Zero-Shot Temporal Action Detection via Vision-Language Prompting概述
1.针对的问题
现有的方法在推断时只能识别之前见过的类别,即训练时出现过的类别,而为每个感兴趣的类收集和注释大型训练集是昂贵的。
2.主要贡献
(1)研究了如何利用大量预训练的ViL模型进行未修剪视频中的zero-shot时序动作定位(ZS-TAD)的问题。
(2)提出了一种新的one-stage分类定位模型STALE,该模型在并行分类和定位设计的同时引入了一个可学习的class-agnostic掩码组件,以实现zero-shot迁移到未见过的类。为了增强跨模态任务的自适应能力,在Transformer框架中引入了流间对齐正则化。
(3)在标准ZS-TAD视频基准上的大量实验表明,STALE优于最先进的类似方法,通常有很大的优势。此外,模型也可以应用于全监督TAD设置,并取得比最近的其他工作更优越的性能。
3.方法
主要特点是采用并行定位(掩码生成)和分类结构,以解决传统ZS-TAD模型的定位误差传播问题
模型结构如下:
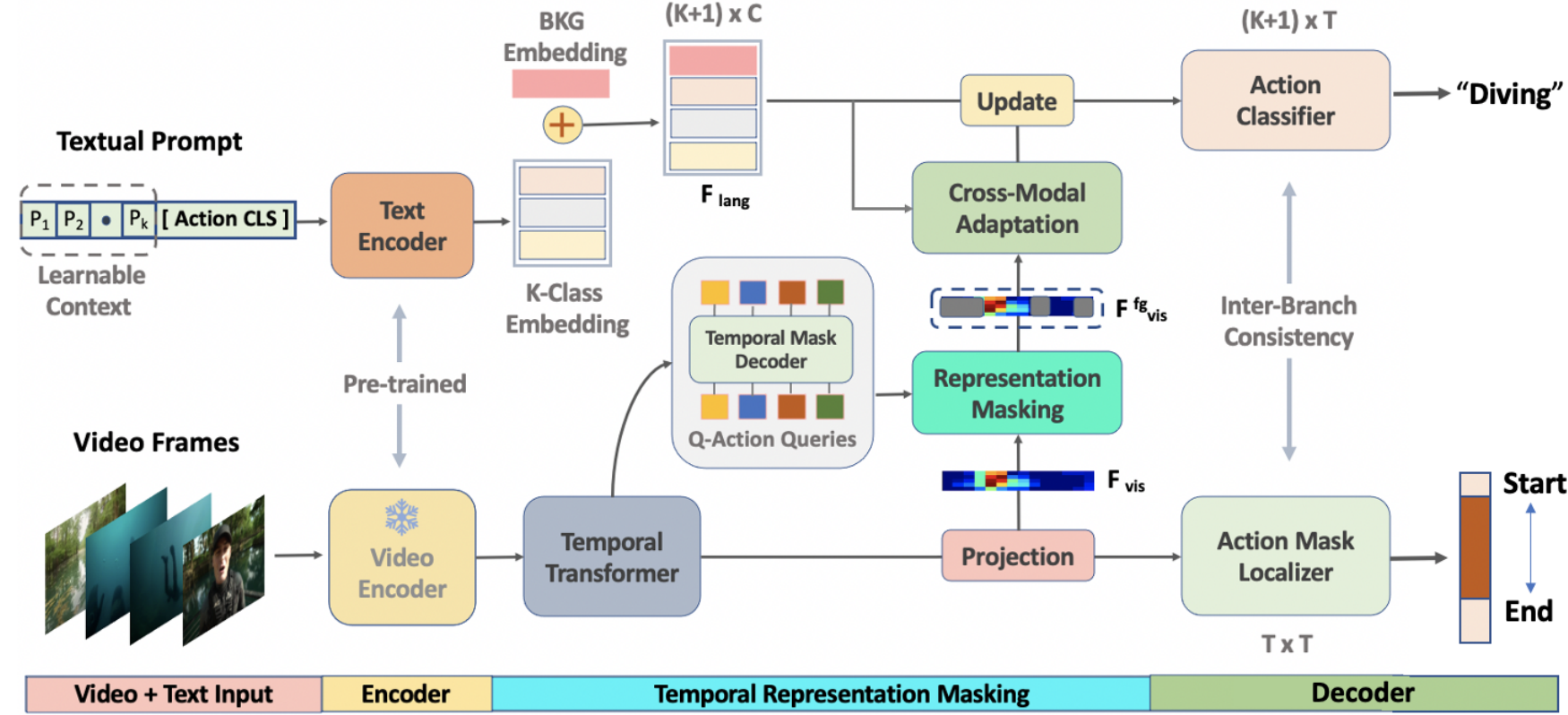
给定一个未裁剪的视频V,首先通过预训练的冻结视频编码器提取一组T个片段特征序列,包括RGB Xr ∈Rd×T和光流特征Xo ∈Rd×T,然后将它们连接为E = [Xr;Xo]∈R2d×T。虽然E(论文中是F,但是个人感觉这里应该是E)包含局部时空信息,但它缺乏对TAD至关重要的全局上下文,作者利用自注意力机制来学习全局上下文,将多头注意力编码器Τ()的输入(查询,键,值)设置为特征(E,E,E)得到最终的视频片段嵌入Fvis。
对于文本上下文,将其输入文本编码器,即带有可学习的提示的标准CLIP预训练的Transformer,得到嵌入Gke∈RC',由于背景类的文本嵌入不能直接从CLIP词汇表中获得,所以学习一个特定的背景嵌入,表示为Gbge∈RC',将其附加到嵌入的动作类Gke,得到包含K+1类的嵌入Flan。以上组成了输入和编码部分。
