SQLSERVER 的复合索引和包含索引到底有啥区别?
一:背景
1. 讲故事
在 SQLSERVER 中有非常多的索引,比如:聚集索引,非聚集索引,唯一索引,复合索引,Include索引,交叉索引,连接索引,奇葩索引等等,当索引多了之后很容易傻傻的分不清,比如:复合索引 和 Include索引,但又在真实场景中用的特别多,本篇我们就从底层数据页层面厘清一下。
二:到底有什么区别
1. 这些索引解决了什么问题
说区别之前,一定要知道它们大概解决了什么问题?这里我就从 索引覆盖 角度来展开吧,为了方便讲述,先上一个测试 sql:
IF(OBJECT_ID('t') IS NOT NULL) DROP TABLE t;
CREATE TABLE t(a INT IDENTITY, b CHAR(6), c CHAR(10) DEFAULT 'aaaaaaaaaa')
SET NOCOUNT ON
DECLARE @num INT
SET @num =10000
WHILE (@num <90000)
BEGIN
INSERT INTO t(b) VALUES ('b'+CAST(@num AS CHAR(5)))
SET @num=@num+1
END
CREATE CLUSTERED INDEX idx_a ON t(a)
CREATE INDEX idx_b ON t(b)
SELECT * FROM t;
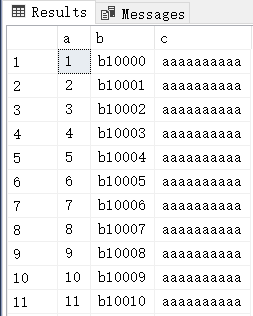
代码非常简单,在 t 表中创建三个列,插入 8w 条数据,然后创建两个索引,接下来做一个查询获取 b,c 列。
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT b,c FROM t WHERE b IN ('b10000','b20000','b30000','b40000','b50000','b70000','b80000','b90000')
SET STATISTICS IO OFF
SET STATISTICS TIME OFF
输出如下:
表“t”。扫描计数 8,逻辑读取次数 30,物理读取次数 0,页面服务器读取次数 0,预读读取次数 0,页面服务器预读读取次数 0,LOb 逻辑读取次数 0,LOB 逻辑读取次数 0,LOB 页面服务器读取次数 0,LOB 预读读取次数 0,LOB 页面服务器预读读取次数 0。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 134 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
Completion time: 2023-01-06T08:47:45.2364473+08:00
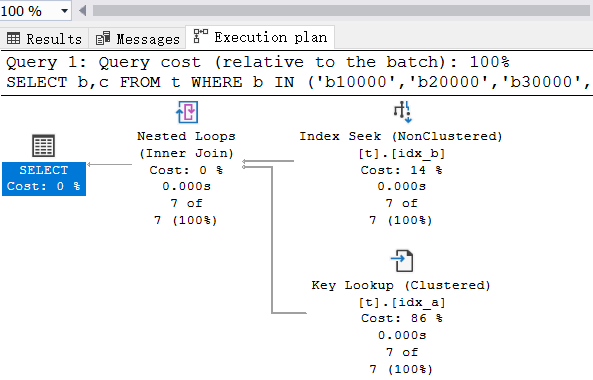
从执行计划看,这是一个经典的 书签查找,这种查找返回的行数越多性能越差,在索引优化时一般都会规避掉这种情况,我们也看到了逻辑读取次数有 30 次,那能不能再小一点呢?
