Python爬虫-爬取手机应用市场中APP下载量
一、首先是爬取360手机助手应用市场信息,用来爬取360应用市场,App软件信息,现阶段代码只能爬取下载量,如需爬取别的信息,请自行添加代码。
使用方法:
1、在D盘根目录新建.tet文件,命名为App_name,并把App名称黏贴到文件内,格式如下:

2、直接运行就好。
最近比较忙,好久没更新博客了,为什么忙呢,是因为最近被派到“App专项治理组”做App治理工作了,在专班成立初期热心网友举报量比较多,天天处理举报问题,和统计被举报App的下载量,而且是5个应用市场下载量和,如果就几款App可能还好,但是每天处理几百款App,俺表示眼睛和手指头都抗议,这时我就想起了python,所以决定做5个爬虫,分别爬取5个应用市场上App信息,废话不多说,下面是我的代码:
1、第一种方法,使用字典完成。
# !/usr/bin/env python
# -*- coding: UTF-8 –*-
__author__ = 'Mr.Li' import requests
from bs4 import BeautifulSoup
import xlsxwriter,time def write_excel(name, download, type_name=0, url=0):
# 全局变量row代表行号 0-2代表列数
global row
sheet.write(row, 0, row)
sheet.write(row, 1, name)
sheet.write(row, 2, download) row += 1 headers = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'} def App_download(url,app_name):
# 获取地址
i = 1
try:
time.sleep(0.5)
req = requests.get(url=url,headers=headers)
req.encoding = 'utf-8' # 获取的内容保存在变量
html_all = req.text div_bf = BeautifulSoup(html_all, 'html.parser') # 使用BeautifulSoup进行解析
div = div_bf.find_all('div',class_='SeaCon')#查找SeaCon元素内容 a_bf = BeautifulSoup(str(div), 'html.parser') # 重新解析
info = a_bf.find_all('li') # 查找元素为'li'的内容,其中包括APP的名称和下载量信息
name = info[0].dl.dd.h3.a.text.strip()
all_list = []
if name == app_name: download_num = BeautifulSoup(str(info[0]), 'html.parser') # 重新解析
texts = download_num.find_all('p', class_='downNum')#查找下载量
find_download_num = texts[0].text.replace('\xa0'*8,'\n\n')[:-3]#去除不需要的信息
print(name, find_download_num)
write_excel(name,find_download_num)#写入xlsx文件
else:
find_download_num1= 'None'
print(app_name,find_download_num1)
write_excel(app_name,find_download_num1) except Exception as e:
#print('error:%s,尝试重新获取'%(e,i))
#print(url)
if i != 3:
App_download(url, app_name)
i += 1 row = 1
# 新建一个excel文件
file = xlsxwriter.Workbook('360_applist.xlsx')
# 新建一个sheet
sheet = file.add_worksheet()
if __name__ == '__main__':
path_file = "D:\\"
Old_AppFlie = open(path_file + "App_name.txt").read()
app_list = Old_AppFlie.split('\n') # 把字符串转为列表
#app_list = ['微信','1113123','支付宝','荔枝']
for app_name in app_list:
yyb_url = 'http://zhushou.360.cn/search/index/?kw={app_name}'.format(app_name=app_name)
App_download(yyb_url,app_name)
file.close()
运行结果:
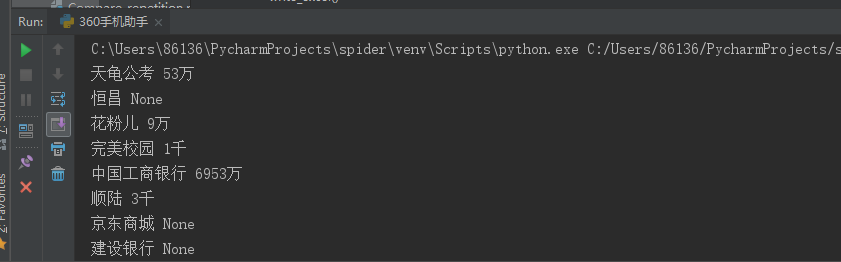
可以查到的,会显示下载量,如果在应用中查不到会显示None,并把结果写到360_applist.xlsx文件中。
已经过一段时间使用以上程序发现一个问题,如果所爬取的程序不存在,也就是在360应用市场中搜索不到的话,程序就会卡死,搜索不到指的是页面一个内容也没有,如下图:

这样的话程序会卡死,最终出错,这是因为我们程序中需要用到索引,在查询结果中进行索引,但是结果是空的,在使用索引就超范围了,所以会卡死报错,我们可以判断是,如果搜索不到内容及搜索结果为空也就是0,我在程序中做了判断,如果搜索结果长度不等于0就执行爬取下载量操作,然后下入数据,如果等于0就直接写入APP名称和None表示没有东西。
修改后代码:
# !/usr/bin/env python
# -*- coding: UTF-8 –*-
__author__ = 'Mr.Li' import requests
from bs4 import BeautifulSoup
import xlsxwriter,time def write_excel(name, download, type_name=0, url=0):
# 全局变量row代表行号 0-2代表列数
global row
sheet.write(row, 0, row)
sheet.write(row, 1, name)
sheet.write(row, 2, download) row += 1 headers = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'} def App_download(url,app_name):
