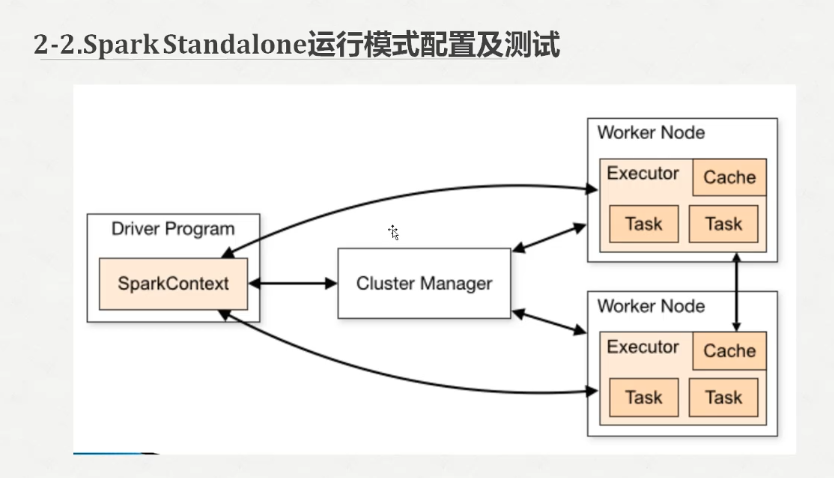
Spark2.X集群运行模式
rn
启动



先把这三个文件的名字改一下

配置slaves

配置spark-env.sh
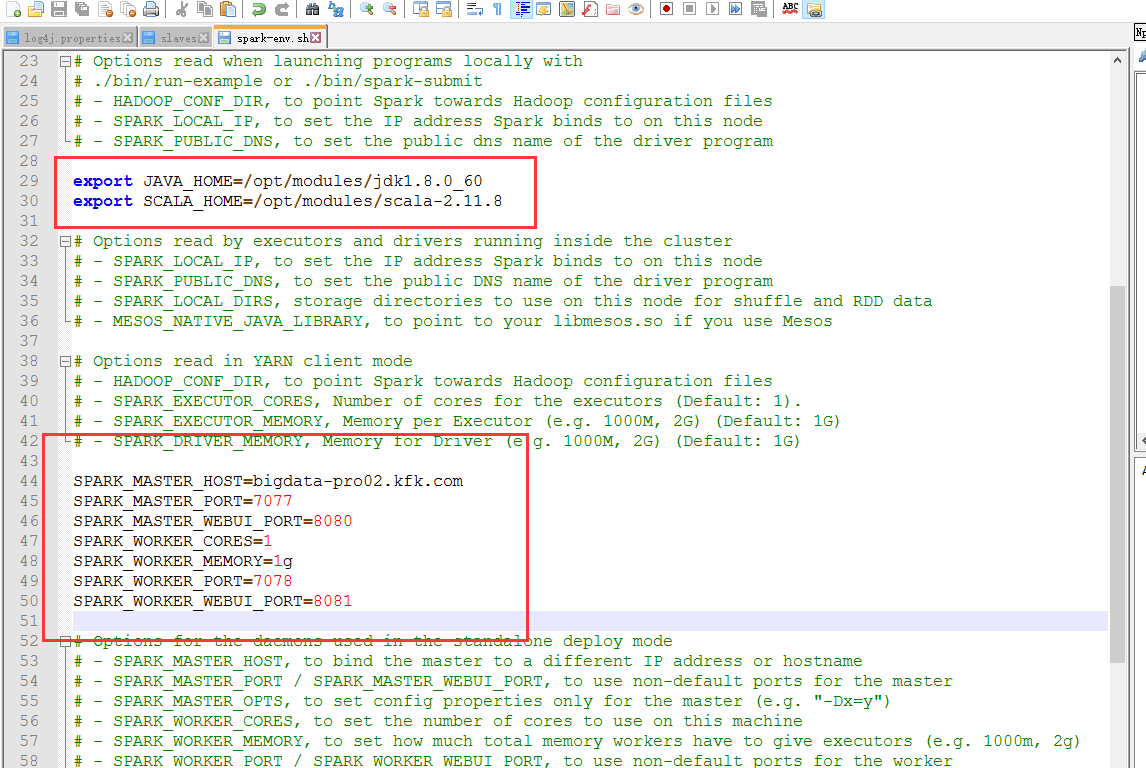
export JAVA_HOME=/opt/modules/jdk1..0_60
export SCALA_HOME=/opt/modules/scala-2.11. SPARK_MASTER_HOST=bigdata-pro02.kfk.com
SPARK_MASTER_PORT=
SPARK_MASTER_WEBUI_PORT=
SPARK_WORKER_CORES=
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=
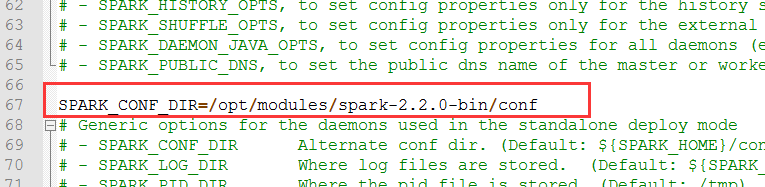
SPARK_WORKER_WEBUI_PORT= SPARK_CONF_DIR=/opt/modules/spark-2.2.-bin/conf
将spark 配置分发到其他节点并修改每个节点特殊配置
scp -r spark-2.2.0-bin bigdata-pro01.kfk.com:/opt/modules/
scp -r spark-2.2.0-bin bigdata-pro03.kfk.com:/opt/modules/
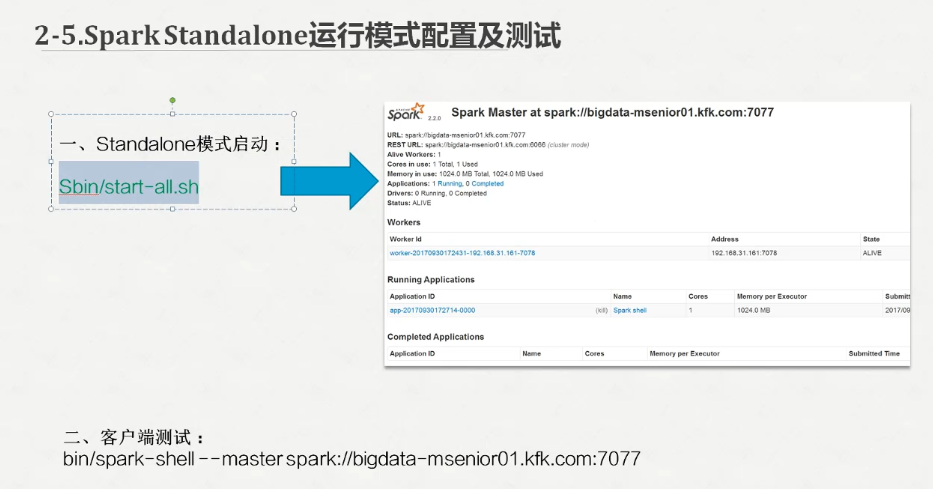