为了解决这个问题,干脆把 c 列也放到索引中去达到索引覆盖的效果,这就需要用到 复合索引 了,参考sql如下:
CREATE INDEX idx_complex ON t (b,c)
再次查询输出如下:
SQL Server 分析和编译时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
表“t”。扫描计数 8,逻辑读取次数 24,物理读取次数 0,页面服务器读取次数 0,预读读取次数 0,页面服务器预读读取次数 0,LOb 逻辑读取次数 0,LOB 逻辑读取次数 0,LOB 页面服务器读取次数 0,LOB 预读读取次数 0,LOB 页面服务器预读读取次数 0。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 96 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
Completion time: 2023-01-06T08:53:56.9688921+08:00
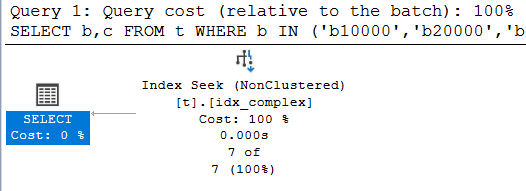
从执行计划来看,这次没有走 书签查找 而是 索引查找,并且逻辑读也降到了 24 次,这是一个好的优化。
相信有些朋友也知道用 Include索引 也能达到这个效果,接下来试着把复合索引给删了增加一个 Include索引,代码如下:
DROP INDEX idx_complex ON dbo.t;
CREATE INDEX idx_include ON t(b) INCLUDE (c)
再次查询输出如下:
表“t”。扫描计数 8,逻辑读取次数 16,物理读取次数 0,页面服务器读取次数 0,预读读取次数 0,页面服务器预读读取次数 0,LOb 逻辑读取次数 0,LOB 逻辑读取次数 0,LOB 页面服务器读取次数 0,LOB 预读读取次数 0,LOB 页面服务器预读读取次数 0。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 73 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
Completion time: 2023-01-06T08:58:18.1122561+08:00
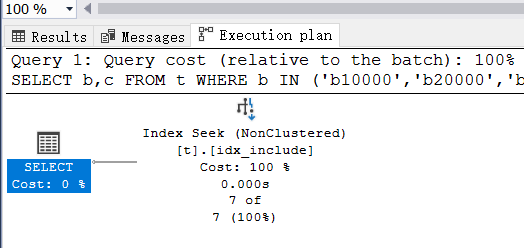
从执行计划来看也是走的 非聚集索引,而且逻辑读再次降到了 16 次,相比原始的书签查找已经优化了 50%,这是一个巨大的性能提升不是。
到这里其实有一个问题,两种优化走的都是 非聚集索引,从逻辑读次数看貌似 Include索引 更好一些,为什么会这样呢?这就涉及到了底层存储,接下来一起扒一下。
2. 存储原理研究
研究它们的不同点,最彻底的方式就是从底层存储出发,首先我们观察下 复合索引 的底层存储是什么样的,可以用 DBCC 命令。
DBCC TRACEON(3604)
DBCC IND(MyTestDB,t,-1)

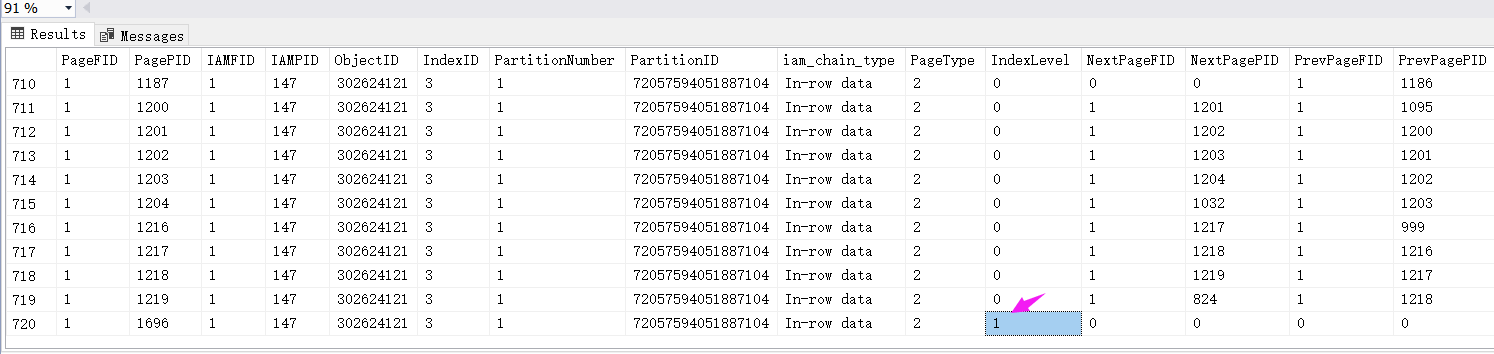
从 IndexLevel=2 来看这个复合索引构成的B树已经达到了二层,接下来我们查一下 368 号数据页内容。
DBCC PAGE(MyTestDB,1,368,2)
输出如下:
PAGE: (1:368)
Memory Dump @0x000000F555578000
000000F555578000: 01020002 00800001 00000000 00001b00 00000000 ....................
