MySQL应用架构优化-实时数据处理
1.1. 场景
在和开发人员做优化的时候,讨论最多的应该是结合应用场景编写出合适的SQL。并培训开发应该如何编写SQL让MySQL的性能尽量好。但是有一些的场景对于SQL的优化是行不通的。
打个比方,产品有这样的需求:针对每个商品实时显示销售者的销售量,并且按销售量做排序,还要实现 分页。这个需求看上去很简单,实现起来也很容易。无非就是对三张表(seller、goods、orders)进行查询、聚合、排序。但是对于上亿订单量来说,这样查询简直就是一个噩梦。
分析:这边主要是需要按销售量来进行排序,这样的操作在这里就比较可怕。如果没有这个的话,我们的按下面步骤来写SQL,MySQL跑起来就很爽:
- 按分页需求,先查出销售者的个数(如:100个销售着,去10个)。
- 通过1取出的销售者到orders中查询订单并GROUP BY。
- 通过2中的orders中的goods id 取出商品信息。
可惜的是我们不是产品,不能按照我们的意愿来。当然,最好的办法就是说服产品,干掉类似这样的需求。或改变一种方式来实现这中需求,如:不要实时的展示。可是说服产品和顶在头上的人谈何容易啊,也许是关注的东西是不一样的吧。
1.2. 解决方案
首先要说明一些,像这样统计的计算能不实时就不实时。我们应该把OLAP的操作和OLTP的操作尽量解耦。来做。如白天我们关注的是OLTP(就是大家普通在用的应用程序),晚上我们关注的OLAP(Hadoop实现)。
这是我们的奇葩需求需要实时,所以Hadoop都是用不上的了。这时我们就需要用气实时计算的系统。现在业界应该有两个实时计算系统比较流行:Storm、Spark。这边我选用了使用Storm来作为我们的方案。这边选择Storm的原因主要也就是之前接触过,比较熟悉上手比较快。
当然这边我们要需要用到其他的主键:
- Logstash:主要也就是用来收集日志。这边我们将交易一笔订单记录都会化成json格式输出到日志文件中。之前也考虑过使用Flume,但是Flume没有Logstash来的实时。
- Kafka:主要是为了接受Logstash传过来的信息,并将它持久化和提供给Storm来使用。说明一下:有些系统会将Kafka放入程序就使用,就是说订单完成时将订单json信息直接发送给Kafka。我们这边多一层Logstash的目的是为了让应用系统和Kafka进行解耦。如果Kafka挂掉或者网络出现问题。不会影响到应用系统的正常运行。
- Storm:接收Kafka中的信息进行分析计算出想要的数据。
- MongoDB:主要是为了存储从Storm中分析完的数据。
- Zookeeper:用来管理Kafka和Storm用的。
在使用这样的架构之前希望大家能理解一下“实时”这个概念:其实无论在什么应用程序中基本没有实时能完成的。只是电脑运行的快,让你误认为是实时的。所以,这边我们还是准实时。
实时理解的图:

1.3. 实时计算架构部署图

1.4. 架构部署
1.4.1. 环境说明
部署演示使用的是VirtualBox虚拟机,总共启用了5台虚拟机(可以根据自己的机器配置而定,我的配置:i3、12G内存、固态硬盘250G)。
系统应用部署信息
| 操作系统 | IP | 部署软件 | 端口 |
| Centos7.2 | 10.10.10.11 | Logstash | |
| Kafka | 9092 | ||
| ~ | 10.10.10.12 | MongoDB | 27017、27018、27019 |
| ~ | 10.10.10.21 | Zookeeper | 2181、3887 |
| Storm | |||
| ~ | 10.10.10.22 | Zookeeper | 2181、3887 |
| Storm | |||
| ~ | 10.10.10.23 | Zookeeper | 2181、3887 |
| Storm |
这边我就不部署Jetty了,到时候我使用变相的方式来向日志文件中输入json格式数据。
22.4.2. 统一配置
这边5台机子的有统一的hosts文件,并且都需要配置好JDK:
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@storm_1 conf]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
10.10.10.21 storm_1
10.10.10.22 storm_2
10.10.10.23 storm_3
10.10.10.11 normal_11
10.10.10.12 normal_12
[root@normal_11 local]# java -version
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
|
22.4.3. 部署Zookeeper
因为这边我们部署的是Zookeeper集群因此在3台机子上的操作步骤都是一样的:这边我以操作其中一台(10.10.10.21 storm_1)机子为例。
- 到官网下载软件(zookeeper-3.4.6.tar.gz)
- 将软件解压到 /usr/local/ 目录下
|
1
2
3
4
5
|
[root@storm_1 local]# tar zookeeper-3.4.6.tar.gz -C /usr/local
[root@storm_1 local]# pwd
/usr/local
[root@storm_1 local]# ls -la
drwxr-xr-x. 10 1000 1000 4096 Feb 20 2014 zookeeper-3.4.6
|
- Zookeeper配置文件
如果没有/usr/local/zookeeper-3.4.6/conf/zoo.cfg配置文件则新建一个。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
[root@storm_1 conf]# pwd
/usr/local/zookeeper-3.4.6/conf
[root@storm_1 conf]# cat zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
dataDir=/u01/zookeeper/data
dataLogDir=/u01/zookeeper/data_log
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=7
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1 = storm_1:2887:3887
server.2 = storm_2:2887:3887
server.3 = storm_3:2887:3887
|
- 创建相关需要的目录
|
1
2
3
4
5
6
|
[root@storm_1 zookeeper]# mkdir -p /u01/zookeeper/data
[root@storm_1 zookeeper]# mkdir -p /u01/zookeeper/data_log
[root@storm_1 zookeeper]# ll /u01/zookeeper/
total 0
drwxr-xr-x 3 root root 33 Apr 19 00:23 data
drwxr-xr-x 3 root root 22 Apr 2 12:36 data_log
|
- 创建myid文件
下面的命令应该在不同的机器上执行
|
1
2
3
4
5
6
|
# 在 10.10.10.21 storm_1 机器上执行
[root@storm_1 zookeeper]# echo 1 > /u01/zookeeper/data/myid
# 在 10.10.10.21 storm_2 机器上执行
[root@storm_2 zookeeper]# echo 2 > /u01/zookeeper/data/myid
# 在 10.10.10.21 storm_3 机器上执行
[root@storm_3 zookeeper]# echo 3 > /u01/zookeeper/data/myid
|
- 启动Zookeeper
分表在三台机子上都要执行下面命令
|
1
|
[root@sotrm_1 ~]# /usr/local/zookeeper-3.4.6/bin/zkServer.sh start
|
- 查看Zookeeper状态
|
1
2
3
4
|
[root@storm_1 zookeeper]# /usr/local/zookeeper-3.4.6/bin/zkServer.sh status
JMX enabled by default
Using config: /usr/local/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower
|
- 客户端链接Zookeeper进行验证
|
1
2
3
4
5
6
7
|
[root@storm_1 zookeeper]# /usr/local/zookeeper-3.4.6/bin/zkCli.sh -timeout 5000 -r -server storm_1:2181
Connecting to storm_1:2181
... omit ...