http://bigdata-pro02.kfk.com:8080/
在浏览器打开这个页面
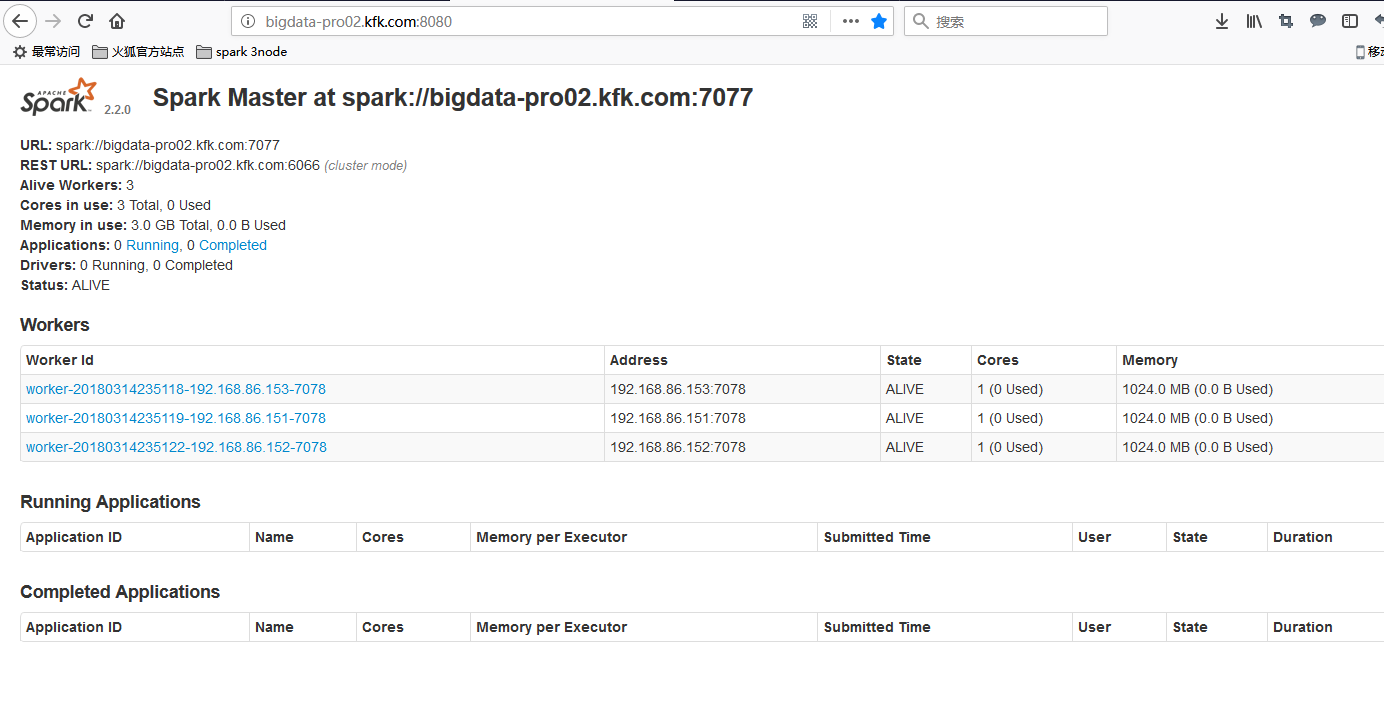
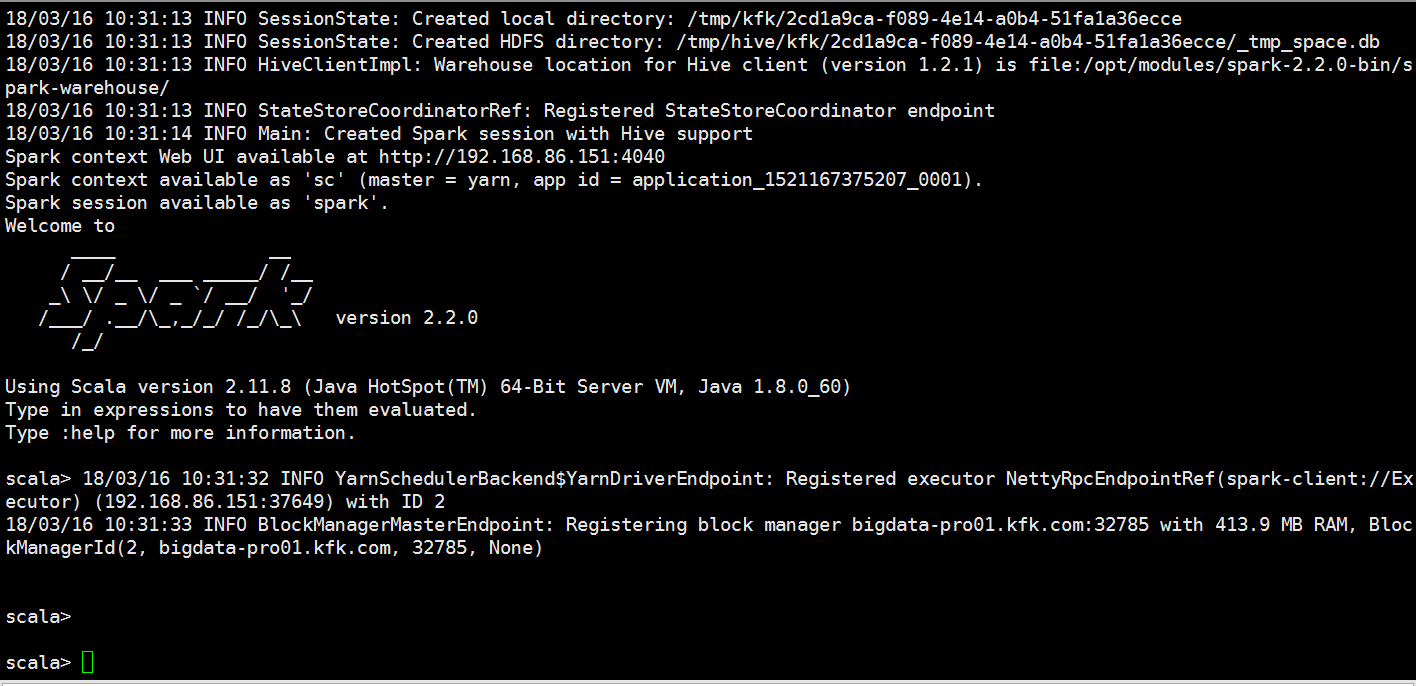
客户端测试
bin/spark-shell --master spark://bigdata-pro02.kfk.com:7077
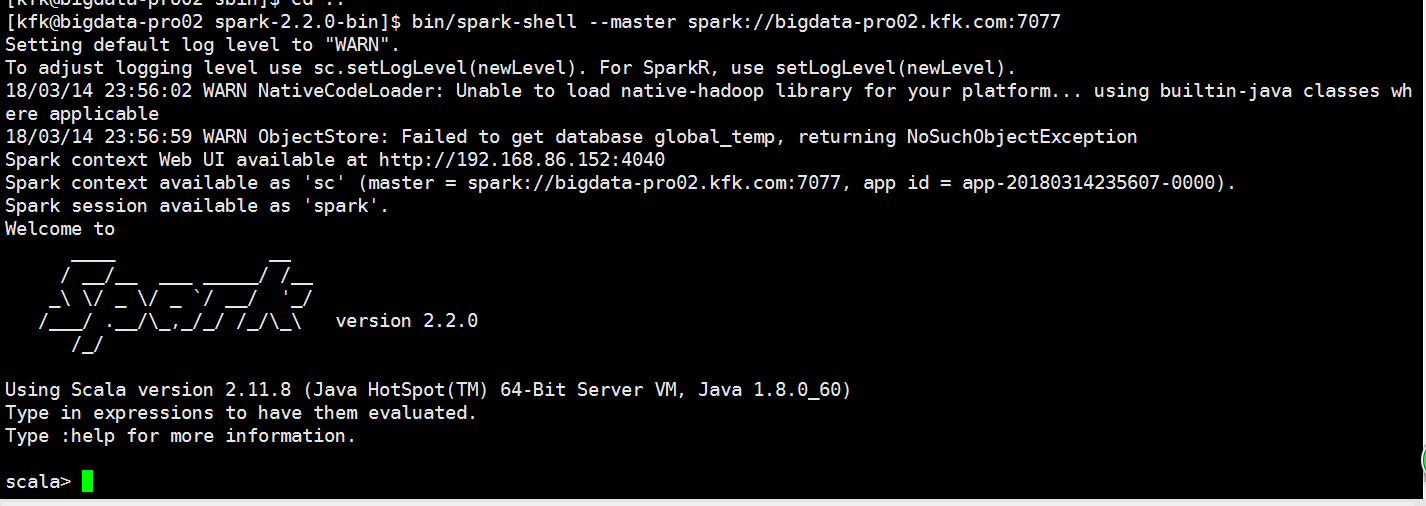
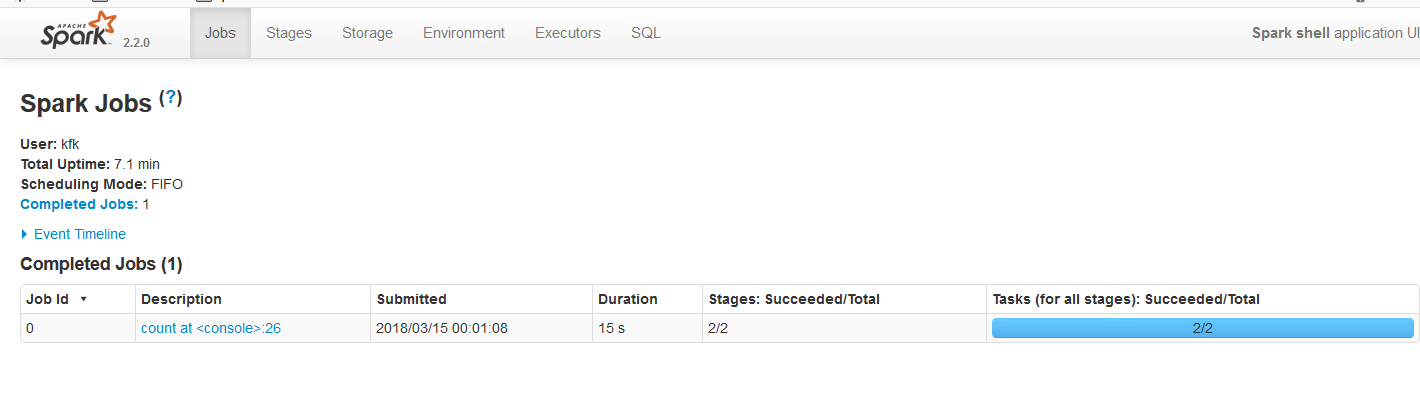
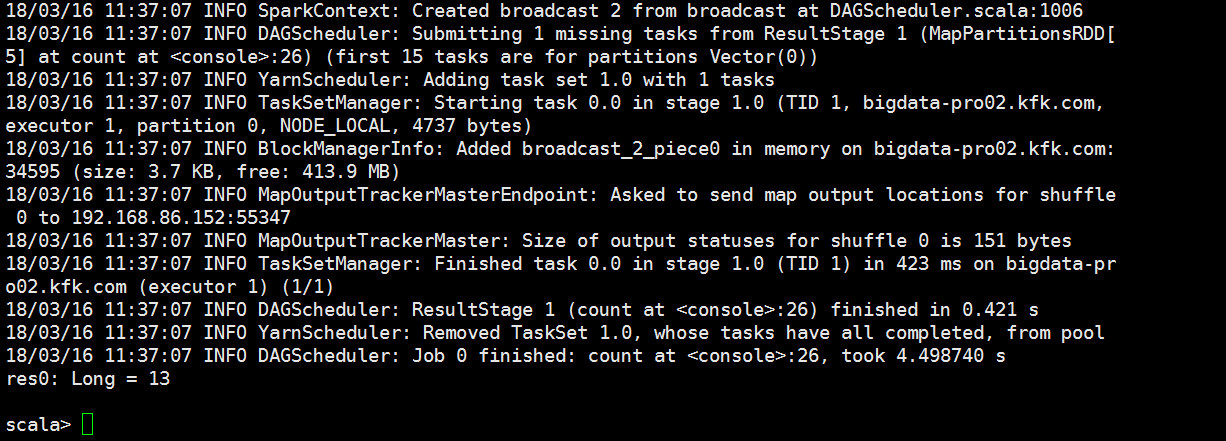
执行一个job