000000F555578014: 00000200 3e010000 601f9c00 70010000 01000000 ....>...`...p.......
000000F555578028: f8000000 e0680000 f5010000 00000000 00000000 .....h..............
000000F55557803C: 00000000 01000000 00000000 00000000 00000000 ....................
000000F555578050: 00000000 00000000 00000000 00000000 16623130 .................b10
000000F555578064: 30303061 61616161 61616161 61010000 00380500 000aaaaaaaaaa....8..
000000F555578078: 00010004 00001662 38333631 36616161 61616161 .......b83616aaaaaaa
000000F55557808C: 61616191 1f010070 05000001 00040000 00006231 aaa....p..........b1
OFFSET TABLE:
Row - Offset
1 (0x1) - 126 (0x7e)
0 (0x0) - 96 (0x60)
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。
根据下面的 Slot 个数可以知道这个分支节点数据页只有 2 条记录,分别为:(b10000,aaaaaaaaaa,0x01) , (b83616,aaaaaaaaaa,0x011f91),这里说明一下最后的 01 和 0x011f91 是主键key,接下来找个叶子节点,比如:1632 号索引页。
PAGE: (1:1632)
Memory Dump @0x000000F555578000
...
000000F555578050: 00000000 00000000 00000000 00000000 16623135 .................b15
000000F555578064: 32383761 61616161 61616161 61a81400 00040000 287aaaaaaaaaa.......
000000F555578078: 16623135 32383861 61616161 61616161 61a91400 .b15288aaaaaaaaaa...
000000F55557808C: 00040000 16623135 32383961 61616161 61616161 .....b15289aaaaaaaaa
000000F5555780A0: 61aa1400 00040000 16623135 32393061 61616161 a........b15290aaaaa
000000F5555780B4: 61616161 61ab1400 00040000 16623135 32393161 aaaaa........b15291a
000000F5555780C8: 61616161 61616161 61ac1400 00040000 16623135 aaaaaaaaa........b15
000000F5555780DC: 32393261 61616161 61616161 61ad1400 00040000 292aaaaaaaaaa.......
000000F5555780F0: 16623135 32393361 61616161 61616161 61ae1400 .b15293aaaaaaaaaa...
000000F555578104: 00040000 16623135 32393461 61616161 61616161 .....b15294aaaaaaaaa
000000F555578118: 61af1400 00040000 16623135 32393561 61616161 a........b15295aaaaa
000000F55557812C: 61616161 61b01400 00040000 16623135 32393661 aaaaa........b15296a
000000F555578140: 61616161 61616161 61b11400 00040000 16623135 aaaaaaaaa........b15
...
