Spark项目应用-电子商务大数据分析总结
一. 数据采集(要求至少爬取三千条记录,时间跨度超过一星期)数据采集到本地文件内容
爬取详见:python爬取京东评论
爬取了将近20000条数据,156个商品种类,用时2个多小时,期间中断数次
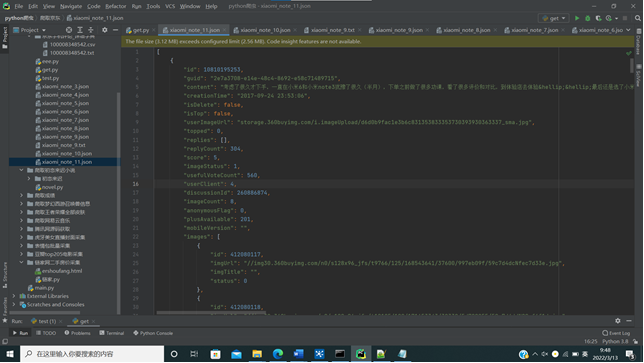
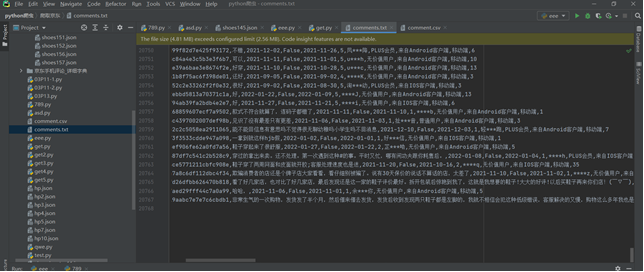
二、数据预处理:要求使用MapReduce或者kettle实现源数据的预处理,对大量的Json文件,进行清洗,以得到结构化的文本文件
在解析json时,处理了一部分,包括日期格式修改,数据格式转换等,在kettle中做去重、排序处理
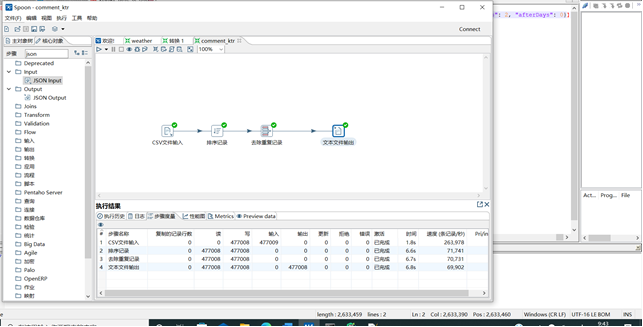
三.数据统计:生成Hive用户评论数据
(1)在Hive创建一张表,用于存放清洗后的数据,表名为pinglun,(创建数据表SQL语句),创建成功导入数据截图:
使用presto查询,速度比hive快好几倍
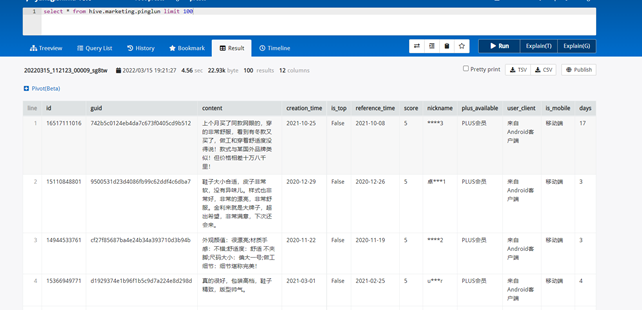
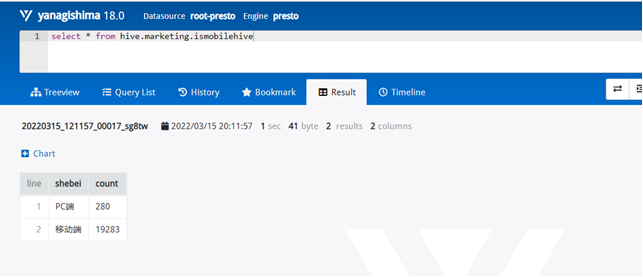
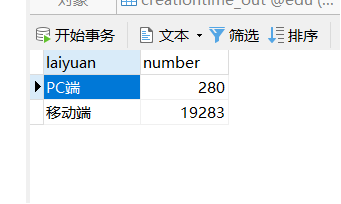
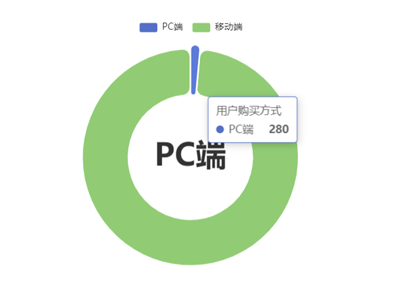
需求1:分析用户使用移动端购买还是PC端购买,及移动端和PC端的用户比例,生成ismobilehive表,存储统计结果;
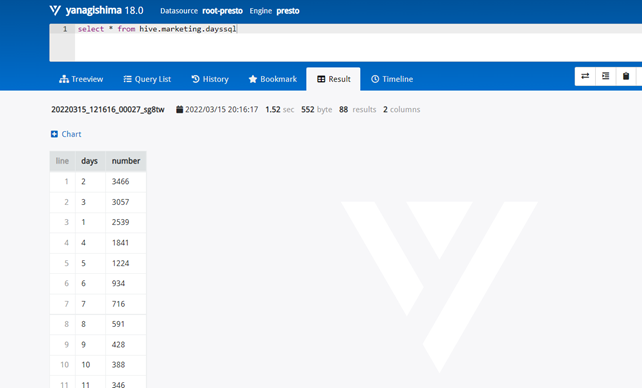
需求2:分析用户评论周期(收到货后,一般多久进行评论),生成dayssql表,存储统计结果;
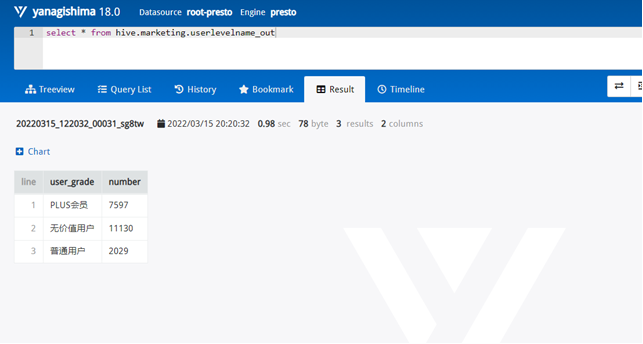
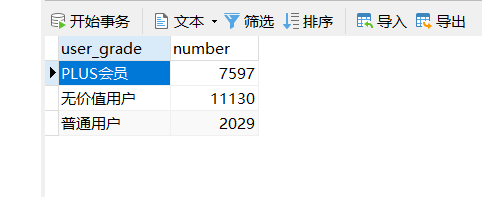
需求3:分析会员级别(判断购买此商品的用户级别),生成userlevelname_out表,存储统计结果;
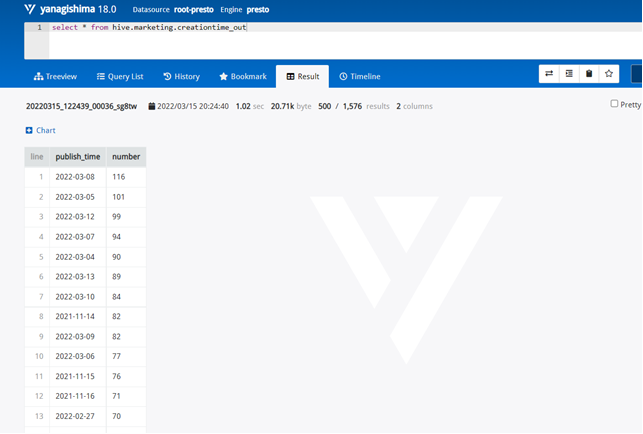
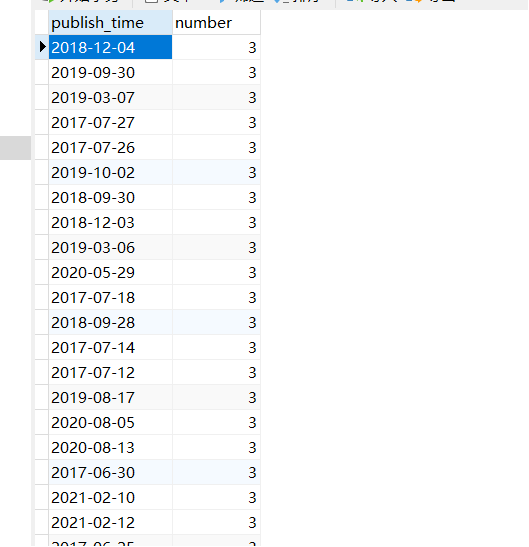
需求4:分析每天评论量,生成creationtime_out表,存储统计结果;
四.利用Sqoop进行数据迁移至Mysql数据库:
四个表导入mysql数据库中四个表截图

五.数据可视化:利用JavaWeb+Echarts完成数据图表展示过程
需求1:可视化展示截图
需求2:可视化展示截图
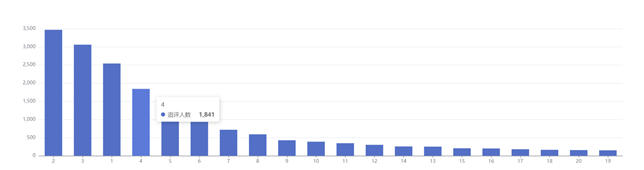
需求3:可视化展示截图
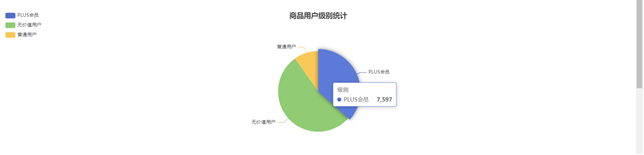
需求4:可视化展示截图
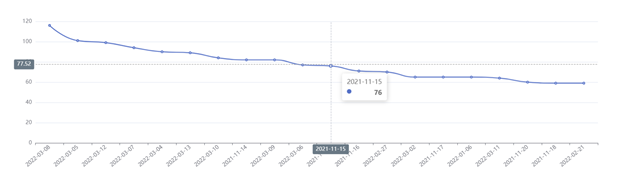
六.中文分词实现用户评价分析
(1)本节通过对商品评论表中的差评数据,进行分析,筛选用户差评点,以知己知彼。(筛选差评数据集截图)
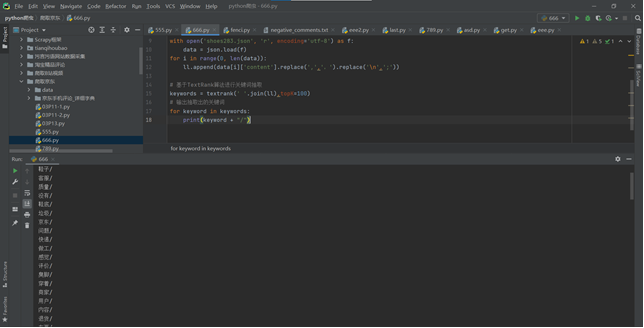
基于TextRank算法进行关键词抽取
import json import jieba
from jieba import analyse ll =[]
# 引入TextRank关键词抽取接口
textrank = analyse.textrank
with open('shoes283.json', 'r', encoding='utf-8') as f:
data = json.load(f)
for i in range(0, len(data)):
ll.append(data[i]['content'].replace(',',',').replace('\n',';')) # 基于TextRank算法进行关键词抽取
keywords = textrank(' '.join(ll),topK=100)
# 输出抽取出的关键词
for keyword in keywords:
print(keyword + "/")
(2)利用 python 结巴分词实现用户评价信息中的中文分词及词频统计;(分词后截图)
主要利用jieba去除标点符号,停用词,单个字符等等
import csv
import json
import re import jieba ll =[]
def regex_change(line):
# 前缀的正则
username_regex = re.compile(r"^\d+::")
# URL,为了防止对中文的过滤,所以使用[a-zA-Z0-9]而不是\w
url_regex = re.compile(r"""
(https?://)?
([a-zA-Z0-9]+)
(\.[a-zA-Z0-9]+)
(\.[a-zA-Z0-9]+)*
(/[a-zA-Z0-9]+)*
""", re.VERBOSE | re.IGNORECASE)
# 剔除日期
data_regex = re.compile(u""" #utf-8编码
