论文解读(BGRL)《Bootstrapped Representation Learning on Graphs》
论文信息
论文标题:Bootstrapped Representation Learning on Graphs
论文作者:Shantanu Thakoor, Corentin Tallec, Mohammad Gheshlaghi Azar, Rémi Munos, Petar Veličković, Michal Valko
论文来源:2021, ArXiv
论文地址:download
论文代码:download
1 介绍
研究目的:对比学习中不适用负样本。
本文贡献:
- 对图比学习不使用负样本
2 方法
2.1 整体框架(节点级对比)
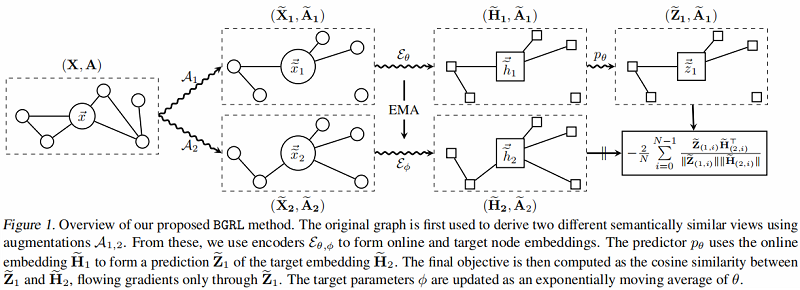
上面是 online network,下面是 target network 。
步骤:
- 步骤一:分别应用随机图增强函数 $\mathcal{A}_{1}$ 和 $\mathcal{A}_{2}$,产生 $G$ 的两个视图:$\mathbf{G}_{1}= \left(\widetilde{\mathbf{X}}_{1}, \widetilde{\mathbf{A}}_{1}\right)$ 和 $\mathbf{G}_{2}=\left(\widetilde{\mathbf{X}}_{2}, \widetilde{\mathbf{A}}_{2}\right) $;
- 步骤二:在线编码器从其增广图中生成一个在线表示 $\widetilde{\mathbf{H}}_{1}:=\mathcal{E}_{\theta}\left(\widetilde{\mathbf{X}}_{1}, \widetilde{\mathbf{A}}_{1}\right)$;目标编码器从其增广图生成目标表示 $\widetilde{\mathbf{H}}_{2}:=\mathcal{E}_{\phi}\left(\widetilde{\mathbf{X}}_{2}, \widetilde{\mathbf{A}}_{2}\right) $;
- 步骤三:在线表示被输入到一个预测器 $p_{\theta}$ 中,该预测器 $p_{\theta}$ 输出对目标表示的预测 $\widetilde{\mathbf{Z}}_{1}:= p_{\theta}\left(\widetilde{\mathbf{H}}_{1}, \widetilde{\mathbf{A}}_{1}\right)$,除非另有说明,预测器在节点级别工作,不考虑图信息(仅在 $\widetilde{\mathbf{H}}_{1}$ 上操作,而不是 $\widetilde{\mathbf{A}}_{1}$)。
2.2 BGRL更新步骤
更新 $\theta$
在线参数 $\theta$(而不是 $\phi$),通过余弦相似度的梯度,使预测的目标表示 $\mathbf{Z}_{1}$ 更接近每个节点的真实目标表示 $\widetilde{\mathbf{H}}_{2}$。
$\ell(\theta, \phi)=-\frac{2}{N} \sum\limits _{i=0}^{N-1} {\large \frac{\widetilde{\mathbf{Z}}_{(1, i)} \widetilde{\mathbf{H}}_{(2, i)}^{\top}}{\left\|\widetilde{\mathbf{Z}}_{(1, i)}\right\|\left\|\widetilde{\mathbf{H}}_{(2, i)}\right\|}} \quad\quad\quad(1)$