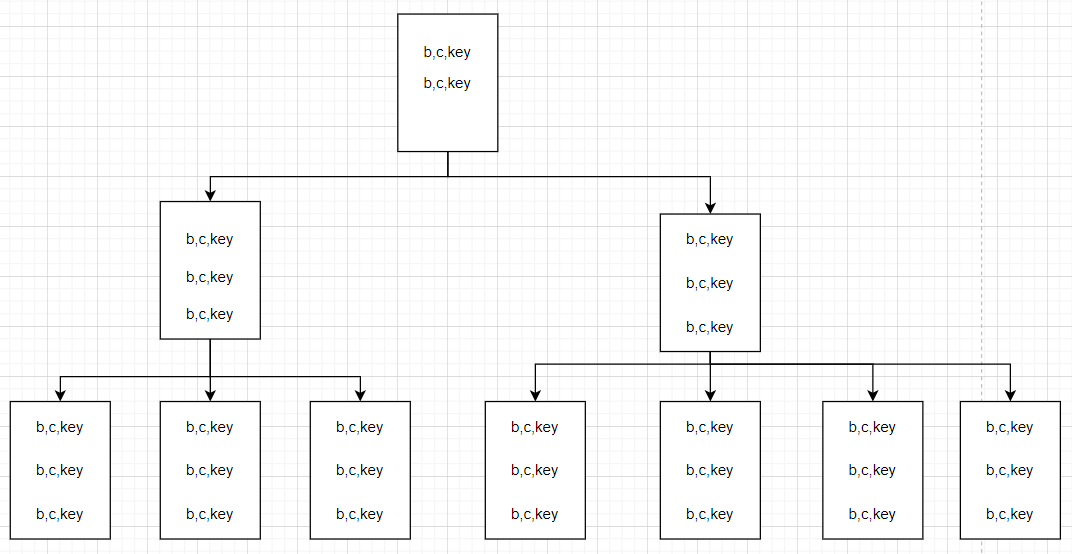
从叶子节点上看,也是 (b,c,key) 的布局模式,这时候脑子里就有了一张图。
用同样的方式观察下 Include索引,发现 IndexLevel=1,说明只有一层。
再用 DBCC 观察下分支节点的布局。
PAGE: (1:1696)
Memory Dump @0x000000F554F78000
000000F554F78000: 01020001 00820001 00000000 00001100 00000000 ....................
000000F554F78014: 00000601 42010000 1c09d814 a0060000 01000000 ....B.... ..........
000000F554F78028: 0f010000 78310000 39010000 00000000 00000000 ....x1..9...........
000000F554F7803C: f01efa04 00000000 00000000 00000000 00000000 ....................
000000F554F78050: 00000000 00000000 00000000 00000000 16623130 .................b10
000000F554F78064: 30303001 00000088 03000001 00030000 16623130 000..............b10
000000F554F78078: 33313138 010000b0 03000001 00030000 16623130 3118.............b10
000000F554F7808C: 3632326f 020000b1 03000001 00030000 16623130 622o.............b10
000000F554F780A0: 393333a6 030000b2 03000001 00030000 16623131 933..............b11
...
从输出看并没有记录 列c 的值,就是那烦人的 aaaaaaaaaa,然后再抽个叶子节点看看,比如:1218号索引页。
PAGE: (1:1218)
Memory Dump @0x000000F554F78000
000000F554F78000: 01020000 04020001 c1040000 01001500 c3040000 ....................
000000F554F78014: 01003701 42010000 0a00881d c2040000 01000000 ..7.B...............
000000F554F78028: 0f010000 00310000 03000000 00000000 00000000 .....1..............
000000F554F7803C: e7351886 00000000 00000000 00000000 00000000 .5..................
000000F554F78050: 00000000 00000000 00000000 00000000 16623833 .................b83
000000F554F78064: 313235a6 1d010061 61616161 61616161 61040000 125....aaaaaaaaaa...
000000F554F78078: 16623833 313236a7 1d010061 61616161 61616161 .b83126....aaaaaaaaa
000000F554F7808C: 61040000 16623833 313237a8 1d010061 61616161 a....b83127....aaaaa
000000F554F780A0: 61616161 61040000 16623833 313238a9 1d010061 aaaaa....b83128....a
000000F554F780B4: 61616161 61616161 61040000 16623833 313239aa aaaaaaaaa....b83129.
