爬取白鲸nft排名前25项目,持有nft大户地址数据。
https://moby.gg/rankings?tab=Market
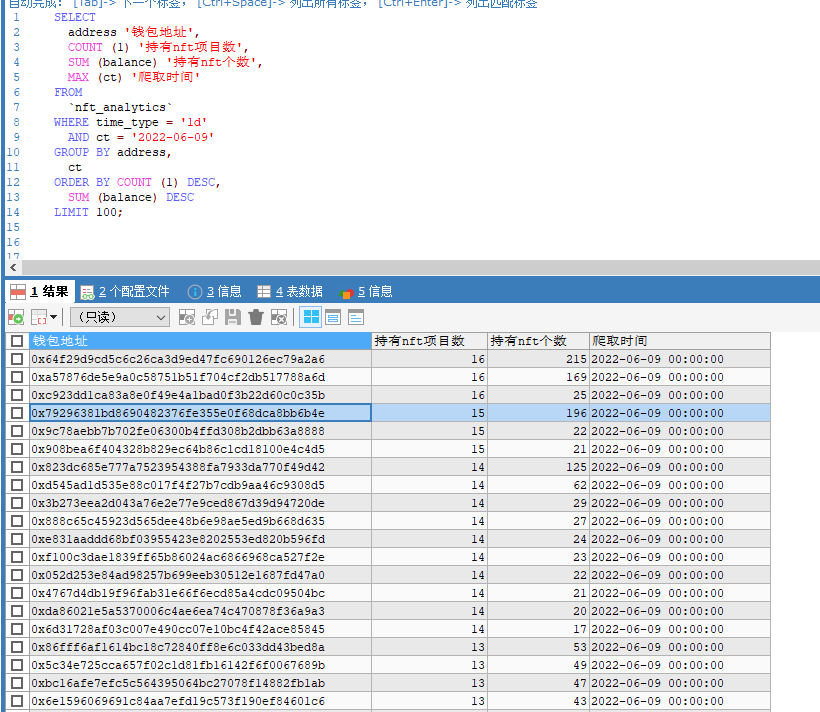
SELECT
address '钱包地址',
COUNT (1) '持有nft项目数',
SUM (balance) '持有nft个数',
MAX (ct) '爬取时间'
FROM
`nft_analytics`
WHERE time_type = '1d'
AND ct = '2022-06-09'
GROUP BY address,
ct
ORDER BY COUNT (1) DESC,
SUM (balance) DESC
LIMIT 100;
#coding=utf-8
import requests
import time
import json
import math
import datetime
from requests.packages.urllib3 import disable_warnings data_12h = ''
from selenium_chrome.MySqlUtils import getMysql
disable_warnings()
def spider_nft(time_type):
'''
12h 1d 3d
:param time_type:
:return:
'''
time_12h = f'https://moby-api.onrender.com/market/rank/{time_type}'
time_12h_resp = requests.get(time_12h,timeout=600,verify=False)
mysql = getMysql()
if(time_12h_resp.status_code == 200 and time_12h_resp.reason == 'OK'):
nft_address_list = json.loads(time_12h_resp.text)['data']
for nft_obj in nft_address_list:
try:
nft_address = nft_obj['contract']['address']
holder_url = f'https://ethplorer.io/service/service.php?data={nft_address}&page=tab=tab-holders%26pageSize=500%26holders=1&showTx=all'
holder_resp = requests.get(holder_url,timeout=60,verify=False)
if(holder_resp.status_code == 200):
time.sleep(5)
resp_data = json.loads(holder_resp.text)
total = resp_data['pager']['holders']['total']
holder1 = resp_data['holders']
'''
id bigint(20) (NULL) NO PRI (NULL) auto_increment select,insert,update,references
name varchar(500) utf8_general_ci YES (NULL) select,insert,update,references
address varchar(500) utf8_general_ci YES (NULL) select,insert,update,references
balance varchar(500) utf8_general_ci YES (NULL) select,insert,update,references
contract_address varchar(500) utf8_general_ci YES (NULL) select,insert,update,references
owner varchar(500) utf8_general_ci YES (NULL) select,insert,update,references
time_type varchar(100) utf8_general_ci YES (NULL) select,insert,update,references
ct datetime (NULL) YES (NULL) select,insert,update,references
'''
name = resp_data['token']['name']
contract_address = resp_data['token']['address']
owner = resp_data['token']['owner']
time_type = time_type
ct = datetime.datetime.now().strftime('%Y-%m-%d')
num = math.ceil(total/500)
for n in range(2,num+1):
holder_url = f'https://ethplorer.io/service/service.php?data={nft_address}&page=tab=tab-holders%26pageSize=500%26holders={n}&showTx=all'
holder_resp = requests.get(holder_url,timeout=60,verify=False)
if (holder_resp.status_code == 200):
holder1 += json.loads(holder_resp.text)['holders']
time.sleep(5)
for h in holder1:
address = h['address']
balance = h['balance']
insert_sql = f'insert into nft_analytics (name,address,balance,contract_address,owner,time_type,ct) values ("'+name+'","'+address+'",'+str(balance)+',"'+contract_address+'","'+owner+'","'+time_type+'","'+ct+'")'
print(insert_sql)
mysql.execute_db(insert_sql)
except BaseException as e:
print(e)
if __name__ == '__main__':
spider_nft('1d')
import pymysql
class MysqlDb():
def __init__(self, host, port, user, passwd, db):
# 建立数据库连接
self.conn = pymysql.connect(
host=host,
port=port,
user=user,
passwd=passwd,
db=db
)
# 通过 cursor() 创建游标对象,并让查询结果以字典格式输出
self.cur = self.conn.cursor(cursor=pymysql.cursors.DictCursor)
def __del__(self): # 对象资源被释放时触发,在对象即将被删除时的最后操作
# 关闭游标
self.cur.close()
# 关闭数据库连接
self.conn.close()
def select_db(self, sql):
"""查询"""
# 使用 execute() 执行sql
self.cur.execute(sql)
# 使用 fetchall() 获取查询结果
data = self.cur.fetchall()
return data
def execute_db(self, sql):
"""更新/插入/删除"""
try:
# 使用 execute() 执行sql
self.cur.execute(sql)
# 提交事务
self.conn.commit()
except Exception as e:
print("操作出现错误:{}".format(e))
# 回滚所有更改
self.conn.rollback()
def getMysql():
try:
db = MysqlDb("127.0.0.1", 3306, "root", "root", "coin_project")
except BaseException as e:
print('初始化mysql失败:'+e)
return db
if __name__ == '__main__':
db = getMysql()
/*表: nft_analytics*/---------------------- /*列信息*/-----------
自增id id
nft名称 name
地址 address
持有nft数量 balance
nft合约地址 contract_address
nft合约创建地址 owner
时间类型 time_type
创建时间 ct Field Type Collation Null Key Default Extra Privileges Comment
---------------- ------------ --------------- ------ ------ ------- -------------- ------------------------------- ---------
id bigint(20) (NULL) NO PRI (NULL) auto_increment select,insert,update,references
name varchar(500) utf8_general_ci YES (NULL) select,insert,update,references
address varchar(500) utf8_general_ci YES (NULL) select,insert,update,references
balance int(255) (NULL) YES (NULL) select,insert,update,references
contract_address varchar(500) utf8_general_ci YES (NULL) select,insert,update,references
owner varchar(500) utf8_general_ci YES (NULL) select,insert,update,references
time_type varchar(100) utf8_general_ci YES (NULL) select,insert,update,references
ct datetime (NULL) YES (NULL) select,insert,update,references /*索引信息*/-------------- Table Non_unique Key_name Seq_in_index Column_name Collation Cardinality Sub_part Packed Null Index_type Comment Index_comment
------------- ---------- -------- ------------ ----------- --------- ----------- -------- ------ ------ ---------- ------- ---------------
nft_analytics 0 PRIMARY 1 id A 230789 (NULL) (NULL) BTREE /*DDL 信息*/------------ CREATE TABLE `nft_analytics` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(500) DEFAULT NULL,
`address` varchar(500) DEFAULT NULL,
`balance` int(255) DEFAULT NULL,
`contract_address` varchar(500) DEFAULT NULL,
`owner` varchar(500) DEFAULT NULL,
`time_type` varchar(100) DEFAULT NULL,
`ct` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=241992 DEFAULT CHARSET=utf8
爬取白鲸nft排名前25项目,持有nft大户地址数据。的更多相关文章
- Python爬虫【三】利用requests和正则抓取猫眼电影网上排名前100的电影
#利用requests和正则抓取猫眼电影网上排名前100的电影 import requests from requests.exceptions import RequestException imp ...