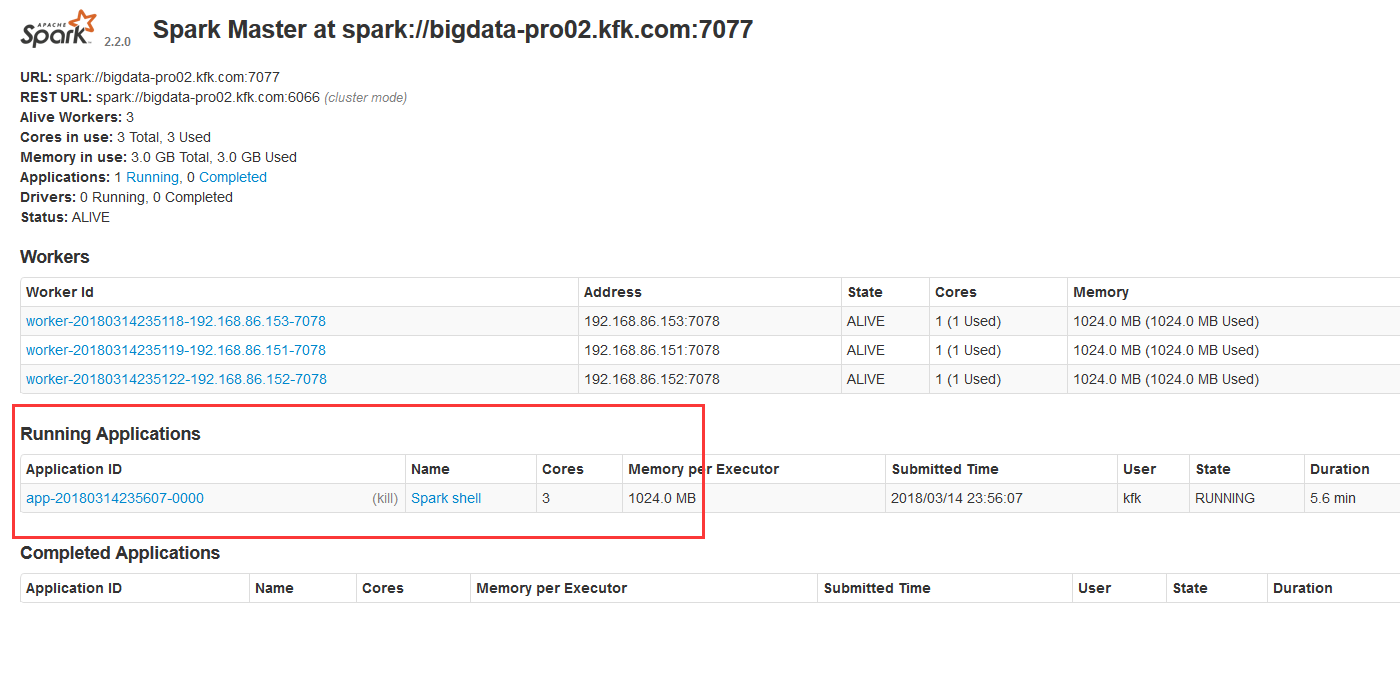

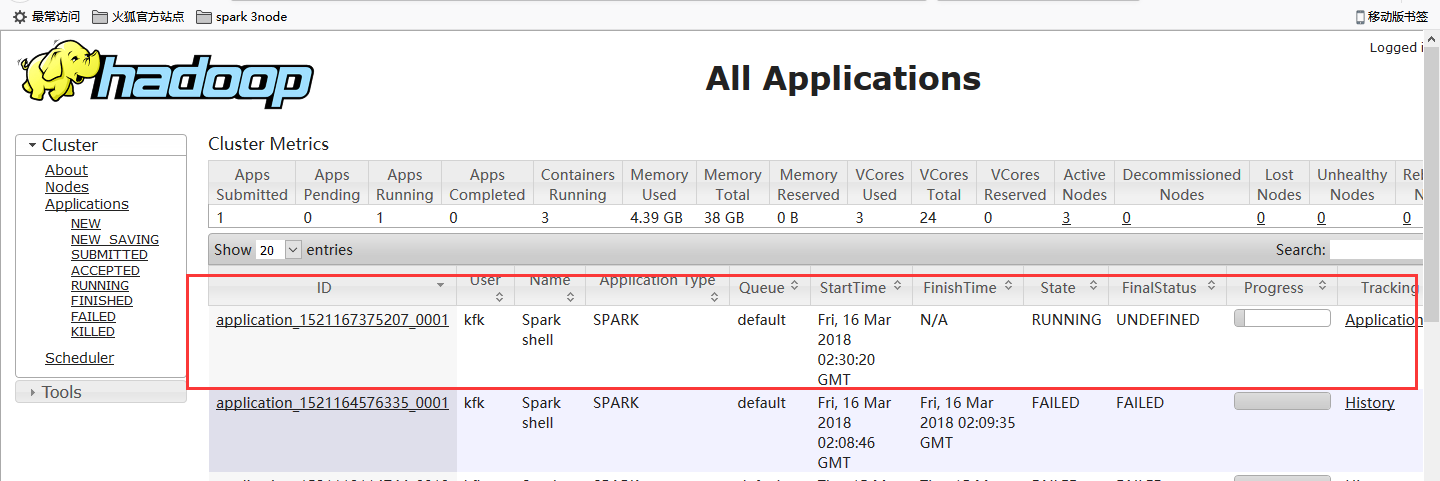
点进去看看
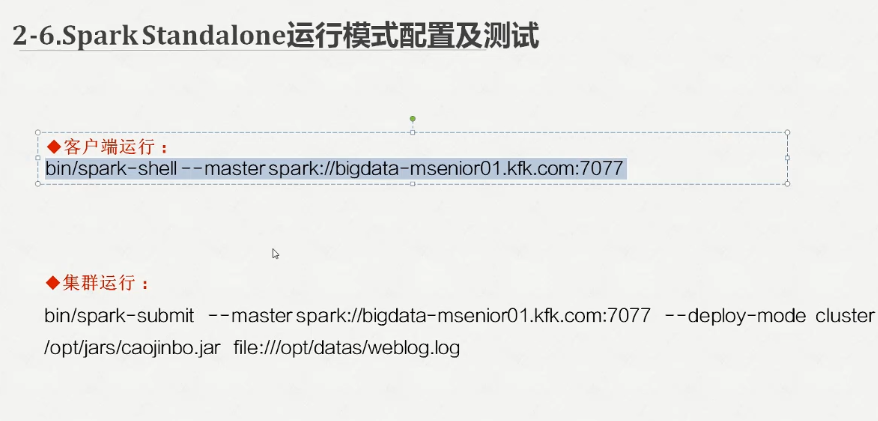
bin/spark-submit --master spark://bigdata-pro02.kfk.com:7077 --deploy-mode cluster /opt/jars/sparkStu.jar file:///opt/datas/stu.txt

可以看到报错了!!!!
我们应该使用这个模式



启动一下yarn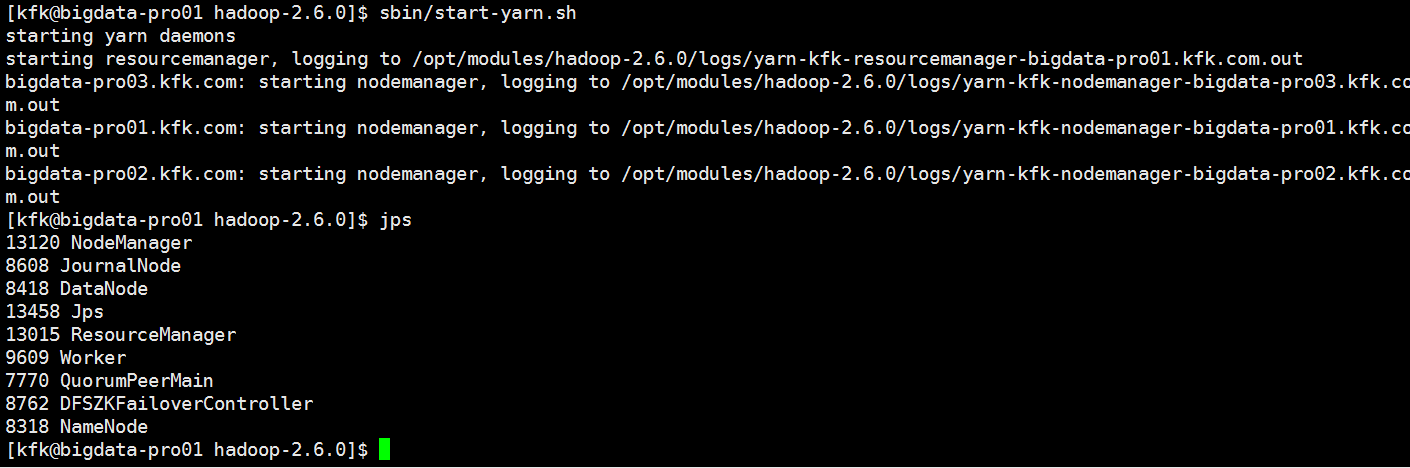
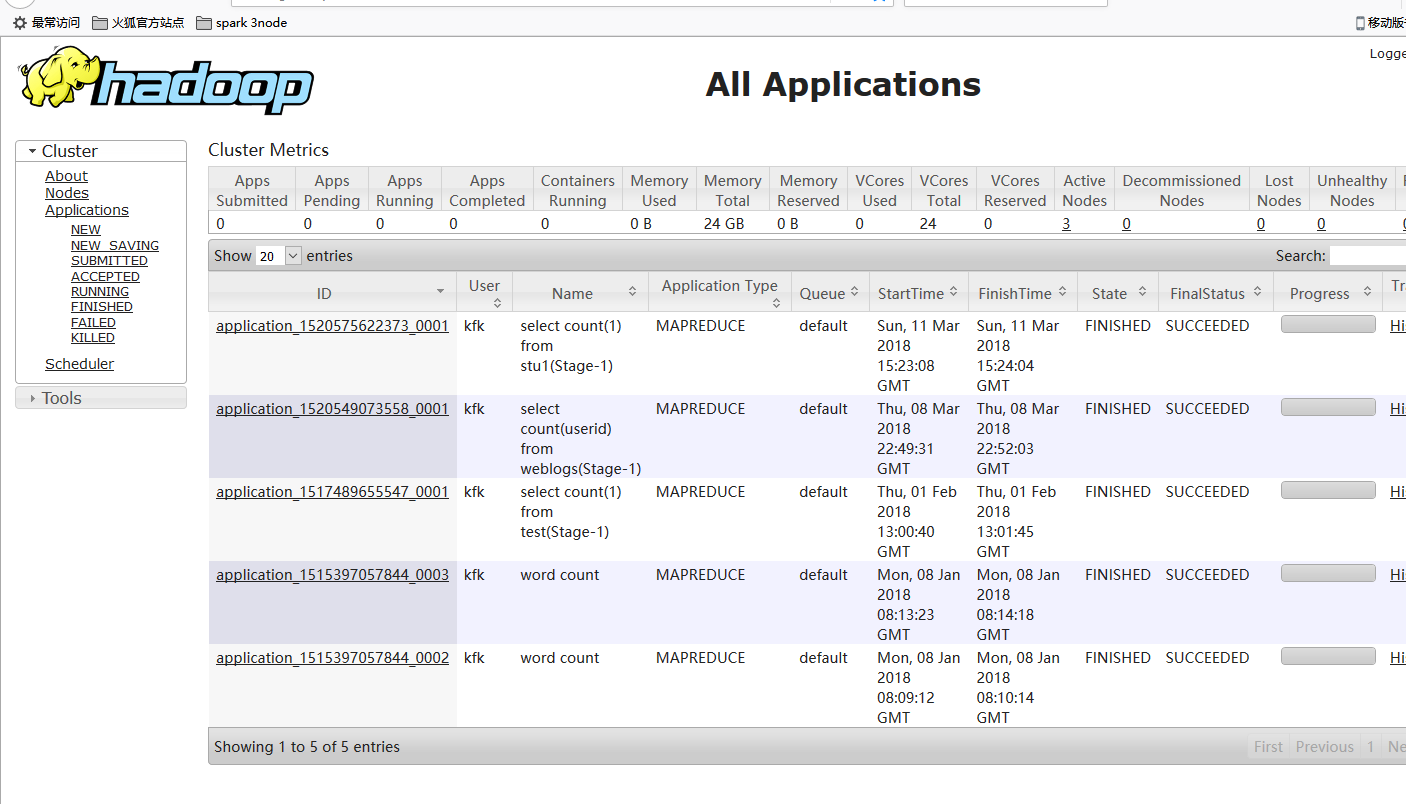
http://bigdata-pro01.kfk.com:8088/cluster