WatchedEvent state:SyncConnected type:None path:null
[zk: storm_1:2181(CONNECTED) 0] ls /
[consumers, config, isr_change_notification, admin, brokers, zookeeper, controller_epoch]
|
以上就算是部署好了Zookeeper集群了。
22.4.4. 部署Kafka
按照前面规划的我们应该将Kafka部署在(10.10.10.12 normal_12)机子上。
- 到官网下载Kafka(10-0.9.0.0.tgz)
- 将Kafka解压到/usr/local目录下,并从命令为kafka
|
1
2
3
4
5
|
[root@normal_11 local]# tar -zxf kafka_2.10-0.9.0.0.tgz -C /usr/local
[root@normal_11 local]# mv /usr/local/kafka_2.10-0.9.0.0 /usr/local/kafka
[root@normal_11 local]# cd /usr/local
[root@normal_11 local]# ls -la
drwxr-xr-x 7 root root 4096 Apr 18 22:41 kafka
|
- 设置Kafka配置文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
[root@normal_11 config]# pwd
/usr/local/kafka/config
[root@normal_11 config]# cat server.properties
broker.id=0
listeners=PLAINTEXT://:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/u01/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
log.cleaner.enable=false
zookeeper.connect=storm_1:2181,storm_2:2181,storm_3:2181
zookeeper.connection.timeout.ms=6000
|
- 创建Kafka相关目录
|
1
|
[root@normal_11 config]# mkdir -p /u01/kafka-logs
|
- 启动Kafka
|
1
2
3
|
[root@normal_11 config]# /usr/local/kafka/bin/kafka-server-start.sh \
/usr/local/kafka/config/server.properties > /u01/kafka-logs/kafka.out 2>&1 &
[1] 3656
|
- 创建test topic
|
1
2
3
4
5
6
|
[root@normal_11 config]# /usr/local/kafka/bin/kafka-topics.sh \
--create \
--zookeeper storm_1:2181 \
--replication-factor 1 \
--partitions 1 \
--topic test
|
- 查看创建的topic
|
1
2
3
4
|
[root@normal_11 config]# /usr/local/kafka/bin/kafka-topics.sh \
--list \
--zookeeper storm_1:2181
test
|
- 新建一个session,开启Kafka消费者客户端
|
1
2
3
4
|
[root@normal_11 config]# /usr/local/kafka/bin/kafka-console-consumer.sh \
--zookeeper storm_1:2181 \
--topic test \
--from-beginning
|
- 新建一个session,开启Kafka生产者客户端,并生产一个消息。
|
1
2
3
4
5
|
/usr/local/kafka/bin/kafka-console-producer.sh \
--broker-list localhost:9092 \
--topic test
this is message 1
|
在消费者的session中能看到同时也出现了 “this is message 1”这个消息
22.4.5. 部署Logstash
按照前面规划的我们应该将Kafka部署在(10.10.10.12 normal_12)机子上。这边我们使用Logstash监听/tmp/orders.log文件,并且将Kafka作为它的输出。
- 到官网下载Logstash(logstash-2.3.1.tar.gz)
- 将Logstash解压到/usr/local/目录下
|
1
2
3
4
5
|
[root@normal_11 local]# tar -zxf logstash-2.3.1.tar.gz
[root@normal_11 local]# mv logstash-2.3.1 /usr/local/logstash
[root@normal_11 local]# cd /usr/local
[root@normal_11 local]# ll
drwxr-xr-x 5 root root 4096 May 8 21:35 logstash
|
- 设置Logstash配置文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
[root@normal_11 logstash]# mkdir -p /usr/local/logstash/conf
[root@normal_11 logstash]# cat /usr/local/logstash/conf/logstash-kafka.conf
input {
file {
path => "/tmp/orders.log"
}
}
output {
kafka {
bootstrap_servers => "normal_11:9092"
topic_id => "test"
}
}
|
- 启动Logstash agent
|
1
2
3
4
|
[root@normal_11 config]# /usr/local/logstash/bin/logstash agent \
--verbose \
-f /usr/local/logstash/conf/logstash-kafka.conf \
--log /tmp/logstash.log &
|
- 向/tmp/orders.log中输入一个json字符串
|
1
|
[root@normal_11 tmp]# echo '{"order_price":20, "good_name":"good_1", "seller_id":1}' >> /tmp/orders.log
|
再之前启动的Kafka消费者客户端会出现如下消息
|
1
|
{"message":"{\"order_price\":20, \"good_name\":\"good_1\", \"seller_id\":1}","@version":"1","@timestamp":"2016-05-08T13:59:45.080Z","path":"/tmp/orders.log","host":"normal_11"}
|
22.4.6. 部署MongoDB
这边我们MongoDB部署在(10.10.10.12 normal_12)机子上。并且采用的是复制的形式。
- 官网下载MongoDB(mongodb-linux-x86_64-rhel70-3.2.5.tgz)
- 解压MongoDB到/usr/local/目录下
|
1
2
|
[root@normal_12 soft]# tar -zxf mongodb-linux-x86_64-rhel70-3.2.5.tgz
[root@normal_12 soft]# mv mongodb-linux-x86_64-rhel70-3.2.5 /usr/local/mongodb
|
- 创建MongoDB的相关目录
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
[root@normal_12 soft]# mkdir -p /u01/mongodb_2701{7,8,9}/{data,logs,tmp}
[root@normal_12 soft]# cd /u01
[root@normal_12 soft]# ll *
mongodb_27017:
total 6396
drwxr-xr-x 4 root root 4096 May 8 02:07 data
drwxr-xr-x 2 root root 41 Apr 30 22:17 logs
-rw-r--r-- 1 root root 658 May 7 15:21 mongodb.yaml
drwxr-xr-x 2 root root 24 Apr 30 22:17 tmp
mongodb_27018:
total 20
drwxr-xr-x 2 root root 6 May 7 10:04 data
drwxr-xr-x 2 root root 24 May 1 20:42 logs
-rw-r--r-- 1 root root 662 May 7 11:14 mongodb.yaml
drwxr-xr-x 2 root root 24 May 1 20:42 tmp
mongodb_27019:
total 20
