Hadoop(一)Hadoop核心架构与安装
Hadoop是什么
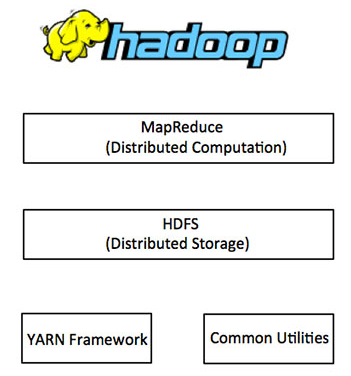
大白话,Hadoop是个存储数据,计算数据的分布式框架。核心组件是HDFS、MapReduce、Yarn。
HDFS:分布式存储
MapReduce:分布式计算
Yarn:调度MapReduce
现在为止我们知道了HDFS、MapReduce、Yarn是干啥的,下面通过一张图再来看看他的整体架构。
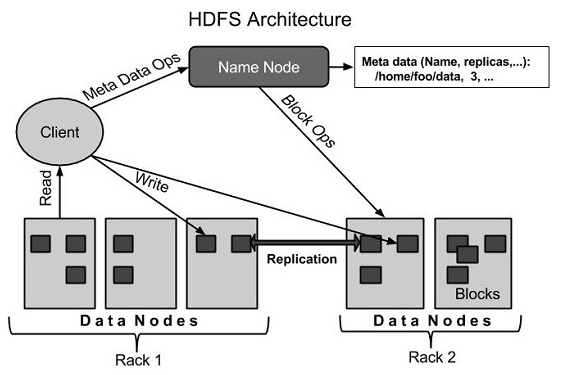
HDFS
HDFS是Hadoop的存储系统,将庞大的数据存储在多台机器上,并通过数据副本冗余实现容错。HDFS两大核心组件是NameNode与DataNode。
NameNode:管理文件命名空间元数据;实现文件命名、打开关闭操作
SecondaryNameNode:帮助NameNode实现log与数据快照的合并
DataNode:根据客户请求实现文件的读写
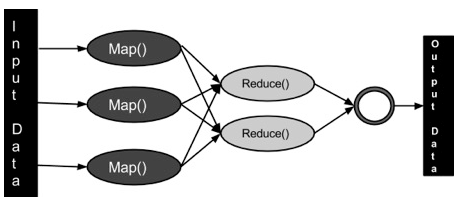
MapReduce
MapReduce是基于Java开发的分布式计算。包含重要的两部分,Map和Reduce。
Map:将数据转成键值对
Reduce:将Map的输出数据聚合减少
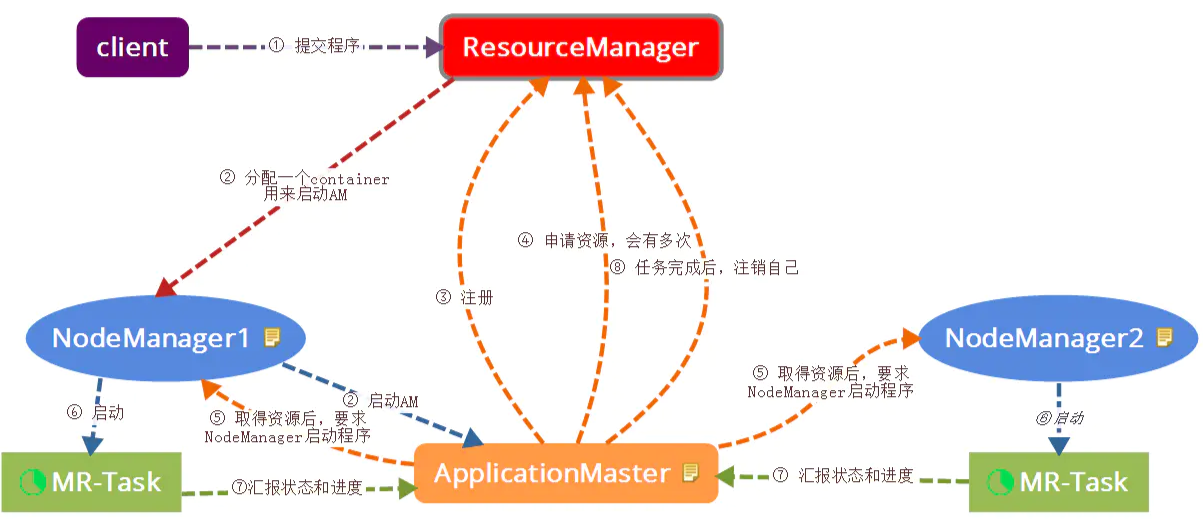
Yarn
通过对集群资源的监控,调度MapReduce的任务。核心组件有ResourceManager、NodeManager、ApplicationMaster 和 Container。
ResourceManager:处理客户端请求;监控NodeManager与ApplicationMaster;调度资源。
NodeManager:管理节点资源;与ResourceManager ApplicationMaster交互。
ApplicationMaster:为程序申请资源并将资源分配给任务;任务监控。
安装Hadoop
1.安装Jdk
下载https://www.oracle.com/java/technologies/downloads/
解压
tar -zxvf jdk-8u331-linux-x64.tar.gz
加入环境变量
vi /etc/profile #加入以下内容
JAVA_HOME=/usr/local/java18/jdk1.8.0_331
JRE_HOME=$JAVA_HOME/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME PATH CLASSPATH //生效
source /etc/profile
验证java
2.安装伪分布式Hadoop
下载https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
解压
tar xzf hadoop-3.2.3.tar.gz
配置本机ssh
