Internet
0x01 URL的解析/反解析/连接
解析
urlparse()--分解URL
# -*- coding: UTF-8 -*- from urlparse import urlparse url = 'http://user:pwd@NetLoc:80/p1;param/p2?query=arg#frag'
parsed = urlparse(url)
print parsed print parsed.scheme
print parsed.netloc
print parsed.path
print parsed.params
print parsed.query
print parsed.fragment
print parsed.username
print parsed.password
print parsed.hostname,'(netloc in lowercase)'
print parsed.port
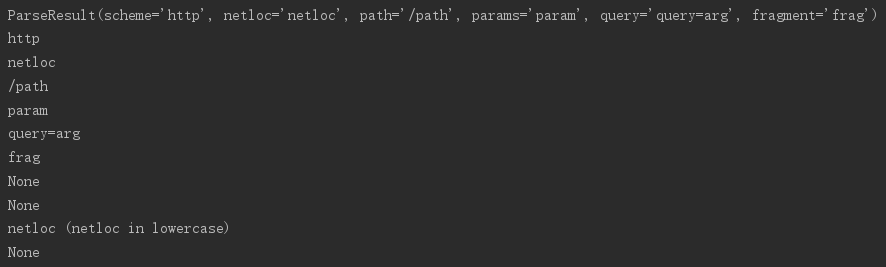
urlsplit()--替换urlparse(),但不会分解参数。(没有params属性)
# -*- coding: UTF-8 -*- from urlparse import urlsplit url = 'http://user:pwd@NetLoc:80/p1;param/p2?query=arg#frag'
parsed = urlsplit(url)
print parsed print parsed.scheme
print parsed.netloc
print parsed.path
print parsed.params
print parsed.query
print parsed.fragment
print parsed.username
print parsed.password
print parsed.hostname,'(netloc in lowercase)'
print parsed.port
urlsplit()示例

urldefrag()--从URL中剥离出片段标识符
# -*- coding: UTF-8 -*- from urlparse import urldefrag url = 'http://NetLoc/path;param?query=arg#frag' print 'original :',url
url,fragment = urldefrag(url)
print 'url :',url
print 'fragment :',fragment
urldefrag()示例

反解析
geturl()--只适用于urlparse()或urlsplit()返回的对象
# -*- coding: UTF-8 -*- from urlparse import urlparse url = 'http://NetLoc/path;param?query=arg#frag' print 'original :',url
parsed = urlparse(url) print 'after geturl() :',parsed.geturl()
urlsplit()示例

urlunparse()--将包含串的普通元组拼接成一个URL(如果输入URL包含多余部分,重新构造的URL可能会将其去除)
# -*- coding: UTF-8 -*- from urlparse import urlparse,urlunparse url = 'http://NetLoc/path;param?query=arg#frag' print 'ORIGINAL URL:',url
parsed = urlparse(url)
print 'PARSED :',type(parsed),parsed
t = parsed[:]
print 'TUPLE :',type(t),t
print 'NEW :',urlunparse(t)