年 |
月 |
日 |
(周一) |
(周二) |
(周三) |
(周四) |
(周五) |
(周六)
""", re.VERBOSE)
# 剔除所有数字
decimal_regex = re.compile(r"[^a-zA-Z]\d+")
# 剔除空格
space_regex = re.compile(r"\s+")
regEx = "[\n”“|,,;;''/?! 。的了是]" # 去除字符串中的换行符、中文冒号、|,需要去除什么字符就在里面写什么字符
line = re.sub(regEx, "", line)
line = username_regex.sub(r"", line)
line = url_regex.sub(r"", line)
line = data_regex.sub(r"", line)
line = decimal_regex.sub(r"", line)
line = space_regex.sub(r"", line) return line with open('data/shoes156.json', 'r', encoding='utf-8') as f:
data = json.load(f) for i in range(0, len(data)):
ll.append(data[i]['content'].replace(',',',').replace('\n',';')) words = jieba.lcut(regex_change(' '.join(ll))) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数 for word in words:
if word in "|,,;;''/?! 。::" or len(word) == 1: # 单个词语不计算在内
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1 items = list(counts.items()) # 将键值对转换成列表
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序 a =[]
b = []
for i in range(0,len(items)):
#word, count = items[i]
#b.append([list(items[i])[0],list(items[i])[1]])
print([list(items[i])[0],list(items[i])[1]])
with open("comments_jieba.txt", "a+", encoding='utf-8',newline='') as file: # 处理csv读写时不同换行符 linux:\n windows:\r\n mac:\r
csv_file = csv.writer(file)
csv_file.writerow([list(items[i])[0],list(items[i])[1]])
(3)在 hive 中新建词频统计表并加载分词数据;
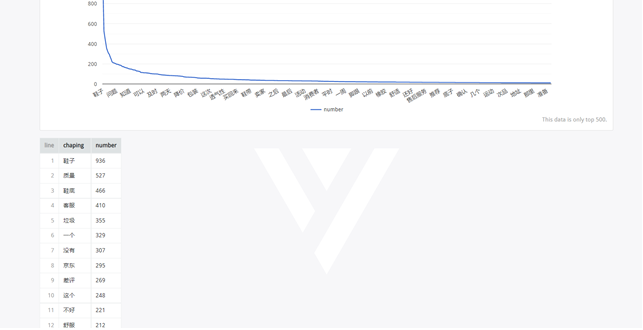
①柱状图可视化展示用户差评的统计前十类

②用词云图可视化展示用户差评分词

七.利用Spark进行实时数据分析
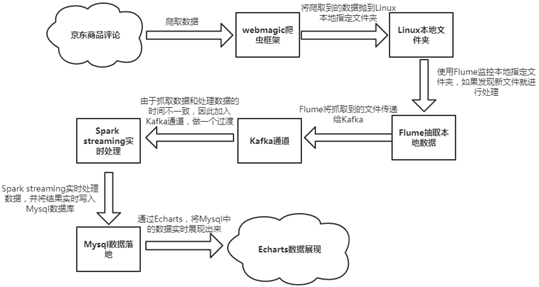
本实验以京东商品评论为目标网站,架构采用爬虫+Flume+Kafka+Spark Streaming+Mysql,实现数据动态实时的采集、分析、展示数据。
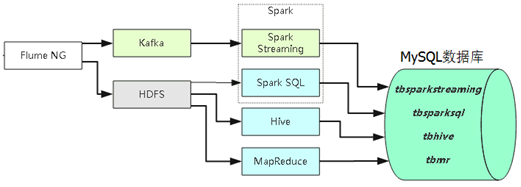
具体工作流程如下图:
操作步骤截图
1.启动flume
flume配置文件
pro.sources = s1
pro.channels = c1
pro.sinks = k1 pro.sources.s1.type = exec
pro.sources.s1.command = tail -F /opt/a.log #日志文件 pro.channels.c1.type = memory
pro.channels.c1.capacity = 1000
pro.channels.c1.transactionCapacity = 100 pro.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
pro.sinks.k1.kafka.topic = ct #需要启动这个topic
pro.sinks.k1.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
pro.sinks.k1.kafka.flumeBatchSize = 20
pro.sinks.k1.kafka.producer.acks = 1
pro.sinks.k1.kafka.producer.linger.ms = 1
pro.sinks.k1.kafka.producer.compression.type = snappy pro.sources.s1.channels = c1
