python实战之原生爬虫(爬取熊猫主播排行榜)
"""this is a module,多行注释"""import refrom urllib import request# BeautifulSoup:解析数据结构 推荐库 Scrapy:爬虫框架#爬虫,反爬虫,反反爬虫#ip 封#代理ip库class Spider():url='https://www.panda.tv/cate/lol'root_pattern='<div class="video-info">([\s\S]*?)</div>'name_pattern='</i>([\s\S]*?)</span>'number_pattern='<span class="video-number">([\s\S]*?)</span>'def __fetch_content(self):r=request.urlopen(Spider.url)htmls=r.read()htmls=str(htmls,encoding='utf-8')return htmlsa=1def __analysis(self,htmls):root_html=re.findall(Spider.root_pattern,htmls)anchors=[]for html in root_html:name=re.findall(Spider.name_pattern,html)number=re.findall(Spider.number_pattern,html)anchor={'name':name,'number':number}anchors.append(anchor)return anchorsdef __refine(self,achors):l=lambda anchor:{'name':anchor['name'][0].strip(),'number':anchor['number'][0]}return map(l,achors)def __sort(self,anchors):anchors=sorted(anchors,key=self.__sord_seed,reverse=True)return anchorsdef __show(self,anchors):for rank in range(0,len(anchors)):print('rank '+str(rank+1)+':'+anchors[rank]['name']+' '+anchors[rank]['number'])def __sord_seed(self,anchor):r=re.findall('\d*',anchor['number'])number= float(r[0])if '万' in anchor['number']:number*=10000return numberdef go(self):htmls=self.__fetch_content()anchors=self.__analysis(htmls)anchors=list(self.__refine(anchors))anchors=self.__sort(anchors)self.__show(anchors)splider=Spider()splider.go()
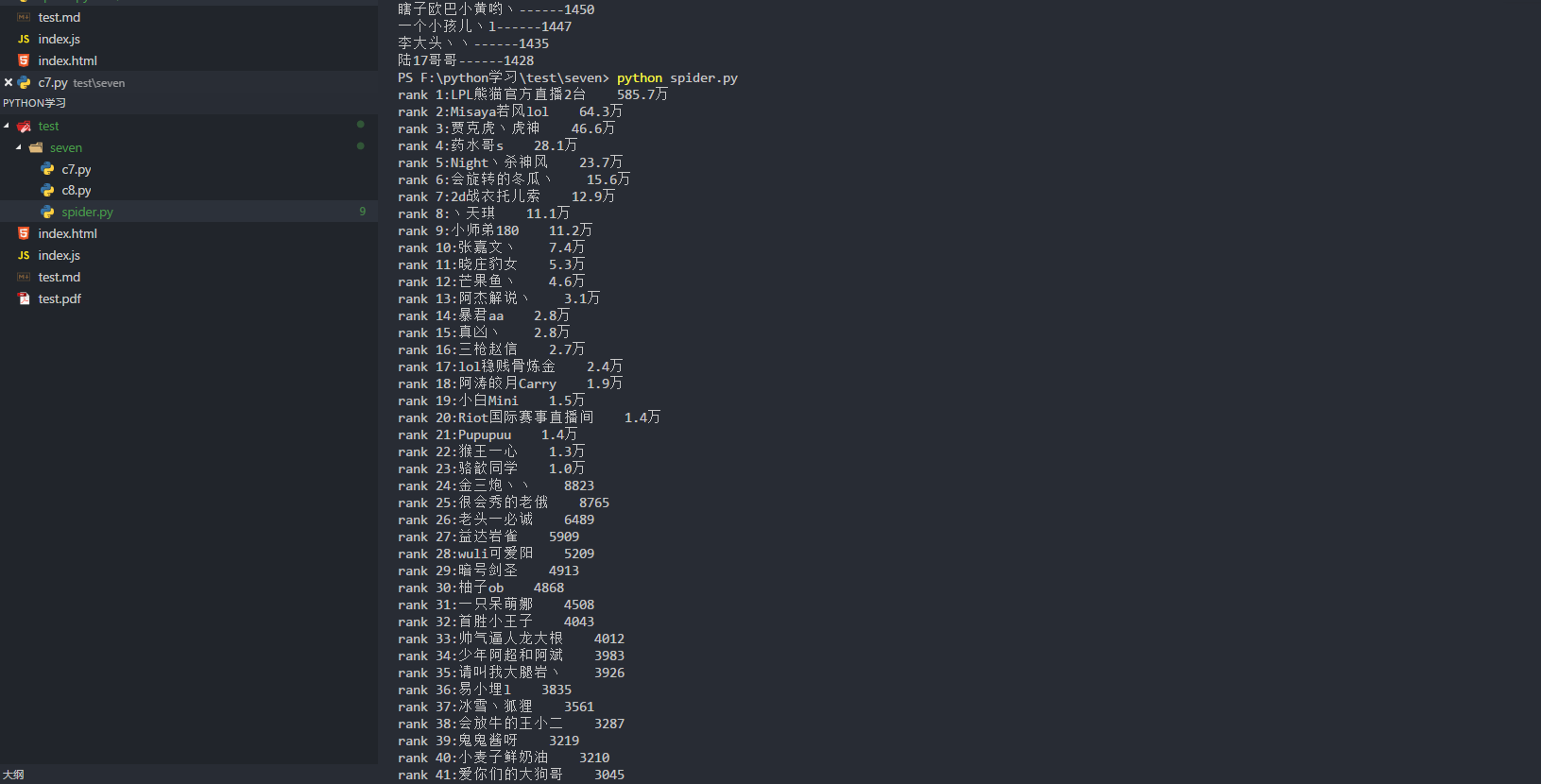
python实战之原生爬虫(爬取熊猫主播排行榜)的更多相关文章
- 『Scrapy』爬取斗鱼主播头像
分析目标 爬取的是斗鱼主播头像,示范使用的URL似乎是个移动接口(下文有提到),理由是网页主页属于动态页面,爬取难度陡升,当然爬取斗鱼主播头像这么恶趣味的事也不是我的兴趣...... 目标URL如下, ...
