RabbitMQ Go客户端教程2——任务队列/工作队列
本文翻译自RabbitMQ官网的Go语言客户端系列教程,本文首发于我的个人博客:liwenzhou.com,教程共分为六篇,本文是第二篇——任务队列。
这些教程涵盖了使用RabbitMQ创建消息传递应用程序的基础知识。
你需要安装RabbitMQ服务器才能完成这些教程,请参阅安装指南或使用Docker镜像。
这些教程的代码是开源的,官方网站也是如此。
先决条件
本教程假设RabbitMQ已安装并运行在本机上的标准端口(5672)。如果你使用不同的主机、端口或凭据,则需要调整连接设置。
任务队列/工作队列
(使用Go RabbitMQ客户端)

在第一个教程中,我们编写程序从命名的队列发送和接收消息。在这一节中,我们将创建一个工作队列,该队列将用于在多个工人之间分配耗时的任务。
工作队列(又称任务队列)的主要思想是避免立即执行某些资源密集型任务并且不得不等待这些任务完成。相反,我们安排任务异步地同时或在当前任务之后完成。我们将任务封装为消息并将其发送到队列,在后台运行的工作进程将取出消息并最终执行任务。当你运行多个工作进程时,任务将在他们之间共享。
这个概念在Web应用中特别有用,因为在Web应用中不可能在较短的HTTP请求窗口内处理复杂的任务,(译注:例如注册时发送邮件或短信验证码等场景)。
准备工作
在本教程的上一部分,我们发送了一条包含“ Hello World!”的消息。现在,我们将发送代表复杂任务的字符串。我们没有实际的任务,例如调整图像大小或渲染pdf文件,所以我们通过借助time.Sleep函数模拟一些比较耗时的任务。我们会将一些包含.的字符串封装为消息发送到队列中,其中每有一个.就表示需要耗费1秒钟的工作,例如,hello...表示一个将花费三秒钟的假任务。
我们将稍微修改上一个示例中的send.go代码,以允许从命令行发送任意消息。该程序会将任务安排到我们的工作队列中,因此我们将其命名为new_task.go
body := bodyFrom(os.Args) // 从参数中获取要发送的消息正文
err = ch.Publish(
"", // exchange
q.Name, // routing key
false, // mandatory
false,
amqp.Publishing {
DeliveryMode: amqp.Persistent,
ContentType: "text/plain",
Body: []byte(body),
})
failOnError(err, "Failed to publish a message")
log.Printf(" [x] Sent %s", body)
下面是bodyFrom函数:
func bodyFrom(args []string) string {
var s string
if (len(args) < 2) || os.Args[1] == "" {
s = "hello"
} else {
s = strings.Join(args[1:], " ")
}
return s
}
我们以前的receive.go程序也需要进行一些更改:它需要为消息正文中出现的每个.伪造一秒钟的工作。它将从队列中弹出消息并执行任务,因此我们将其称为worker.go:
msgs, err := ch.Consume(
q.Name, // queue
"", // consumer
true, // auto-ack
false, // exclusive
false, // no-local
false, // no-wait
nil, // args
)
failOnError(err, "Failed to register a consumer")
forever := make(chan bool)
go func() {
for d := range msgs {
log.Printf("Received a message: %s", d.Body)
dot_count := bytes.Count(d.Body, []byte(".")) // 数一下有几个.
t := time.Duration(dot_count)
time.Sleep(t * time.Second) // 模拟耗时的任务
log.Printf("Done")
}
}()
log.Printf(" [*] Waiting for messages. To exit press CTRL+C")
<-forever
请注意,我们的假任务模拟执行时间。
然后,我们就可以打开两个终端,分别执行new_task.go和worker.go了。
# shell 1
go run worker.go
# shell 2
go run new_task.go
循环调度
使用任务队列的优点之一是能够轻松并行化工作。如果我们的工作正在积压,我们可以增加更多的工人,这样就可以轻松扩展。
首先,让我们尝试同时运行两个worker.go脚本。它们都将从队列中获取消息,但是究竟是怎样呢?让我们来看看。
你需要打开三个控制台。其中两个将运行worker.go脚本。这些控制台将成为我们的两个消费者——C1和C2。
# shell 1
go run worker.go
# => [*] Waiting for messages. To exit press CTRL+C
# shell 2
go run worker.go
# => [*] Waiting for messages. To exit press CTRL+C
在第三个控制台中,我们将发布新任务。启动消费者之后,你可以发布一些消息:
# shell 3
go run new_task.go msg1.
go run new_task.go msg2..
go run new_task.go msg3...
go run new_task.go msg4....
go run new_task.go msg5.....