# 获取地址
i = 1
try:
time.sleep(0.5)
req = requests.get(url=url,headers=headers)
req.encoding = 'utf-8' # 获取的内容保存在变量
html_all = req.text div_bf = BeautifulSoup(html_all, 'html.parser') # 使用BeautifulSoup进行解析
div = div_bf.find_all('div',class_='SeaCon')#查找SeaCon元素内容 a_bf = BeautifulSoup(str(div), 'html.parser') # 重新解析
info = a_bf.find_all('li') # 查找元素为'li'的内容,其中包括APP的名称和下载量信息
name = info[0].dl.dd.h3.a.text.strip()
all_list = []
if name == app_name: download_num = BeautifulSoup(str(info[0]), 'html.parser') # 重新解析
texts = download_num.find_all('p', class_='downNum')#查找下载量
find_download_num = texts[0].text.replace('\xa0'*8,'\n\n')[:-3]#去除不需要的信息
print(name, find_download_num)
write_excel(name,find_download_num)#写入xlsx文件
else:
find_download_num1= 'None'
print(app_name,find_download_num1)
write_excel(app_name,find_download_num1) except Exception as e:
#print('error:%s,尝试重新获取'%(e,i))
#print(url)
if i != 3:
App_download(url, app_name)
i += 1 row = 1
# 新建一个excel文件
file = xlsxwriter.Workbook('360_applist.xlsx')
# 新建一个sheet
sheet = file.add_worksheet()
if __name__ == '__main__':
path_file = "D:\\"
Old_AppFlie = open(path_file + "App_name.txt").read()
app_list = Old_AppFlie.split('\n') # 把字符串转为列表
#app_list = ['微信','1113123','支付宝','荔枝']
for app_name in app_list:
yyb_url = 'http://zhushou.360.cn/search/index/?kw={app_name}'.format(app_name=app_name)
App_download(yyb_url,app_name)
file.close()
二、爬取百度应用市场APP信息
# !/usr/bin/env python
# -*- coding: UTF-8 –*-
__author__ = 'Mr.Li'
import requests
from bs4 import BeautifulSoup
import xlsxwriter,time
def write_excel(name, download, type_name=0, url=0):
# 全局变量row代表行号 0-2代表列数
global row
sheet.write(row, 0, row)
sheet.write(row, 1, name)
sheet.write(row, 2, download)
row += 1
headers = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'}
def App_download(url,app_name):
# 获取地址
i = 1
try:
time.sleep(0.5)
req = requests.get(url=url,headers=headers)
req.encoding = 'utf-8'
# 获取的内容保存在变量
html_all = req.text
div_bf = BeautifulSoup(html_all, 'html.parser') # 使用BeautifulSoup进行解析
div = div_bf.find_all('div',class_='SeaCon')#查找SeaCon元素内容
a_bf = BeautifulSoup(str(div), 'html.parser') # 重新解析
info = a_bf.find_all('li') # 查找元素为'li'的内容,其中包括APP的名称和下载量信息
name = info[0].dl.dd.h3.a.text.strip()
if len(info) != 0:
if name == app_name:
download_num = BeautifulSoup(str(info[0]), 'html.parser') # 重新解析
texts = download_num.find_all('p', class_='downNum')#查找下载量
find_download_num = texts[0].text.replace('\xa0'*8,'\n\n')[:-3]#去除不需要的信息
print(name, find_download_num)
write_excel(name,find_download_num)#写入xlsx文件
else:
find_download_num1= 'None'
print(app_name,find_download_num1)
write_excel(app_name,find_download_num1)
else:
print(app_name, 'None')
write_excel(app_name, 'None')
except Exception as e:
#print('error:%s,尝试重新获取'%(e,i))
#print(url)
if i != 3:
App_download(url, app_name)
i += 1
row = 1
# 新建一个excel文件
file = xlsxwriter.Workbook('360_applist.xlsx')
# 新建一个sheet
sheet = file.add_worksheet()
if __name__ == '__main__':