- 【Python数据分析】简单爬虫 爬取知乎神回复
看知乎的时候发现了一个 “如何正确地吐槽” 收藏夹,里面的一些神回复实在很搞笑,但是一页一页地看又有点麻烦,而且每次都要打开网页,于是想如果全部爬下来到一个文件里面,是不是看起来很爽,并且随时可以看到 ...
- python实战项目 — 使用bs4 爬取猫眼电影热榜(存入本地txt、以及存储数据库列表)
案例一: 重点: 1. 使用bs4 爬取 2. 数据写入本地 txt from bs4 import BeautifulSoup import requests url = "http:// ...
- 爬虫之selenium爬取斗鱼主播图片
这是我GitHub上简单的selenium介绍与简单使用:https://github.com/bwyt/spider/tree/master/selenium%E5%9F%BA%E7%A1%80 & ...
- selenium,webdriver爬取斗鱼主播信息 实操
from selenium import webdriver import time from bs4 import BeautifulSoup class douyuSelenium(): #初始化 ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫爬取京东、淘宝、苏宁上华为P20购买评论
爬虫爬取京东.淘宝.苏宁上华为P20购买评论 1.使用软件 Anaconda3 2.代码截图 三个网站代码大同小异,因此只展示一个 3.结果(部分) 京东 淘宝 苏宁 4.分析 这三个网站上的评论数据 ...
随机推荐
- 转帖:Android 官方推荐 : DialogFragment 创建对话框
转: Android 官方推荐 : DialogFragment 创建对话框 复制内容,留作备份 1. 概述 DialogFragment在android 3.0时被引入.是一种特殊的Fragment ...
- window.open() & iframe
window.open() & iframe https://www.w3schools.com/jsref/met_win_open.asp window.open(URL, name, s ...
- ES6之Promise用法详解
一 前言 本文主要对ES6的Promise进行一些入门级的介绍.要想学习一个知识点,肯定是从三个方面出发,what.why.how.下面就跟着我一步步学习吧~ 二 什么是Promise 首先是what ...
- java数组倒序查找值
java语言里面没有arr[:-2]这种方式取值 只能通过 arr[arr.length-1-x]的方式取值倒数的 x(标示具体的某个值)
- COCI 2018/2019 CONTEST #2 Solution
Problem1 Preokret 第一题一定不是什么难题. 第一个问题在读入的时候判断当前时间是不是在1440及以前就行 第二个问题考虑离线处理,由于每个时刻只能最多发生1个事件那么就弄个桶记录每一 ...
- HGOI20181030 模拟题解
problem:给定一个序列,问你能不能通过一次交换把他弄成有序 sol: 对于0%的数据,满足数列是一个排列,然后我就打了这档分(自己瞎造的!) 对于100%的数据,显然我们先对数列进行排序然后上下 ...
- DynamicSegmentTree
最近尝试了一下动态开点线段树,英文直译就是Dynamic Open Point Segment Tree,太SB了. 就跟之前的主席树写法差不多. if(!x || x == y) { x = ++t ...
- java基础基础总结----- RunTime
- 菜单栏--Dom选择器
制作一个左侧菜单栏,包含菜单目录和内容 点击菜单栏才会展示内容,否则隐藏内容 二.事例 2.1 菜单栏基本样式 <body> <div style="height: 48p ...
- javascript中的this到底指什么?
来自百度知道解释 JavaScript:this是什么? 定义:this是包含它的函数作为方法被调用时所属的对象.说明:这句话有点咬嘴,但一个多余的字也没有,定义非常准确,我们可以分3部分来理解它!1 ...