然后我们在shell1和 shell2 两个窗口看到如下输出结果了:
# shell 1
go run worker.go
# => [*] Waiting for messages. To exit press CTRL+C
# => [x] Received a message: msg1.
# => [x] Received a message: msg3...
# => [x] Received a message: msg5.....
# shell 2
go run worker.go
# => [*] Waiting for messages. To exit press CTRL+C
# => [x] Received a message: msg2..
# => [x] Received a message: msg4....
默认情况下,RabbitMQ将按顺序将每个消息发送给下一个消费者。平均而言,每个消费者都会收到相同数量的消息。这种分发消息的方式称为轮询。使用三个或者更多worker试一下。
消息确认
work 完成任务可能需要耗费几秒钟,如果一个worker在任务执行过程中宕机了该怎么办呢?我们当前的代码中,RabbitMQ一旦向消费者传递了一条消息,便立即将其标记为删除。在这种情况下,如果你终止一个worker那么你就可能会丢失这个任务,我们还将丢失所有已经交付给这个worker的尚未处理的消息。
我们不想丢失任何任务,如果一个worker意外宕机了,那么我们希望将任务交付给其他worker来处理。
为了确保消息永不丢失,RabbitMQ支持 消息确认。消费者发送回一个确认(acknowledgement),以告知RabbitMQ已经接收,处理了特定的消息,并且RabbitMQ可以自由删除它。
如果使用者在不发送确认的情况下死亡(其通道已关闭,连接已关闭或TCP连接丢失),RabbitMQ将了解消息未完全处理,并将对其重新排队。如果同时有其他消费者在线,它将很快将其重新分发给另一个消费者。这样,您可以确保即使工人偶尔死亡也不会丢失任何消息。
没有任何消息超时;RabbitMQ将在消费者死亡时重新传递消息。即使处理一条消息需要很长时间也没关系。
在本教程中,我们将使用手动消息确认,方法是为“auto-ack”参数传递一个false,然后在完成任务后,使用d.Ack(false)从worker发送一个正确的确认(这将确认一次传递)。
msgs, err := ch.Consume(
q.Name, // queue
"", // consumer
false, // 注意这里传false,关闭自动消息确认
false, // exclusive
false, // no-local
false, // no-wait
nil, // args
)
if err != nil {
fmt.Printf("ch.Consume failed, err:%v\n", err)
return
}
// 开启循环不断地消费消息
forever := make(chan bool)
go func() {
for d := range msgs {
log.Printf("Received a message: %s", d.Body)
dotCount := bytes.Count(d.Body, []byte("."))