我们就把HADOOP_CONF_DIR配置近来
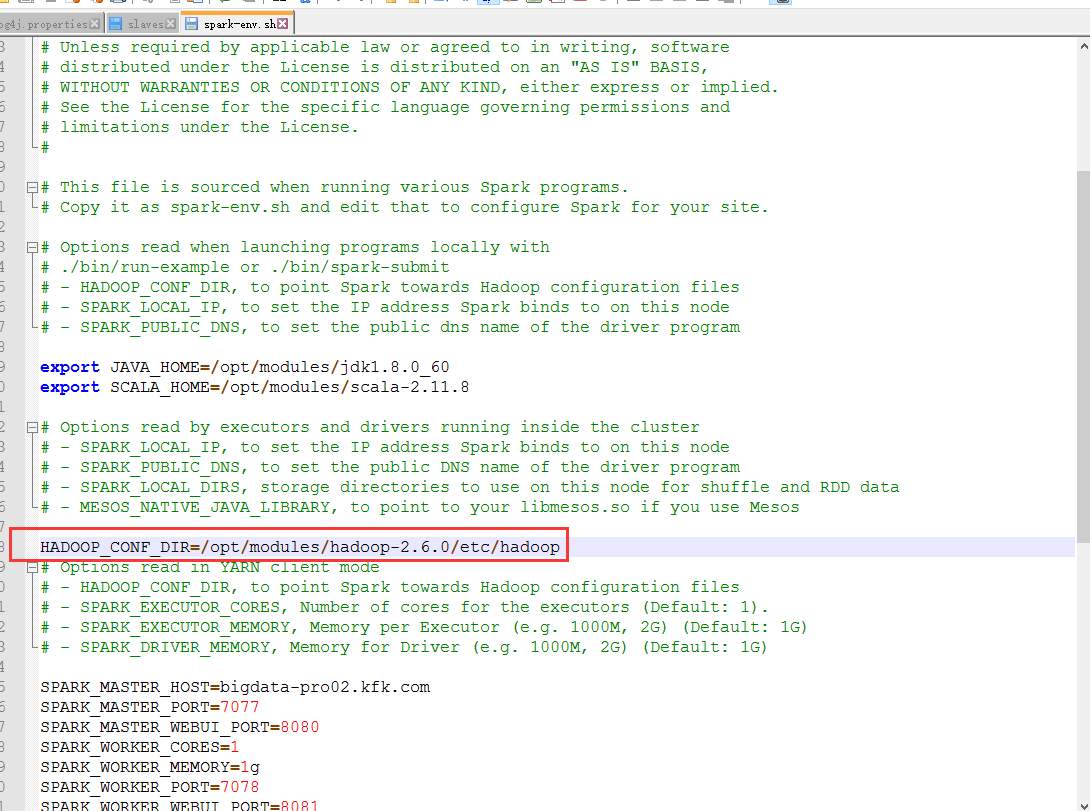
其他两个节点也一样。
再次运行,还是报错了
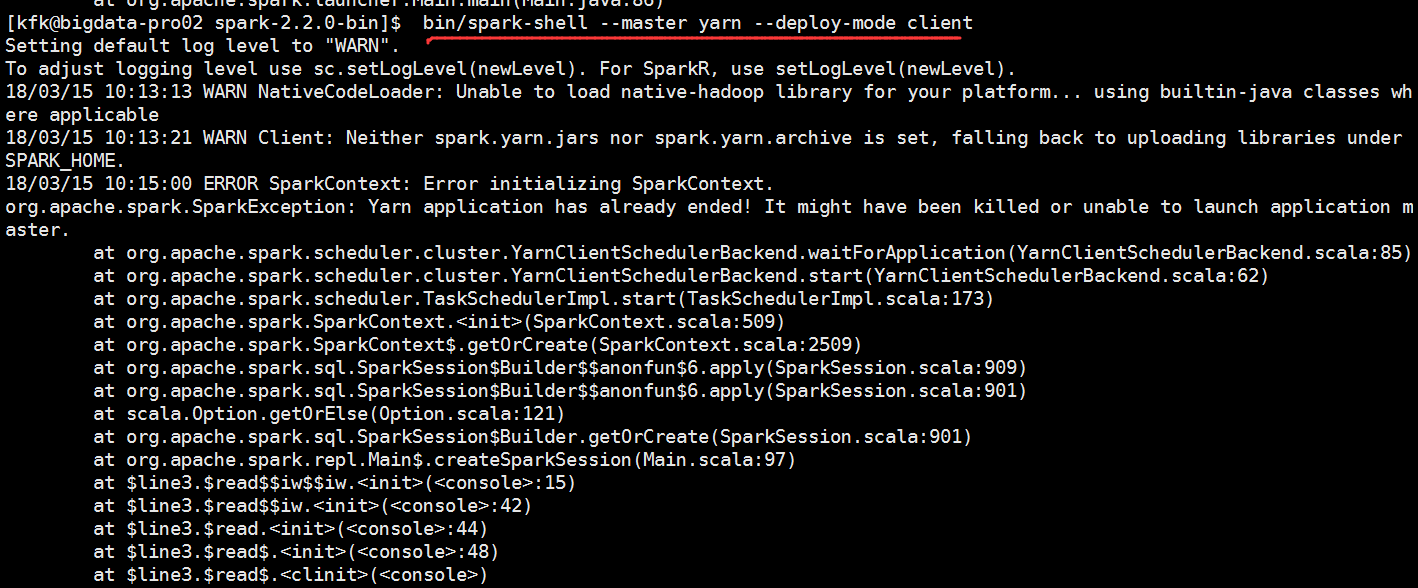
[kfk@bigdata-pro02 spark-2.2.-bin]$ bin/spark-shell --master yarn --deploy-mode client
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
// :: WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
// :: ERROR SparkContext: Error initializing SparkContext.
org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master.
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$.apply(SparkSession.scala:)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$.apply(SparkSession.scala:)
at scala.Option.getOrElse(Option.scala:)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:)
at org.apache.spark.repl.Main$.createSparkSession(Main.scala:)
at $line3.$read$$iw$$iw.<init>(<console>:)
at $line3.$read$$iw.<init>(<console>:)
at $line3.$read.<init>(<console>:)
at $line3.$read$.<init>(<console>:)
at $line3.$read$.<clinit>(<console>)
at $line3.$eval$.$print$lzycompute(<console>:)
at $line3.$eval$.$print(<console>:)
at $line3.$eval.$print(<console>)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at scala.tools.nsc.interpreter.IMain$ReadEvalPrint.call(IMain.scala:)
at scala.tools.nsc.interpreter.IMain$Request.loadAndRun(IMain.scala:)
at scala.tools.nsc.interpreter.IMain$WrappedRequest$$anonfun$loadAndRunReq$.apply(IMain.scala:)
at scala.tools.nsc.interpreter.IMain$WrappedRequest$$anonfun$loadAndRunReq$.apply(IMain.scala:)
at scala.reflect.internal.util.ScalaClassLoader$class.asContext(ScalaClassLoader.scala:)
at scala.reflect.internal.util.AbstractFileClassLoader.asContext(AbstractFileClassLoader.scala:)
at scala.tools.nsc.interpreter.IMain$WrappedRequest.loadAndRunReq(IMain.scala:)
at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:)
at scala.tools.nsc.interpreter.IMain.interpret(IMain.scala:)
at scala.tools.nsc.interpreter.ILoop.interpretStartingWith(ILoop.scala:)
at scala.tools.nsc.interpreter.ILoop.command(ILoop.scala:)
at scala.tools.nsc.interpreter.ILoop.processLine(ILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$.apply$mcV$sp(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$.apply(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$.apply(SparkILoop.scala:)
at scala.tools.nsc.interpreter.IMain.beQuietDuring(IMain.scala:)
at org.apache.spark.repl.SparkILoop.initializeSpark(SparkILoop.scala:)
at org.apache.spark.repl.SparkILoop.loadFiles(SparkILoop.scala:)
at scala.tools.nsc.interpreter.ILoop$$anonfun$process$.apply$mcZ$sp(ILoop.scala:)
at scala.tools.nsc.interpreter.ILoop$$anonfun$process$.apply(ILoop.scala:)
at scala.tools.nsc.interpreter.ILoop$$anonfun$process$.apply(ILoop.scala:)
at scala.reflect.internal.util.ScalaClassLoader$.savingContextLoader(ScalaClassLoader.scala:)
at scala.tools.nsc.interpreter.ILoop.process(ILoop.scala:)
at org.apache.spark.repl.Main$.doMain(Main.scala:)
at org.apache.spark.repl.Main$.main(Main.scala:)
at org.apache.spark.repl.Main.main(Main.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
// :: WARN YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors before the AM has registered!
// :: WARN MetricsSystem: Stopping a MetricsSystem that is not running
org.apache.spark.SparkException: Yarn application has already ended! It might have been killed or unable to launch application master.
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.waitForApplication(YarnClientSchedulerBackend.scala:)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$.apply(SparkSession.scala:)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$.apply(SparkSession.scala:)
at scala.Option.getOrElse(Option.scala:)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:)
at org.apache.spark.repl.Main$.createSparkSession(Main.scala:)
... elided
<console>:: error: not found: value spark
import spark.implicits._
^
<console>:: error: not found: value spark
import spark.sql
^
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.
/_/ Using Scala version 2.11. (Java HotSpot(TM) -Bit Server VM, Java 1.8.0_60)
Type in expressions to have them evaluated.
Type :help for more information.