pro.sinks.k1.channel = c1
启动:
bin/flume-ng agent --conf-file flume-kafka.conf --name pro -Dflume.root.logger=INFO,LOGFILE
2.启动kafka
#查看topic信息
/export/server/kafka/bin/kafka-topics.sh --list --zookeeper node1:2181 #删除topic
/export/server/kafka/bin/kafka-topics.sh --delete --zookeeper node1:2181 --topic edu #创建topic
/export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic ct #模拟消费者
/export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic ct --from-beginning
3.编写爬虫向日志文件传输数据
代码:
# -*- coding: utf-8 -*-
import gzip
import urllib.request
import json
import time
import random
import demjson as dj
import requests
import itertools headers = {
"Cookie": "__jdu=1507876332; shshshfpa=2ea021ee-52dd-c54e-1be1-f5aa9e333af2-1640075639; areaId=5; PCSYCityID=CN_0_0_0; shshshfpb=n7UymiTWOsGPvQfCup%2B3J1g%3D%3D; ipLoc-djd=5-142-42547-54561; jwotest_product=99; pinId=S4TjgVP4kjjnul02leqp07V9-x-f3wj7; pin=jd_60a1ab2940be3; unick=jd_60a1ab2940be3; ceshi3.com=000; _tp=672TNfWmOtaDFuqCPQqYycXMpi6F%2BRiwrhIuumNmoJ4%3D; _pst=jd_60a1ab2940be3; __jdc=122270672; shshshfp=4e8d45f57897e469586da47a0016f20e; ip_cityCode=142; CCC_SE=ADC_rzqTR2%2bUDTtHDYjJdX25PEGvHsBpPY%2bC9pRDVdNK7pU%2fwikRihpN3XEXZ1cn4Jd4w5OWdpJuduhBFwUvdeB6X1VFb7eIZkqL0OJvBn9RB6AJYo4An%2fGTiU%2b8rvqQwYxBI4QCM8a9w9kYQczygSjPxPjn1pbQLtBgo%2fzKBhwfKhAWs563NfBjmnRlkGHPX6E7jy6%2fEdfEhtkNSTCQod238cEpUFpKiQ%2bWV%2bW8MiaL3ti7d7ozdlNbZ03ylqRbI1XrXylDiqzW%2b2uALhF5H1eHuk3yH3t4ojXZmRbDy3k2OoZFk%2bcmrXD0eWhcIaD5RnhHbToYLuX%2byx7otaPuemTVAG4Z7CSyEfmUBAj7QuGmHg647a7KuoaR3hoCvxj%2f3woXdd2H9b40oqmJ5PO958Z1g%2fr7Jbk8a5w2CU547IaXRzakehLhW9xzG57Ak0Jhv85Jlt9A5N6hl%2ft4DSAwh%2bGhwg%3d%3d; unpl=JF8EAJJnNSttDBxWAxxSEkUVQg4EW1QKTx9TazcCAV8KSFICE1FIF0N7XlVdXhRKFR9vYhRUW1NPVA4ZBysSEXteVV1YCE0TAGlnNWRtW0tkBCsCHxMWQltTXF8LeycDZ2M1VFxZSlYGHQEbEBBCbWRbXQlKFQBpYQVQbVl7VTVZbEJTDBkCBxNdDEoRCmlgB1ZeaEpkBg; JSESSIONID=347F847A6818E35675648739BD4BA9FF.s1; __jda=122270672.1507876332.1640075637.1647251498.1647261295.13; thor=8D225D1673AA75681B9D3811417B0D325568BB2DD7F2729798D3AECF0428F59F7C70EA7504347F8E059F895AEE7D6E2662F565665845F0D94F2D7D56739CF3BC2B15F5F6E2ADDB891DDA80A9E9F88B7BA0BA95147512F78D28D8095E52379AB78550E451558DB6595C2270A1D5CFA2E211FF20F22ADA1987C6AE9E864DA6A7364D5BFD3EE08DA597D2EF2B37444CFD7A47134EFFD71B3A70B0C8BD55D51F274F; token=397b2c7c58f4021bbe9a9bbe9eeda694,3,915145; __tk=46fbcc7e51f75824dcdc2e8820904365,3,915145; shshshsID=5c5095f0b5728a839c0397308d625da5_1_1647261360535; __jdb=122270672.2.1507876332|13.1647261295; __jdv=122270672|jd.idey.cn|t_2024175271_|tuiguang|ef376a8f48ba48359a5a6d3c2769bb4b|1647261360584; 3AB9D23F7A4B3C9B=24HI5ARAA3SK7RJERTWUDZKA2NYJIXX3ING24VG466VC3ANKUALJLLD7VBYLQ3QPRYUSO3R6QBJYLVTVXBDIGJLGBA",
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Connection": "keep-alive",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39"
}
headers2 = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cookie": "__jdu=1507876332; shshshfpa=2ea021ee-52dd-c54e-1be1-f5aa9e333af2-1640075639; areaId=5; PCSYCityID=CN_0_0_0; ipLoc-djd=5-142-42547-54561; pinId=S4TjgVP4kjjnul02leqp07V9-x-f3wj7; pin=jd_60a1ab2940be3; unick=jd_60a1ab2940be3; _tp=672TNfWmOtaDFuqCPQqYycXMpi6F%2BRiwrhIuumNmoJ4%3D; _pst=jd_60a1ab2940be3; user-key=a2aaf011-2c1e-4dea-bf76-3392d16b1fb1; __jdc=122270672; wlfstk_smdl=jlwwba2gmccq62touff9evvbp3fk8gbr; ceshi3.com=000; shshshfp=4e8d45f57897e469586da47a0016f20e; ip_cityCode=142; shshshfpb=n7UymiTWOsGPvQfCup%2B3J1g%3D%3D; joyya=1647305570.1647305909.27.0kop377; __jda=122270672.1507876332.1640075637.1647314039.1647318046.22; token=d5899471c4530886f6a9658cbea3ca94,3,915176; __tk=1570759a7dd1a720b0db2dec5df8d044,3,915176; CCC_SE=ADC_Wj0UWzuXioxsiUvbIxw9PbW9q011vNMASHkfjXFO%2fZlkeGDtZUHe5qgaEpWv8RDEkCruGSGmCItsvHjIZ3aHbh9heUjNIZh6WZl9ZDfDokk66kRX6I%2by%2bDsdf4JtPOQUuULSsWOA%2fcDyP7Bb91YuHOwNnciLtS97UIKO7XA5sAd34Rf4XDKijy6Fw1DFTx%2b7izzme6YALuLp9Y%2bByC6aUTDzU9te7g1BZXPXtfGGwqu52ZVkdVId2jpxPnhX24fFD9WI9aX1qgswZ1PPZSGYKswUkqXhIf2S9aLFkjXW2n61LVzw2ZeqJRQI8QIcmi%2fF7WHOHLbWScnKwG594WIk0SRiCa0n2aEJAhVlXmzEE%2f5%2f%2bXWsKhlneTLduVs52ST5m96zdx%2bLnNGgDERqznFNu3AT5zvLcN0PyVq08n4keSv2ngLLTZK4QQJslS4he9MT3XJoEUfe9L8beZNh1239eLHYF6w4KWMCWWTfwxdCUOY%3d; unpl=JF8EAJZnNSttDEhSAkwDE0dEGAoEWw8LSh9TbjRVXV5QHFIDGwMfGhd7XlVdXhRKFR9vYxRUXlNIUw4ZBysSEXteVV1YCE0TAGlnNWRtW0tkBCsCHxMWQltTXF8LeycDZ2M1VFxZSlYGGwcTEhhObWRbXQlKFQBpYQVQbVl7VTVNbBsTEUpcVVteDENaA2tmA11bX0lWBisDKxE; __jdv=122270672|jd.idey.cn|t_2024175271