drwxr-xr-x 2 root root 6 May 7 10:04 data
drwxr-xr-x 2 root root 24 May 1 20:55 logs
-rw-r--r-- 1 root root 662 May 7 11:15 mongodb.yaml
drwxr-xr-x 2 root root 24 May 1 20:55 tmp
|
- 分别在/u01/mongodb_27017、/u01/mongodb_27018、/u01/mongodb_27019中创建配置文件和启动脚本
- /u01/mongodb_27017中的配置文件和启动脚本
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
[root@normal_12 u01]# cat /u01/mongodb_27017/mongodb.yaml
# http://docs.mongoing.com/manual-zh/reference/configuration-options.html
systemLog:
destination: file
path: /u01/mongodb_27017/logs/mongodb.log
logAppend: true
logRotate: reopen
storage:
dbPath: /u01/mongodb_27017/data
engine: wiredTiger
journal:
enabled: true
processManagement:
fork: true
pidFilePath: /u01/mongodb_27017/tmp/mongodb.pid
net:
bindIp: 10.10.10.12
port: 27017
unixDomainSocket:
enabled: false
operationProfiling:
mode: slowOp
slowOpThresholdMs: 100
replication:
replSetName: rs_12
enableMajorityReadConcern: true
[root@normal_12 u01]# cat /u01/mongodb_27017/start_mongodb.sh
#!/usr/bin/env bash
/usr/local/mongodb/bin/mongod \
--config=/u01/mongodb_27017/mongodb.yaml
[root@normal_12 u01]# cat /u01/mongodb_27017/stop_mongodb.sh
#!/usr/bin/env bash
/usr/local/mongodb/bin/mongod \
--config /u01/mongodb_27017/mongodb.yaml \
--shutdown
[root@normal_12 u01]# cat /u01/mongodb_27017/client_mongodb.sh
#!/usr/bin/env bash
/usr/local/mongodb/bin/mongo 10.10.10.12:27017
|
- /u01/mongodb_27018中的配置文件和启动脚本
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
[root@normal_12 u01]# cat /u01/mongodb_27018/mongodb.yaml
# http://docs.mongoing.com/manual-zh/reference/configuration-options.html
systemLog:
destination: file
path: /u01/mongodb_27018/logs/mongodb.log
logAppend: true
logRotate: reopen
storage:
dbPath: /u01/mongodb_27018/data
engine: wiredTiger
journal:
enabled: true
processManagement:
fork: true
pidFilePath: /u01/mongodb_27018/tmp/mongodb.pid
net:
bindIp: 10.10.10.12
port: 27018
unixDomainSocket:
enabled: false
operationProfiling:
mode: slowOp
slowOpThresholdMs: 100
replication:
replSetName: rs_12
enableMajorityReadConcern: true
[root@normal_12 u01]# cat /u01/mongodb_27018/start_mongodb.sh
#!/usr/bin/env bash
/usr/local/mongodb/bin/mongod \
--config=/u01/mongodb_27018/mongodb.yaml
[root@normal_12 u01]# cat /u01/mongodb_27018/stop_mongodb.sh
#!/usr/bin/env bash
/usr/local/mongodb/bin/mongod \
--config /u01/mongodb_27018/mongodb.yaml \
--shutdown
[root@normal_12 u01]# cat /u01/mongodb_27018/client_mongodb.sh
#!/usr/bin/env bash
/usr/local/mongodb/bin/mongo 10.10.10.12:27018
|
- /u01/mongodb_27019中的配置文件和启动脚本
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
[root@normal_12 u01]# cat /u01/mongodb_27019/mongodb.yaml
# http://docs.mongoing.com/manual-zh/reference/configuration-options.html
systemLog:
destination: file
path: /u01/mongodb_27019/logs/mongodb.log
logAppend: true
logRotate: reopen
storage:
dbPath: /u01/mongodb_27019/data
engine: wiredTiger
journal:
enabled: true
processManagement:
fork: true
pidFilePath: /u01/mongodb_27019/tmp/mongodb.pid
net:
bindIp: 10.10.10.12
port: 27019
unixDomainSocket:
enabled: false
operationProfiling:
mode: slowOp
slowOpThresholdMs: 100
replication:
replSetName: rs_12
enableMajorityReadConcern: true
[root@normal_12 u01]# cat /u01/mongodb_27019/start_mongodb.sh
#!/usr/bin/env bash
/usr/local/mongodb/bin/mongod \
--config=/u01/mongodb_27019/mongodb.yaml
[root@normal_12 u01]# cat /u01/mongodb_27019/stop_mongodb.sh
#!/usr/bin/env bash
/usr/local/mongodb/bin/mongod \
--config /u01/mongodb_27019/mongodb.yaml \
--shutdown
[root@normal_12 u01]# cat /u01/mongodb_27019/client_mongodb.sh
#!/usr/bin/env bash
/usr/local/mongodb/bin/mongo 10.10.10.12:27019
|
- 启动MongoDB
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@normal_12 u01]# /u01/mongodb_27017/start_mongodb.sh
about to fork child process, waiting until server is ready for connections.
forked process: 3817
child process started successfully, parent exiting
[root@normal_12 u01]# /u01/mongodb_27018/start_mongodb.sh
about to fork child process, waiting until server is ready for connections.
forked process: 3841
child process started successfully, parent exiting
[root@normal_12 u01]# /u01/mongodb_27019/start_mongodb.sh
about to fork child process, waiting until server is ready for connections.