我们来修改这个配置文件yarn-site.xml
加上这两项
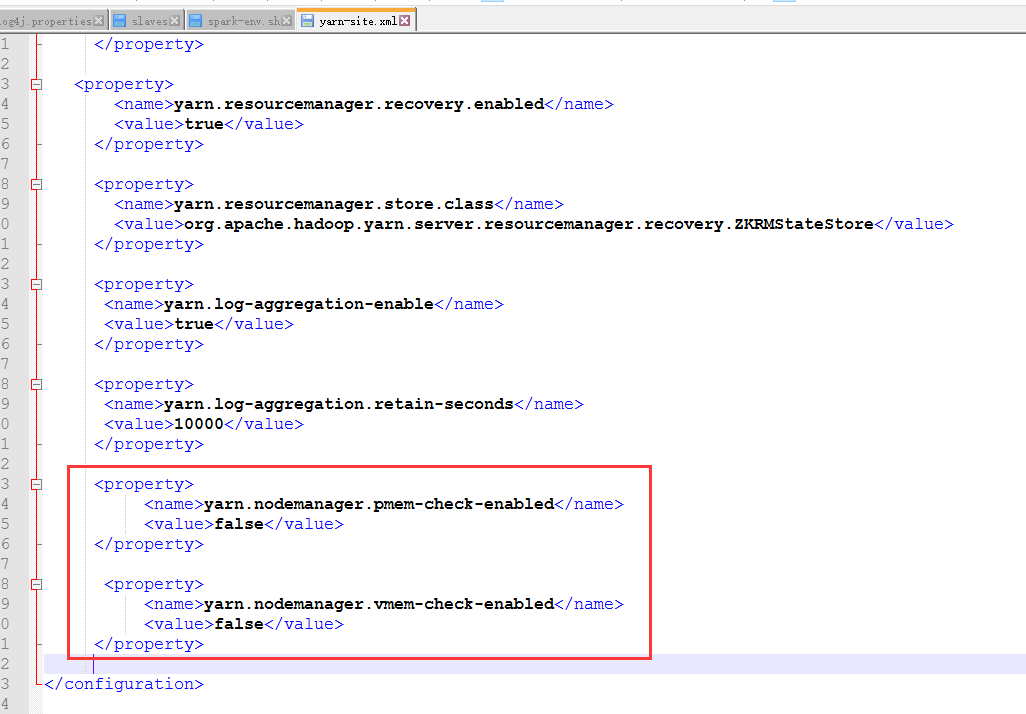
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property> <property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
其他两个节点的yarn-site.xml也是一样,这里我就不多说了。或者是我们把节点2的这个文件分发给另外两个节点也是可以的。
不过分发之前先把yarn停下来

还有一点细节一定要注意,报这个错误其实原因有很多的,不单单是说内存不够的问题,内存不够只是其中一个原因,还有一个细节我们容易漏掉的就jdk版本一定要跟spark-env.sh的一致
尤其要注意hadoop里面的这两个文件

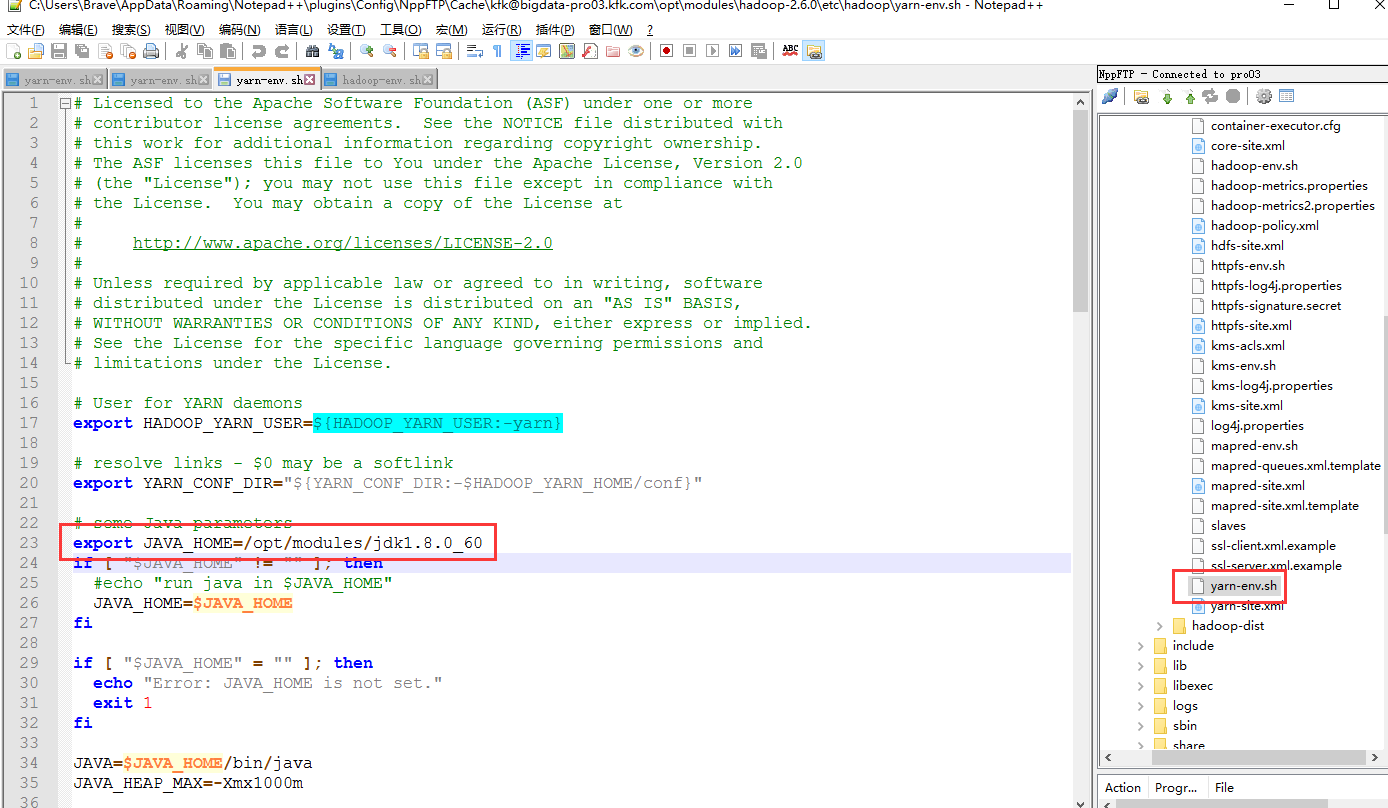
我这里是以其中一个节点来说明,其他两个节点的hadoop配置文件也是这样修改,因为我们之前的hadoop是用jdk1.7版本的,spark改用1.8版本了,所以关于hadoop的所有配置文件有关配置jdk的都某要改成1.8
我们再次启动yarn
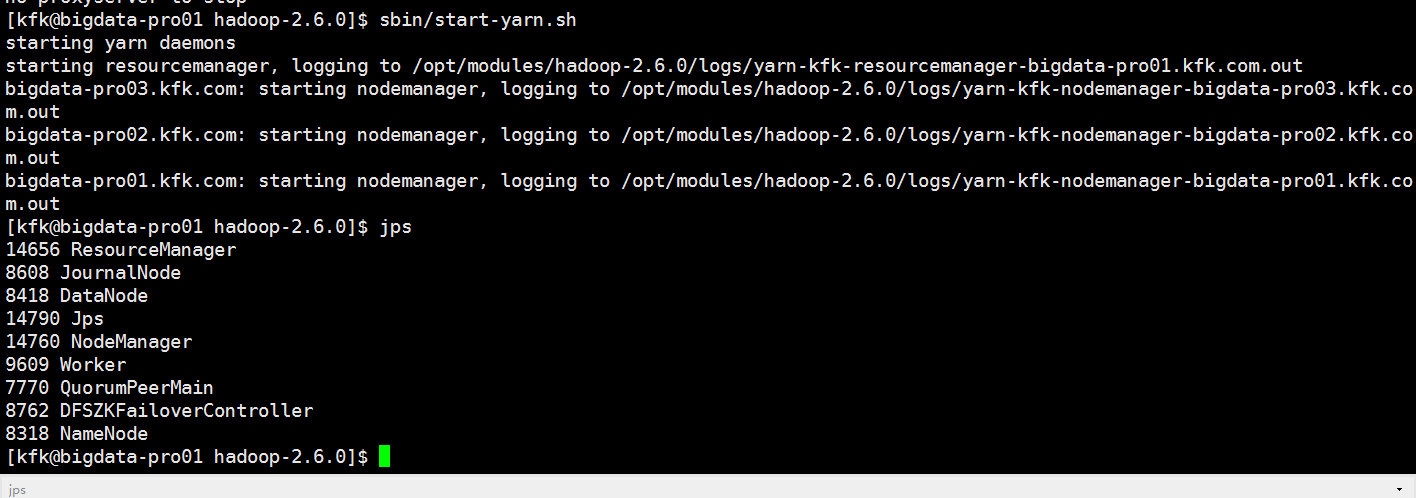
启动spark(由于考虑到spark比较消耗内存,我就把spark的master切换到节点1去了,因为节点1我给他分配了4G内存)
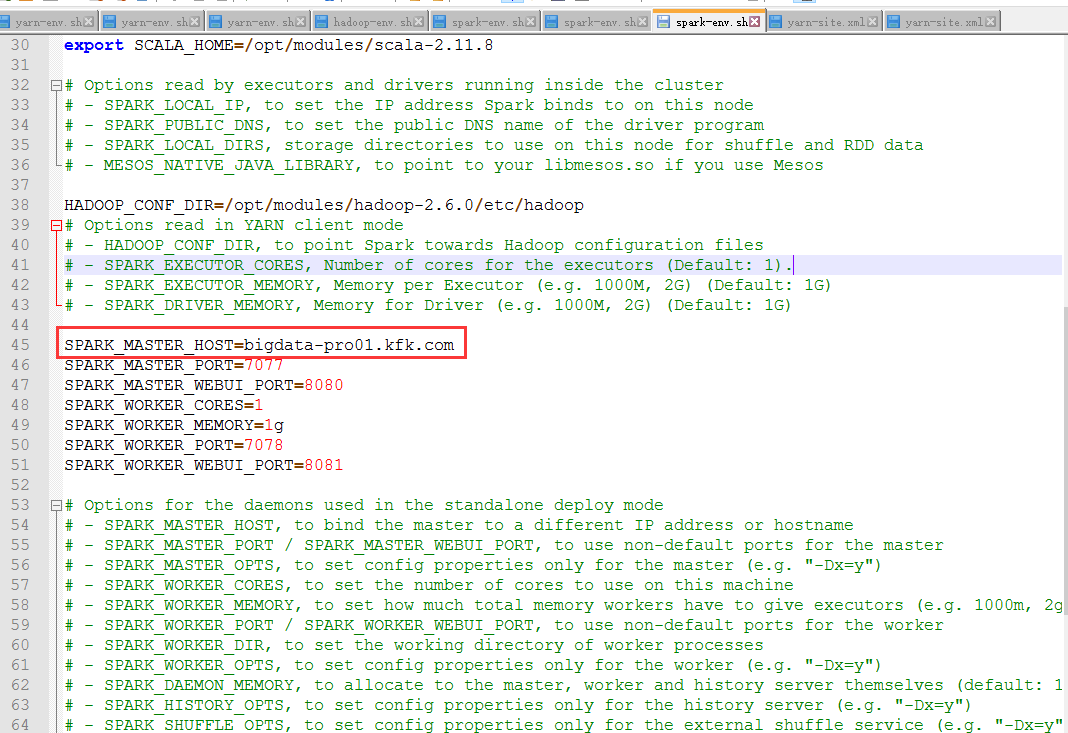
记得修改spark-env.sh文件(3个节点都改)