_|tuiguang|e276f09debfa4c209a0ba829f7710596|1647318395561; thor=8D225D1673AA75681B9D3811417B0D325568BB2DD7F2729798D3AECF0428F59F4C39726C44E930AA2DD868FC4BCA33EA0D52228F39A68FC9F5C1157433CAACF1110B20B6975502864453B70E6B21C0ED165B733359002643CD05BDBA37E4A673AF38CC827B6013BCB5961ADA022E57DB6811E99E10E9C4E6410D844CD129071F7646EC7CE120A0B3D2F768020B044A010452D9F8ABD67A59D41880DD1991935C; 3AB9D23F7A4B3C9B=24HI5ARAA3SK7RJERTWUDZKA2NYJIXX3ING24VG466VC3ANKUALJLLD7VBYLQ3QPRYUSO3R6QBJYLVTVXBDIGJLGBA; __jdb=122270672.5.1507876332|22.1647318046; shshshsID=d7a96097b296c895558adfd840546a72_5_1647318650562",
"referer": "https://search.jd.com/"
}
def crawlProductComment(url):
# 读取原始数据(注意选择gbk编码方式)
try:
req = requests.get(url=url, headers=headers2).text
reqs = req.replace("fetchJSON_comment98(", "").strip(');')
print(reqs)
jsondata = json.loads(reqs)
# 遍历商品评论列表
comments = jsondata['comments']
return comments
except IOError:
print("Error: gbk不合适")
# 从原始数据中提取出JSON格式数据(分别以'{'和'}'作为开始和结束标志) def getProduct(url):
ids = []
req = requests.get(url=url, headers=headers2).text
reqs = req.replace("jQuery1544821(", "").strip(')')
jsondata = json.loads(reqs)['291']
for i in range(0, len(jsondata)):
ids.append(jsondata[i]['sku_id'])
print(ids)
return ids import paramiko #服务器信息,主机名(IP地址)、端口号、用户名及密码
hostname = "node1"
port = 22
username = "root"
password = "123456" client = paramiko.SSHClient()
client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
client.connect(hostname, port, username, password, compress=True)
sftp_client = client.open_sftp()
remote_file = sftp_client.open("/opt/a.log",'a+') # 文件路径
ids = []
for i in range(2,3):
product_id = getProduct(
"https://search-x.jd.com/Search?callback=jQuery1544821&area=5&enc=utf-8&keyword=%E7%94%B7%E5%A3%AB%E8%BF%90%E5%8A%A8%E9%9E%8B&adType=7&page="+str(i)+"&ad_ids=291%3A33&xtest=new_search&_=1647325621019")
time.sleep(random.randint(1, 3))
ids.append(product_id) data = []
count = 0
for k in list(set(itertools.chain.from_iterable(ids))):
for i in range(0, 100):
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=' + str(
k) + '&score=0&sortType=5&page=' \
+ str(i) + '&pageSize=10&isShadowSku=0&fold=1'
comments = crawlProductComment(url)
if len(comments) <= 0:
break