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
配置Hadoop环境变量
cat etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8
配置hdfs地址
cat etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
配置hafs分片数
cat etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.2.3
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar //生效
source /etc/profile
配置mapreduce
vi etc/hadoop/mapred-site.xml <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
配置yarn
vi etc/hadoop/yarn-site.xml <configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
配置相关user
//将sbin/start-dfs.sh,sbin/stop-dfs.sh两个文件顶部添加以下参数 HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root //将sbin/start-yarn.sh,sbin/stop-yarn.sh顶部也需添加以下 YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
初始化hdfs
bin/hdfs namenode -format
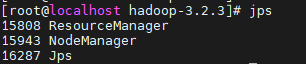
启动yarn
sbin/start-yarn.sh
通过jps查看启动的进程
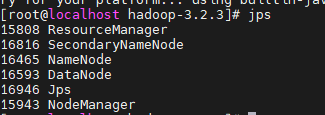
启动hdfs
sbin/start-dfs.sh
通过jps查看进程
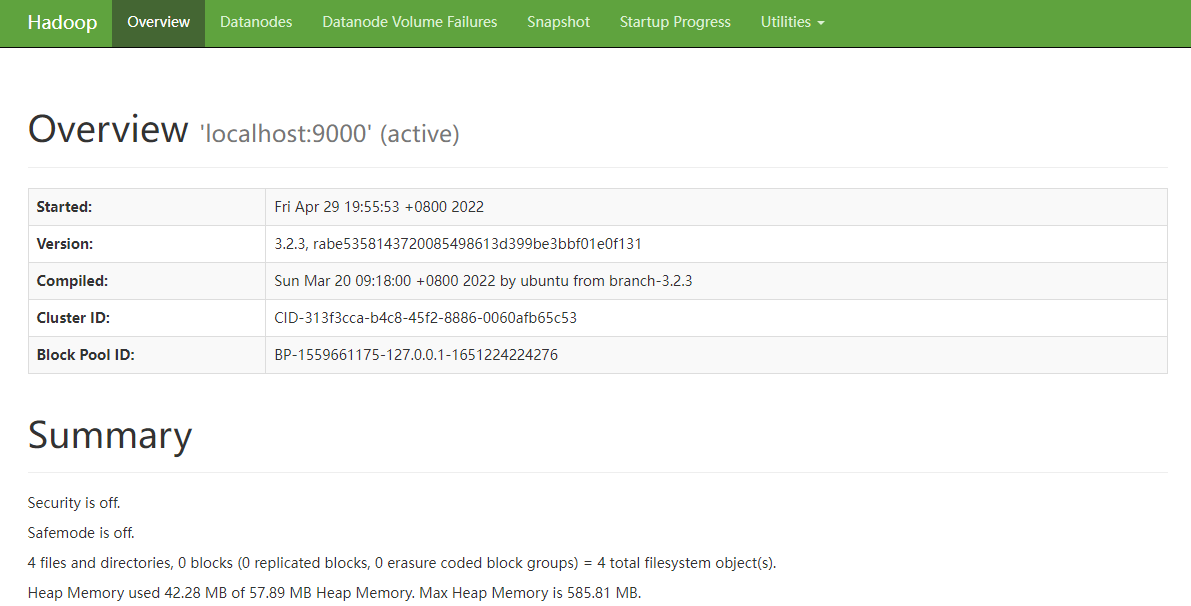
访问hadoopui验证安装是否成功
http://192.168.43.50:9870/dfshealth.html#tab-overview
访问集群ui
http://192.168.43.50:8088/cluster/cluster
Hadoop(一)Hadoop核心架构与安装的更多相关文章
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- Hadoop 核心架构
Hadoop 由许多元素构成.其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件.HDFS(对于本文)的上一层是Ma ...