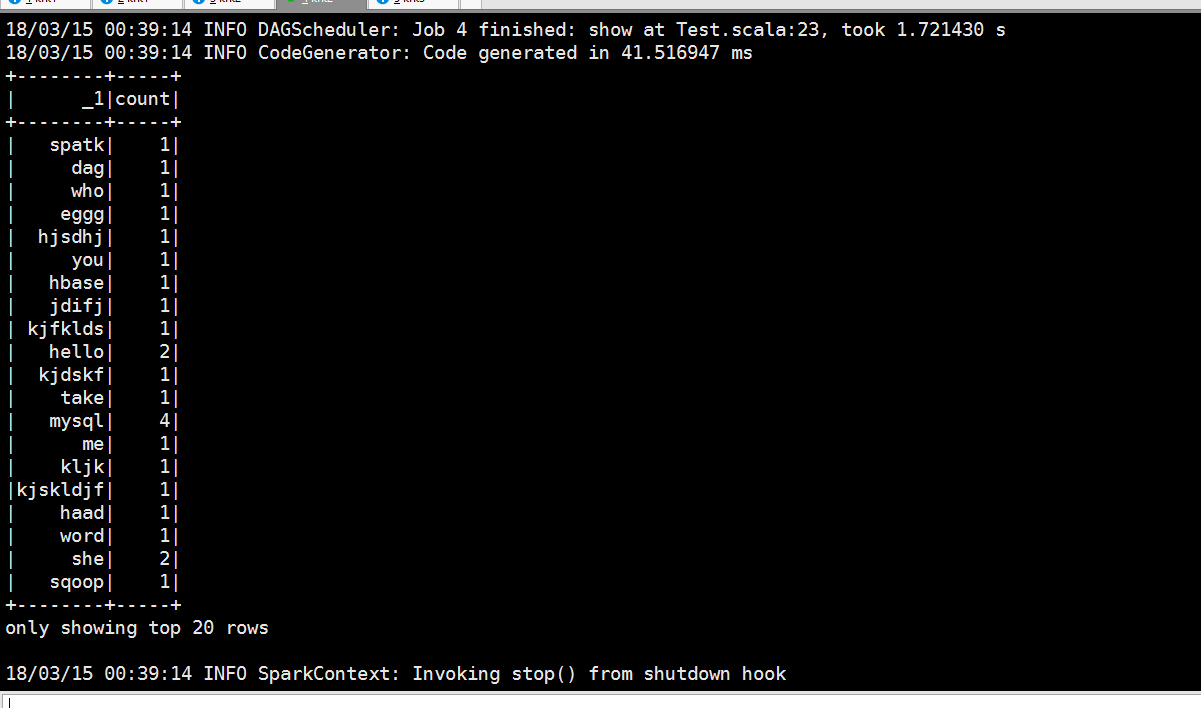
进行分组求和

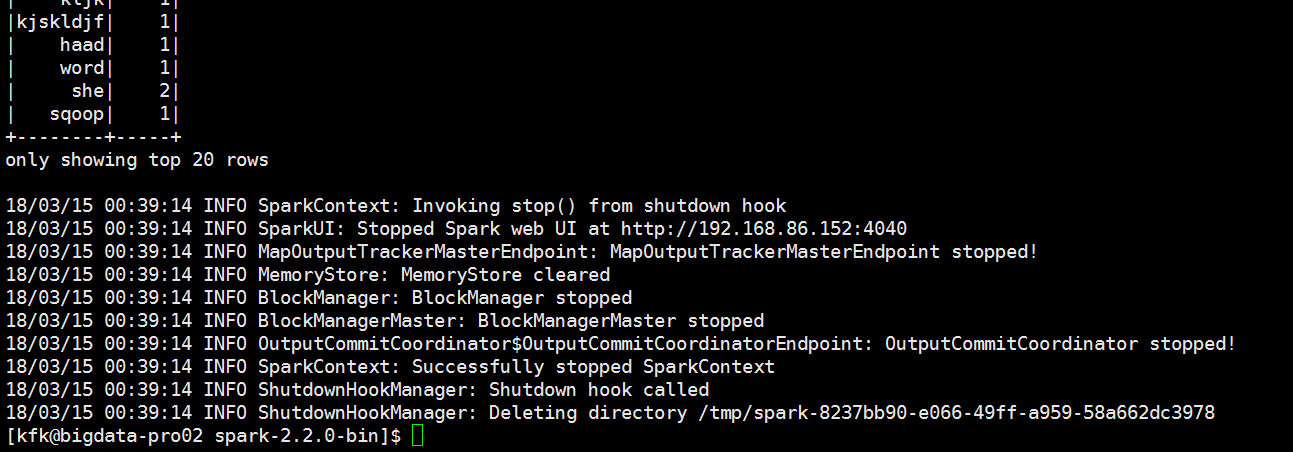
退出

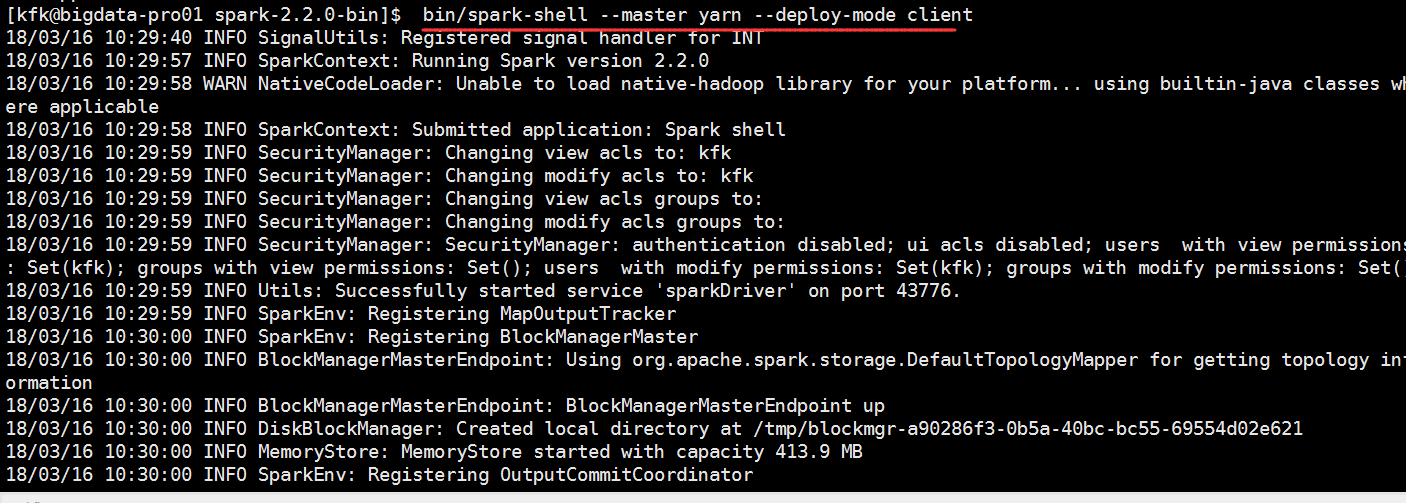
用submit模式跑一下
可以看到报错了
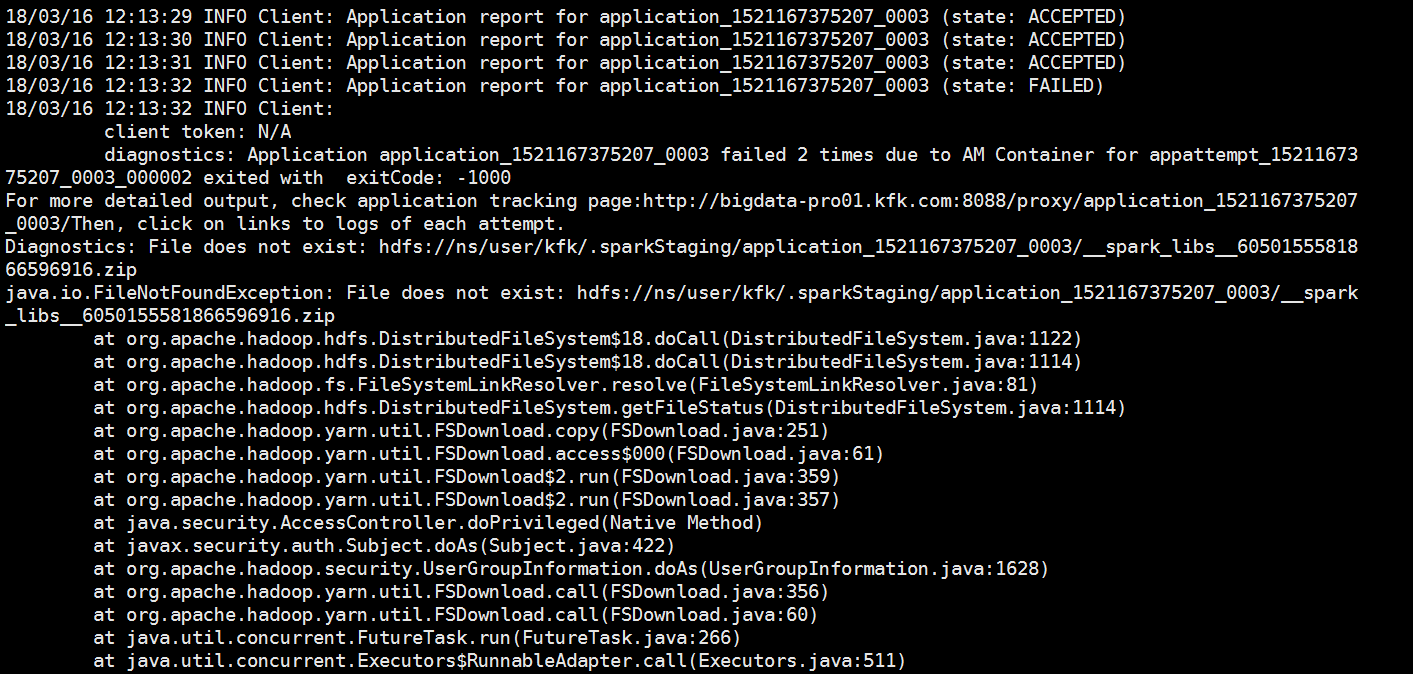
[kfk@bigdata-pro01 spark-2.2.-bin]$ bin/spark-submit --class com.spark.test.Test --master yarn --deploy-mode cluster /opt/jars/sparkStu.jar file:///opt/datas/stu.txt
// :: WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO Client: Requesting a new application from cluster with NodeManagers
// :: INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster ( MB per container)
// :: INFO Client: Will allocate AM container, with MB memory including MB overhead
// :: INFO Client: Setting up container launch context for our AM
// :: INFO Client: Setting up the launch environment for our AM container
// :: INFO Client: Preparing resources for our AM container
// :: WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
// :: INFO Client: Uploading resource file:/tmp/spark-edc616a1-10bf--9d7c-91a2430844f8/__spark_libs__6050155581866596916.zip -> hdfs://ns/user/kfk/.sparkStaging/application_1521167375207_0003/__spark_libs__6050155581866596916.zip
// :: INFO Client: Uploading resource file:/opt/jars/sparkStu.jar -> hdfs://ns/user/kfk/.sparkStaging/application_1521167375207_0003/sparkStu.jar
// :: INFO Client: Uploading resource file:/tmp/spark-edc616a1-10bf--9d7c-91a2430844f8/__spark_conf__6419799297331143395.zip -> hdfs://ns/user/kfk/.sparkStaging/application_1521167375207_0003/__spark_conf__.zip
// :: INFO SecurityManager: Changing view acls to: kfk
// :: INFO SecurityManager: Changing modify acls to: kfk
// :: INFO SecurityManager: Changing view acls groups to:
// :: INFO SecurityManager: Changing modify acls groups to:
// :: INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(kfk); groups with view permissions: Set(); users with modify permissions: Set(kfk); groups with modify permissions: Set()
// :: INFO Client: Submitting application application_1521167375207_0003 to ResourceManager
// :: INFO YarnClientImpl: Submitted application application_1521167375207_0003
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -
queue: default
start time:
final status: UNDEFINED
tracking URL: http://bigdata-pro01.kfk.com:8088/proxy/application_1521167375207_0003/
user: kfk
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0003 (state: FAILED)
// :: INFO Client:
client token: N/A
diagnostics: Application application_1521167375207_0003 failed times due to AM Container for appattempt_1521167375207_0003_000002 exited with exitCode: -
