kafka客户端打印日志
kafka 0.10.0 java客户端使用slf4j作为日志门面,需要我们加入具体的日志实现依赖才能打印日志,日志框架:http://www.cnblogs.com/set-cookie/p/8836496.html
1 客户端依赖jar包
使用命令
mvn dependency:tree -Dverbose
查看客户端依赖的那些包,可以看到java客户端只依赖了slf4j,并没有具体的日志实现:
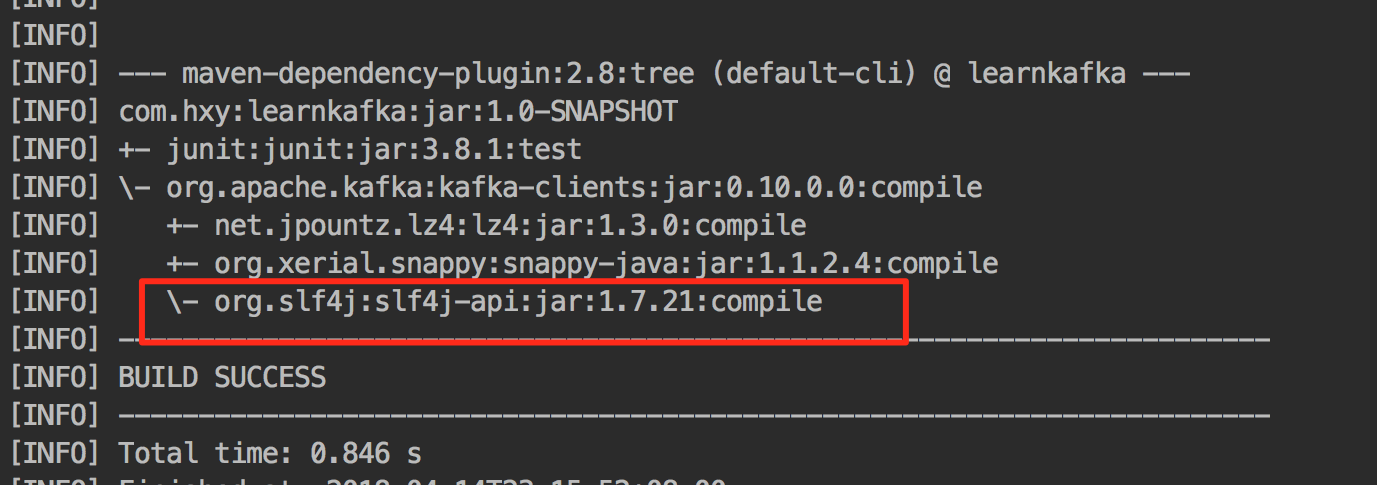
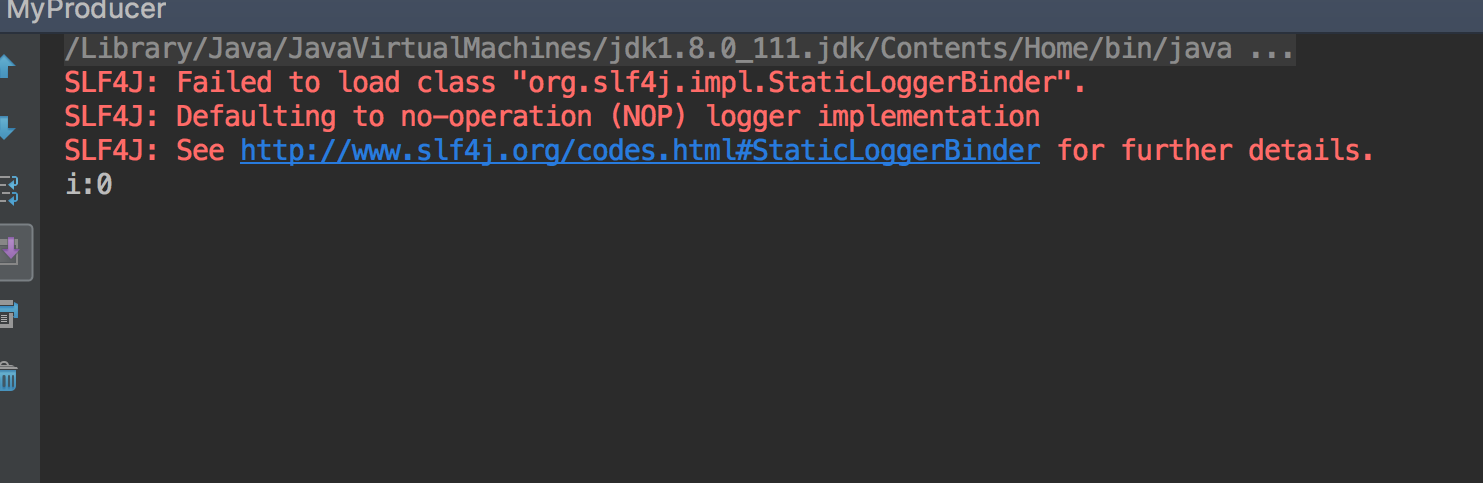
运行客户端,会打印slf4j的warn提示
2 使用log4j2
加入依赖
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!-- kafka客户端-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.0.0</version>
</dependency>
<!--log4j2到slf4j桥梁-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.9.1</version>
</dependency>
<!--log4j2 begin-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.11.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.11.0</version>
</dependency>
<!--log4j2 end-->