然后是时序表示掩码部分。将Fvis(代码中这里是E)输入一个transformer解码器来生成Nz潜在嵌入,然后将每个潜在嵌入通过一个掩码投影层(从代码中看是一个MLP),得到每个片段的掩码嵌入Bq ∈Rq×C,其中q代表query,将Bq与Fvis(图中的投影层论文中似乎并没有介绍)相乘再通过sigmoid函数得到关于每个查询的一个二进制预测Lq,将Lq输入一个线性层和sigmoid函数得到 (代码中好像没有这个线性层),在阈值θbin处对这个掩码进行二值化,并选择前景掩码,用
(代码中好像没有这个线性层),在阈值θbin处对这个掩码进行二值化,并选择前景掩码,用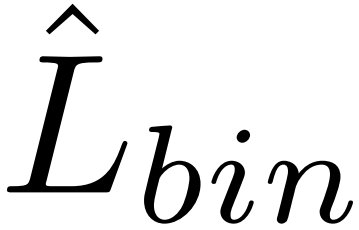 表示,使用检索嵌入Fvis的片段,获得前景特征Ffgvis。
表示,使用检索嵌入Fvis的片段,获得前景特征Ffgvis。
将Ffgvis和Flan输入跨模态自适应模块,该模块由自注意层,co-attention层和前馈网络组成,公式为: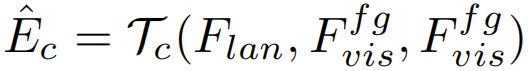 ,其中Tc为transformer层,以Flan为查询,Fvisfg为键和值。该模块鼓励文本特征在前景片段中找到最相关的视觉线索。然后,通过残差连接Flan和
,其中Tc为transformer层,以Flan为查询,Fvisfg为键和值。该模块鼓励文本特征在前景片段中找到最相关的视觉线索。然后,通过残差连接Flan和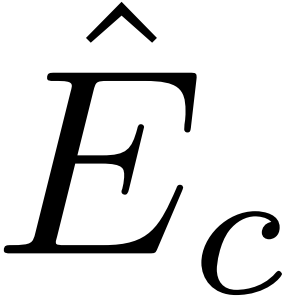 更新文本特征得到
更新文本特征得到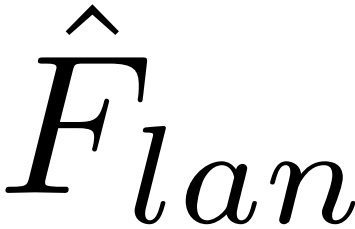 。
。
最后是解码部分,该部分包括并行的分类流和定位流,定位流将Fvis输入动作掩码定位器,即3个(代码中是2个)1-D动态卷积层Hm的叠加,得到M,M的第t列是通过第t个片段进行的时序掩码预测。分类流的动作分类为器将更新后的文本特征和掩码前景特征Fvisfg相乘得到分类输出P∈R(K+1)×T,其中每个片段定位t∈T被赋予一个概率分布pt∈R(K+1)×1。