urlunparse()示例

连接
urljoin()--由相对片段构造绝对URL
# -*- coding: UTF-8 -*-
from urlparse import urljoin
print urljoin('http://www.example.com/path/file.html','anotherfile.html')
print urljoin('http://www.example.com/path/file.html','../anotherfile.html')
urljoin()相对路径示例

# -*- coding: UTF-8 -*-
from urlparse import urljoin
print urljoin('http://www.example.com/path/','/subpath/file.html')
print urljoin('http://www.example.com/path/','subpath/file.html')
urljoin()非相对路径示例
注:如果连接到URL的路径以斜线开头(/),这会将URL的路径重置为顶级路径。如果不是以一个斜线开头,则追加到当前URL路径的末尾。

0x02 BaseHTTPServer--实现web服务器的基类
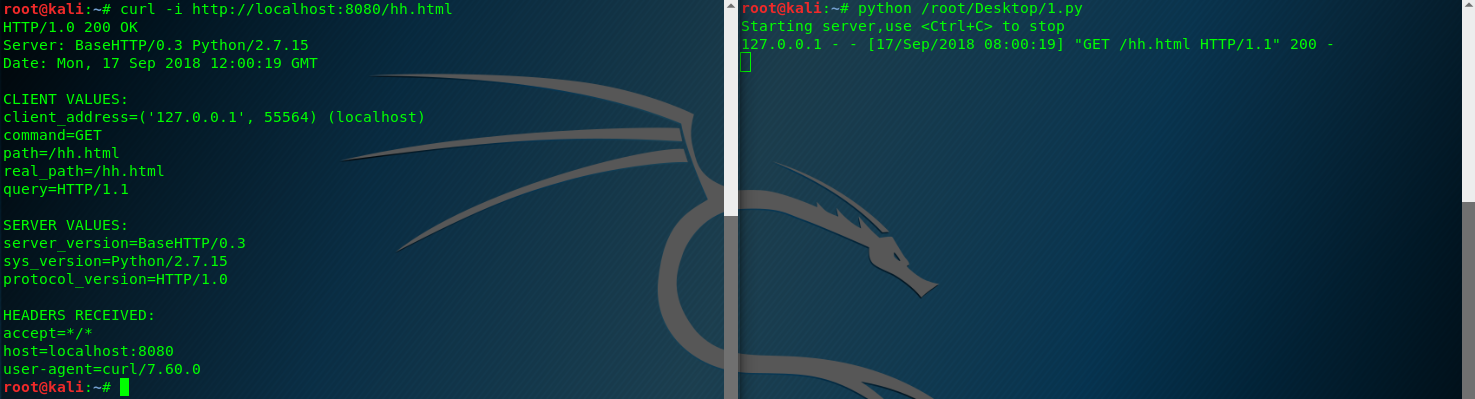
HTTP GET
下面一个示例展示了一个请求处理器如何向客户返回一个响应
# -*- coding: UTF-8 -*- from BaseHTTPServer import BaseHTTPRequestHandler
import urlparse class GetHandler (BaseHTTPRequestHandler):
def do_GET(self):
parsed_path = urlparse.urlparse(self.path)
message_parts = [
'CLIENT VALUES:',
'client_address=%s (%s)' % (self.client_address,
self.address_string()),
'command=%s' % self.command,
'path=%s' % self.path,
'real_path=%s' % parsed_path.path,
'query=%s' % self.request_version,
'',
'SERVER VALUES:',
'server_version=%s' % self.server_version,
'sys_version=%s' % self.sys_version,
'protocol_version=%s' % self.protocol_version,
'',
'HEADERS RECEIVED:',
]
for name,value in sorted(self.headers.items()):
message_parts.append('%s=%s' % (name,value.rstrip()))
message_parts.append('')
message = '\r\n'.join(message_parts)
self.send_response(200)
self.end_headers()
self.wfile.write(message)
return if __name__ == '__main__':
from BaseHTTPServer import HTTPServer
server = HTTPServer(('localhost',8080),GetHandler)
print 'Starting server,use <Ctrl+C> to stop'
server.serve_forever()
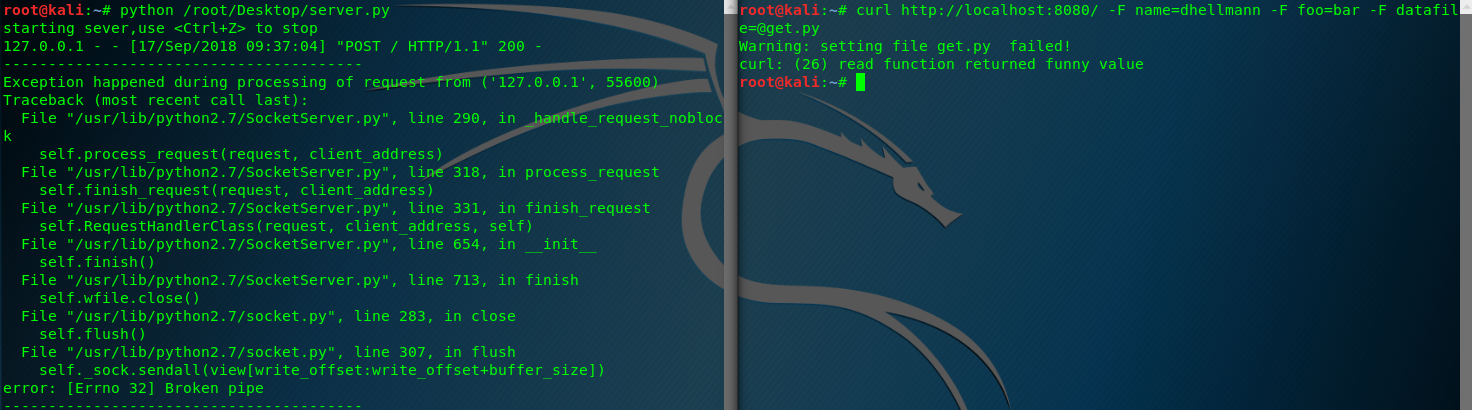
HTTP POST