如果不创建log4j2.xml配置文件的话,log4j2会使用默认的配置,输出级别是ERROR,如下:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN"> <!--status表示log4j2自身日志的级别-->
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="error">
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
为了灵活性,我们可以在resources目录下创建log4j2.xml来自定义log4j2的打印,其实仅仅是将日志级别从error修改为了trace
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</Appenders>
<Loggers>
<Root level="trace"> <!--error改成trace,便于debug-->
<AppenderRef ref="Console"/>
</Root>
</Loggers>
</Configuration>
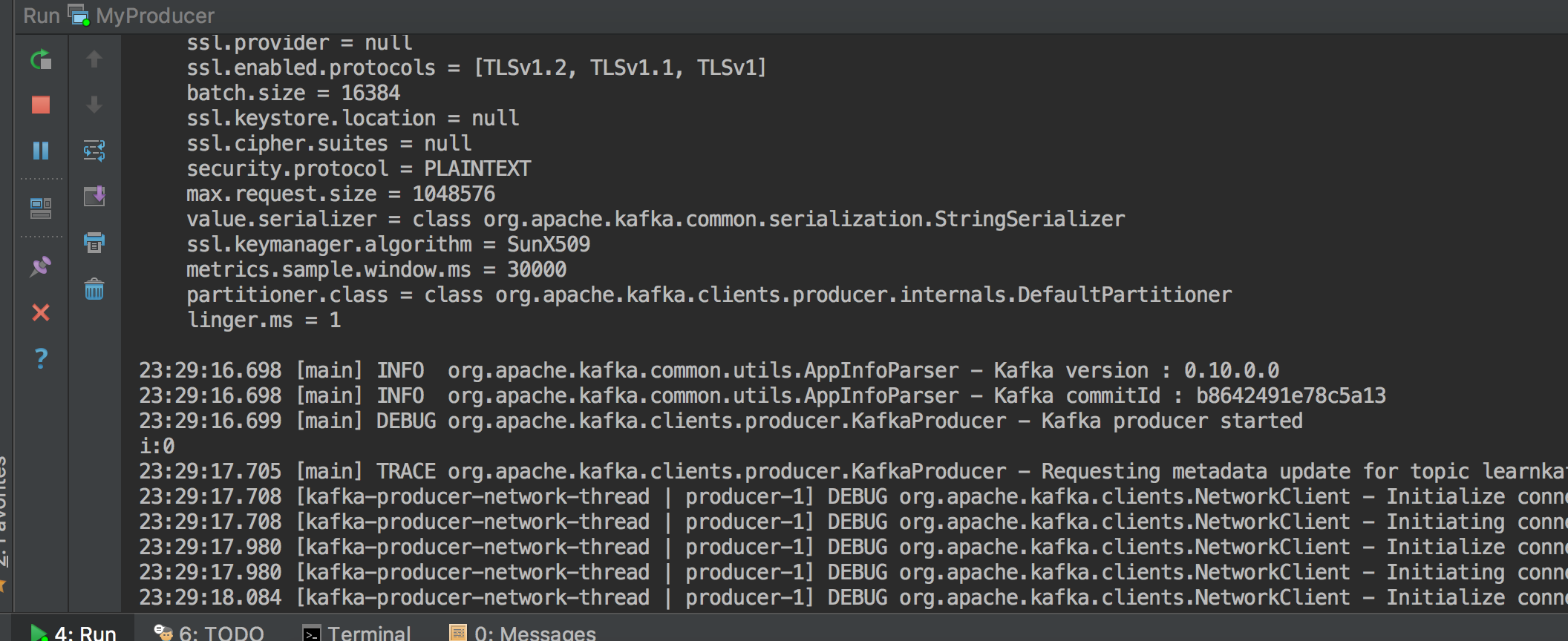
再次运行, 已经打印了trace日志
kafka客户端打印日志的更多相关文章
- 一次flume exec source采集日志到kafka因为单条日志数据非常大同步失败的踩坑带来的思考
本次遇到的问题描述,日志采集同步时,当单条日志(日志文件中一行日志)超过2M大小,数据无法采集同步到kafka,分析后,共踩到如下几个坑.1.flume采集时,通过shell+EXEC(tail -F ...