t := time.Duration(dotCount)
time.Sleep(t * time.Second)
log.Printf("Done")
d.Ack(false) // 手动传递消息确认
}
}()
使用这段代码,我们可以确保即使你在处理消息时使用CTRL+C杀死一个worker,也不会丢失任何内容。在worker死后不久,所有未确认的消息都将被重新发送。
消息确认必须在接收消息的同一通道(Channel)上发送。尝试使用不同的通道(Channel)进行消息确认将导致通道级协议异常。有关更多信息,请参阅确认的文档指南。
忘记确认
忘记确认是一个常见的错误。这是一个简单的错误,但后果是严重的。当你的客户机退出时,消息将被重新传递(这看起来像随机重新传递),但是RabbitMQ将消耗越来越多的内存,因为它无法释放任何未确认的消息。
为了调试这种错误,可以使用rabbitmqctl打印messages_unacknowledged字段:
sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
在Windows平台,去掉sudo
rabbitmqctl.bat list_queues name messages_ready messages_unacknowledged
消息持久化
我们已经学会了如何确保即使消费者死亡,任务也不会丢失。但是如果RabbitMQ服务器停止运行,我们的任务仍然会丢失。
当RabbitMQ退出或崩溃时,它将忘记队列和消息,除非您告诉它不要这样做。要确保消息不会丢失,需要做两件事:我们需要将队列和消息都标记为持久的。
首先,我们需要确保队列能够在RabbitMQ节点重新启动后继续运行。为此,我们需要声明它是持久的:
q, err := ch.QueueDeclare(
"hello", // name
true, // 声明为持久队列
false, // delete when unused
false, // exclusive
false, // no-wait
nil, // arguments
)
虽然这个命令本身是正确的,但它在我们当前的设置中不起作用。这是因为我们已经定义了一个名为hello的队列,它不是持久的。RabbitMQ不允许你使用不同的参数重新定义现有队列,并将向任何尝试重新定义的程序返回错误。但是有一个快速的解决方法——让我们声明一个具有不同名称的队列,例如task_queue:
q, err := ch.QueueDeclare(
"task_queue", // name
true, // 声明为持久队列
false, // delete when unused
false, // exclusive
false, // no-wait
nil, // arguments
)
这种持久的选项更改需要同时应用于生产者代码和消费者代码。
在这一点上,我们确信即使RabbitMQ重新启动,任务队列队列也不会丢失。现在我们需要将消息标记为持久的——通过使用amqp.Publishing中的持久性选项amqp.Persistent。
err = ch.Publish(
"", // exchange
q.Name, // routing key
false, // 立即
false, // 强制
amqp.Publishing{
DeliveryMode: amqp.Persistent, // 持久(交付模式:瞬态/持久)
ContentType: "text/plain",
Body: []byte(body),
})
有关消息持久性的说明
将消息标记为持久性并不能完全保证消息不会丢失。尽管它告诉RabbitMQ将消息保存到磁盘上,但是RabbitMQ接受了一条消息并且还没有保存它时,仍然有一个很短的时间窗口。而且,RabbitMQ并不是对每个消息都执行
fsync(2)——它可能只是保存到缓存中,而不是真正写入磁盘。持久性保证不是很强,但是对于我们的简单任务队列来说已经足够了。如果您需要更强有力的担保,那么您可以使用publisher confirms。
公平分发
你可能已经注意到调度仍然不能完全按照我们的要求工作。例如,在一个有两个worker的情况下,当所有的奇数消息都是重消息而偶数消息都是轻消息时,一个worker将持续忙碌,而另一个worker几乎不做任何工作。嗯,RabbitMQ对此一无所知,仍然会均匀地发送消息。
这是因为RabbitMQ只是在消息进入队列时发送消息。它不考虑消费者未确认消息的数量。只是盲目地向消费者发送信息。
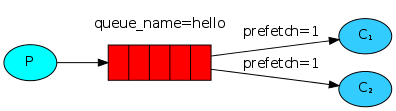
为了避免这种情况,我们可以将预取计数设置为1。这告诉RabbitMQ不要一次向一个worker发出多个消息。或者,换句话说,在处理并确认前一条消息之前,不要向worker发送新消息。相反,它将把它发送给下一个不忙的worker。
err = ch.Qos(
1, // prefetch count
0, // prefetch size
false, // global
)
关于队列大小的说明
如果所有的
worker都很忙,你的queue随时可能会满。你会想继续关注这一点,也许需要增加更多的worker,或者有一些其他的策略。
完整的代码示例
我们的new_task.go的最终代码代入如下:
package main
import (
"fmt"
"log"
"os"
"strings"
"github.com/streadway/amqp"
)
func main() {
// 1. 尝试连接RabbitMQ,建立连接
// 该连接抽象了套接字连接,并为我们处理协议版本协商和认证等。
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
fmt.Printf("connect to RabbitMQ failed, err:%v\n", err)
return
}
defer conn.Close()
// 2. 接下来,我们创建一个通道,大多数API都是用过该通道操作的。
ch, err := conn.Channel()
if err != nil {
fmt.Printf("open a channel failed, err:%v\n", err)
return
}
defer ch.Close()