forked process: 3865
child process started successfully, parent exiting
|
- 初始化复制
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
[root@normal_12 u01]# /u01/mongodb_27017/client_mongodb.sh
MongoDB shell version: 3.2.5
connecting to: 10.10.10.12:27017/test
(test) 22:48:43>
(test) 22:48:45>rs.initiate()
{
"info2" : "no configuration specified. Using a default configuration for the set",
"me" : "10.10.10.12:27017",
"ok" : 1
}
(test) 22:48:43>
(test) 22:48:43>
(test) 22:48:56>rs.add("10.10.10.12:27018")
{ "ok" : 1 }
(test) 22:48:43>
(test) 22:48:43>
(test) 22:49:30>rs.add("10.10.10.12:27019")
{ "ok" : 1 }
(test) 22:48:43>
(test) 22:48:43>
(test) 22:49:33>rs.conf()
{
"_id" : "rs_12",
"version" : 3,
"protocolVersion" : NumberLong(1),
"members" : [
{
"_id" : 0,
"host" : "10.10.10.12:27017",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 1,
"host" : "10.10.10.12:27018",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
},
{
"_id" : 2,
"host" : "10.10.10.12:27019",
"arbiterOnly" : false,
"buildIndexes" : true,
"hidden" : false,
"priority" : 1,
"tags" : {
},
"slaveDelay" : NumberLong(0),
"votes" : 1
}
],
"settings" : {
"chainingAllowed" : true,
"heartbeatIntervalMillis" : 2000,
"heartbeatTimeoutSecs" : 10,
"electionTimeoutMillis" : 10000,
"getLastErrorModes" : {
},
"getLastErrorDefaults" : {
"w" : 1,
"wtimeout" : 0
},
"replicaSetId" : ObjectId("572f51d8d37af8a0cf4cabf8")
}
}
(test) 22:49:42>
(test) 22:49:48>
(test) 22:49:48>rs.isMaster()
{
"hosts" : [
"10.10.10.12:27017",
"10.10.10.12:27018",
"10.10.10.12:27019"
],
"setName" : "rs_12",
"setVersion" : 3,
"ismaster" : true,
"secondary" : false,
"primary" : "10.10.10.12:27017",
"me" : "10.10.10.12:27017",
"electionId" : ObjectId("7fffffff0000000000000001"),
"maxBsonObjectSize" : 16777216,
"maxMessageSizeBytes" : 48000000,
"maxWriteBatchSize" : 1000,
"localTime" : ISODate("2016-05-08T14:49:54.119Z"),
"maxWireVersion" : 4,
"minWireVersion" : 0,
"ok" : 1
}
|
22.4.7. 初始化Storm
这边我们在(10.10.10.21 storm_1、10.10.10.22 storm_2、10.10.10.23 storm_3)这三台部署storm。
- 到官网下载Stormtorm(apache-storm-0.9.6.zip)
- 解压到/usr/local/目录下,三台机子都执行同样的命令
|
1
2
|
[root@storm_1 wordcount]# unzip apache-storm-0.9.6.zip
[root@storm_1 wordcount]# mv apache-storm-0.9.6 /usr/local/
|
- 设置yaml配置文件
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
[root@storm_2 wordcount]# cat /usr/local/apache-storm-0.9.6/conf/storm.yaml
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
########### These MUST be filled in for a storm configuration
# storm.zookeeper.servers:
# - "server1"
# - "server2"
#
# nimbus.host: "nimbus"
#
#
# ##### These may optionally be filled in:
#
## List of custom serializations
# topology.kryo.register:
# - org.mycompany.MyType
# - org.mycompany.MyType2: org.mycompany.MyType2Serializer
#
## List of custom kryo decorators
# topology.kryo.decorators:
# - org.mycompany.MyDecorator
#
## Locations of the drpc servers
# drpc.servers:
# - "server1"
# - "server2"
## Metrics Consumers
# topology.metrics.consumer.register:
# - class: "backtype.storm.metric.LoggingMetricsConsumer"
# parallelism.hint: 1
# - class: "org.mycompany.MyMetricsConsumer"
# parallelism.hint: 1
# argument:
# - endpoint: "metrics-collector.mycompany.org"
storm.zookeeper.servers:
- "storm_1"
- "storm_2"
- "storm_3"
nimbus.host: "storm_1"
storm.local.dir: "/u01/storm/status"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
|
- 创建Storm运行时目录
|
1
|
[root@storm_1 wordcount]# mkdir -p /u01/storm/status
|
- 启动Storm
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# Node1:启动 storm UI界面
[root@storm_1 wordcount]# /usr/local/apache-storm-0.9.6/bin/storm ui > /dev/null 2>&1 &
# Node1:启动 storm nimbus
[root@storm_1 wordcount]# /usr/local/apache-storm-0.9.6/bin/storm nimbus > /dev/null 2>&1 &
# Node2:启动 supervisor
[root@storm_1 wordcount]# /usr/local/apache-storm-0.9.6/bin/storm supervisor > /dev/null 2>&1 &
# Node3:启动 supervisor
[root@storm_1 wordcount]# /usr/local/apache-storm-0.9.6/bin/storm supervisor > /dev/null 2>&1 &
# 在各个节点上运行 jps 查看服务状态
[root@storm_1 wordcount]# lps
2151 core
2097 QuorumPeerMain
3969 Jps
2191 nimbus
|
- 开启web界面访问Storm UI

看到上的界面就说明我们的Storm已经部署完毕了。
22.4.1. 构建streamparse(Python Storm框架)
streamparse 是Python Storm的一个框架,他可以将python代码打包为一个jar包运行在Storm中。
官网:http://streamparse.readthedocs.io/en/master/quickstart.html。
(PS:streamparse 3 以上的拓扑已经改变。和作者沟通过他是为了让streamparse能够更好的独立运行,从而脱离storm环境。)
- 创建3机信任,分别在3台机子上都生成ssh的公钥,分别执行以下命令
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
[root@storm_1 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
1e:20:62:da:f5:fb:69:32:da:ac:09:ef:7c:35:a5:01 root@storm_3
The key's randomart image is:
+--[ RSA 2048]----+
| |
| E |
| o o .. |
| + o o .. . |
|. . . S+ |
| o+. |
| . .... |
| + ++... |
| .B+o+o |
+-----------------+
|
执行完上面命令后会在各个主机的 ~/.ssh/ 目录下会生成 id_rsa.pub 文件。将3台机子中的公钥都拷贝到一个文件中并且让3台机子的这个文件内容都一样
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# storm_1 节点