path_file = "D:\\"
Old_AppFlie = open(path_file + "App_name.txt").read()
app_list = Old_AppFlie.split('\n') # 把字符串转为列表
#app_list = ['微信','1113123','支付宝','荔枝']
for app_name in app_list:
yyb_url = 'http://zhushou.360.cn/search/index/?kw={app_name}'.format(app_name=app_name)
App_download(yyb_url,app_name)
file.close()
三、爬取华为应用市场APP信息
# !/usr/bin/env python
# -*- coding: UTF-8 –*-
__author__ = 'Mr.Li' import requests
from bs4 import BeautifulSoup
import xlsxwriter def write_excel(name, download, type_name=0, url=0):
# 全局变量row代表行号 0-2代表列数
global row
sheet.write(row, 0, row)
sheet.write(row, 1, name)
sheet.write(row, 2, download) row += 1 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36'} def App_download(url,app_name):
# 获取地址
i = 1
try:
req = requests.get(url=url,headers=headers)
req.encoding = 'utf-8' # 获取的内容保存在变量
html_all = req.text
div_bf = BeautifulSoup(html_all, 'html.parser') # 使用BeautifulSoup进行解析
div = div_bf.find_all('div',class_='unit-main')#查找SeaCon元素内容 a_bf = BeautifulSoup(str(div), 'html.parser') # 重新解析
info = a_bf.find_all('div',class_='list-game-app dotline-btn nofloat') # 查找元素为'li'的内容,其中包括APP的名称和下载量信息 if len(info) != 0: name = info[0].h4.a.text.strip() # 获取app名称,去除两边的空格
if name == app_name:
download_num = BeautifulSoup(str(info[0]), 'html.parser') # 重新解析
texts = download_num.find_all('span') # 查找下载量
find_download_num = texts[3].text.replace('\xa0' * 8, '\n\n')[2:] # 去除不需要的信息
print(name, find_download_num)
write_excel(name, find_download_num) # 写入xlsx文件
else:
find_download_num1= 'None'
print(app_name,find_download_num1)
write_excel(app_name,find_download_num1)
else:
print(app_name, 'None')
write_excel(app_name, 'None') # 写入xlsx文件
except Exception as e:
#print('error:%s,尝试重新获取'%(e,i))
#print(url)
if i != 3:
App_download(url, app_name)
i += 1 row = 1
# 新建一个excel文件
file = xlsxwriter.Workbook('hw_applist.xlsx')
# 新建一个sheet
sheet = file.add_worksheet()
if __name__ == '__main__':
path_file = "D:\\"
Old_AppFlie = open(path_file + "App_name.txt").read()
app_list = Old_AppFlie.split('\n') # 把字符串转为列表
#app_list = ['微信','wea11','支付宝','荔枝']
for app_name in app_list:
yyb_url = 'https://appstore.huawei.com/search/{app_name}'.format(app_name=app_name)
App_download(yyb_url,app_name)
file.close()
爬取华为和百度应用市场代码就不详细介绍了,原理一样,如果感兴趣你还可以在这基础上做出更改,加入爬取APP介绍信息,爬取APP版本等功能。
2019.12.09再次更新,更新原因,因为各大应用市场名称不太一样,为了实现模糊匹配,提高精度,笔者又进行了一次更新,模糊匹配本来应该使用re的正则表达式的,但是考虑到各大应用市场名称的不确定性,以及如果下载量错误,还不如没有下载量的情况,所以笔者在代码中只是增加了一个小小或的判断,看代码:
百度手机助手应用市场代码:
# !/usr/bin/env python
# -*- coding: UTF-8 –*-
__author__ = 'Mr.Li' import requests
from bs4 import BeautifulSoup
import xlsxwriter def write_excel(name, download, type_name=0, url=0):
# 全局变量row代表行号 0-2代表列数
global row
sheet.write(row, 0, row)
sheet.write(row, 1, name)
sheet.write(row, 2, download) row += 1 name_wu = 'None'
find_download_num_wu = '无'
headers = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'} def App_download(url,app_name):
# 获取地址
i = 1
try:
req = requests.get(url=url,headers=headers)
req.encoding = 'utf-8'
# 获取的内容保存在变量
html_all = req.text
div_bf = BeautifulSoup(html_all, 'html.parser') # 使用BeautifulSoup进行解析
div = div_bf.find_all('ul',class_='app-list')#查找app-list元素内容 a_bf = BeautifulSoup(str(div), 'html.parser') # 重新解析
info = a_bf.find_all('div',class_='info') # 查找元素为'info'的内容,其中包括APP的名称和下载量信息
if len(info) != 0:
name = info[0].a.text.strip()#获取app名称,去除两边的空格
download_num = BeautifulSoup(str(info[0]), 'html.parser') # 重新解析
texts = download_num.find_all('span', class_='download-num') # 查找下载量
find_download_num = texts[0].text.replace('\xa0' * 8, '\n\n') # 去除不需要的信息 if app_name in name or name in app_name: #模糊匹配,判断自己输入App名称是否在查找到的内容中
print(name,find_download_num)
write_excel(name,find_download_num)#写入xlsx文件
else:
find_download_num1= 'None'
print(app_name,find_download_num1)
write_excel(app_name,find_download_num1)
else:
print(app_name, 'None')
write_excel(app_name, 'None')
except Exception as e:
#print('error:%s,尝试重新获取'%(e,i))
#print(url)
if i != 3:
App_download(url, app_name)
i += 1 row = 1
# 新建一个excel文件
file = xlsxwriter.Workbook('baidu_applist.xlsx')
# 新建一个sheet
sheet = file.add_worksheet()
if __name__ == '__main__':
path_file = "D:\\"
Old_AppFlie = open(path_file + "App_name.txt").read()
app_list = Old_AppFlie.split('\n') # 把字符串转为列表
#app_list = ['支付宝','as','荔枝']
for app_name in app_list:
yyb_url = 'https://shouji.baidu.com/s?wd={app_name}&data_type=app&f=header_all%40input'.format(app_name=app_name)
App_download(yyb_url,app_name)
file.close()
这样更新后的精度虽然不是很高,但是可以提高一半,最主要是不会爬错,我们要的就是数据准确,哈哈!!,如果小伙伴有高精度要求,可以考虑正则匹配,自己改一下。
Python爬虫-爬取手机应用市场中APP下载量的更多相关文章
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
随机推荐
- MySQL函数--时间格式--流程控制if判断
目录 一:函数 1.MySQL什么是函数? 2.通过help查看函数帮助 3.移除指定字符 4.大小写转换 5.获取左右起始指定个数字符 6.返回读音相似值(对英文效果) 二:时间格式实战案例 1.时 ...
- 实现 .Net 7 下的数据库定时检查
在软件开发过程中,有时候我们需要定时地检查数据库中的数据,并在发现新增数据时触发一个动作.为了实现这个需求,我们在 .Net 7 下进行一次简单的演示. PeriodicTimer .Net 6 中新 ...
- 微信小程序地区和location_id对应关系
点击查看代码 location_list = [ {'location_id': '101010100', 'location_name': ['北京', '北京', '北京']}, {'locati ...
- 速记·python 123章
第一.二.三章 初识python 1.1 Python的概述 开发环境:Python 开发工具:IDLE(Python自带) 1.python的特点:代码简单.开发速度快.容易学习:有丰富的库:&qu ...
- Mapper的动态代理
可以自动生产接口的实现类 ,所以就不需要再写daoImpl这个实现类了, 直接使用sqlSession.getMapper自动生成实现类 @Before 此注解的目的是为了将@Befoe 作为首先执行 ...
- 青少年CTF-Web-Robots
题目信息 题目名称:Robots 题目描述:昨天十三年社团讲课,讲了Robots.txt的作用,小刚上课没有认真听课正在着急,你能不能帮帮忙? 题目难度:一颗星 解题过程 访问题目链接 浏览器里是空白 ...
- 【Redis 技术探索】「数据迁移实战」手把手教你如何实现在线 + 离线模式进行迁移Redis数据实战指南(离线同步数据)
离线迁移 与在线迁移相比,离线迁移适宜于源实例与目标实例的网络无法连通的场景,或者源端实例部署在其他云厂商Redis服务中,无法实现在线迁移. 存在的问题 由于生产环境的各种原因,我们需要对现有服务器 ...
- Redis 数据结构-双向链表
Redis 数据结构-双向链表 最是人间留不住,朱颜辞镜花辞树. 1.简介 Redis 之所以快主要得益于它的数据结构.操作内存数据库.单线程和多路 I/O 复用模型,进一步窥探下它常见的五种基本数据 ...
- Linux c 程序自动启动自己
在程序自动升级的时候需要自己重新启动自己 #include <stdio.h> #include <stdlib.h> #include <unistd.h> in ...
- 拜占庭将军问题与CAP
1.拜占庭将军问题 拜占庭位于如今的土耳其的伊斯坦布尔,是东罗马帝国的首都.由于当时拜占庭罗马帝国国土辽阔,为了达到防御目的,每个军队都分隔很远,将军与将军之间只能靠信差传消息.在战争的时候,拜占庭军 ...