零基础学习python_文件(28-30课)
本人小白一枚,随着现在对测试要求越来越高,动不动就要去会一门编程语言,没办法只能学习学习Python,今天看到几个月前还是菜鸟的人突然就已经能使用Python写简单系统了,没办法,虽然之前也简单学习过Python,但是还是怒了,最近一直再看鱼C工作室的Python教程,为啥看这个?没为啥,因为讲解没那么死板咯,于是乎就找这个视频来看看,唯一的缺点就是练习题要钱,坑~~~~没办法,没钱人家怎么继续玩下去呢,好了不说废话了,进入今天的主题,由于之前27课看过了,也没写博客,没办法只能从28课写起了,如果日后感觉还可以的话再补吧!注意:Python是3+版本的喔
今天主要讲的是Python操作文件,大家想一下既然是文件那我们肯定要“打开”啊是不是,打开那英文单词是啥?Open对不对,没错啦,那打开啥呢?所以open后面是不是得加文件路径?没错,那接着文件打开了那你是想干嘛呢?(读、写?)所以,最基本的打开两个要素就来了呗,如下,一般open(‘文件路径’,‘打开方式’)这样既可,其余默认。

如果我们open时打开模式不填写就代表只读,即为'r',来看一看下面,这么多种打开模式总有你喜欢的吧^-^
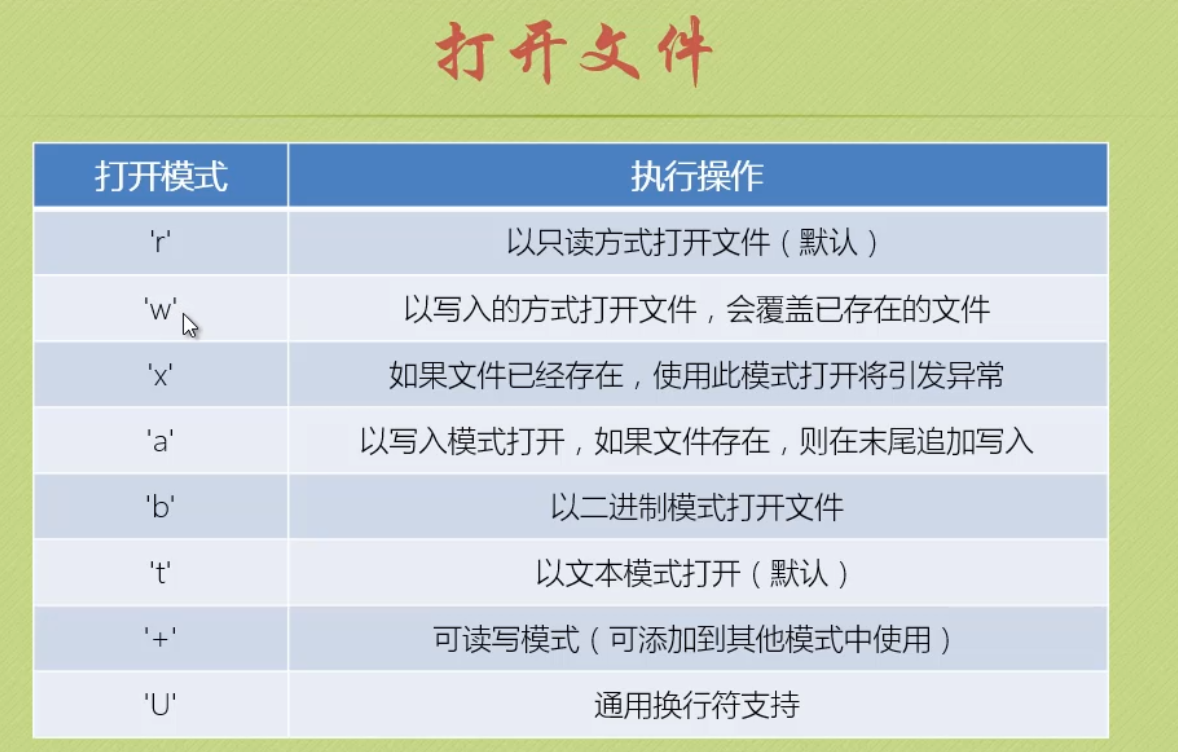
哎呀呀,打开完文件后,那你想下我们要干嘛呢?读文件内容或者写东西进入文件对不?因此就有了下面方法,哎,专业术语叫文件对象方法,老记不住专业名称,你们可得记住哟!还有虽然Python有垃圾回收机制,但是我们编辑读取文件时,完成操作后记得关闭文件哟,不然突然断电那内存内的数据可是会不见的喔,因为我们编辑的时候是保存在内存的,只有关闭文件时才会保存到本地!