[root@storm_1 ~]# cat ~/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0z8u8K0wGWLhhzxcztokzVWHqKf1O5PScjkIvXFh2AnEqZz+d5/LqyT6qDi1T8p+k4UHCkgmRqWZbG+LEtzQEjE3/Guya4uEP5g8MGvnLUSQQWS5oQN6EAq2fQ7G806fipQCEKWETF7axk6We1NNUjO27c071OMQ2JXM7PLVQACaUcaI8sJg3uHOs7Bcb871tyiuXtVygpyjJEBxvzpuxcjEJI/C/Yu+q28KXRfSWblJ7hIN7c8eIGYumTi4vSKo3Rwwm5UGvBIopK8Xc4SmvrZ6jpHInR2YLQsEznrcR9MprhHXPeFgnoJ3vCLeXbOesmH+h6Cb4UJChUR7owWKr root@storm_1
# storm_2 节点
[root@storm_2 ~]# cat ~/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC/n9bY6jD8Z2mkgZLO9meXAMNvDt/YJRpcTM57ko2p9Cmm4c+CgQzstBExOAciQR9ckranLj8k/GYDBL5jBIBjquvVEtA06sCp6vGsvUOOOg07VgrmpbEvGNovNa8bfVOXR5cSbqwoesPu33wG43WXDdpD7vKU9YrqUyNXj1xPi+xTQwWkUMz9zEH8zwYuhD7pglP7iJsvzl/GpJRA5kwlPj0PWOLocq8D26pNSMiP034Ah9bojpM6jnbFT4lXeV85PdCABhcqyLZVNiKqU/Yozx1Ui9UsXfPLcHl1SnvIOBFRIaih5WzZ0CMAENXzjrfSxvrFGCYLrwORO/uSJc0t root@storm_2
# storm_3 节点
[root@storm_3 ~]# cat ~/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCzwB3Qq0ElUY6EDRYQF5NupPtQ6hILzzDrVp9GGdavdsjxlO1kD5LroeP2s94A38u0jbXiEYJZhNprfA+a+UuT6DtVVIIl9/gPrNlRUFLy+8vbzhN9G8hsqcB0nb3VNtnMJGsS9QyOmOieqp4fW15HZn0jQIS+TgmgaMeaMlK8LV5cO0S4sCjPTbtXMDKZ/oNWFenZ143Ul4ViAPudLm9o6ik4UkFaP847cxyKy/jgpDdEQBibRucrTiQWoJ/uhiHH020MqEv6H2ZbmjOXbEQLFo8b6feSJSp0RaFZuook0CNs88QXxSKRw+kKEDlEZGCUuvFHLfIzV7C4PExEViml root@storm_3
# 每个节点中的 authorized_keys 文件内容
[root@storm_1 ~]# cat ~/.ssh/authorized_keys
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQD0z8u8K0wGWLhhzxcztokzVWHqKf1O5PScjkIvXFh2AnEqZz+d5/LqyT6qDi1T8p+k4UHCkgmRqWZbG+LEtzQEjE3/Guya4uEP5g8MGvnLUSQQWS5oQN6EAq2fQ7G806fipQCEKWETF7axk6We1NNUjO27c071OMQ2JXM7PLVQACaUcaI8sJg3uHOs7Bcb871tyiuXtVygpyjJEBxvzpuxcjEJI/C/Yu+q28KXRfSWblJ7hIN7c8eIGYumTi4vSKo3Rwwm5UGvBIopK8Xc4SmvrZ6jpHInR2YLQsEznrcR9MprhHXPeFgnoJ3vCLeXbOesmH+h6Cb4UJChUR7owWKr root@storm_1
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC/n9bY6jD8Z2mkgZLO9meXAMNvDt/YJRpcTM57ko2p9Cmm4c+CgQzstBExOAciQR9ckranLj8k/GYDBL5jBIBjquvVEtA06sCp6vGsvUOOOg07VgrmpbEvGNovNa8bfVOXR5cSbqwoesPu33wG43WXDdpD7vKU9YrqUyNXj1xPi+xTQwWkUMz9zEH8zwYuhD7pglP7iJsvzl/GpJRA5kwlPj0PWOLocq8D26pNSMiP034Ah9bojpM6jnbFT4lXeV85PdCABhcqyLZVNiKqU/Yozx1Ui9UsXfPLcHl1SnvIOBFRIaih5WzZ0CMAENXzjrfSxvrFGCYLrwORO/uSJc0t root@storm_2
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCzwB3Qq0ElUY6EDRYQF5NupPtQ6hILzzDrVp9GGdavdsjxlO1kD5LroeP2s94A38u0jbXiEYJZhNprfA+a+UuT6DtVVIIl9/gPrNlRUFLy+8vbzhN9G8hsqcB0nb3VNtnMJGsS9QyOmOieqp4fW15HZn0jQIS+TgmgaMeaMlK8LV5cO0S4sCjPTbtXMDKZ/oNWFenZ143Ul4ViAPudLm9o6ik4UkFaP847cxyKy/jgpDdEQBibRucrTiQWoJ/uhiHH020MqEv6H2ZbmjOXbEQLFo8b6feSJSp0RaFZuook0CNs88QXxSKRw+kKEDlEZGCUuvFHLfIzV7C4PExEViml root@storm_3
|
- 在3台机子上创建config文件(3台机子都要执行)
|
1
|
[root@storm_1 wordcount]# touch /root/.ssh/config
|
- 下载 lein 文件到 /usr/local/bin 目录中,授予可执行权限(3台机子都要执行)
|
1
2
3
|
[root@storm_1 wordcount]# wget https://raw.githubusercontent.com/technomancy/leiningen/stable/bin/lein
[root@storm_1 wordcount]# mv lein /usr/local/bin/
[root@storm_1 wordcount]# chmod 755 /usr/local/bin/lein
|
- 安装streamparse(3台机子都要执行)
|
1
|
[root@storm_1 wordcount]# pip install streamparse
|
- 创建storm_project 目录,并且开始一个简单的Storm项目(在storm_2上操作),这边不要再Storm启动的Nimbus节点上创建,因为到时候运行Storm项目会有端口上的冲突。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
[root@storm_2 ~]# mkdir -p /u01/storm_project
[root@storm_2 ~]# cd /u01/storm_project/
[root@storm_2 storm_project]# pwd
/u01/storm_project
[root@storm_2 ~]# sparse quickstart wordcount
Creating your wordcount streamparse project...
create wordcount
create wordcount/.gitignore
create wordcount/config.json
create wordcount/fabfile.py
create wordcount/project.clj
create wordcount/README.md
create wordcount/src
create wordcount/src/bolts/
create wordcount/src/bolts/__init__.py
create wordcount/src/bolts/wordcount.py
create wordcount/src/spouts/
create wordcount/src/spouts/__init__.py
create wordcount/src/spouts/words.py
create wordcount/topologies
create wordcount/topologies/wordcount.py
create wordcount/virtualenvs
create wordcount/virtualenvs/wordcount.txt
Done.
Try running your topology locally with:
cd wordcount
sparse run
|
- 设置json配置文件(在storm_2上操作)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
[root@storm_2 wordcount]# cat /u01/storm_project/wordcount/config.json
{
"library": "",
"topology_specs": "topologies/",
"virtualenv_specs": "virtualenvs/",
"envs": {
"prod": {
"user": "root",
"nimbus": "storm_1",
"workers": [
"storm_1",
"storm_2",
"storm_3"
],
"log": {
"path": "/tmp/storm/stream/log",
"file": "pystorm_{topolopy_name}_{component_name}_{task_id}_{pid}.log",
"max_bytes": 1000000,
"backup_count": 10,
"level": "info"
},
"use_ssh_for_nimbus": true,
"virtualenv_root": "/tmp/storm/stream/virtualenvs"
}
}
}
|
- 创建相关目录(3个机器上都需要执行)
|
1
2
|
[root@storm_1 wordcount]# mkdir -p /tmp/storm/stream/log
[root@storm_1 wordcount]# mkdir -p /tmp/storm/stream/virtualenvs
|
- 将wordcount程序提交到Storm集群上(在storm_2上操作)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
[root@storm_2 wordcount]# pwd
/u01/storm_project/wordcount
[root@storm_2 wordcount]# sparse submit
[storm_1] Executing task '_create_or_update_virtualenv'
[storm_2] Executing task '_create_or_update_virtualenv'
... omit ...