For more detailed output, check application tracking page:http://bigdata-pro01.kfk.com:8088/proxy/application_1521167375207_0003/Then, click on links to logs of each attempt.
Diagnostics: File does not exist: hdfs://ns/user/kfk/.sparkStaging/application_1521167375207_0003/__spark_libs__6050155581866596916.zip
java.io.FileNotFoundException: File does not exist: hdfs://ns/user/kfk/.sparkStaging/application_1521167375207_0003/__spark_libs__6050155581866596916.zip
at org.apache.hadoop.hdfs.DistributedFileSystem$.doCall(DistributedFileSystem.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem$.doCall(DistributedFileSystem.java:)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:)
at org.apache.hadoop.yarn.util.FSDownload.copy(FSDownload.java:)
at org.apache.hadoop.yarn.util.FSDownload.access$(FSDownload.java:)
at org.apache.hadoop.yarn.util.FSDownload$.run(FSDownload.java:)
at org.apache.hadoop.yarn.util.FSDownload$.run(FSDownload.java:)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:)
at org.apache.hadoop.yarn.util.FSDownload.call(FSDownload.java:)
at org.apache.hadoop.yarn.util.FSDownload.call(FSDownload.java:)
at java.util.concurrent.FutureTask.run(FutureTask.java:)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:)
at java.util.concurrent.FutureTask.run(FutureTask.java:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:) Failing this attempt. Failing the application.
ApplicationMaster host: N/A
ApplicationMaster RPC port: -
queue: default
start time:
final status: FAILED
tracking URL: http://bigdata-pro01.kfk.com:8088/cluster/app/application_1521167375207_0003
user: kfk
Exception in thread "main" org.apache.spark.SparkException: Application application_1521167375207_0003 finished with failed status
at org.apache.spark.deploy.yarn.Client.run(Client.scala:)
at org.apache.spark.deploy.yarn.Client$.main(Client.scala:)
at org.apache.spark.deploy.yarn.Client.main(Client.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:)
at java.lang.reflect.Method.invoke(Method.java:)
at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.doRunMain$(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
// :: INFO ShutdownHookManager: Shutdown hook called
// :: INFO ShutdownHookManager: Deleting directory /tmp/spark-edc616a1-10bf--9d7c-91a2430844f8
[kfk@bigdata-pro01 spark-2.2.-bin]$
我们在idea把sparkStu的源码打开
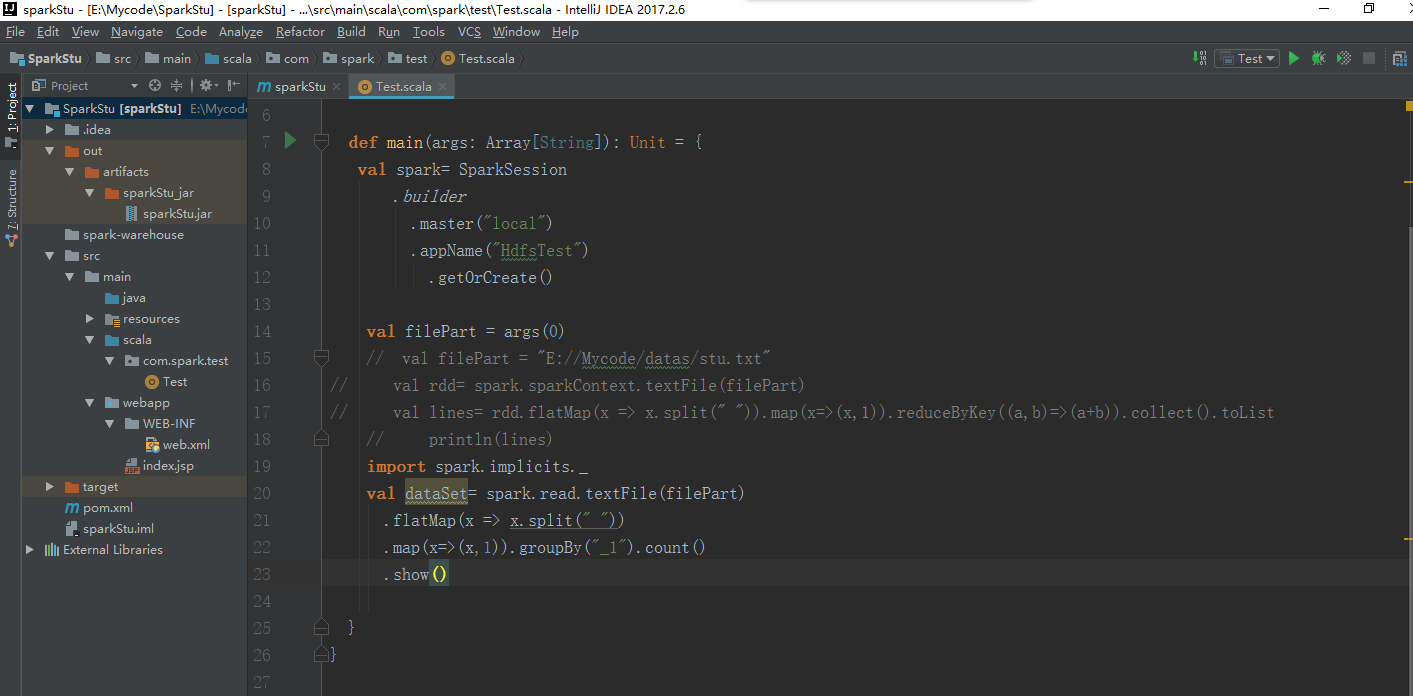
改一下这里
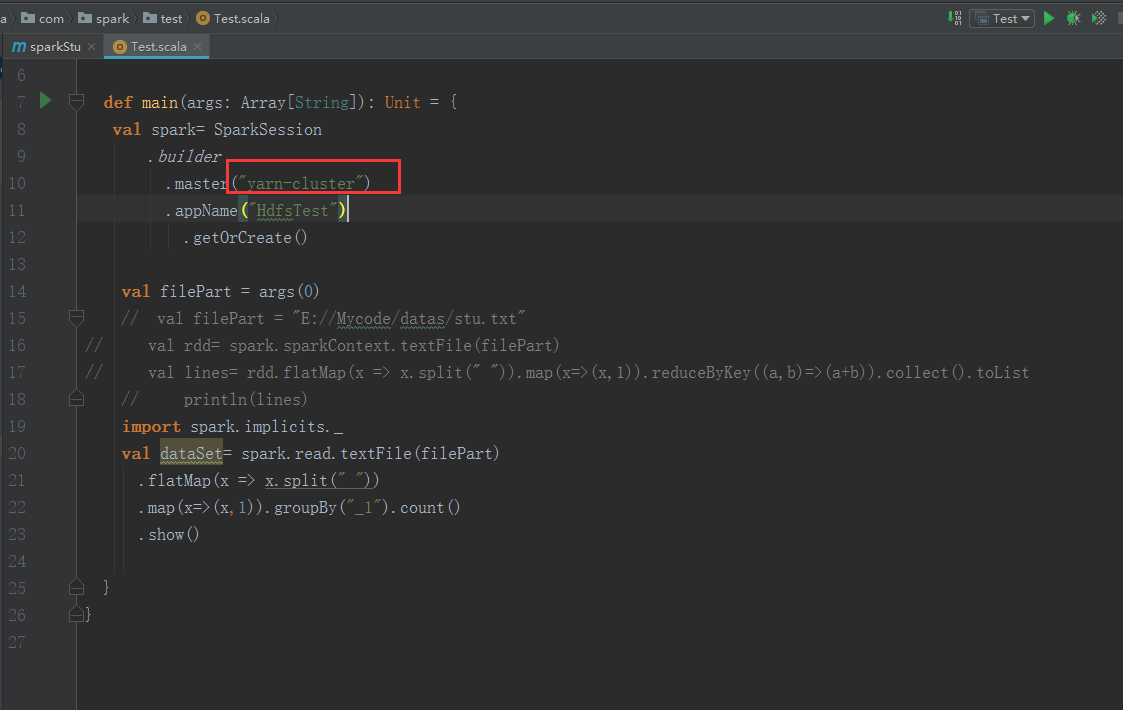


把包完之后我们把这个包再次上传(为了保险,我把3个节点都上传了,可能我比较SB)
先把原来的包干掉
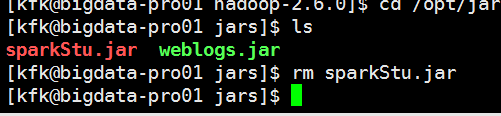