说了这么多,接下来有道题目很好玩。尝试着去完成吧^-^
任务:将文件(record.txt)中的数据进行分割并按照以下规律保存起来:
小甲鱼的对话单独保存为boy_*.txt的文件(去掉“小甲鱼:”)
小客服的对话单独保存为girl_*.txt的文件(去掉“小客服:”)
文件中总共有三段对话,分别保存为boy_1.txt, girl_1.txt,boy_2.txt, girl_2.txt, boy_3.txt, gril_3.txt共6个文件(提示:文件中不同的对话间已经使用“==========”分割)
record.txt文件内容如下:
小客服:小甲鱼,今天有客户问你有没有女朋友?
小甲鱼:咦??
小客服:我跟她说你有女朋友了!
小甲鱼:。。。。。。
小客服:她让你分手后考虑下她!然后我说:"您要买个优盘,我就帮您留意下~"
小甲鱼:然后呢?
小客服:她买了两个,说发一个货就好~
小甲鱼:呃。。。。。。你真牛!
小客服:那是,谁让我是鱼C最可爱小客服嘛~
小甲鱼:下次有人想调戏你我不阻止~
小客服:滚!!!
================================================================================
小客服:小甲鱼,有个好评很好笑哈。
小甲鱼:哦?
小客服:"有了小甲鱼,以后妈妈再也不用担心我的学习了~"
小甲鱼:哈哈哈,我看到丫,我还发微博了呢~
小客服:嗯嗯,我看了你的微博丫~
小甲鱼:哟西~
小客服:那个有条回复“左手拿著小甲魚,右手拿著打火機,哪裡不會點哪裡,so easy ^_^”
小甲鱼:T_T
================================================================================
小客服:小甲鱼,今天一个会员想找你
小甲鱼:哦?什么事?
小客服:他说你一个学生月薪已经超过12k了!!
小甲鱼:哪里的?
小客服:上海的
小甲鱼:那正常,哪家公司?
小客服:他没说呀。
小甲鱼:哦
小客服:老大,为什么我工资那么低啊??是时候涨涨工资了!!
小甲鱼:啊,你说什么?我在外边呢,这里好吵吖。。。。。。
小客服:滚!!!
以上即为文件内容,尝试着写出上面的代码吧,答案如下:
#coding=utf-8
def writefile(girl_list,boy_list,count): girl_file = open(r'D:\girl_'+ str(count) +'.txt','w') boy_file = open(r'D:\boy_'+ str(count) +'.txt','w')
girl_file.writelines(girl_list)
boy_file.writelines(boy_list) girl_file.close()
boy_file.close() def split_file():
boy_list = []
girl_list = []
count = 1
f = open(r'D:\record.txt') for each_line in f:
if each_line[:6] != '======':
(name,content) = each_line.split(':',1)
if name == '小客服':
girl_list.append(each_line) else:
boy_list.append(each_line) else:
writefile(girl_list,boy_list,count)
boy_list.clear()
girl_list.clear()
count += 1
writefile(girl_list,boy_list,count)
f.close() split_file()
上面的代码只是个人写的而已,记住代码的写法没有最好,只有更好,努力优化自己的代码吧。好了,介绍了文件的基本读写,那么接下来就应该介绍下相对应的文件系统了。

大家千万不要烦恼,沉住气看完,看完后我会在后面留几道题巩固大家学习,一起努力吧!