- Python爬取酷狗飙升榜前十首(100)首,写入CSV文件
酷狗飙升榜,写入CSV文件 爬取酷狗音乐飙升榜的前十首歌名.歌手.时间,是一个很好的爬取网页内容的例子,对爬虫不熟悉的读者可以根据这个例子熟悉爬虫是如何爬取网页内容的. 需要用到的库:requests ...
- Python的scrapy之爬取豆瓣影评和排名
基于scrapy框架的爬影评 爬虫主程序: import scrapy from ..items import DoubanmovieItem class MoviespiderSpider(scra ...
- 使用正则表达式和urllib模块爬取最好大学排名信息
题目 使用urllib模块编程实现爬取网站的大学排名. (网址:http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html) (1)获取网站页面,分析代 ...
- Python爬虫练习:爬取800多所大学学校排名、星级等
前言 国内大学最新排名,北大反超,浙大仅第四,中科大跌至第八 时隔五年,"双一流"大学即将迎来首次大考,这也是继改变高校评断标准之后,第一次即将以官方对外发布,自然是引来了许多人的 ...
- R语言爬虫:使用R语言爬取豆瓣电影数据
豆瓣排名前25电影及评价爬取 url <-'http://movie.douban.com/top250?format=text' # 获取网页原代码,以行的形式存放在web 变量中 web & ...
- 正则表达式和豆瓣Top250的爬取练习
datawhale任务2-爬取豆瓣top250 正则表达式 豆瓣250页面分析 完整代码 参考资料 正则表达式 正则表达式的功能用于实现字符串的特定模式精确检索或替换操作. 常用匹配模式 常用修饰符 ...
- python3 爬虫---爬取豆瓣电影TOP250
第一次爬取的网站就是豆瓣电影 Top 250,网址是:https://movie.douban.com/top250?start=0&filter= 分析网址'?'符号后的参数,第一个参数's ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 复仇者联盟3热映,我用python爬取影评告诉你它都在讲什么
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象.直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定.它包含了一组完善而且容易理 ...
随机推荐
- php 实现CURL请求接口
$ch = curl_init (); //初始化 @curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); // 跳过证书检查 @curl_setopt($ ...
- Django路由重定向
路由重定向又称HTTP协议重定向,也可以称为网页跳转,它对应的HTTP状态码为301.302.303.307.308. 网页重定向就是在浏览器访问某个网页的时候,这个网页不提供响应内容,而是自动跳转到 ...
- 富文本编辑器第一次正常显示,第二次渲染失败 -----在使用laravel-admin 时
第二次显示 解决方法: 在每次获取富文本编辑器实例的时候,先删除一下,避免之前已经实例化造成的渲染失败
- 蓝牙mesh组网实践(节点功能介绍)
目录 未配网设备在配好网,被纳入网络后,可称之为节点. 蓝牙mesh网络中,节点可以有选择地支持四大功能--朋友.低功耗.转发.代理功能,可以复用多个功能(由于单片机硬件限制,ch582除了复用转发功 ...
- pytorch学习笔记(9)--神经网络模型的保存与读取
一.网络模型的保存和加载 1.网络模型保存方法1 import torch import torchvision vgg16 = torchvision.models.vgg16(weights=Fa ...
- winform 中 label透明化
label1.BackColor = Color.Transparent;//设置背景颜色为透明 label1.Parent = pictureBox1;//将pictureBox1设为标签的父控件, ...
- [转载]Linux关于磁盘操作命令
一.查看篇 1.1.du : 查看文件和 目录的使用空间 语法: du [参数] [文件或目录] 参数 说明 -a 列出所有的文件与目录容量. -h 以G.M.K为单位,返回容量. -s 列出总量. ...
- SDN之Openflow+OpenDayLight课程开课通知
内容简介: 该课程为期2天,在这两天里 我们将会深入体会SDN的特点与传统网络的区别 ,掌握SDN架构里各层的协议用途,Openflow作为sdn里的一款开源的南向协议,最大的意义体现在它实现了网络设 ...
- Java程序(数组扩容的尝试)
import java.util.Scanner; public class ArrayAdd { public static void main(String[] args) { int arr[] ...
- 光盘实现半自动化安装linux以及PXE实现自动安装
重点 实验一:使用 kickstart 半自动化安装CentOS系统 可以将定制安装光盘,并结合kickstart实现基于光盘启动的半自动化安装 实现过程 首先下载httpd搭建个web网页 [ro ...