支持POST请求需要多做一些工作,因为基类不会自动解析表单数据。cgi模块提供了FieldStorage类,如果给定了正确的输入,它知道如何解析表单。
# -*- coding: UTF-8 -*- from BaseHTTPServer import BaseHTTPRequestHandler
import cgi class PostHandler(BaseHTTPRequestHandler):
def do_POST(self):
# parse the form data posted
form = cgi.FieldStorage(
fp=self.rfile,
headers=self.headers,
environ={'REQUEST_METHOD': 'POST',
'CONTENT_TYPE': self.headers['Content-Type'],
}) # begin the response
self.send_response(200)
self.end_headers()
self.wfile.write('Client:%s\n' % str(self.client_address))
self.wfile.write('User-agent:%s\n' % str(self.headers['user-agent']))
self.wfile.write('Path:%s\n' % self.path)
self.wfile.write('Form data:\n') # Echo back information about what was posted in the form
for field in form.keys():
field_item = form[field]
if field_item.filename:
# the field contains an uploaded file
file_data = field_item.file.read()
file_len = len(file_data)
del file_data
self.wfile.write(
'\tUpload %s as "%s" (%d bytes)\n' % (field, field_item.filename, file_len))
else:
# regular form values
self.wfile.write('\t%s=%s\n' % (field, form[field].value)) return if __name__ == '__main__':
from BaseHTTPServer import HTTPServer
server = HTTPServer(('localhost', 8080), PostHandler)
print 'starting sever,use <Ctrl+Z> to stop'
server.serve_forever()
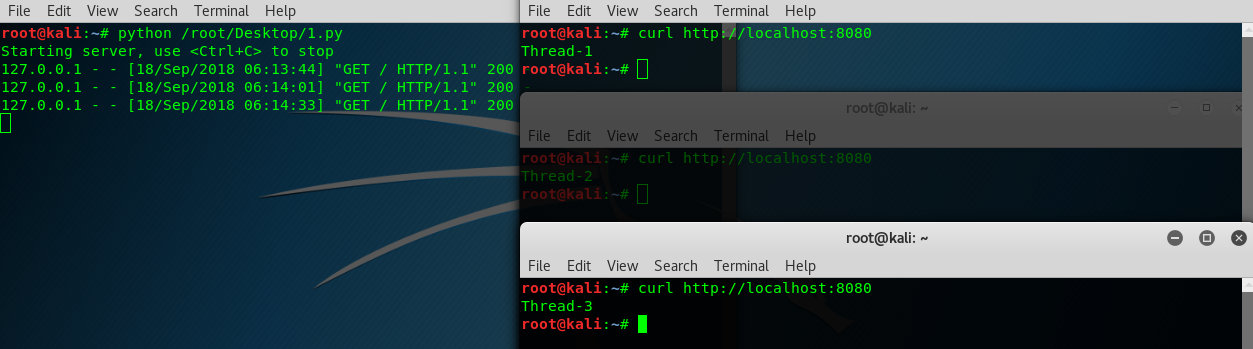
线程与进程
HTTPServer是SocketServer.TCPServer的一个子类,不使用多线程或者多进程来处理请求。要增加线程或进程,需要使用相应的mix-in技术从SocketServer创建一个新类。
# -*- coding: UTF-8 -*- from BaseHTTPServer import HTTPServer, BaseHTTPRequestHandler
from SocketServer import ThreadingMixIn
import threading class Handler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.end_headers()
message=threading.currentThread().getName()
self.wfile.write(message)
