Keras下的文本情感分析简介。与MLP,RNN,LSTM模型下的文本情感测试
# coding: utf-8 # In[1]: import urllib.request
import os
import tarfile # In[2]: url="http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
filepath="example/data/aclImdb_v1.tar.gz"
if not os.path.isfile(filepath):
result=urllib.request.urlretrieve(url,filepath)
print('downloaded:',result)
if not os.path.exists("example/data/aclImdb_v1/aclImdb"):
tfile = tarfile.open("data/aclImdb_v1.tar.gz", 'r:gz')
result=tfile.extractall('data/') # In[3]: from keras.datasets import imdb
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer # In[4]: import re
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>')
return re_tag.sub('', text) # In[5]: import os
def read_files(filetype):
path = "example/data/aclImdb_v1/aclImdb/"
file_list=[] positive_path=path + filetype+"/pos/"
for f in os.listdir(positive_path):
file_list+=[positive_path+f] negative_path=path + filetype+"/neg/"
for f in os.listdir(negative_path):
file_list+=[negative_path+f] print('read',filetype, 'files:',len(file_list))
all_labels = ([1] * 12500 + [0] * 12500) all_texts = []
for fi in file_list:
with open(fi,encoding='utf8') as file_input:
all_texts += [rm_tags(" ".join(file_input.readlines()))] return all_labels,all_texts # In[6]: y_train,train_text=read_files("train") # In[7]: y_test,test_text=read_files("test") # In[8]: train_text[0] # In[9]: y_train[0] # In[10]: train_text[12500] # In[11]: y_train[12500] # In[12]: token = Tokenizer(num_words=2000)
token.fit_on_texts(train_text) # In[13]: print(token.document_count)
print(token.word_index) # In[14]: x_train_seq = token.texts_to_sequences(train_text)
x_test_seq = token.texts_to_sequences(test_text) # In[15]: print(x_train_seq[0]) # In[16]: x_train = sequence.pad_sequences(x_train_seq, maxlen=100)
x_test = sequence.pad_sequences(x_test_seq, maxlen=100) # In[17]: x_train[0] # In[18]: from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation,Flatten
from keras.layers.embeddings import Embedding
model = Sequential()
model.add(Embedding(output_dim=32,
input_dim=2000,
input_length=100))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(units=256,
activation='relu' ))
model.add(Dropout(0.2))
model.add(Dense(units=1,
activation='sigmoid' ))
model.summary() # In[19]: model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_history =model.fit(x_train, y_train,batch_size=100,
epochs=10,verbose=2,
validation_split=0.2) # In[20]: get_ipython().magic('pylab inline')
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')
plt.ylabel(train)
plt.xlabel('Epoch')
plt.legend(['train', 'validation'], loc='upper left')
plt.show() # In[21]: show_train_history(train_history,'acc','val_acc')
show_train_history(train_history,'loss','val_loss') # In[22]: scores = model.evaluate(x_test, y_test, verbose=1)
scores[1] # In[23]: probility=model.predict(x_test) # In[24]: probility[:10] # In[25]: probility[12500:12510] # In[26]: predict=model.predict_classes(x_test) # In[27]: predict_classes=predict.reshape(-1) # In[28]: SentimentDict={1:'正面的',0:'负面的'}
def display_test_Sentiment(i):
print(test_text[i])
print('标签label:',SentimentDict[y_test[i]],
'预测结果:',SentimentDict[predict_classes[i]]) # In[29]: display_test_Sentiment(2) # In[30]: display_test_Sentiment(12505) # In[31]: from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import SimpleRNN
model = Sequential()
model.add(Embedding(output_dim=32,
input_dim=2000,
input_length=100))
model.add(Dropout(0.35))
model.add(SimpleRNN(units=16))
model.add(Dense(units=256,activation='relu' ))
model.add(Dropout(0.35))
model.add(Dense(units=1,activation='sigmoid' ))
model.summary() # In[32]: model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_history =model.fit(x_train, y_train,batch_size=100,
epochs=10,verbose=2,
validation_split=0.2) # In[33]: scores = model.evaluate(x_test, y_test, verbose=1)
scores[1] # In[34]: from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation,Flatten
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
model = Sequential()
model.add(Embedding(output_dim=32,
input_dim=2000,
input_length=100))
model.add(Dropout(0.2))
model.add(LSTM(32))
model.add(Dense(units=256,
activation='relu' ))
model.add(Dropout(0.2))
model.add(Dense(units=1,
activation='sigmoid' ))
model.summary() # In[35]: model.compile(loss='binary_crossentropy',
#optimizer='rmsprop',
optimizer='adam',
metrics=['accuracy'])
train_history =model.fit(x_train, y_train,batch_size=100,
epochs=10,verbose=2,
validation_split=0.2) # In[36]: show_train_history(train_history,'acc','val_acc')
show_train_history(train_history,'loss','val_loss')
scores = model.evaluate(x_test, y_test, verbose=1)
scores[1] # In[ ]:
文本来源于IMDb网络电影数据集。下载,放到合适的路径下,然后,开始。
过滤掉HTML标签。因为数据集中有相关标签。:

之后读取所有数据和目标标签,然后建立字典:
将文本转化为数字串:

格式化数字串长度为100

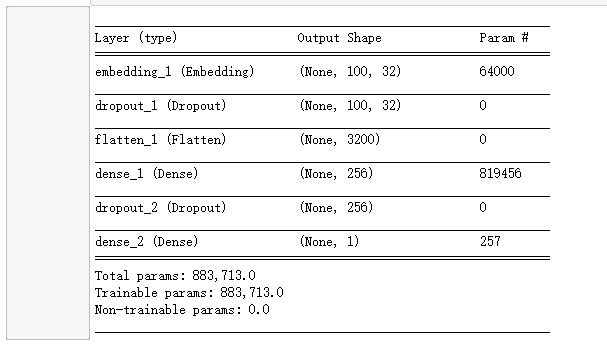
建立MLP模型,其中嵌入层将每个长度为100的数字串转为100个32维的向量,将文字映射成多维的几何空间向量,让每一个文字有上下的关联性。
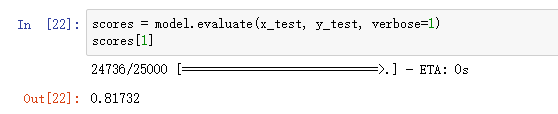
编译,训练,绘图,评估后的准确率:
建立RNN模型,有关RNN模型的介绍:https://www.cnblogs.com/bai2018/p/10466418.html

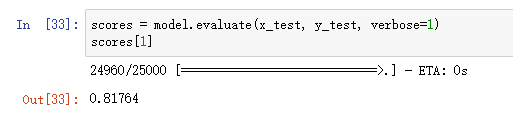
测试评估:
建立LSTM模型,相关介绍:https://www.cnblogs.com/bai2018/p/10466497.html

准确率:

Keras下的文本情感分析简介。与MLP,RNN,LSTM模型下的文本情感测试的更多相关文章
- Python爬虫和情感分析简介
摘要 这篇短文的目的是分享我这几天里从头开始学习Python爬虫技术的经验,并展示对爬取的文本进行情感分析(文本分类)的一些挖掘结果. 不同于其他专注爬虫技术的介绍,这里首先阐述爬取网络数据动机,接着 ...
- 文本分类实战(七)—— Adversarial LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- NLP入门(十)使用LSTM进行文本情感分析
情感分析简介 文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的分类.它是对带有情感色彩的主观性 ...
- 朴素贝叶斯算法下的情感分析——C#编程实现
这篇文章做了什么 朴素贝叶斯算法是机器学习中非常重要的分类算法,用途十分广泛,如垃圾邮件处理等.而情感分析(Sentiment Analysis)是自然语言处理(Natural Language Pr ...
- C#编程实现朴素贝叶斯算法下的情感分析
C#编程实现 这篇文章做了什么 朴素贝叶斯算法是机器学习中非常重要的分类算法,用途十分广泛,如垃圾邮件处理等.而情感分析(Sentiment Analysis)是自然语言处理(Natural Lang ...
- R语言︱词典型情感分析文本操作技巧汇总(打标签、词典与数据匹配等)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:情感分析中对文本处理的数据的小技巧要 ...
- 【转】用python实现简单的文本情感分析
import jieba import numpy as np # 打开词典文件,返回列表 def open_dict(Dict='hahah',path = r'/Users/zhangzhengh ...
- Spark 的情感分析
Spark 的情感分析 本文描述了基于 Spark 如何构建一个文本情感分析系统.文章首先介绍文本情感分析基本概念和应用场景,其次描述采用 Spark 作为分析的基础技术平台的原因和本文使用到技术组件 ...
- 如何使用百度EasyDL进行情感分析
使用百度EasyDL定制化训练和服务平台有一段时间了,越来越能体会到EasyDL的易用性.在此之前我也接触过不少的深度学习平台,如类脑平台.Google的GCP深度学习平台.AWS深度学习平台,但我觉 ...
随机推荐
- window中磁盘空间不足但是找不到使用空间的文件
今天看到 电脑的 d盘 空间爆红,空间满了,去找了找没有找到具体是哪个文件占用的空间.一个一个文件的查看属性,都没有找到.文件都不大,几百个g的空间就没了.莫名其妙!!! 自己开启了备份还原,存储的 ...
- Codeforces Beta Round #67 (Div. 2)
Codeforces Beta Round #67 (Div. 2) http://codeforces.com/contest/75 A #include<bits/stdc++.h> ...
- jQuery MD5 加密
一 MD5 概述 MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value) ...
- @ResponseBody使用须知
-------------------siwuxie095 @ResponseBody 使用须知 使用 @ResponseBody 注解映射响应体 @ResponseBody 注解可被应用于方法上,标 ...
- TZOJ 1800 Martian Mining(二维dp)
描述 The NASA Space Center, Houston, is less than 200 miles from San Antonio, Texas (the site of the A ...
- 《基于Nginx的中间件架构》学习笔记---2.nginx的优点以及nginx的安装
[优势] 优势1:IO多路复用和epoll模型(详见总结知识) 优势2:轻量级(1.功能模块少:只保留了一些核心代码 2.代码模块化) 优势3:CPU亲和 这里的CPU亲和指的是:是一种把cp ...
- [leetcode]103. Binary Tree Zigzag Level Order Traversal二叉树来回遍历
Given a binary tree, return the zigzag level order traversal of its nodes' values. (ie, from left to ...
- HelloWorld 基础语法
所有内容取自菜鸟教程 public class HelloWorld { /* 第一个Java程序 * 它将打印字符串 Hello World */ public stat ...
- 解决织梦替换ueditor编辑器后栏目与单页无法保存内容
织梦的默认编辑器是ckeditor,没有插入代码的功能,不够强大,就换成了百度的UEditor编辑器. 使用织梦DedeCMS百度整合UEditor编辑器时,碰到了栏目内容或者单页无法保存的问题,这个 ...
- CSS学习总结2:CSS框模型
1.CSS框模型概述 CSS框模型规定了元素框处理元素内容.内边框.边框和外边框的方式. 元素框的最内部分是实际的内容,直接包围内容的是内边距.内边距呈现了元素的背景.内边距的边缘是边框.边框以外是外 ...