000000F554F780C8: 1d010061 61616161 61616161 61040000 16623833 ...aaaaaaaaaa....b83
000000F554F780DC: 313330ab 1d010061 61616161 61616161 61040000 130....aaaaaaaaaa...
...
在叶子节点中我们终于看到了 aaaaaaaaaa ,其实想一想肯定是有的,不然怎么做索引覆盖呢?有了这些信息,脑子中又有了一张图。
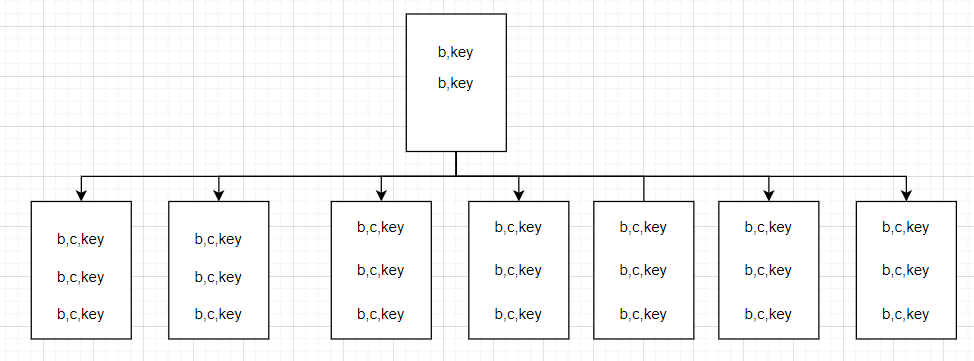
从图中可以看出,Include索引 的分支节点是不包含 c 列的,这个列只会保存在 叶子节点 中,再结合树的高度来看就能解释为什么 Include索引 的逻辑读要少于 复合索引。
三:总结
总的来说 复合索引 和 Include索引 各有利弊吧,前者会让索引页的行数据更大,导致索引页更多,也就会占用更多的存储空间,更多的逻辑读,索引维护开销也更大,而后者只会将 Include 列 保存在叶子节点,不参与索引计算,相对来说占用的索引页空间更小。
在查询方面,复合索引能达到的索引覆盖场景远大于单列索引,而且在过滤,排序场景下也能发挥奇效,所以还是根据你的读写比例做一个取舍吧。
SQLSERVER 的复合索引和包含索引到底有啥区别?的更多相关文章
- SQL SERVER大话存储结构(4)_复合索引与包含索引
索引这块从存储结构来分,有2大类,聚集索引和非聚集索引,而非聚集索引在堆表或者在聚集索引表都会对其 键值有所影响,这块可以详细查看本系列第二篇文章:SQL SERVER大话存储结构 ...
- Sql Server之旅——第八站 复合索引和include索引到底有多大区别?
周末终于搬进出租房了,装了宽带....才发现没网的日子...那是一个怎样的与世隔绝呀...再也受不了那样的日子了....好了,既然网 安上去了,还得继续我的这个系列. 索引和锁,这两个主题对我们开发工 ...
- (转)Sql Server之旅——第八站 复合索引和include索引到底有多大区别?
索引和锁,这两个主题对我们开发工程师来说,非常的重要...只有理解了这两个主题,我们才能写出高质量的sql语句,在之前的博客中,我所说的 索引都是单列索引...当然数据库不可能只认单列索引,还有我这篇 ...
- 认识SQLServer索引以及单列索引和多列索引的不同
一.索引的概念 索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法. 索引是什么:数据库中的索引类似于一本书的目录,在一本书中使 ...
- SQLServer中间接实现函数索引或者Hash索引
本文出处:http://www.cnblogs.com/wy123/p/6617700.html SQLServer中没有函数索引,在某些场景下查询的时候要根据字段的某一部分做查询或者经过某种计算之后 ...
- mysql索引之四:复合索引之最左前缀原理,索引选择性,索引优化策略之前缀索引
高效使用索引的首要条件是知道什么样的查询会使用到索引,这个问题和B+Tree中的“最左前缀原理”有关,下面通过例子说明最左前缀原理. 一.最左前缀索引 这里先说一下联合索引的概念.MySQL中的索引可 ...
