kafka消费组创建和删除原理
0.10.0.0版本的kafka的消费者和消费组已经不在zk上注册节点了,那么消费组是以什么形式存在的呢?
1 入口
看下kafka自带的脚本kafka-consumer-groups.sh,可见脚本调用了kafka.admin.ConsumerGroupCommand
exec $(dirname $0)/kafka-run-class.sh kafka.admin.ConsumerGroupCommand "$@"
看下ConsumerGroupCommand,从代码中可以看出新版本的kafka不支持删除消费组操作,实际上,当消费组内消费者为空的时候消费组就会被删除。
def main(args: Array[String]) {
// ...
val consumerGroupService = {
if (opts.options.has(opts.newConsumerOpt)) new KafkaConsumerGroupService(opts) // 对于新版本kafka来说调用的是KafkaConsumerGroupService
else new ZkConsumerGroupService(opts)
}
try {
if (opts.options.has(opts.listOpt))
consumerGroupService.list() // 以此为例来看下消费组存在的形式
else if (opts.options.has(opts.describeOpt))
consumerGroupService.describe()
else if (opts.options.has(opts.deleteOpt)) {
consumerGroupService match {
case service: ZkConsumerGroupService => service.delete()
case _ => throw new IllegalStateException(s"delete is not supported for $consumerGroupService")
}
}
}
// ...
}
我们以KafkaConsumerGroupService#list为例来看下消费组存在的形式。KafkaConsumerGroupService#list用于获取所有的消费组。沿着代码一直追溯可以看到其会调用AdminClient#listAllGroups。从代码中可以看出要想获取到所有消费组,就需要遍历每个broker。而要获取某个broker上的消费组则需要发送ApiKeys.LIST_GROUPS的请求。
def listAllGroups(): Map[Node, List[GroupOverview]] = {
findAllBrokers.map {
case broker =>
broker -> { // 需要遍历每个broker
try {
listGroups(broker)
} catch {
case e: Exception =>
debug(s"Failed to find groups from broker ${broker}", e)
List[GroupOverview]()
}
}
}.toMap
}
def listGroups(node: Node): List[GroupOverview] = { // 向相应broker发送请求来获取改broker上的消费组信息
val responseBody = send(node, ApiKeys.LIST_GROUPS, new ListGroupsRequest())
val response = new ListGroupsResponse(responseBody)
Errors.forCode(response.errorCode()).maybeThrow()
response.groups().map(group => GroupOverview(group.groupId(), group.protocolType())).toList
}
看下KafkaApis.scala对应的请求处理方法handleListGroupsRequest
def handleListGroupsRequest(request: RequestChannel.Request) {
// ...
val (error, groups) = coordinator.handleListGroups() // 关键,获取消费组列表
val allGroups = groups.map { group => new ListGroupsResponse.Group(group.groupId, group.protocolType) }
new ListGroupsResponse(error.code, allGroups.asJava)
}
requestChannel.sendResponse(new RequestChannel.Response(request, new ResponseSend(request.connectionId, responseHeader, responseBody)))
}
顺着coordinator.handleListGroups一直往下,可以看到最终是调用GroupMetadataManager#currentGroups来获取到broker上的消费组的。到这里我们可以看出,消费组和GroupMetadataManager有关。
def currentGroups(): Iterable[GroupMetadata] = groupsCache.values
2 存在形式
GroupMetadata表示一个消费组,MemberMetadata表示一个消费者。先放下总结的图
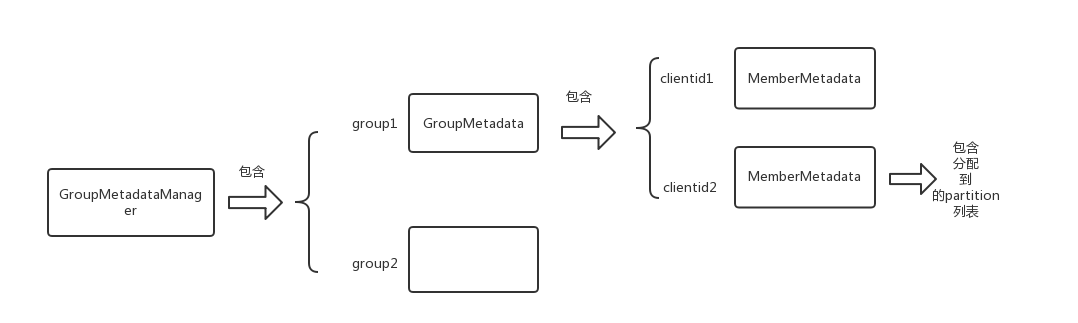
GroupMetadataManager有个groupsCache属性保存了该broker所管辖的消费组
private val groupsCache = new Pool[String, GroupMetadata]
看下GroupMetadata的内部属性
private[coordinator] class GroupMetadata(val groupId: String, val protocolType: String) {
private val members = new mutable.HashMap[String, MemberMetadata] // 消费组的客户端
private var state: GroupState = Stable
var generationId = 0 // generationId 用于reblance
var leaderId: String = null
var protocol: String = null
// ...