$\theta$ 的更新公式:
$\theta \leftarrow \operatorname{optimize}\left(\theta, \eta, \partial_{\theta} \ell(\theta, \phi)\right)\quad\quad\quad(2)$
其中 $ \eta $ 是学习速率,最终更新仅从目标对 $\theta$ 的梯度计算,使用优化方法如 SGD 或 Adam 等方法。在实践中,
我们对称了训练,也通过使用第二个视图的在线表示来预测第一个视图的目标表示。
更新 $\phi$
目标参数 $\phi$ 被更新为在线参数 $\theta$ 的指数移动平均数,即:
$\phi \leftarrow \tau \phi+(1-\tau) \theta\quad\quad\quad(3)$
其中 $\tau$ 是控制 $\phi$ 与 $ \theta$ 的距离的衰减速率。
只有在线参数被更新用来减少这种损失,而目标参数遵循不同的目标函数。根据经验,与BYOL类似,BGRL不会崩溃为平凡解,而 $\ell(\theta, \phi)$ 也不收敛于 $0$ 。
2.3. 完全非对比目标
对比学习常用的负样本带来的问题是:
- 如何定义负样本
- 随着负样本数量增多,带来的内存瓶颈;
本文损失函数定义的好处:
- 不需要对比负对 $\{(i, j) \mid i \neq j\} $ ;
- 计算方便,只需要保证余弦相似度大就行;
2.4.图增强函数
本文采用以下两种数据增强方法:
- 节点特征掩蔽(node feature masking)
- 边缘掩蔽(edge masking)
3 实验
数据集
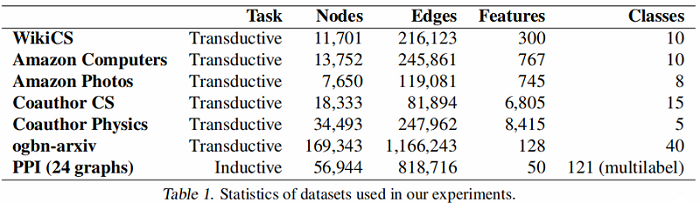
数据集划分:
- WikiCS: 20 canonical train/valid/test splits
- Amazon Computers, Amazon Photos——train/validation/test—10/10/80%
- Coauthor CS, Coauthor Physics——train/validation/test—10/10/80%
直推式学习——基线实验
图编码器采用 $\text{GCN$ Encoder 。
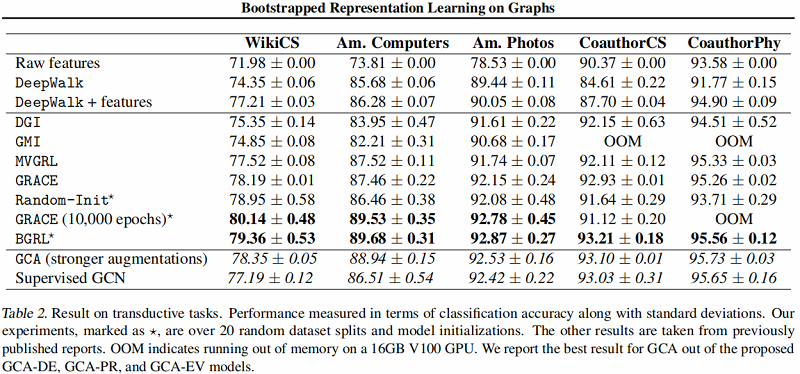
大图上的直推式学习——基线实验
结果:

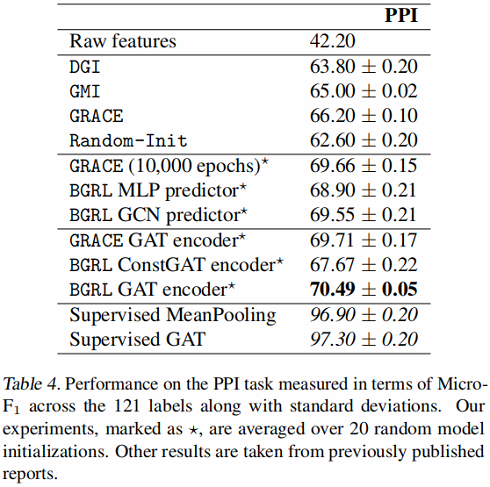
归纳式学习——基线实验
编码器采用 GraphSAGE-GCN (平均池化)和 GAT 。
结果:
4 结论
介绍了一种新的自监督图表示学习方法BGRL。通过广泛的实验,我们已经证明了我们的方法与最先进的方法具有竞争力,尽管不需要负例,并且由于不依赖于投影网络或二次节点比较而大大降低了存储需求。此外,我们的方法可以自然地扩展到学习图级嵌入,其中定义消极的例子是具有挑战性的,并且所有的目标不具有规模。
论文解读(BGRL)《Bootstrapped Representation Learning on Graphs》的更多相关文章
- 论文解读(MVGRL)Contrastive Multi-View Representation Learning on Graphs
Paper Information 论文标题:Contrastive Multi-View Representation Learning on Graphs论文作者:Kaveh Hassani .A ...