[storm_1] run: rm /tmp/streamparse_requirements-oD8qdm4We.txt
[storm_3] out:
[storm_3] run: rm /tmp/streamparse_requirements-5greXfqjW.txt
Cleaning from prior builds...
# 需要敲回车键
Creating topology Uber-JAR...
# 需要敲回车键
Uber-JAR created: /u01/storm_project/wordcount/_build/wordcount-0.0.1-SNAPSHOT-standalone.jar
Deploying "wordcount" topology...
ssh tunnel to Nimbus storm_1:6627 established.
Routing Python logging to /tmp/storm/stream/log.
Running lein command to submit topology to nimbus:
lein run -m streamparse.commands.submit_topology/-main topologies/wordcount.clj --option 'topology.workers=2' --option 'topology.acker.executors=2' --option 'topology.python.path="/tmp/storm/stream/virtualenvs/wordcount/bin/python"' --option 'streamparse.log.path="/tmp/storm/stream/log"' --option 'streamparse.log.max_bytes=1000000' --option 'streamparse.log.backup_count=10' --option 'streamparse.log.level="info"'
WARNING: You're currently running as root; probably by accident.
Press control-C to abort or Enter to continue as root.
Set LEIN_ROOT to disable this warning.
# 需要敲回车键
{:option {streamparse.log.level info, streamparse.log.backup_count 10, streamparse.log.max_bytes 1000000, streamparse.log.path /tmp/storm/stream/log, topology.python.path /tmp/storm/stream/virtualenvs/wordcount/bin/python, topology.acker.executors 2, topology.workers 2}, :debug false, :port 6627, :host localhost, :help false}
1604 [main] INFO backtype.storm.StormSubmitter - Jar not uploaded to master yet. Submitting jar...
1620 [main] INFO backtype.storm.StormSubmitter - Uploading topology jar /u01/storm_project/wordcount/_build/wordcount-0.0.1-SNAPSHOT-standalone.jar to assigned location: /u01/storm/status/nimbus/inbox/stormjar-03200d7a-dec1-44a6-b0f7-e775d0227864.jar
3853 [main] INFO backtype.storm.StormSubmitter - Successfully uploaded topology jar to assigned location: /u01/storm/status/nimbus/inbox/stormjar-03200d7a-dec1-44a6-b0f7-e775d0227864.jar
3854 [main] INFO backtype.storm.StormSubmitter - Submitting topology wordcount in distributed mode with conf {"streamparse.log.backup_count":10,"streamparse.log.path":"\/tmp\/storm\/stream\/log","topology.python.path":"\/tmp\/storm\/stream\/virtualenvs\/wordcount\/bin\/python","topology.debug":false,"nimbus.thrift.port":6627,"topology.max.spout.pending":5000,"nimbus.host":"localhost","topology.workers":2,"topology.acker.executors":2,"streamparse.log.max_bytes":1000000,"streamparse.log.level":"info","topology.message.timeout.secs":60}
4487 [main] INFO backtype.storm.StormSubmitter - Finished submitting topology: wordcount
|
如果输出类似上面的信息就算是部署完成了。
- 确认wordcount程序已经部署到了 Storm中
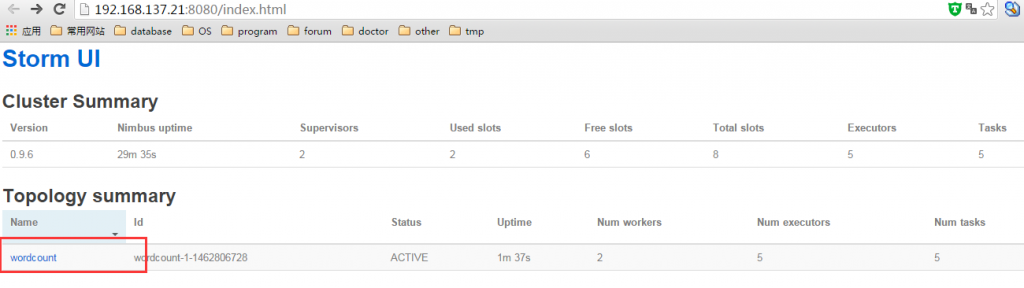
- 停止Storm中的wordcount程序
|
1
2
3
4
5
6
7
8
9
|
[root@storm_2 wordcount]# pwd
/u01/storm_project/wordcount
[root@storm_2 wordcount]# sparse kill -n wordcount
WARNING: You're currently running as root; probably by accident.
Press control-C to abort or Enter to continue as root.
Set LEIN_ROOT to disable this warning.