// 3. 要发送,我们必须声明要发送到的队列。
q, err := ch.QueueDeclare(
"task_queue", // name
true, // 持久的
false, // delete when unused
false, // 独有的
false, // no-wait
nil, // arguments
)
if err != nil {
fmt.Printf("declare a queue failed, err:%v\n", err)
return
}
// 4. 然后我们可以将消息发布到声明的队列
body := bodyFrom(os.Args)
err = ch.Publish(
"", // exchange
q.Name, // routing key
false, // 立即
false, // 强制
amqp.Publishing{
DeliveryMode: amqp.Persistent, // 持久
ContentType: "text/plain",
Body: []byte(body),
})
if err != nil {
fmt.Printf("publish a message failed, err:%v\n", err)
return
}
log.Printf(" [x] Sent %s", body)
}
// bodyFrom 从命令行获取将要发送的消息内容
func bodyFrom(args []string) string {
var s string
if (len(args) < 2) || os.Args[1] == "" {
s = "hello"
} else {
s = strings.Join(args[1:], " ")
}
return s
}
work.go内容如下:
package main
import (
"bytes"
"fmt"
"log"
"time"
"github.com/streadway/amqp"
)
func main() {
conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")
if err != nil {
fmt.Printf("connect to RabbitMQ failed, err:%v\n", err)
return
}
defer conn.Close()
ch, err := conn.Channel()
if err != nil {
fmt.Printf("open a channel failed, err:%v\n", err)
return
}
defer ch.Close()
// 声明一个queue
q, err := ch.QueueDeclare(
"task_queue", // name
true, // 声明为持久队列
false, // delete when unused
false, // exclusive
false, // no-wait
nil, // arguments
)
err = ch.Qos(
1, // prefetch count
0, // prefetch size
false, // global
)
if err != nil {
fmt.Printf("ch.Qos() failed, err:%v\n", err)
return
}
// 立即返回一个Delivery的通道
msgs, err := ch.Consume(
q.Name, // queue
"", // consumer
false, // 注意这里传false,关闭自动消息确认
false, // exclusive
false, // no-local
false, // no-wait
nil, // args
)
if err != nil {
fmt.Printf("ch.Consume failed, err:%v\n", err)
return
}
// 开启循环不断地消费消息
forever := make(chan bool)
go func() {
for d := range msgs {
log.Printf("Received a message: %s", d.Body)
dotCount := bytes.Count(d.Body, []byte("."))
t := time.Duration(dotCount)
time.Sleep(t * time.Second)
log.Printf("Done")
d.Ack(false) // 手动传递消息确认
}
}()
log.Printf(" [*] Waiting for messages. To exit press CTRL+C")
<-forever
}
使用消息确认和预取计数,可以设置工作队列(work queue)。即使RabbitMQ重新启动,持久性选项也可以让任务继续存在。
有关amqp.Channel方法和消息属性的内容,可以浏览amqp API文档。
RabbitMQ Go客户端教程2——任务队列/工作队列的更多相关文章
- RabbitMQ Go客户端教程1——HelloWorld
本文翻译自RabbitMQ官网的Go语言客户端系列教程,本文首发于我的个人博客:liwenzhou.com,共分为六篇,本文是第一篇--HelloWorld. 这些教程涵盖了使用RabbitMQ创建消 ...
- RabbitMQ 官方NET教程(二)【工作队列】
这篇中我们将会创建一个工作队列用来在工作者(consumer)间分发耗时任务. 工作队列的主要任务是:避免立刻执行资源密集型任务和避免必须等待其完成.相反地,我们进行任务调度:我们把任务封装为消息发送 ...
- RabbitMQ Go客户端教程6——RPC
本文翻译自RabbitMQ官网的Go语言客户端系列教程,本文首发于我的个人博客:liwenzhou.com,教程共分为六篇,本文是第六篇--RPC. 这些教程涵盖了使用RabbitMQ创建消息传递应用 ...
- RabbitMQ Go客户端教程3——发布/订阅
本文翻译自RabbitMQ官网的Go语言客户端系列教程,本文首发于我的个人博客:liwenzhou.com,教程共分为六篇,本文是第三篇--发布/订阅. 这些教程涵盖了使用RabbitMQ创建消息传递 ...