- 论文解读(JKnet)《Representation Learning on Graphs with Jumping Knowledge Networks》
论文信息 论文标题:Representation Learning on Graphs with Jumping Knowledge Networks论文作者:Keyulu Xu, Chengtao ...
- 论文阅读 Dynamic Graph Representation Learning Via Self-Attention Networks
4 Dynamic Graph Representation Learning Via Self-Attention Networks link:https://arxiv.org/abs/1812. ...
- 论文解读《Deep Resdual Learning for Image Recognition》
总的来说这篇论文提出了ResNet架构,让训练非常深的神经网络(NN)成为了可能. 什么是残差? "残差在数理统计中是指实际观察值与估计值(拟合值)之间的差."如果回归模型正确的话 ...
- 论文解读( N2N)《Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization》
论文信息 论文标题:Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximiz ...
- 论文解读(GRCCA)《 Graph Representation Learning via Contrasting Cluster Assignments》
论文信息 论文标题:Graph Representation Learning via Contrasting Cluster Assignments论文作者:Chun-Yang Zhang, Hon ...
- 论文阅读 Inductive Representation Learning on Temporal Graphs
12 Inductive Representation Learning on Temporal Graphs link:https://arxiv.org/abs/2002.07962 本文提出了时 ...
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
Paper Information Title:Simple Unsupervised Graph Representation LearningAuthors: Yujie Mo.Liang Pen ...
- 论文解读(AutoSSL)《Automated Self-Supervised Learning for Graphs》
论文信息 论文标题:Automated Self-Supervised Learning for Graphs论文作者:Wei Jin, Xiaorui Liu, Xiangyu Zhao, Yao ...
随机推荐
- 网络IO模型 非阻塞IO模型
网络IO模型 非阻塞IO模型 同步 一件事做完后再做另一件事情 异步 同时做多件事情 相对论 多线程 多进程 协程 异步的程序 宏观角度:异步 并发聊天 阻塞IO 阻塞IO的问题 一旦阻塞就不能做其他 ...
- 07模块化设计之top_down
一设计功能:(一)用两个分频模块,实现16分频,且让输入a 和b在16个系统时钟内,相与一次. (二)模块化设计思想(结构化思维) 拆分,即把一个系统划分成多个功能模块,控制模块,组合模块.然后从功能 ...
- 容器化 | 在 K8s 上部署 RadonDB MySQL Operator 和集群
作者:程润科 数据库研发工程师 编辑:张莉梅 高级文档工程师 视频:钱芬 高级测试工程师 本文将演示在 Kubernetes 上部署 RadonDB MySQL Kubernetes 2.X(Oper ...
- 《HelloGitHub》第 72 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣.入门级的开源项目. https://github.com/521xueweiha ...
- 利用 ps 怎么显示所有的进程? 怎么利用 ps 查看指定进程的信息?
ps -ef (system v 输出)ps -aux bsd 格式输出ps -ef | grep pid
- String s = new String("xyz");创建了几个String Object?
两个.一个是直接量的xyz对象:另一个是通过new Sting()构造器创建出来的String对象. 通常来说,应该尽量使用直接量的String对象,这样具有更好的性能.
- SpringCloud和Dubbo?
SpringCloud和Dubbo都是现在主流的微服务架构SpringCloud是Apache旗下的Spring体系下的微服务解决方案Dubbo是阿里系的分布式服务治理框架从技术维度上,其实Sprin ...
- java-設計模式-單例模式
單例模式 一种创建型设计模式, 让你能够保证一个类只有一个实例, 并提供一个访问该实例的全局节点. 一个类只有一个实例,且该类能自行创建这个实例的一种模式. 簡單的對比就是: 例如,Windows 中 ...
- prometheus-存储
采集到的样本以时间序列的方式保存在内存(TSDB 时序数据库)中,并定时保存到硬盘中 prometheus一般会保留15天 prometheus按照block块的方式来存储数据,每2小时为一个时间单位 ...
- ACM - 动态规划 - P1282 多米诺骨牌
多米诺骨牌由上下 \(2\) 个方块组成,每个方块中有 \(1 \sim 6\) 个点.现有排成行的上方块中点数之和记为 \(S_1\),下方块中点数之和记为 \(S_2\),它们的差为 \(\lef ...