}
// MemberMetadata表示一个消费者
private[coordinator] class MemberMetadata(val memberId: String,
val groupId: String,
val clientId: String,
val clientHost: String,
val sessionTimeoutMs: Int,
var supportedProtocols: List[(String, Array[Byte])]) {
var assignment: Array[Byte] = Array.empty[Byte] // 消费者分配到的partiton
var awaitingJoinCallback: JoinGroupResult => Unit = null
var awaitingSyncCallback: (Array[Byte], Short) => Unit = null
var latestHeartbeat: Long = -1
var isLeaving: Boolean = false
// ...
}
以上就是消费组及其消费者的存在形式,即存在缓存变量中,而不是持久在其他什么地方
3 消费组的创建
消费组是不会单独创建的,消费组的创建是在消费者第一次发送join_group请求的时候创建的。创建消费组过程也很简单,就是在GroupMetadataManager#groupsCache加入代表该消费组的GroupMetadata
GroupCoordinator#handleJoinGroup
def handleJoinGroup(groupId: String,
memberId: String,
clientId: String,
clientHost: String,
sessionTimeoutMs: Int,
protocolType: String,
protocols: List[(String, Array[Byte])],
responseCallback: JoinCallback) {
// ...
} else {
var group = groupManager.getGroup(groupId)
if (group == null) {
if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID) {
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
} else {
group = groupManager.addGroup(new GroupMetadata(groupId, protocolType)) // 关键,如果group为空,则添加一个group
doJoinGroup(group, memberId, clientId, clientHost, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
} else {
doJoinGroup(group, memberId, clientId, clientHost, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
}
}
GroupMetadataManager#addGroup
def addGroup(group: GroupMetadata): GroupMetadata = {
val currentGroup = groupsCache.putIfNotExists(group.groupId, group) // 加入代表该消费组的GroupMetadata
if (currentGroup != null) {
currentGroup
} else {
group
}
}
4 消费组的删除
在第一节ConsumerGroupCommand中我们可以知道消费组是不支持手动删除的,那么消费组是怎么删除的呢,实际上当消费组中的消费者为空的时候,消费组就会被删除。
4.1 删除动作
看下GroupMetadataManager#removeGroup,我先看下删除消费组都有哪些动作
def removeGroup(group: GroupMetadata) {
if (groupsCache.remove(group.groupId, group)) { // 从cache中移除group
// 然后再__consumer_offsets主题中该group对应的partition写一个tombstone消息,用于压缩,这是因为__consumer_offsets不会删除,只会压缩
val groupPartition = partitionFor(group.groupId) // 计算group相关联分区,默认是abs(hashcode) % 50
val (magicValue, timestamp) = getMessageFormatVersionAndTimestamp(groupPartition)
// 然后将tombstone写入该partition,用于压缩
val tombstone = new Message(bytes = null, key = GroupMetadataManager.groupMetadataKey(group.groupId),
timestamp = timestamp, magicValue = magicValue)
val partitionOpt = replicaManager.getPartition(TopicConstants.GROUP_METADATA_TOPIC_NAME, groupPartition)
partitionOpt.foreach { partition =>
val appendPartition = TopicAndPartition(TopicConstants.GROUP_METADATA_TOPIC_NAME, groupPartition)
trace("Marking group %s as deleted.".format(group.groupId))
try {
partition.appendMessagesToLeader(new ByteBufferMessageSet(config.offsetsTopicCompressionCodec, tombstone))
} catch {
case t: Throwable =>
error("Failed to mark group %s as deleted in %s.".format(group.groupId, appendPartition), t)
// ignore and continue
}
}
}
}
由以上可以看出,删除消费组有两个动作
- 将cache,即(Pool[String, GroupMetadata])中的消费组移除
- 在__consumer_offsets中要删除消费组相关的partition中写入tombstone,而不会删除要删除消费组的相关记录
4.2 触发删除的动作
唯一调用GroupMetadataManager#removeGroup的地方是GroupCoordinator#onCompleteJoin,而调用GroupCoordinator#onCompleteJoin的唯一地方是DelayedJoin。
GroupCoordinator#onCompleteJoin
def onCompleteJoin(group: GroupMetadata) {
// ...
if (group.isEmpty) {
group.transitionTo(Dead) // 先将消费组置位dead状态,然后移除
groupManager.removeGroup(group)
info("Group %s generation %s is dead and removed".format(group.groupId, group.generationId))
}
}
// ...