self.wfile.write('\n')
return class ThreadedHTTPServer(ThreadingMixIn,HTTPServer):
"""Handler requests in a separate thread.""" if __name__ == '__main__':
server = ThreadedHTTPServer(('localhost',8080),Handler)
print 'Starting server, use <Ctrl+C> to stop'
server.serve_forever()
处理错误
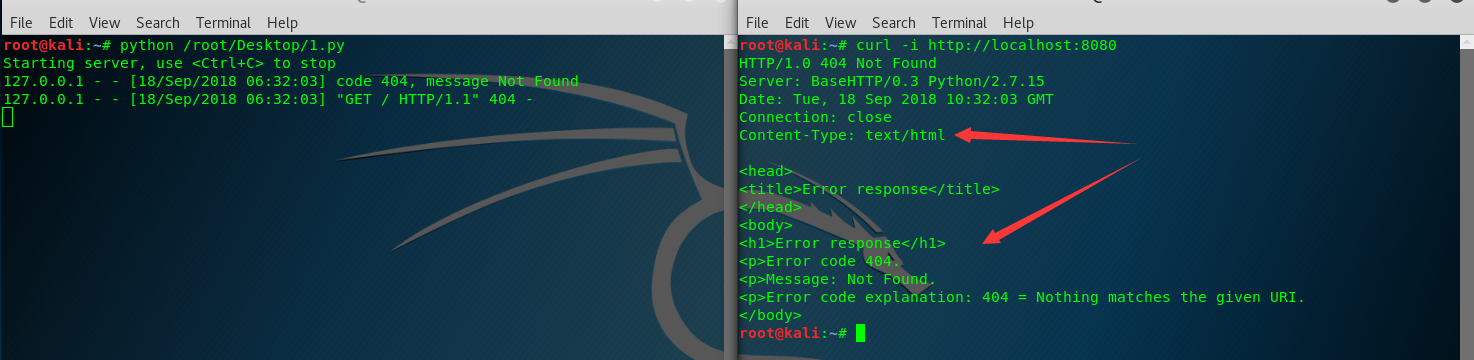
# -*- coding: UTF-8 -*- from BaseHTTPServer import BaseHTTPRequestHandler class ErrorHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_error(404)
return if __name__ == '__main__'
from BaseHTTPServer import HTTPServer
server = HTTPServer(('localhost',8080),ErrorHandler)
print 'Starting server, use <Ctrl+C> to stop'
server.serve_forever()
设置首部
send_header()方法将向HTTP响应添加首部数据。
# -*- coding: UTF-8 -*- from BaseHTTPServer import BaseHTTPRequestHandler
import urlparse
import time class GetHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Last-Modified',
self.date_time_string(time.time()))
self.end_headers()
self.wfile.write('Response body \n')
return if __name__ == '__main__':
from BaseHTTPServer import HTTPServer
server = HTTPServer(('localhost',8080),GetHandler)
print 'Starting server, use <Ctrl+C> to stop'
server.serve_forever()
send_header()

0x03 urllib--网络资源访问
作用:访问不需要验证的远程资源/coocie等等。
利用缓存实现简单获取
urllib提供的urlretrieve()函数提供下载数据的功能。参数:1.URL 2.存放数据的一个临时文件和一个报告下载进度的函数。另外如果UTL指示一个表单,要求提交数据,那么urlretrieve()还有有一个参数表示要传递的数据。调用程序可以直接删除这个文件,或者将这个文件作为一个缓存,使用urlcleanup()将其删除。
使用一个HTTP GET请求从一个web服务器获取数据的例子:
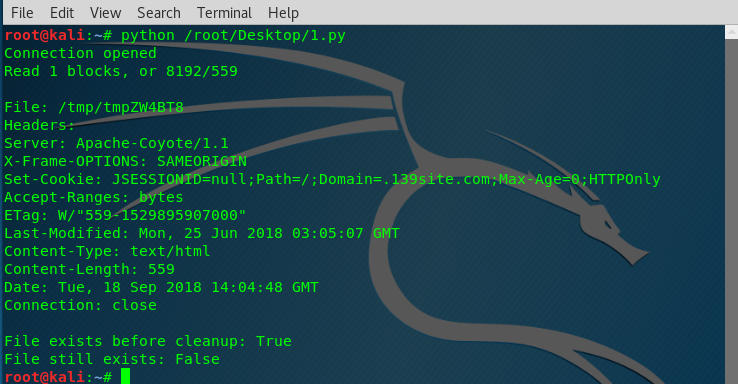
# -*- coding: UTF-8 -*- import urllib
import os def reporthook(blocks_read, block_size, total_size):
"""total_size is reported in bytes,
block_size is the amount read each time.
blocks_read is the number of blocks successfully read.