附带几个题目,大家可以完成下看看,最后一个稍微有点复杂:
1、编写一个程序,统计目录下每个文件类型的文件数;
2、编写一个程序,用户输入文件名以及开始搜索的路径,搜索该文件是否存在,如遇到文件夹则进入文件夹继续搜索。
3、编写一个程序,用户输入关键字,查找当前文件夹内(如果当前文件夹内包含文件夹则进入文件夹继续搜索)所有含有该关键字的文本文件(.txt后缀),要求显示该文件所在的位置以及关键字在文件中的具体位置(第几行第几个字符)
答案:
第一题答案:
#coding=utf-8
#1:编写一个程序,统计当前目录下每个文件类型的文件数 import os
import os.path as op def file_num(mulu_role='D:\\'):
file_houzhui = []
filejia_count = 0
for wenjian in os.listdir(mulu_role):
file_luji = op.join(mulu_role,wenjian)
print(wenjian)
if op.isdir(file_luji):
filejia_count += 1
else:
(filename_first,filename_last) = op.splitext(wenjian)
file_houzhui.append(filename_last)
if filejia_count >= 1:
print('该文件下共有类型为【文件夹】的文件 %d个' %(filejia_count))
houzhui = list(set(file_houzhui))
for file_leixing in houzhui:
file_count = file_houzhui.count(file_leixing)
print('该文件下共有类型为【%s】的文件 %d个' %(file_leixing,file_count)) mulu_role = input('请输入你想查询的目录(默认D盘):') file_num(mulu_role)
第二题答案:
#coding=utf-8
import os def search_file(start_dir,target):
os.chdir(start_dir) for each_file in os.listdir(os.curdir) :
if each_file == target:
print(os.getcwd() + os.sep + each_file) #sep是路径分隔符
if os.path.isdir(each_file):
search_file(each_file,target) #递归调用
os.chdir(os.pardir) #递归调用后返回上一层目录 start_dir = input('请输入要查询的初始目录:')
target = input('请输入需要查找的目标文件:')
search_file(start_dir,target)
第三题答案:
#coding=utf-8 import os def print_pos(key_dict):
keys = key_dict.keys()
keys = sorted(keys) #由于字典是无序的,这里对行数进行排序
for each_key in kyes:
print('关键字出现在第 %s 行,第 %s 个位置。'%(each_key,str(key_dict[each_key]))) def pos_in_line(line,key):
pos = []
begin = line.find(key)
while begin != -1:
pos.append(begin + 1) #用户的角度从1开始数
begin = line.find(key,begin+1) #从下一个位置继续查找 return pos def search_in_file(file_name,key):
f = open(file_name)
count = 0 #记录行数
key_dict = dict() #用户存放key所在具体行数对应具体位置 for each_line in f:
count += 1
if key in each_line:
pos = pos_in_line(each_line,key) #key每行对应的位置
key_dict[count] = pos f.close()
return key_dict def search_files(key,detail):
all_files = os.walk(os.getcwd())
txt_files = [] for i in all_files:
for each_file in i[2]:
if os.path.splitext(each_file)[1] == '.txt': #根据后缀判断是否文本文件
each_file = os.path.join(i[0],each_file)
txt_files.append(each_file) for each_txt_file in txt_files:
key_dict = search_in_file(each_txt_file,key)
if key_dict:
print('=================================================')
print('在文件【%s】中找到关键字【%s】'%(each_txt_file,key))
if detail in ['YES','Yes','yes']:
print_pos(key_dict) key = input('请将该脚本放于待查找的文件夹内,请输入关键字:')
detail = input('请问是否需要打印关键字【%s】在文件中的具体位置(YES/NO):'%key)
search_files(key,detail)
注明:该文档的图片来自于鱼C工作室的视频,地址为:http://blog.fishc.com/category/python。
零基础学习python_文件(28-30课)的更多相关文章
- 零基础学习python_字符串(14-15课)
今天回顾下我之前学习python的第一个对象——字符串,这个对象真蛋疼,因为方法是最多的,也是最常见的类型,没有之一... 内容有点多,我就搜了下网上的资料,转载下这个看起来还不错的网址吧:http: ...
- 零基础学习python_模块(50-52课)
今天学了下模块,那什么是模块呢?其实我们写的以py结尾的一个文件就是一个模块,模块也就是程序 还记得我们之前学过容器.函数.类吧 容器 -> 数据的封装 函数 -> ...