5180 [main] INFO backtype.storm.thrift - Connecting to Nimbus at localhost:6627
Killed topology: wordcount
|
出现上面信息就说明wordcount程序已经从Storm集群中停止并移除了。

22.4.9. streamparse代码编写
由于这是示例程序,我们就在之前创建好的wordcount项目中修改代码。在这里我们只需要修改spout和bolt的代码就好。
这边我们需要安装Python Kafka和Python MongoDB的相关模块,执行如下命令:
|
1
2
3
4
5
6
|
# 在操作系统自带的Python中安装,主要是为了使用sparse run时会调用
pip install pykafka
pip install pymongo
# 在streamparse Storm Python虚拟环境中安装(sparse submit)
/tmp/storm/stream/virtualenvs/wordcount/bin/pip install pykafka
/tmp/storm/stream/virtualenvs/wordcount/bin/pip install pymongo
|
- words.py代码(spout)
words.py的功能就是不断消费kafka产生的消息,并且发送(emit)下面一个接收者(spout|bolt)。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
[root@storm_2 spouts]# pwd
/u01/storm_project/wordcount/src/spouts
[root@storm_2 spouts]#
[root@storm_2 spouts]#
[root@storm_2 spouts]# cat words.py
# -*- coding:utf-8 -*-
from __future__ import absolute_import, print_function, unicode_literals
import itertools
from streamparse.spout import Spout
from pykafka import KafkaClient
import simplejson as json
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class WordSpout(Spout):
def initialize(self, stormconf, context):
# self.words = itertools.cycle(['dog', 'cat',
# 'zebra', 'elephant'])
client = KafkaClient(hosts="10.10.10.11:9092")
topic = client.topics[b"test"]
self.balanced_consumer = topic.get_balanced_consumer(
consumer_group=b"test_group",
auto_commit_enable=True,
zookeeper_connect="storm_1:2181,storm_2:2181,storm_3:2181"
)
def next_tuple(self):
# word = next(self.words)
# self.emit([word])
message = self.balanced_consumer.consume()
# Logstash字符串转化为dict
log_info = json.loads(message.value)
word = log_info["message"]
with open("/tmp/storm.log", "a") as f:
f.write(word)
self.emit([word])
|
- py代码
wordcount.py主要是实现了,接收从words.py发送的信息(json字符串),并将接收的到信息解析成转化成python的字典类型,分析数据存放到MongoDB(10.10.10.12)中。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
[root@storm_2 bolts]# pwd
/u01/storm_project/wordcount/src/bolts
[root@storm_2 bolts]#
[root@storm_2 bolts]# cat wordcount.py
# -*- coding:utf-8 -*-
from __future__ import absolute_import, print_function, unicode_literals
from collections import Counter
from streamparse.bolt import Bolt
import simplejson as json
from pymongo import MongoClient
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class WordCounter(Bolt):
def initialize(self, conf, ctx):
# self.counts = Counter()
client = MongoClient(b"10.10.10.12:27017,10.10.10.12:27018,10.10.10.12:27019",
replicaset="rs_12")
# 获得 order_stat 数据库
self.db = client.shop
def process(self, tup):
# 获得从spout传过来的字符串
word = tup.values[0]
# self.counts[word] += 1
# self.emit([word, self.counts[word]])
# self.log('%s: %d' % (word, self.counts[word]))
# 将spout传来的字符串解析成dict
order_info = json.loads(word)
# 通过 kafka 传入的 user_name 查找相关用户统计信息
condition = {"user_name": order_info["user_name"]}
order_stat_info = self.db.order_stat.find_one(condition)
## 如果order_stat_info无值则插入, 有值则更新
# 1、无值情况
if not order_stat_info:
order_stat_info_new = {
"user_name": order_info.get("user_name", "Unknow"),
"order_num": 1,
"total_price": order_info.get("price", 0.00),
"min_order_price": order_info.get("price", 0.00),
"max_order_price": order_info.get("price", 0.00),
"min_order": order_info.get("order_id", 0),
"max_order": order_info.get("order_id", 0),
}
self.db.order_stat.insert_one(order_stat_info_new)
# 2、有值情况
else:
min_order_price = min(order_stat_info["min_order_price"],
order_info.get("price", 0.00))
max_order_price = max(order_stat_info["max_order_price"],
order_info.get("price", 0.00))
min_order = order_stat_info["min_order"]
max_order = order_stat_info["max_order"]
# 设置 最小order id
if min_order_price == order_info.get("price", 0.00):
min_order = order_info.get("order_id", min_order)
# 设置 最大order id
if max_order_price == order_info.get("price", 0.00):
max_order = order_info.get("order_id", max_order)
# 构造更新的信息
order_stat_info_new = {
"order_num": order_stat_info["order_num"] + 1,
"total_price": order_stat_info["total_price"] +
order_info.get("price", 0.00),
"min_order_price": min_order_price,
"max_order_price": max_order_price,
"min_order": min_order,
"max_order": max_order
}
# 跟新信息
self.db.order_stat.update_one({"_id": order_stat_info["_id"]},
{"$set": order_stat_info_new})
|
编写好上面代码之后就需要测试运行情况了。
- 运行streamparse进行测试
由于我们还不知道我们写的代码正确性,因此需要使用sparse run来记性调试,而非使用sparse submit直接提交到Storm环境中。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@storm_2 wordcount]# pwd
/u01/storm_project/wordcount
[root@storm_2 wordcount]#
[root@storm_2 wordcount]# sparse run
... Omit ...
8653 [Thread-15-count-bolt] INFO backtype.storm.task.ShellBolt - Launched subprocess with pid 3719
8703 [Thread-16-word-spout] INFO backtype.storm.spout.ShellSpout - Launched subprocess with pid 3717
8706 [Thread-13-count-bolt] INFO backtype.storm.task.ShellBolt - Start checking heartbeat...
8706 [Thread-13-count-bolt] INFO backtype.storm.daemon.executor - Prepared bolt count-bolt:(3)
8708 [Thread-15-count-bolt] INFO backtype.storm.task.ShellBolt - Start checking heartbeat...
8708 [Thread-15-count-bolt] INFO backtype.storm.daemon.executor - Prepared bolt count-bolt:(4)
8708 [Thread-16-word-spout] INFO backtype.storm.daemon.executor - Opened spout word-spout:(5)
8715 [Thread-16-word-spout] INFO backtype.storm.daemon.executor - Activating spout word-spout:(5)
8715 [Thread-16-word-spout] INFO backtype.storm.spout.ShellSpout - Start checking heartbeat...