- Hadoop核心架构(1)
在大数据的发展过程中,出现了一批专门应用与大数据的处理分析工具,如Hadoop,Hbase,Hive,Spark等,我们先从最基础的Hadoop开始进行介绍 Hadoop是apache基金会下所开发的 ...
- Hadoop化繁为简(一)-从安装Linux到搭建集群环境
简介与环境准备 hadoop的核心是分布式文件系统HDFS以及批处理计算MapReduce.近年,随着大数据.云计算.物联网的兴起,也极大的吸引了我的兴趣,看了网上很多文章,感觉还是云里雾里,很多不必 ...
- 五十九.大数据、Hadoop 、 Hadoop安装与配置 、 HDFS
1.安装Hadoop 单机模式安装Hadoop 安装JAVA环境 设置环境变量,启动运行 1.1 环境准备 1)配置主机名为nn01,ip为192.168.1.21,配置yum源(系统源) 备 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- Hadoop分布式文件系统:架构和设计要点
原文:http://hadoop.apache.org/core/docs/current/hdfs_design.html 一.前提和设计目标 1.硬件错误是常态,而非异常情况, HDFS可能是有成 ...
随机推荐
- 简述synchronized和java.util.concurrent.locks.Lock的异同 ?
主要相同点:Lock能完成synchronized所实现的所有功能 主要不同点:Lock有比synchronized更精确的线程语义和更好的性能.synchronized会自动释放锁,而Lock一定要 ...
- 一个tomcat部署两个springboot服务时启动JMX报错
一.问题来源 今天在部署开发好的组件的时候,发现无法启动,检查启动日志,报如下错误: 2022-03-17T10:39:41.823+08:00 ERROR vediomanage.vediomana ...
- Java 中 interrupted 和 isInterrupted 方法的区别?
interrupt interrupt 方法用于中断线程.调用该方法的线程的状态为将被置为"中断"状态. 注意:线程中断仅仅是置线程的中断状态位,不会停止线程.需要用户自己去监 视 ...
- java-設計模式-生成器
生成器模式Bulider 使你能够分步骤创建复杂对象. 该模式允许你使用相同的创建代码生成不同类型和形式的对象. 将一个复杂对象的构造与它的表示分离,使同样的构建过程可以创建不同的表示. 将一个复杂的 ...
- MariaDB InnoDB基本介绍
InnoDB锁定模式 事务获取锁,以防止并发事务修改甚至读取某些行或行范围.这样做是为了确保并发写入操作不会冲突. 共享锁(S)和排他锁(X) 两种标准的行级锁是共享锁(S)和排他锁(X) 获取共享锁 ...
- 在虚拟机里面运行java程序
首先输入vi在里面写一个java程序 然后再查找jdk 复制jdk名字 然后安装jdk 安装完之后输入Javac加你创建的文件名 然后再输入Java 和文件名(这个不要加后缀)然后就打印出来了
- 速看,ElasticSearch如何处理空值
大家好,我是咔咔 不期速成,日拱一卒 在MySQL中,十分不建议大家给表的默认值设置为Null,这个后期咔咔也会单独出一期文章来说明这个事情. 但你进入一家新公司之前的业务中存在大量的字段默认值为Nu ...
- 对height 100%和inherit的总结
对height 100%和inherit的总结 欢迎大家来我的博客留言:https://sxq222.github.io/CSS%...博客主页:https://sxq222.github.io 正文 ...
- 【前端小技巧】利用border画三角形及梯形
border是围绕元素内容和内边距的一条或多条线,border 属性允许你规定元素边框的样式.宽度和颜色 值: border-width 粗细 none/hidden/solid/dashed/dot ...
- 《深入理解ES6》笔记—— Promise与异步编程(11)
为什么要异步编程 我们在写前端代码时,经常会对dom做事件处理操作,比如点击.激活焦点.失去焦点等:再比如我们用ajax请求数据,使用回调函数获取返回值.这些都属于异步编程. 也许你已经大概知道Jav ...