- 零基础学习python_字典(25-26课)
今天学到后面的知识,突然发现之前学习到的字典列表啥的都有点忘了,打算补一下之前学到的字典,到时候你看的时候,字符串.列表.字典.元祖这几个没啥顺序,刚开始学的时候了解下方法,当然你可以死记硬背下,后面 ...
- 零基础学习python_异常处理(32-33课)
我们写完python执行的时候是不是经常会遇到报错,而且报错都是大片红字,这样给别人的感受就是你写的程序怎么老是出问题啊,这样我们还咋么混下去呢?于是乎,就有了异常处理的东东. python的try语 ...
- 零基础学习python_爬虫(53课)
1.Url的格式简单介绍,如下图: 2.我们要对网站进行访问,需要用到python中的一个模块或者说一个包吧,urllib(这个在python2中是urllib+urllib2,python3将这两个 ...
- 零基础学习python_生成器(49课)
一个生成器函数的定义很像一个普通的函数,除了当它要生成一个值的时候,使用yield关键字而不是return.如果一个def的主体包含yield,这个函数会自动变成一个生成器(即使它包含一个return ...
- 零基础学习python_类和对象(36-40课)
今天我们开始学习面向对象的知识咯,之前我对面向对象也学的懵懵的,因为感觉知道好像又不是特别清楚,接下来我们一起来学习类和对象吧.零基础的课程我都是看小甲鱼的视频学的,没基础的可以去这个网址下载视频学习 ...
- 零基础学习python_魔法方法(41-48课)(迭代器)
接下来这个为啥要叫魔法方法呢,额,这个嘛我是跟小甲鱼的视频取的名字一样的,因为会讲比较多杂的东西,有... 魔法方法详细阅读地址:http://bbs.fishc.com/thread-48793-1 ...
- 零基础学习python_列表和元组(10-13课)
一时兴起今天又回过头来补一下列表和元组,先来说说列表哈,列表其实是python最经常用到的数据类型了,不仅经常用还很强大呢,这个跟C语言里面的数组是类似的,列表当然也可以增删改查,不过我可没打算用之前 ...
随机推荐
- tornado请求头/状态码/接口 笔记
set_header()/set_default_headers() set_header():设置请求头数据 set_default_headers():设置默认请求头数据 import torna ...
- MapReduce案例:统计共同好友+订单表多表合并+求每个订单中最贵的商品
案例三: 统计共同好友 任务需求: 如下的文本, A:B,C,D,F,E,OB:A,C,E,KC:F,A,D,ID:A,E,F,LE:B,C,D,M,LF:A,B,C,D,E,O,MG:A,C,D,E ...
- RedHat如何关闭防火墙
1.查看防火墙是否已开启 #可以查看到iptables服务的当前状态. service iptables status 上图表示防火墙已关闭. 2.关闭防火墙 关闭防火墙的方法为: 1)永久性生 ...
- CentOS6.5 安装+ Tengine + PHP + MySQL
简介: Tengine是由淘宝网发起的Web服务器项目.它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性.Tengine的性能和稳定性已经在大型的网站如淘宝网,天猫商城等得到了 ...
- oracle rename数据文件的两种方法
oracle rename数据文件的两种方法 2012-12-11 20:44 10925人阅读 评论(0) 收藏 举报 分类: oracle(98) 版权声明:本文为博主原创文章,未经博主允许不 ...
- windows server core 设置shell 及切换
hkey_local_machine/software/Microsoft/windows nt/currentversion/winlogon/shell 1)windows server 2012 ...
- vue中为对象添加值的问题
demo: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- Python中的self和init
From: https://www.crifan.com/summary_the_meaning_of_self_and___init___in_python_and_why_need_them/ 背 ...
- 在windows 7中vagrant up 无反应,没任何信息输出
本文转载自:https://blog.csdn.net/cow66/article/details/77993908 我的系统是windows 7 安装了vagrant,当运行vagrant up时, ...
- 【mysql】IP地址整数int和varchar的转换
mysql中IP地址的存储 IP:如192.168.12.145,在存储时,若是采用varchar进行存储,存在两个主要缺点: 存储空间占用较大: 查询检索较慢: 解决方式: 存储时:将字符串类型的I ...