print(comments)
remote_file.writelines(str(len(comments))+"\n")
data.extend(comments)
# 设置休眠时间
time.sleep(random.randint(1, 5))
print('-------', i) print("这是第{}类商品".format(count))
count += 1
kafka接收到数据并显示出来
4.sparkstreaming接收kafka数据并保存至mysql,动态存储
代码:
package cn.itcast.edu.analysis.streaming import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext} import java.sql.{Connection, DriverManager}
import java.text.SimpleDateFormat
import java.util.Date /**
* Author itcast
* Desc Direct模式连接Kafka消费数据
*/
object Streaming {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//the time interval at which streaming data will be divided into batches
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))//每隔5s划分一个批次
ssc.checkpoint("./ckp") //TODO 1.加载数据-从Kafka
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1:9092",//kafka集群地址
"key.deserializer" -> classOf[StringDeserializer],//key的反序列化规则
"value.deserializer" -> classOf[StringDeserializer],//value的反序列化规则
"group.id" -> "ct",//消费者组名称
//earliest:表示如果有offset记录从offset记录开始消费,如果没有从最早的消息开始消费
//latest:表示如果有offset记录从offset记录开始消费,如果没有从最后/最新的消息开始消费
//none:表示如果有offset记录从offset记录开始消费,如果没有就报错
"auto.offset.reset" -> "latest",
"auto.commit.interval.ms"->"5000",//自动提交的时间间隔
"enable.auto.commit" -> (true: java.lang.Boolean)//是否自动提交
)
val topics = Array("ct")//要订阅的主题
//使用工具类从Kafka中消费消息
val kafkaDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent, //位置策略,使用源码中推荐的
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams) //消费策略,使用源码中推荐的
) //TODO 2.处理消息
val infoDS: DStream[Int] = kafkaDS.map(record => {
val nowDate = new Date()
val strDate: String = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(nowDate)
val value: String = record.value()
Class.forName("com.mysql.jdbc.Driver")
//获取mysql连接
val conn: Connection = DriverManager.getConnection("jdbc:mysql://node3:3306/edu?useUnicode=true&characterEncoding=utf-8", "root", "123456")
//把数据写入mysql
try {
val sql: String = "insert into spider(spider_time,number)values('" + strDate + "','" + value.toInt + "')"
conn.prepareStatement(sql).executeUpdate()
} finally {
conn.close()
}
value.toInt
})
//TODO 3.输出结果
infoDS.print()
//TODO 4.启动并等待结束
ssc.start()
ssc.awaitTermination()//注意:流式应用程序启动之后需要一直运行等待手动停止/等待数据到来 //TODO 5.关闭资源