"""
if not blocks_read:
print 'Connection opened'
return
if total_size < 0:
#unknown size
print 'Read %d blocks (%d bytes)' % (blocks_read,blocks_read* block_size)
else:
amount_read = blocks_read * block_size
print 'Read %d blocks, or %d/%d' % (blocks_read,amount_read,total_size)
return try:
filename,msg = urllib.urlretrieve('http://blog.doughellmann.com/', reporthook=reporthook) print
print 'File:',filename
print 'Headers:'
print msg
print 'File exists before cleanup:', os.path.exists(filename) finally:
urllib.urlcleanup()
print 'File still exists:', os.path.exists(filename)
参数编码
对参数编码并追加到URL,从而将它们传递到服务器。(error)
# -*- coding: UTF-8 -*-
import urllib
query_args = {'q':'query string','foo':'bar'}
encoded_args = urllib.urlencode(query_args)
print 'Encoded:', encoded_args
url = 'http://localhost:8080/?' + encoded_args
print urllib.urlopen(url).read()

要使用变量的不同出现向查询串传入一个值序列,需要在调用urlencode()时将doseq设置为True。
# -*- coding: UTF-8 -*-
import urllib
query_args = {'foo':['foo1','foo2']}
print 'Single :',urllib.urlencode(query_args)
print 'Sequence:',urllib.urlencode(query_args,doseq=True)
结果时一个查询串,同一个名称与多个值关联。

查询参数中可能有一些特殊字符,在服务器端对URL解析时这些字符会带来问题,所以在传递到urlencode()时要对这些特殊字符"加引号"。要在本地对特殊字符加引号从而得到字符串的“安全”版本。
直接使用quote()或quote_plus()函数。
# -*- coding: UTF-8 -*- import urllib url = 'http://localhost:8080/~dhellmann/'
print 'urlencode() :',urllib.urlencode({'url':url})
print 'quote() :',urllib.quote(url)
print 'quote_plus():',urllib.quote_plus(url)

加引号的逆过程
相应的使用unquote()或unquote_plus()函数。
# -*- coding: UTF-8 -*-
import urllib
print urllib.unquote('http%3A//localhost%3A8080/%7Edhellmann/')
print urllib.unquote_plus('http%3A%2F%2Flocalhost%3A8080%2F%7Edhellmann%2F')

路径与URL
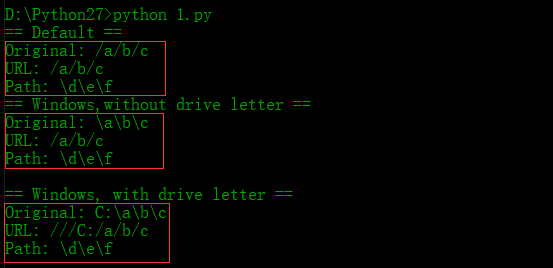
有些操作系统在本地文件和URL中使用不同的值分隔路径的不同部分。为了保证代码可移植,可以使用函数pathname2url()和url2pathname()来回转换。
# -*- coding: UTF-8 -*- import os
from urllib import pathname2url,url2pathname print '== Default =='
path = '/a/b/c'
print 'Original:',path
print 'URL:',pathname2url(path)
print 'Path:',url2pathname('/d/e/f') print '== Windows,without drive letter =='
path = r'\a\b\c'
print 'Original:',path
print 'URL:',pathname2url(path)
print 'Path:',url2pathname('/d/e/f')
print print '== Windows, with drive letter =='
path = r'C:\a\b\c'
print 'Original:',path
print 'URL:',pathname2url(path)
print 'Path:',url2pathname('/d/e/f')
0x04 urllib2--网络资源访问
作用:用于打开扩展URL的库,这些URL可以通过定义定制协议处理器来扩展。
urllib2模块提供了一个更新的API来使用URL标识的Internet资源。
HTTP GET
...临场error
0x05 Base64--用ASCLL编码二进制数据
base64编码
# -*- coding: UTF-8 -*- import base64
import textwrap #load this sourse file and strip the header.
with open(__file__,'rt') as input:
raw = input.read()
initial_data = raw.split('#end_pymotw_headers')[1] encoded_data = base64.b64encode(initial_data) num_initial = len(initial_data) #there will never be more than 2 padding bytes.