}
GroupCoordinator#onCompleteJoin
private[coordinator] class DelayedJoin(coordinator: GroupCoordinator,
group: GroupMetadata,
sessionTimeout: Long)
extends DelayedOperation(sessionTimeout) {
override def tryComplete(): Boolean = coordinator.tryCompleteJoin(group, forceComplete)
override def onExpiration() = coordinator.onExpireJoin()
override def onComplete() = coordinator.onCompleteJoin(group)
}
难道是在joinGroup操作的时候删除消费组吗?其实并不是,而是在heartbeat超时的时候删除的,即当最后一个消费者心跳超时或者说消费组内没有了消费者的时候,该消费组就对被删除。从DelayedHeartbeat开始看下
private[coordinator] class DelayedHeartbeat(coordinator: GroupCoordinator,
group: GroupMetadata,
member: MemberMetadata,
heartbeatDeadline: Long,
sessionTimeout: Long)
extends DelayedOperation(sessionTimeout) {
override def tryComplete(): Boolean = coordinator.tryCompleteHeartbeat(group, member, heartbeatDeadline, forceComplete)
override def onExpiration() = coordinator.onExpireHeartbeat(group, member, heartbeatDeadline) // 关注这里
override def onComplete() = coordinator.onCompleteHeartbeat()
}
def onExpireHeartbeat(group: GroupMetadata, member: MemberMetadata, heartbeatDeadline: Long) {
group synchronized {
if (!shouldKeepMemberAlive(member, heartbeatDeadline))
onMemberFailure(group, member) // 关注这里
}
}
}
private def onMemberFailure(group: GroupMetadata, member: MemberMetadata) {
trace("Member %s in group %s has failed".format(member.memberId, group.groupId))
group.remove(member.memberId)
group.currentState match {
case Dead =>
case Stable | AwaitingSync => maybePrepareRebalance(group) // 假设消费组有一个消费者处于Stable状态,当该消费者超时后,就会调用maybePrepareRebalance
case PreparingRebalance => joinPurgatory.checkAndComplete(GroupKey(group.groupId))
}
}
private def maybePrepareRebalance(group: GroupMetadata) {
group synchronized {
if (group.canRebalance)
prepareRebalance(group) // 关注这里
}
}
private def prepareRebalance(group: GroupMetadata) {
if (group.is(AwaitingSync))
resetAndPropagateAssignmentError(group, Errors.REBALANCE_IN_PROGRESS.code)
group.transitionTo(PreparingRebalance)
info("Preparing to restabilize group %s with old generation %s".format(group.groupId, group.generationId))
val rebalanceTimeout = group.rebalanceTimeout
val delayedRebalance = new DelayedJoin(this, group, rebalanceTimeout) // 最终DelayedJoin在这里被调用
val groupKey = GroupKey(group.groupId)
joinPurgatory.tryCompleteElseWatch(delayedRebalance, Seq(groupKey))
}
由以上我们可以总结出,就是在heartbeat超时后会进行reblance操作,最终调用GroupCoordinator#prepareRebalance,这个时候如果消费组中members为空则会删除。
5 总结
- 消费组只存在一个Pool[String, GroupMetadata], 并没有持久化
- 当第一个消费者join请求来的时候,才会创建消费组,创建消费组即在Pool[String, GroupMetadata]加入代表该消费组的GroupMetadata
- 不能手动删除消费组,删除消费组的时机是当最后一个消费者离开的时候,会触发heartbeat超时从而reblance将消费组删除
- 消费组删除涉及两个动作,一个是将消费组从Pool[String, GroupMetadata]中移除,另一个是在__consumer_offsets中写入tombstone
- __consumer_offsets只会压缩不会删除
kafka消费组创建和删除原理的更多相关文章
- Kafka设计解析(十三)Kafka消费组(consumer group)
转载自 huxihx,原文链接 Kafka消费组(consumer group) 一直以来都想写一点关于kafka consumer的东西,特别是关于新版consumer的中文资料很少.最近Kafka ...
- Kafka Topic Partition Replica Assignment实现原理及资源隔离方案
本文共分为三个部分: Kafka Topic创建方式 Kafka Topic Partitions Assignment实现原理 Kafka资源隔离方案 1. Kafka Topic创建方式 ...