ssc.stop(stopSparkContext = true, stopGracefully = true)//优雅关闭 }
}
pom.xml配置
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>cn.itcast</groupId>
<artifactId>dataproject</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>war</packaging> <name>dataproject Maven Webapp</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<scala.version>2.12.11</scala.version>
<spark.version>3.0.3</spark.version>
<hadoop.version>3.1.4</hadoop.version>
</properties> <repositories>
<repository>
<id>aliyun</id>
<url>https://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>apache</id>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!--依赖Scala语言-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency> <!--SparkCore依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency> <!-- spark-streaming-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
</dependency> <!--spark-streaming+Kafka依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency> <!--SparkSQL依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency> <!--SparkSQL+ Hive依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_2.12</artifactId>
<version>${spark.version}</version>
</dependency> <!--StructuredStreaming+Kafka依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency> <!-- SparkMlLib机器学习模块,里面有ALS推荐算法-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>${spark.version}</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency> <dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency> <dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency> <dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency> <dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.3</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.2</version>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<!-- 指定编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
5.可视化展示
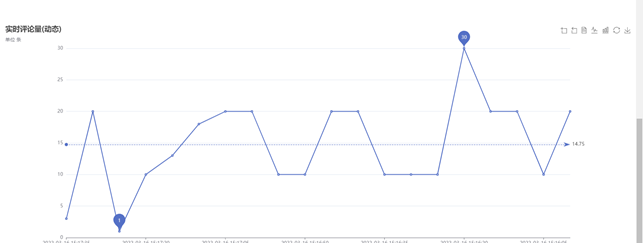
动态显示爬取的评论数量,每5秒更新图像,这里就不展示了
Spark项目应用-电子商务大数据分析总结的更多相关文章
- SPARK快学大数据分析概要
Spark 是一个用来实现快速而通用的集群计算的平台.在速度方面,Spark 扩展了广泛使用的MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理.在处理大规模数据集时,速 ...
- [spark 快速大数据分析读书笔记] 第一章 导论
[序言] Spark 基于内存的基本类型 (primitive)为一些应用程序带来了 100 倍的性能提升.Spark 允许用户程序将数据加载到 集群内存中用于反复查询,非常适用于大数据和机器学习. ...