|
- 向Logstash(10.10.11)监听的文件中输入相关的订单信息
|
1
2
3
4
5
6
7
8
9
|
echo '{"order_id":1, "price":20, "user_name":"Bob", "goods_name":"good_name2"}' > /tmp/orders.log
echo '{"order_id":2, "price":120, "user_name":"Bob", "goods_name":"good_name1"}' >> /tmp/orders.log
echo '{"order_id":3, "price":1120, "user_name":"Bob", "goods_name":"good_name4"}' >> /tmp/orders.log
echo '{"order_id":4, "price":11120, "user_name":"Bob", "goods_name":"good_name3"}' >> /tmp/orders.log
echo '{"order_id":1, "price":10, "user_name":"Tom", "goods_name":"good_name2"}' >> /tmp/orders.log
echo '{"order_id":2, "price":110, "user_name":"Tom", "goods_name":"good_name1"}' >> /tmp/orders.log
echo '{"order_id":3, "price":1110, "user_name":"Tom", "goods_name":"good_name4"}' >> /tmp/orders.log
echo '{"order_id":4, "price":11110, "user_name":"Tom", "goods_name":"good_name3"}' >> /tmp/orders.log
|
- 查看MongoDB(10.10.12)中的订单统计信息
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
[root@normal_12 ~]# /u01/mongodb_27018/client_mongodb.sh
MongoDB shell version: 3.2.5
connecting to: 10.10.10.12:27018/test
(test) 01:01:10>
(test) 01:01:11> use shop
switched to db shop
(shop) 01:01:16>
(shop) 01:22:32>db.order_stat.find()
{
"_id" : ObjectId("5734bba0172d290f86e2d2e4"),
"total_price" : 12380,
"min_order_price" : 20,
"min_order" : 1,
"order_num" : 4,
"max_order_price" : 11120,
"user_name" : "Bob",
"max_order" : 4
}
{
"_id" : ObjectId("5734bbf1172d290f844d2fdc"),
"total_price" : 12230,
"min_order_price" : 10,
"min_order" : 1,
"order_num" : 3,
"max_order_price" : 11110,
"user_name" : "Tom",
"max_order" : 4
}
|
- 最后只要将我们的项目提交到Storm上面去就好了
|
1
2
3
4
|
[root@storm_2 wordcount]# pwd
/u01/storm_project/wordcount
[root@storm_2 wordcount]#
[root@storm_2 wordcount]# sparse submit
|
到这里我们就使用Python完成了Storm环境的搭建和开发。
22.4. 总结
其实许多的系统中都不纯属于的OLTP或者OLAP,基本上是他们两个的结合体。当OLTP中掺杂OLAP的时候有时候如果单靠数据库查询来解决问题,这样就会造成OLTP系统变的慢(因为查询变大而复杂)。因此,遇到这类的情况就需要在架构层面上去解决了。现在,Storm和Spark都是用于实时计算。因此,有碰到类似以上场景的朋友,可以考虑给系统换上“新装”了。
昵称: HH
QQ: 275258836
ttlsa群交流沟通(QQ群②: 6690706 QQ群③: 168085569 QQ群④: 415230207(新) 微信公众号: ttlsacom)
MySQL应用架构优化-实时数据处理的更多相关文章
- 【MySQL参数优化】根据架构优化
根据MySQL的架构优化 参数调整的最终效果: 1)SQL执行速度足够快 2)业务吞吐量足够高:TPS,QPS 3)系统负载可控,合理:cpu,io负载 在调整参数的时候,应该熟悉mysql的体系架构 ...
- MySQL数据库的优化(下)MySQL数据库的高可用架构方案
MySQL数据库的优化(下)MySQL数据库的高可用架构方案 2011-03-09 08:53 抚琴煮酒 51CTO 字号:T | T 在上一篇MySQL数据库的优化中,我们跟随笔者学习了单机MySQ ...
- [转]MySQL数据库的优化-运维架构师必会高薪技能,笔者近六年来一线城市工作实战经验
本文转自:http://liangweilinux.blog.51cto.com/8340258/1728131 年,嘿,废话不多说,下面开启MySQL优化之旅! 我们究竟应该如何对MySQL数据库进 ...
- MySQL数据库的优化-运维架构师必会高薪技能,笔者近六年来一线城市工作实战经验
原文地址:http://liangweilinux.blog.51cto.com/8340258/1728131 首先在此感谢下我的老师年一线实战经验,我当然不能和我的老师平起平坐,得到老师三分之一的 ...
- 优秀后端架构师必会知识:史上最全MySQL大表优化方案总结
本文原作者“ manong”,原创发表于segmentfault,原文链接:segmentfault.com/a/1190000006158186 1.引言 MySQL作为开源技术的代表作之一,是 ...
- MySQL 高级性能优化架构 千万级高并发交易一致性系统基础
一.MySQL体系架构 由图,可以看出MySQL最上层是连接组件.下面服务器是由连接池.管理服务和工具组件.SQL接口.查询解析器.查询优化器.缓存.存储引擎.文件系统组成. 1.连接池 管理.缓冲用 ...
- MySQL 到 ES 数据实时同步技术架构
MySQL 到 ES 数据实时同步技术架构 我们已经讨论了数据去规范化的几种实现方式.MySQL 到 ES 数据同步本质上是数据去规范化多种实现方式中的一种,即通过"数据迁移同步" ...
- MySQL架构优化:定时计划任务与表分区
转自: MySQL架构优化实战系列3:定时计划任务与表分区 - 今日头条(TouTiao.com)http://toutiao.com/a6304736482361049345/?tt_from=mo ...
- mysql数据库架构设计与优化
mysql数据库架构设计与优化 2019-04-23 20:51:20 无畏D尘埃 阅读数 179 收藏 更多 分类专栏: MySQL 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA ...
随机推荐
- java EE第一周博客
一,课程目标 能够完成javaee开发框架的深入学习,能够熟练的构建出基本开发框架,熟练掌握配置文件以及各种插件的应用.实现一个较为复杂的javaee项目 二.企业级应用与互联网应用的区别 企业级应用 ...
- 解决org.apache.rat:apache-rat-plugin:0.8:check (default) on project hbase: Too many unapproved license
maven打包的时候报错: 报错信息: [ERROR] Failed to execute goal org.apache.rat:apache-rat-plugin:0.8:check (defau ...
- Ubuntu下安装qq方法及疑难问题解决
在Ubuntu下安装qq有两种方法:.tar.gz包安装和.deb包安装下载地址:http://im.qq.com/qq/linux/download.shtml 方法一:.tar.gz包安装法 .t ...
- postman环境变量 全局变量清理
一:主要内容 清除一个环境变量.全局变量 清除全部环境变量.全局变量 清除部分环境变量.全局变量 二:清除一个指定环境变量.全局变量 1. 清除一个环境变量,如清除用户名环境变量,username为变 ...
- 使用Unicode字符实现换行
要让inline元素换行可以使用Unicode字符实现: <!DOCTYPE html> <html lang="en"> <head> < ...
- POJ 1740(构造博弈)
题目链接: https://cn.vjudge.net/problem/POJ-1740 题目描述: Alice and Bob decide to play a new stone game.At ...
- 并发编程之 Semaphore 源码分析
前言 并发 JUC 包提供了很多工具类,比如之前说的 CountDownLatch,CyclicBarrier ,今天说说这个 Semaphore--信号量,关于他的使用请查看往期文章并发编程之 线程 ...
- linux中使用Crontab定时执行java的jar包无法使用环境变量的问题
1.crontab简单使用 cmd 其实就是5个星星的事情,随便百度一下吧 5个时间标签用来标注执行的设定.比如每5分钟执行一次/5 * * * cmd 要特别注意 2.有些命令在命令行里执行很好,到 ...
- [c#] Html Agility Pack 解析HTML
摘要 在开发过程中,很有可能会遇到这样的情况,服务端返回的是html的内容,但需要在客户端显示纯文本内容,这时候就需要解析这些html,拿到里面的纯文本.达到这样的目的可以有很多途径,比如自己写正则表 ...
- 选择ORACLE数据库字符集
如何选择数据库的字符集是一个有争议的话题,字符集本身涉及的范围很广,它与应用程序.客户的本地环境.操作系统.服务器等关系很密切,因此要做出合适的 选择,需要明白这些因素之间的关系.另外对字符集的基本概 ...