- ( 转 ) mysql复合索引、普通索引总结
对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分.例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合 ...
- SQLServer性能调优3之索引(Index)的维护
前言 前一篇的文章介绍了通过建立索引来提高数据库的查询性能,这其实只是个开始.后续如果缺少适当的维护,你先前建立的索引甚至会成为拖累,成为数据库性能的下降的帮凶. 查找碎片 消除碎片可能是索引维护最常 ...
- SQLServer中在视图上使用索引(转载)
在SQL Server中,视图是一个保存的T-SQL查询.视图定义由SQL Server保存,以便它能够用作一个虚拟表来简化查询,并给基表增加另一层安全.但是,它并不占用数据库的任何空间.实际上,在你 ...
- SQLServer之创建唯一非聚集索引
创建唯一非聚集索引典型实现 唯一索引可通过以下方式实现: PRIMARY KEY 或 UNIQUE 约束 在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自 ...
随机推荐
- Java学习之路:运算符
2022-10-10 10:34:08 1 运算符 算术运算符:+, -, *, /, %, ++, -- 赋值运算符:= 关系运算符:>, <, >=, <=, ==, != ...
- 关于多个 Kubernetes 集群指标的采集操作
简介 在使用观测云期间,有时需要针对一个工作空间接入多个 Kubernetes 集群指标,通过观测云提供的全局 Tag 的方式来进行区分,大大提高了效率.下面是我总结的操作步骤. 当集群中只有一个采集 ...
- 某Hi3516EV300摄像头折腾笔记
最近因工作需要买了某款HI3516DV300开发板,但是价格死贵,于是在国内某著名电商网站上瞎逛,很巧发现一家店铺买摄像头模组,主控HI3516EV300,cmos是IMX335,价格不到200元,然 ...
- 硬核剖析ThreadLocal源码,面试官看了直呼内行
工作面试中经常遇到ThreadLocal,但是很多同学并不了解ThreadLocal实现原理,到底为什么会发生内存泄漏也是一知半解?今天一灯带你深入剖析ThreadLocal源码,总结ThreadLo ...
- 深度优先搜索(Depth-First-Search)dfs代码模板
void dfs()//参数用来表示状态 { if(到达终点状态) { ...//根据需求添加 return; } if(越界或者是不合法状态) return; if(特殊状态)//剪枝,去除一些不需 ...
- Vue 基础学习总结
介绍 Vue.js 中文文档地址:https://cn.vuejs.org/guide/introduction.html#what-is-vue Vue.js 是什么 Vue (读音 /vjuː/, ...
- Blender建模软件怎么安装?有哪些好用的插件?
1.下载Blender软件包,将压缩包解压后,使用鼠标左键双击打开安装文件. 2.由于压缩包内有两个安装文件,用户需要根据系统版本选择安装.可以使用鼠标右键单击桌面上的"此电脑"图 ...
- GAMES101课程 作业6 源代码概览
GAMES101课程 作业6 源代码概览 Written by PiscesAlpaca(双鱼座羊驼) 一.概述 本篇将从main函数为出发点,按照各cpp文件中函数的调用顺序和层级嵌套关系,简单分析 ...
- c#入参使用引用类型为啥要加ref?
摘一段来自官网的说明 :方法的参数列表中使用 ref 关键字时,它指示参数按引用传递,而非按值传递. ref 关键字让形参成为实参的别名,这必须是变量. 换而言之,对形参执行的任何操作都是对实参执行的 ...
- TortoiseGit间接处理linux目录下的仓库,用到window映射linux目录方案
原始需求 习惯用TortoiseGit查看git仓库信息和历史日志,但这个工具只支持window,我希望linux也能用 虽然有其他linux的GUI的git工具,但我用到的linux基本都是无界面版 ...