现在上传

再跑一次


可以看到成功了
[kfk@bigdata-pro01 spark-2.2.-bin]$ bin/spark-submit --class com.spark.test.Test --master yarn --deploy-mode cluster /opt/jars/sparkStu.jar file:///opt/datas/stu.txt
// :: WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO Client: Requesting a new application from cluster with NodeManagers
// :: INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster ( MB per container)
// :: INFO Client: Will allocate AM container, with MB memory including MB overhead
// :: INFO Client: Setting up container launch context for our AM
// :: INFO Client: Setting up the launch environment for our AM container
// :: INFO Client: Preparing resources for our AM container
// :: WARN Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
// :: INFO Client: Uploading resource file:/tmp/spark-43f281a9-034a-424b--d6d00addfff6/__spark_libs__8012713420631475441.zip -> hdfs://ns/user/kfk/.sparkStaging/application_1521167375207_0004/__spark_libs__8012713420631475441.zip
// :: INFO Client: Uploading resource file:/opt/jars/sparkStu.jar -> hdfs://ns/user/kfk/.sparkStaging/application_1521167375207_0004/sparkStu.jar
// :: INFO Client: Uploading resource file:/tmp/spark-43f281a9-034a-424b--d6d00addfff6/__spark_conf__8776342149712582279.zip -> hdfs://ns/user/kfk/.sparkStaging/application_1521167375207_0004/__spark_conf__.zip
// :: INFO SecurityManager: Changing view acls to: kfk
// :: INFO SecurityManager: Changing modify acls to: kfk
// :: INFO SecurityManager: Changing view acls groups to:
// :: INFO SecurityManager: Changing modify acls groups to:
// :: INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(kfk); groups with view permissions: Set(); users with modify permissions: Set(kfk); groups with modify permissions: Set()
// :: INFO Client: Submitting application application_1521167375207_0004 to ResourceManager
// :: INFO YarnClientImpl: Submitted application application_1521167375207_0004
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -
queue: default
start time:
final status: UNDEFINED
tracking URL: http://bigdata-pro01.kfk.com:8088/proxy/application_1521167375207_0004/
user: kfk
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: ACCEPTED)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.86.152
ApplicationMaster RPC port:
queue: default
start time:
final status: UNDEFINED
tracking URL: http://bigdata-pro01.kfk.com:8088/proxy/application_1521167375207_0004/
user: kfk
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: RUNNING)
// :: INFO Client: Application report for application_1521167375207_0004 (state: FINISHED)
// :: INFO Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.86.152
ApplicationMaster RPC port:
queue: default
start time:
final status: SUCCEEDED
tracking URL: http://bigdata-pro01.kfk.com:8088/proxy/application_1521167375207_0004/A
user: kfk
// :: INFO ShutdownHookManager: Shutdown hook called
// :: INFO ShutdownHookManager: Deleting directory /tmp/spark-43f281a9-034a-424b--d6d00addfff6
[kfk@bigdata-pro01 spark-2.2.-bin]$

在这里我补充一下,我们能看见终端打印这么多日志,是因为修改了这个文件
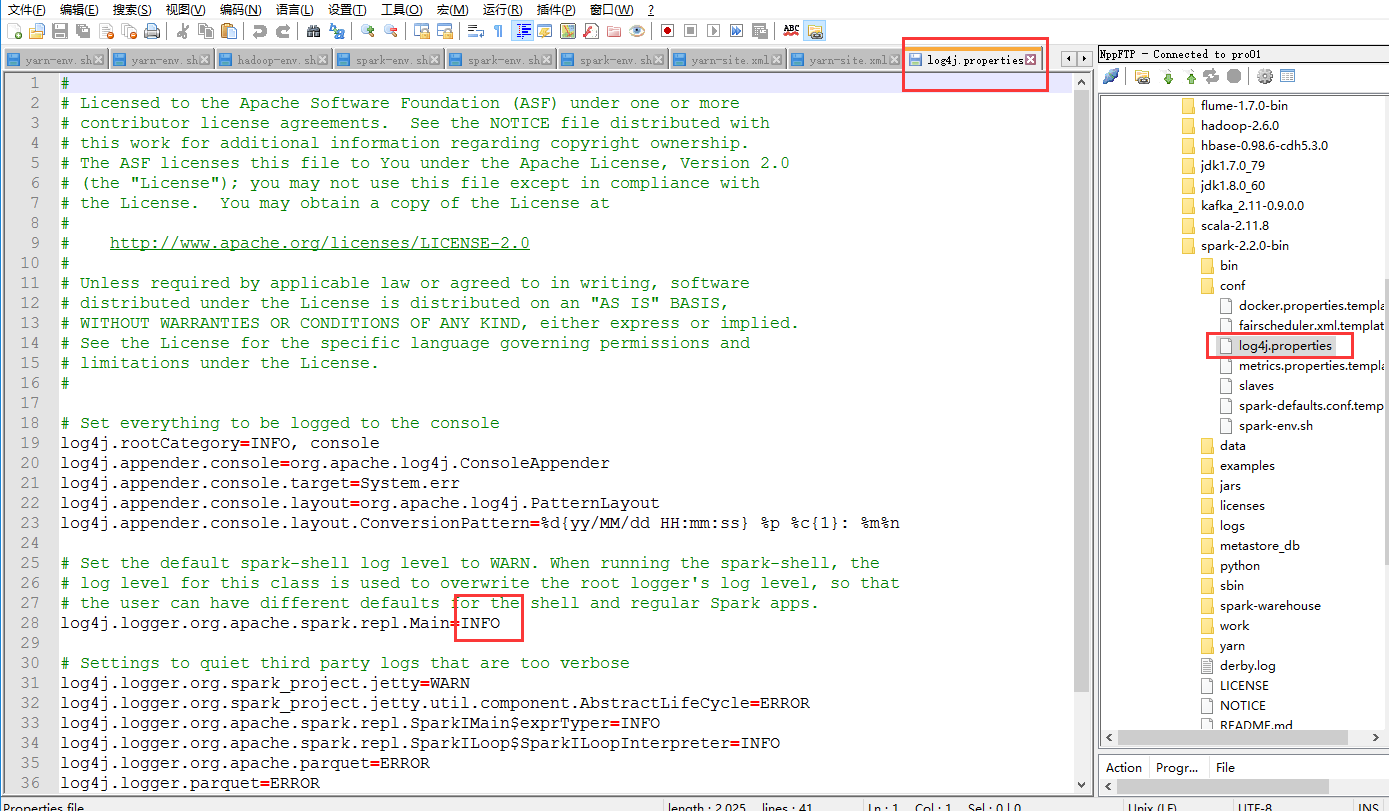
Spark2.X集群运行模式的更多相关文章
- 新闻实时分析系统 Spark2.X集群运行模式
1.几种运行模式介绍 Spark几种运行模式: 1)Local 2)Standalone 3)Yarn 4)Mesos 下载IDEA并安装,可以百度一下免费文档. 2.spark Standalone ...
- 新闻网大数据实时分析可视化系统项目——16、Spark2.X集群运行模式
1.几种运行模式介绍 Spark几种运行模式: 1)Local 2)Standalone 3)Yarn 4)Mesos 下载IDEA并安装,可以百度一下免费文档. 2.spark Standalone ...
- spark之scala程序开发(集群运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- spark集群运行模式
spark的集中运行模式 Local .Standalone.Yarn 关闭防火墙:systemctl stop firewalld.service 重启网络服务:systemctl restart ...
- Spark运行模式_本地伪集群运行模式(单机模拟集群)
这种运行模式,和Local[N]很像,不同的是,它会在单机启动多个进程来模拟集群下的分布式场景,而不像Local[N]这种多个线程只能在一个进程下委屈求全的共享资源.通常也是用来验证开发出来的应用程序 ...
- 简单说明hadoop集群运行三种模式和配置文件
Hadoop的运行模式分为3种:本地运行模式,伪分布运行模式,集群运行模式,相应概念如下: 1.独立模式即本地运行模式(standalone或local mode)无需运行任何守护进程(daemon) ...
- hadoop本地运行与集群运行
开发环境: windows10+伪分布式(虚拟机组成的集群)+IDEA(不需要装插件) 介绍: 本地开发,本地debug,不需要启动集群,不需要在集群启动hdfs yarn 需要准备什么: 1/配置w ...
- Spark新手入门——3.Spark集群(standalone模式)安装
主要包括以下三部分,本文为第三部分: 一. Scala环境准备 查看二. Hadoop集群(伪分布模式)安装 查看三. Spark集群(standalone模式)安装 Spark集群(standalo ...
- [spark]-Spark2.x集群搭建与参数详解
在前面的Spark发展历程和基本概念中介绍了Spark的一些基本概念,熟悉了这些基本概念对于集群的搭建是很有必要的.我们可以了解到每个参数配置的作用是什么.这里将详细介绍Spark集群搭建以及xml参 ...
随机推荐
- 如果指针为空,返回ERROR
if(!p) //是!p而不是p return ERROR;
- centos7数据库连接使用127.0.0.1报permission denied,使用localhost报No such file or directory
安装lamp环境后,测试数据库连接. 当host使用127.0.0.1时,报错:(HY000/2002): Permission denied. 把host换成localhost后,又报错:SQLST ...
- Scrapy 爬虫日志中出现Forbidden by robots.txt
爬取汽车之家数据的时候,日志中一直没有任何报错,开始一直不知道什么原因导致的,后来细细阅读了下日志发现日志提示“Forbidden by robots.txt”,Scrapy 设置文件中如果把ROBO ...
- linux系统中安装JDK 查看安装的ava版本
一.安装JDK 1.在/usr/目录下创建java目录 [root@localhost ~]# mkdir/usr/java[root@localhost ~]# cd /usr/java 2.下载j ...
- SSM整个配置心得
个人整合心得,还望指正
- 信号滤波模块verilog代码---UNLOCK,LOCK状态机方式
信号滤波模块verilog代码 `timescale 1ns / 1ps /////////////////////////////////////////////////////////////// ...
- Thinkphp 关联模型
1.定义关联模型 2.使用关联模型 D('BlogRelation')->relation(true)->add($data);
- Python Flask 构建微电影视频网站
前言 学完本教程,你将掌握: 1.学会使用整形.浮点型.路径型.字符串型正则表达式路由转化器 2.学会使用post与get请求.上传文件.cookie获取与相应.404处理 3.学会适应模板自动转义. ...
- 查询某个SPID,session_id对应的执行sql.
select er.session_id, CAST(csql.text AS varchar(255)) AS CallingSQL from master.sys.dm_exec_requests ...
- STL基础--算法(已排序数据的算法,数值算法)
已排序数据的算法 Binary search, merge, set operations 每个已排序数据算法都有一个同名的更一般的形式 vector vec = {8,9,9,9,45,87,90} ...