash-input-jdbc学习 ES(elasticsearch缩写)的一大优点就是开源,插件众多.所以扩展起来非常的方便,这也造成了它的生态系统越来越强大.这种开源分享的思想真是与天朝格 ...
- ElasticSearch学习笔记(超详细)
文章目录 初识ElasticSearch 什么是ElasticSearch ElasticSearch特点 ElasticSearch用途 ElasticSearch底层实现 ElasticSearc ...
- 【原】无脑操作:ElasticSearch学习笔记(01)
开篇来自于经典的“保安的哲学三问”(你是谁,在哪儿,要干嘛) 问题一.ElasticSearch是什么?有什么用处? 答:截至2018年12月28日,从ElasticSearch官网(https:// ...
- ElasticSearch学习笔记-01 简介、安装、配置与核心概念
一.简介 ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进 ...
- Elasticsearch学习笔记
Why Elasticsearch? 由于需要提升项目的搜索质量,最近研究了一下Elasticsearch,一款非常优秀的分布式搜索程序.最开始的一些笔记放到github,这里只是归纳总结一下. 首先 ...
- Elasticsearch学习笔记 一
本文版权归博客园和作者吴双本人共同所有 转载和爬虫请注明原文地址 www.cnblogs.com/tdws. 本文参考和学习资料 <ES权威指南> 一.基本概念 存储数据到ES中的行为叫做 ...
- 2018/2/13 ElasticSearch学习笔记三 自动映射以及创建自动映射模版,ElasticSearch聚合查询
终于把这些命令全敲了一遍,话说ELK技术栈L和K我今天花了一下午全部搞定,学完后还都是花式玩那种...E却学了四天(当然主要是因为之前上班一直没时间学,还有安装服务时出现的各种error真是让我扎心了 ...
- 2018/2/11 ELK技术栈之ElasticSearch学习笔记二
终于有时间记录一下最近学习的知识了,其实除了写下的这些还有很多很多,但懒得一一写下了: ElasticSearch添加修改删除原理:ElasticSearch的倒排索引和文档一旦生成就不允许修改(其实 ...
- elasticsearch学习笔记——安装,初步使用
前言 久仰elasticsearch大名,近年来,fackbook,baidu等大型网站的搜索功能均开始采用elasticsearch,足见其在处理大数据和高并发搜索中的卓越性能.不少其他网站也开始将 ...
随机推荐
- JAVA—集合框架
ref:https://blog.csdn.net/u012961566/article/details/76915755 https://blog.csdn.net/u011240877/artic ...
- HUD6182
A Math Problem Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- 启动HDFS时datanode无法启动的坑
启动HDFS 启动hdfs,进入sbin目录,也可以执行./start-all.sh - $cd /app/hadoop/hadoop-2.2.0/sbin - $./start-dfs.sh 在此之 ...
- js-ES6学习笔记-数组的扩展
1.Array.from方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(包括ES6新增的数据结构Set和Map). 实际应用中 ...
- Git 及 GitHub 使用
Git bash 的常用命令 1. pwd 查看当前所在目录 2. cd cd .. 返回上一级 cd 目录 进入对应的目录 3. ls 查看当前文件夹的内容 ...
- canvas与svg特性和使用对比
什么是 Canvas? HTML5 的 canvas 元素使用 JavaScript 在网页上绘制图像. 画布是一个矩形区域,您可以控制其每一像素. canvas 拥有多种绘制路径.矩形.圆形.字符以 ...
- 移动设备 小米2S不显示CD驱动器(H),便携设备,MTP,驱动USB Driver,MI2感叹号的解决方法
小米2S不显示CD驱动器(H),便携设备,MTP,驱动USB Driver,MI2感叹号的解决方法 by:授客 QQ:1033553122 用户环境 操作系统:Win7 手机设备:小米2S 问题描 ...
- TLS/SSL测试工具
常用的有SSLScan,我用的是OpenSSL的: openssl s_client -connect www.baidu.com:443
- as 打包报错
错误:Android Error:Execution failed for task ':app:transformClassesAndResourcesWithProguardForRelease' ...
- [Android] Service服务详解以及如何使service服务不被杀死
排版上的细节有些不好看,主要是我用的MarkDown编辑器预览和这里的不一样,在那个上面的样式很舒服.这里要改的地方太多就不想改了,将就看吧.下次写的时候注意.还有看到错误给我提啊. 本文链接:htt ...