padding = 3 - (num_initial %3) print '%d bytes before encoding' % num_initial
print 'Expect %d padding bytes' % padding
print '%d bytes after encoding' % len(encoded_data)
print encoded_data

base64解码
# -*- coding: UTF-8 -*- import base64 original_string = 'this is the data, in the clear.'
print 'Original:' , original_string
encoded_string = base64.b64encode(original_string) print 'Encoded:',encoded_string decoded_string = base64.b64decode(encoded_string)
print 'Decoded:',decoded_string

URL安全的变种
因为默认的Base64字母表可能使用+和/,这两个字符在URL中会用到,所以通常很必要使用一个候选编码来替换这些字符。+替换成-,/替换成下划线_
# -*- coding: UTF-8 -*- import base64 encodes_with_pluses = chr(251) + chr(239)
encodes_with_slashes = chr(255) * 2 for original in [encodes_with_pluses,encodes_with_slashes]:
print 'Original :',repr(original)
print 'Standard encodingL:',base64.standard_b64encode(original)
print 'UTL-safe encoding :',base64.urlsafe_b64encode(original)
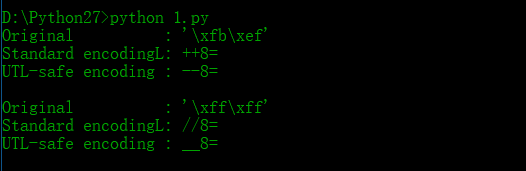
其他编码
# -*- coding: UTF-8 -*- import base64 original_string = 'This is the data,in the clear.'
print 'Original:', original_string #Base32字母表包括ASCLL集中的26个大写字母以及数字2~7
encoded_string = base64.b32encode(original_string)
print 'Base32Encoded :', encoded_string
decoded_string = base64.b32decode(encoded_string)
print 'Base32Decoded :', decoded_string #Base16函数处理十六进制字母表
encoded_string = base64.b16encode(original_string)
print 'Base16Encoded :',encoded_string
encoded_string = base64.b16decode(encoded_string)
print 'Base16Decoded :',encoded_string

0x06 robotparser--网络蜘蛛访问控制
作用:解析用于控制网络蜘蛛的robots.txt文件
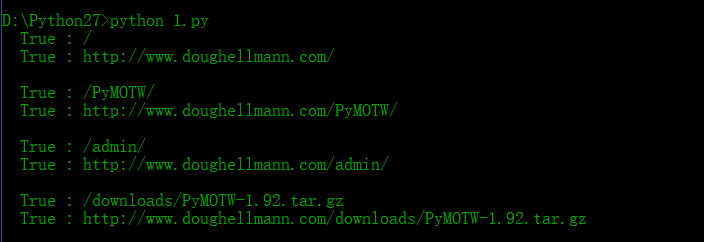
# -*- coding: UTF-8 -*- import robotparser
import urlparse AFENT_NAME = 'PyMOTW'
URL_BASE = 'http://www.doughellmann.com/'
parser = robotparser.RobotFileParser()
parser.set_url(urlparse.urljoin(URL_BASE,'robots.txt'))
parser.read() PATHS = [
'/',
'/PyMOTW/',
'/admin/',
'/downloads/PyMOTW-1.92.tar.gz',
] for path in PATHS:
print '%6s : %s' % (parser.can_fetch(AFENT_NAME,path),path)
url = urlparse.urljoin(URL_BASE,path)
print '%6s : %s' % (parser.can_fetch(AFENT_NAME,url),url)
can_fetch()的URL参数可以是一个相对于网站根目录的相对路径,也可以是一个完全URL。
长久蜘蛛
如果一个应用需要花很长时间来处理它下载的资源,或者受到抑制,需要在很多次下载之间暂停,这样的移动应当以其下载内容的寿命为根据,定期检查新的robots.txt文件。这个寿命并不是自动管理的,不过模块提供了一些简便方法,利用这些方法可以更容易地跟踪文件的寿命。
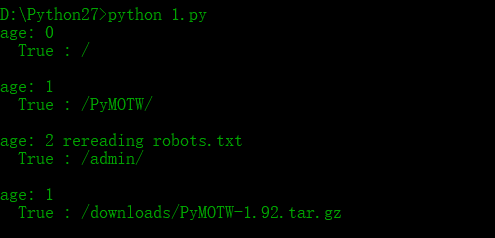