- Python3实战Spark大数据分析及调度 (网盘分享)
Python3实战Spark大数据分析及调度 搜索QQ号直接加群获取其它学习资料:715301384 部分课程截图: 链接:https://pan.baidu.com/s/12VDmdhN4hr7yp ...
- Apache Spark大数据分析入门(一)
摘要:Apache Spark的出现让普通人也具备了大数据及实时数据分析能力.鉴于此,本文通过动手实战操作演示带领大家快速地入门学习Spark.本文是Apache Spark入门系列教程(共四部分)的 ...
- HDFS+ClickHouse+Spark:从0到1实现一款轻量级大数据分析系统
在产品精细化运营时代,经常会遇到产品增长问题:比如指标涨跌原因分析.版本迭代效果分析.运营活动效果分析等.这一类分析问题高频且具有较高时效性要求,然而在人力资源紧张情况,传统的数据分析模式难以满足.本 ...
- discuz论坛apache日志hadoop大数据分析项目:清洗数据核心功能解说及代码实现
discuz论坛apache日志hadoop大数据分析项目:清洗数据核心功能解说及代码实现http://www.aboutyun.com/thread-8637-1-1.html(出处: about云 ...
- Spark项目之电商用户行为分析大数据平台之(一)项目介绍
一.项目概述 本项目主要用于互联网电商企业中,使用Spark技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.购物行为.广告点击行为等)进行复杂的分析.用统计分析出来的数据,辅助公司中 ...
- 大数据分析处理框架——离线分析(hive,pig,spark)、近似实时分析(Impala)和实时分析(storm、spark streaming)
大数据分析处理架构图 数据源: 除该种方法之外,还可以分为离线数据.近似实时数据和实时数据.按照图中的分类其实就是说明了数据存储的结构,而特别要说的是流数据,它的核心就是数据的连续性和快速分析性: 计 ...
- Python3实战spark大数据分析及调度 ☝☝☝
Python3实战spark大数据分析及调度 ☝☝☝ 一.实例分析 1.1 数据 student.txt 1.2 代码 二.代码解析 2.1函数解析 2.1.1 collect() RDD的特性 在 ...
随机推荐
- Django中的Session和cookie
Session和cookie 参考文献:https://www.cnblogs.com/wupeiqi/articles/5246483.html 1.问题引入 1.1 cookie是什么? 保存在客 ...
- Objective-C 基础教程第六章,源文件组织
目录 Object-C 基础教程第六章,源文件组织 0x00:前言 0x01:Xcode创建OC类 0x02:Xcode群组 0x03 Xcode跨文件依赖关系 @class关键字 导入和继承 小结 ...
- 使用windows自带linux子系统开发esp32
步骤: 1.打开windows商店,搜索ubuntu,安装18.04版本. 2.控制面板 /程序和功能 /打开或关闭windows功能 3.关机重启 4.打开刚安装得ubuntu,设置用户名和密码. ...
- C#控制打印机打印
一.引用BarcodeStandard.dll #region BarcodeStandard.dll /* * * 使用说明 需要通过NuGet进行安装BarcodeLib.dll,必不可少 */ ...
- QQ音乐官方定制精简版v1.3.6 纯净无广告
介绍 近期腾讯推出了QQ音乐简洁版.顾名思义,QQ音乐简洁版就是官方精简后的版本,没有内置任何广告.完全专注于听歌,不存在直播.K歌.短视频等花里胡哨的内容.如有违规,请删删.. 结尾附pc端 QQ音 ...
- 矩池云上如何快速安装nvcc
若您想要使用 nvcc,但是所选的镜像中没有预装 nvcc,可按照如下操作自行安装. 1.检查系统版本 source /etc/os-release && echo $VERSION_ ...
- PHP-制作验证码
<?php //11>设置session,必须处于脚本最顶部 session_start(); $image = imagecreatetruecolor(100, 30); //1> ...
- tensorflow源码解析之framework-function
目录 什么是function FunctionDef 函数相关类 关系图 涉及的文件 迭代记录 1. 什么是function 在讲解function的概念之前,我们要先回顾下op.op是规定了输入和输 ...
- LGCF235B题解
简单期望/fad 题意明确,不说了. 对于高次期望,一个套路的方法是维护低次期望(?) 考虑 dp,设 \(dp1[i]\) 为前 \(i\) 次点击中 所有连续的 \(O\) 的长度之和,\(dp2 ...
- LintCode 练习题
/** * 给定一个链表,旋转链表,将链表每个节点向右移动 k 个位置,其中 k 是非负数. 示例 1: 输入: 1->2->3->4->5->NULL, k = 2 输 ...