- logstash redis kafka传输 haproxy日志
logstash 客户端收集 haproxy tcp日志 input { file { path => "/data/haproxy/logs/haproxy_http.log&qu ...
- paho.mqtt.c打印日志
mqtt中自身就带有日志系统Log.h和Log.c,这些日志文件是在客户端调用MQTTClient_create函数是初始化的,MQTTClient_create源码如下: int MQTTClien ...
- 【原创】大叔问题定位分享(5)Kafka客户端报错SocketException: Too many open files 打开的文件过多
kafka0.8.1 一 问题 10月22号应用系统忽然报错: [2014/12/22 11:52:32.738]java.net.SocketException: 打开的文件过多 [2014/12/ ...
- spark读取 kafka nginx网站日志消息 并写入HDFS中(转)
原文链接:spark读取 kafka nginx网站日志消息 并写入HDFS中 spark 版本为1.0 kafka 版本为0.8 首先来看看kafka的架构图 详细了解请参考官方 我这边有三台机器用 ...
- 大数据项目中js中代码和java中代码(解决Tomcat打印日志中文乱码)
Idea2018中集成Tomcat9导致OutPut乱码找到tomcat的安装目录,打开logging.properties文件,增加一行代码,覆盖默认设置,将日志编码格式修改为GBK.java.ut ...
- Java中打印日志,这4点很重要!
目录 一.预先判断日志级别 二.避免无效日志打印 三.区别对待错误日志 四.保证记录完整内容 打印日志,要注意下面4点. 一.预先判断日志级别 对DEBUG.INFO级别的日志,必须使用条件输出或者使 ...
- Java如何打印日志
以下为<正确的打日志姿势>学习笔记. 什么时候打日志 1.程序出现问题,只能通过 debug 功能来定位问题,很大程度是日志没打好.良好的系统,通过日志就能进行问题定位. 2.if-els ...
- 从0开始搭建kafka客户端
上一节,我们实现了搭建kafka集群.本节我们将从0开始,使用Java,搭建kafka客户端生产消费模型. 1.创建maven项目2.kafka producer3.kafka consumer4.结 ...
随机推荐
- owasp中国
http://www.owasp.org.cn/OWASP-CHINA/owasp-project/owasp53415927969079c198ce9669-owasp_top_10_privacy ...
- Dell服务器通过IDRAC9收集TSR日志排查故障
登陆IDRAC9 WEB管理界面,在菜单栏< 维护>下选择 在联网的情况下推荐完成SupportAssist的注册,根据提示安装ISM并进行信息登记.如暂不注册,则点击取消继续. 进入S ...
- .Net Core之选项模式Options使用
一.简要阐述 ASP.NET Core引入了Options模式,使用类来表示相关的设置组.简单的来说,就是用强类型的类来表达配置项,这带来了很多好处.利用了系统的依赖注入,并且还可以利用配置系统.它使 ...
- [HITCON 2017]SSRFme
explode() 字符串转数组,用 ,号分隔数组 @mkdir() 创建目录 @chdir() 改变目录 这两的效果一样,如果在/home/php 目录下,执行mkdir('var') 和 ...
- Thymeleaf将字符串转换为数字
Thymeleaf将字符串转换为数字 Thymeleaf将字符串转换为数字!近期努力敲代码的时候遇到一个问题,某个字段在后端使用的是String存储,但是前端thymeleaf模板需要使用这个字段做数 ...
- LeetCode-010-正则表达式匹配
正则表达式匹配 题目描述:给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配. '.' 匹配任意单个字符 '*' 匹配零个或多个前面的那一个元素 所谓匹配 ...
- JZ-008-跳台阶
跳台阶 题目描述 一只青蛙一次可以跳上1级台阶,也可以跳上2级.求该青蛙跳上一个n级的台阶总共有多少种跳法(先后次序不同算不同的结果) 题目链接: 跳台阶 代码 public class Jz08 { ...
- php 数组相关的函数?
array()----创建数组array_combine()----通过合并两个数组来创建一个新数组range()----创建并返回一个包含指定范围的元素的数组compact()----建立一个数组a ...
- Unknown column ‘avatar_url‘ in ‘field list‘
报错: Unknown column 'avatar_url' in 'field list' 解决: 查看mysql数据库中字段名前面是否有空格或则换行
- 如何用Google Drive下载超大型文件
本文将对「如何下载Google Drive中的超大型文件?」这一问题展开探索和解决. 太长不读:直接看这里 情景与问题 在AI.系统安全等研究领域,一项研究成果的产生需要大量的数据样本进行训练和分析, ...