# -*- coding: UTF-8 -*- import robotparser
import urlparse
import time AGENT_NAME = 'PyMOTW'
URL_BASE = 'http://www.doughellmann.com/'
parser = robotparser.RobotFileParser()
parser.set_url(urlparse.urljoin(URL_BASE,'robots.txt'))
parser.read()
parser.modified() PATHS = [
'/',
'/PyMOTW/',
'/admin/',
'/downloads/PyMOTW-1.92.tar.gz',
] for path in PATHS:
age = int(time.time() - parser.mtime())
print 'age:',age,
if age>1:
print 'rereading robots.txt'
parser.read()
parser.modified()
else:
print '%6s : %s' % (parser.can_fetch(AGENT_NAME,path),path)
#Simulate delay in processing
time.sleep(1)
如果已下载的文件寿命超过了1秒,这个极端例子就会下载一个新的robots.txt文件。作为一个更好的长久应用,在下载整个文件之前可能会请求文件的修改世界。
0x07 Cookie--HTTP Cookie
创建和设置Cookie
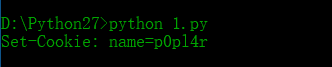
# -*- coding: UTF-8 -*- import Cookie c = Cookie.SimpleCookie()
c['name'] = 'p0pl4r'
print c
输出是一个合法的Set-Cookie首部,可以作为HTTP响应的一部分传递到客户。
Morsel
cookie的所有RFC属性都可以通过表示cookie值的Morsel对象来管理,如到期时间/路径/域。
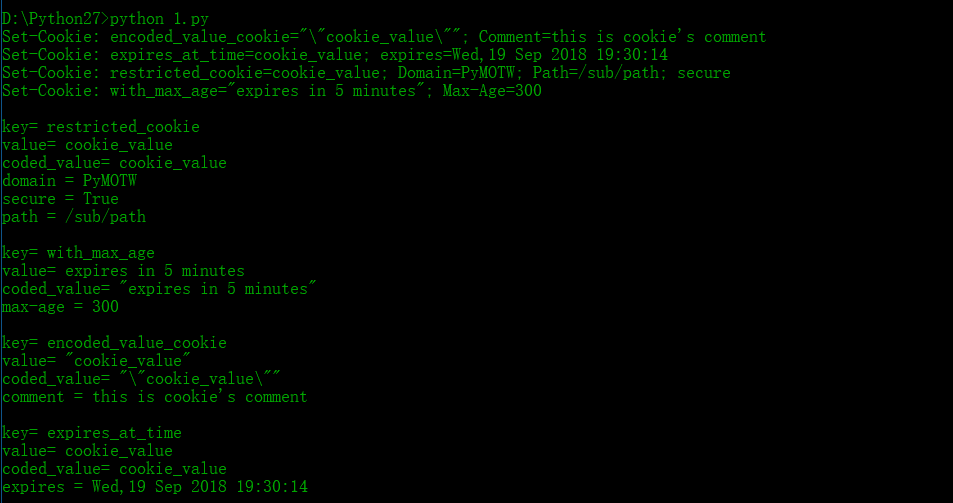
# -*- coding: UTF-8 -*- import Cookie
import datetime def show_cookie(c):
print c
for key,morsel in c.iteritems():
print 'key=',morsel.key
print 'value=',morsel.value
print 'coded_value=',morsel.coded_value
for name in morsel.keys():
if morsel[name]:
print '%s = %s' % (name,morsel[name]) c = Cookie.SimpleCookie() #A cookie with a value that has to be encoded to fit into the headers
c['encoded_value_cookie'] = '"cookie_value"'
c['encoded_value_cookie']['comment'] = 'this is cookie\'s comment' #A cookie that only applies to part of a site
c['restricted_cookie'] = 'cookie_value'
c['restricted_cookie']['path'] = '/sub/path'
c['restricted_cookie']['domain'] = 'PyMOTW'
c['restricted_cookie']['secure'] = 'True' #A cookie that expires in 5 minutes
c['with_max_age'] = 'expires in 5 minutes'
c['with_max_age']['max-age'] = 300 # seconds #A cookie that expires at a specific time
c['expires_at_time'] = 'cookie_value'
time_to_live = datetime.timedelta(hours = 1)
expires = datetime.datetime(2018,9,19,18,30,14)+time_to_live #Date format:Wdy,DD-Mon-YY HH:MM:SS: GMT
expires_at_time = expires.strftime('%a,%d %b %Y %H:%M:%S')
c['expires_at_time']['expires'] = expires_at_time
show_cookie(c)
Internet的更多相关文章
- internet协议入门
前言 劳于读书,逸于作文. 原文地址:internet协议入门 博主博客地址:Damonare的个人博客 博主之前写过一篇博客:网络协议分析,在这篇博客里通过抓包,具体的分析了不同网络协议的传送的数据 ...