- Kafka消费分组和分区分配策略
Kafka消费分组,消息消费原理 同一个消费组里的消费者不能消费同一个分区,不同消费组的消费组可以消费同一个分区 Kafka分区分配策略 在 Kafka 内部存在两种默认的分区分配策略:Range 和 ...
- Kafka管理与监控——彻底删除topic
一.配置 server.properties 设置 delete.topic.enable=true 如果没有设置 delete.topic.enable=true,则调用kafka 的delete命 ...
- 涨姿势了解一下Kafka消费位移可好?
摘要:Kafka中的位移是个极其重要的概念,因为数据一致性.准确性是一个很重要的语义,我们都不希望消息重复消费或者丢失.而位移就是控制消费进度的大佬.本文就详细聊聊kafka消费位移的那些事,包括: ...
- RabbitMQ和Kafka的高可用集群原理
前言 小伙伴们,通过前边文章的阅读,相信大家已经对RocketMQ的基本原理有了一个比较深入的了解,那么大家对当前比较常用的RabbitMQ和Kafka是不是也有兴趣了解一些呢,了解的多一些也不是坏事 ...
- 软硬链接、文件删除原理、linux中的三种时间、chkconfig优化
第1章 软硬链接 1.1 硬链接 1.1.1 含义 多个文件拥有相同的inode号码 硬链接即文件的多个入口 1.1.2 作用 防止你误删除文件 1.1.3 如何创建硬链接 ln 命令,前面是源文件 ...
- kafka 消费
前置资料 kafka kafka消费中的问题及解决方法: 情况1: 问题:脚本读取kafka 数据,写入到数据库,有时候出现MySQL server has gone away,导致脚本死掉.再次启 ...
- 分享一些 Kafka 消费数据的小经验
前言 之前写过一篇<从源码分析如何优雅的使用 Kafka 生产者> ,有生产者自然也就有消费者. 建议对 Kakfa 还比较陌生的朋友可以先看看. 就我的使用经验来说,大部分情况都是处于数 ...
随机推荐
- python处理图像矩阵--值转为int
1. 在用python处理图像数字矩阵时,若对矩阵进行了加减乘除等运算,可能会造成矩阵元素值溢出,然后某些元素值可能都被赋为255:之后若重新显示图像,可能会没有什么变化,此时,可以将运算后的矩阵值转 ...
- 为什么用Python,高级的Python是一种高级编程语言
Python特性 如果有人问我Python最大的特点是什么,我会毫不犹豫地告诉他:它简单易学,功能强大.作为一个纯自由软件,Python有许多优点: 很简单.基于"优雅".&quo ...
- C语言do-while语句
"直到"型 (do-while) 语句的特点: 先执行循环,然后判断条件是否成立.
- Pandas:从CSV中读取一个含有datetime类型的DataFrame、单项时间数据获取
前言 有一个CSV文件test.csv,其中有一列是datetime类型,其他列是数值列,就像下边这样: 问题 1.读取该CSV文件,把datetime列转换为datetime类型,并将它设置为索引列 ...
- ubuntu 下的ftp安装及root身份远程配置
第一步:在 Ubuntu 中安装 VSFTPD 服务器 //安装 VSFTPD 二进制包 $ sudo apt-get update $ sudo apt-get install vsftpd //使 ...
- Navicat15激活(仅供学习使用,严禁任何商业用途)
Navicat15利用注册机破解的方法 需求 Navicat15下载及安装 也可以联系作者获取Navicat15及工具,仅供学习使用,严禁各种用于商业活动 1.打开搜索引擎,查找Navicat15,然 ...
- Java 替换PDF中的字体
文档中可通过应用不同的字体来呈现不一样的视觉效果,通过字体来实现文档布局.排版等设计需要.应用字体时,可在创建文档时指定字体,也可以用新字体去替换文档中已有的字体.下面,以Java代码展示如何来替换P ...
- Lesson A puma at large
新概念三 Lesson 1 A puma at large 词汇: 1. spot 易混淆: recognize v. [认出], identify v. [识别sb/sth的身份] v. 看出,发现 ...
- System x 服务器制作ServerGuide U盘安装Windows Server 2012 R2操作系统
以下内容来源于:联想官方知识库 http://iknow.lenovo.com.cn/detail/dc_154773.html 本例介绍以U盘方式,通过ServerGuide引导在System x ...
- 【故障公告】没有龙卷风,k8s集群翻船3次,投用双集群恢复
今天没有龙卷风(异常的高并发请求),故障却依然出现,问题非常奇怪. 某种异常情况会造成短时间内, k8s 集群中大量 pod (超过60%)因健康检查失败而处于 CrashLoopBackOff 状态 ...