- RabbitMQ Go客户端教程5——topic
本文翻译自RabbitMQ官网的Go语言客户端系列教程,本文首发于我的个人博客:liwenzhou.com,教程共分为六篇,本文是第五篇--topic. 这些教程涵盖了使用RabbitMQ创建消息传递 ...
- RabbitMQ Go客户端教程4——路由
本文翻译自RabbitMQ官网的Go语言客户端系列教程,本文首发于我的个人博客:liwenzhou.com,教程共分为六篇,本文是第四篇--路由. 这些教程涵盖了使用RabbitMQ创建消息传递应用程 ...
- [译]RabbitMQ教程C#版 - 工作队列
先决条件 本教程假定RabbitMQ已经安装,并运行在localhost标准端口(5672).如果你使用不同的主机.端口或证书,则需要调整连接设置. 从哪里获得帮助 如果您在阅读本教程时遇到困难,可以 ...
- RabbitMQ教程C#版 - 工作队列
先决条件本教程假定 RabbitMQ 已经安装,并运行在localhost标准端口(5672).如果你使用不同的主机.端口或证书,则需要调整连接设置. 从哪里获得帮助如果您在阅读本教程时遇到困难,可以 ...
- RabbitMQ入门教程(四):工作队列(Work Queues)
原文:RabbitMQ入门教程(四):工作队列(Work Queues) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https:/ ...
随机推荐
- Spring系列14:IoC容器的扩展点
Spring系列14:IoC容器的扩展点 回顾 知识需要成体系地学习,本系列文章前后有关联,建议按照顺序阅读.上一篇我们详细介绍了Spring Bean的生命周期和丰富的扩展点,没有阅读的强烈建议先阅 ...
- 10、Linux基础--find、正则、文本过滤器grep
笔记 1.晨考 1.每个月的3号.5号和15号,而且这天是星期六时执行 00 00 3,5,15 * 6 2.每天的3点到15点,每隔3分钟执行一次 */3 3-15 * * * 3.每周六早上2点半 ...
- Solution -「CF 1023F」Mobile Phone Network
\(\mathcal{Description}\) Link. 有一个 \(n\) 个结点的图,并给定 \(m_1\) 条无向带权黑边,\(m_2\) 条无向无权白边.你需要为每条白边指定边权 ...
- Solution -「LOCAL」「cov. HDU 6864」找朋友
\(\mathcal{Description}\) Link.(几乎一致) 给定 \(n\) 个点 \(m\) 条边的仙人掌和起点 \(s\),边长度均为 \(1\).令 \(d(u)\) 表 ...
- 【流行前沿】联邦学习 Federated Learning with Only Positive Labels
核心问题:如果每个用户只有一类数据,如何进行联邦学习? Felix X. Yu, , Ankit Singh Rawat, Aditya Krishna Menon, and Sanjiv Kumar ...
- suse 12 升级 OpenSSH-7.2p2 到 OpenSSH-8.4p1
文章目录 1.查看当前当前环境信息 1.1.查看openssh当前版本 1.2.查看当前linux发行版 2.部署telnet-server 2.1.下载telnet-server 2.2.配置tel ...
- LibOpenCM3(二) 项目模板 Makefile分析
目录 LibOpenCM3(一) Linux下命令行开发环境配置 LibOpenCM3(二) 项目模板 Makefile分析 LibOpenCM3 项目模板 项目模板地址: https://githu ...
- wurstmeister/kafka:docker构建kafka遇到的问题
1. kafka 容器无法启动 过程描述: docker ps -a 看到 Exited docker logs a87d9cd2a8ac 查看日志: 发现是内存不够 解决方案: 修改 kafka的J ...
- 给bootstrap-table填坑
由于设计变更,需要把数据由分页展示改为全部展示(才3500条数据),结果chrome浏览器页面卡顿,火狐浏览器直接卡死! console.time分析之后,竟然是bootstrap-table插件的坑 ...
- nodejs调用jar
目前nodejs调用jar主要有两种方式: 通过创建子进程运行java -jar命令调用包含main方法的jar 使用node-java通过c++桥接调用jar 方法一(子进程运行): const { ...