- DOS下命令符开启wifi无internet访问解决办法
先按win+R 输入cmd netsh wlan set host mode=allow ssid=nothing key=323435435 (ssid后面的可以任意,key后面最少8个字符) 我的 ...
- 三星首次更新Gear VR虚拟现实浏览器Samsung Internet
通过VR浏览网页不是问题,不过你需要一个专门的VR浏览器,而GearVR的虚拟现实应用名为"Samsung Internet for Gear VR".继去年12月份上线后,迎来了 ...
- 企业IT管理员IE11升级指南【1】—— Internet Explorer 11增强保护模式 (EPM) 介绍
企业IT管理员IE11升级指南 系列: [1]—— Internet Explorer 11增强保护模式 (EPM) 介绍 [2]—— Internet Explorer 11 对Adobe Flas ...
- 企业IT管理员IE11升级指南【2】—— Internet Explorer 11 对Adobe Flash的支持
企业IT管理员IE11升级指南 系列: [1]—— Internet Explorer 11增强保护模式 (EPM) 介绍 [2]—— Internet Explorer 11 对Adobe Flas ...
- 企业IT管理员IE11升级指南【6】—— Internet Explorer 11面向IT专业人员的常见问题
企业IT管理员IE11升级指南 系列: [1]—— Internet Explorer 11增强保护模式 (EPM) 介绍 [2]—— Internet Explorer 11 对Adobe Flas ...
- ASP.NET MVC - 创建Internet 应用程序
为了学习 ASP.NET MVC,我们将构建一个 Internet 应用程序. 第 1 部分:创建应用程序. 我们将构建什么 我们将构建一个支持添加.编辑.删除和列出数据库存储信息的 Internet ...
- Internet网
Internet网是世界上最大的基于IP的网络.它是世界上所有计算机使用IP相互对话的一个无组织的集合.Internet上每台计算机都至少有一个IP地址来标识该计算机. 节点与主机 连接到Intern ...
- Ubuntu 14.04 掛載 網路磁碟 mount internet disk
1.install cifs tool (Common Internet File System) 新增 /etc/apt/apt.conf.d/01proxy 檔案並加入以下字串,即可透過此台機器做 ...
- Internet Download Manager 6.27.1 中文特别版(IDM)
软件介绍: 软件名称:Internet Download Manager(IDM) 软件大小:5.09M软件语言:简体中文 软件官网:http://www.internetdownloadmanage ...
随机推荐
- NCB之taxonomy系列
1.taxonomy之简介 生物分类学是研究生物系统的一种强有力的组织原则.遗传.共同遗传的同源性以及在确定功能时保护序列和结构,这些都是生物学的中心思想,直接关系到任何一组生物体的进化史.因此,分类 ...
- leetcode 167 two sum II
167. Two Sum II - Input array is sorted Given an array of integers that is already sorted in ascendi ...
- 【Scheme】序列的操作
1.序列的表示 序列 序列(表)是由一个个序对组合而成的,具体来说就是让每个序对的car部分对应这个链的条目,cdr部分则是下一个序对. 对于1->2->3->4这个序列我们可以表示 ...
- oracle 函数的返回值与out参数
函数的return值是调用函数返回的结果. 而out参数就是单纯的赋值. 例子: function test(aaa in varchar, bbb out integer) return integ ...
- python解释器配置和python常用快捷键
1.准备工作 安装好Pycharm2017版本 电脑上安装好Python解释器 2.本地解释器配置 配置本地解释器的步骤相对简洁直观: (1)单击工具栏中的设置按钮. (2)在Settings/Pre ...
- leetcode 数组类型题
// ConsoleApplication1.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <Windows.h& ...
- pta6-15(双端循环队列)
题目链接:https://pintia.cn/problem-sets/1101307589335527424/problems/1101313244863737856 题意:实现双段队列的队首出队. ...
- 第二章 向量(f)归并排序
- linux 切割文件的命令
Head -1000 access.2016.log >> 10000_access.log
- GridView中CheckBox翻页记住选项
<asp:GridView ID="gvYwAssign" runat="server" AutoGenerateColumns="False& ...