类标签和掩码标签在前景方面有结构上的一致性,通过一致性损失来利用这种一致性,表示为 ,
,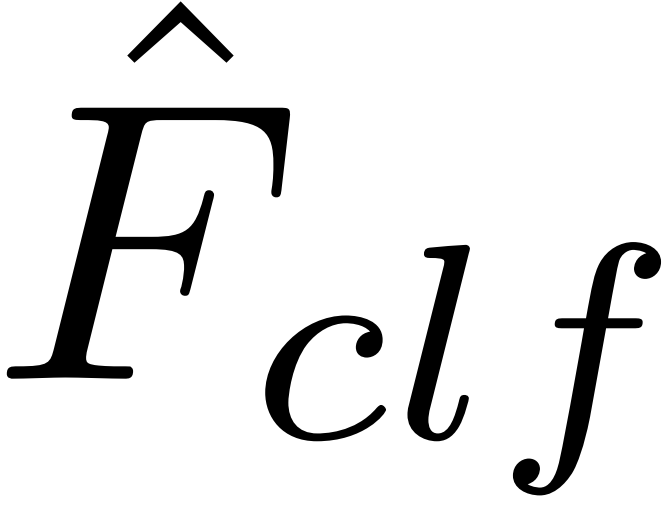 = topk(argmax((Pbin∗Ep)[: K,:]))是从阈值分类得到的得分最高的前景片段中获得的特征,输出Pbin := η(p−θc)与θc 阈值,将嵌入E传递到一个1D conv层得到Ep,用于匹配p的维度。从掩码输出M中获得的最高评分特征类似于:
= topk(argmax((Pbin∗Ep)[: K,:]))是从阈值分类得到的得分最高的前景片段中获得的特征,输出Pbin := η(p−θc)与θc 阈值,将嵌入E传递到一个1D conv层得到Ep,用于匹配p的维度。从掩码输出M中获得的最高评分特征类似于: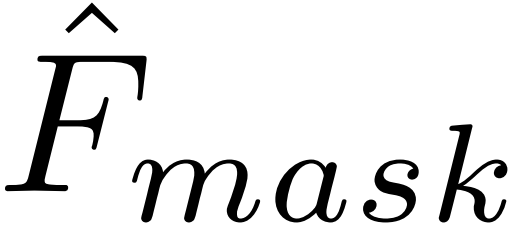 = topk(σ(1DPool(Em * Mbin))),其中Mbin:= η(M−θm)是掩码预测M的二值化,Em通过将嵌入E传递到一维conv层以匹配维数M得到,σ为sigmoid激活函数。
= topk(σ(1DPool(Em * Mbin))),其中Mbin:= η(M−θm)是掩码预测M的二值化,Em通过将嵌入E传递到一维conv层以匹配维数M得到,σ为sigmoid激活函数。
Zero-Shot Temporal Action Detection via Vision-Language Prompting概述的更多相关文章
- Temporal Action Detection with Structured Segment Networks (ssn)【转】
Action Recognition: 行为识别,视频分类,数据集为剪辑过的动作视频 Temporal Action Detection: 从未剪辑的视频,定位动作发生的区间,起始帧和终止帧并预测类别 ...
- 论文笔记之 SST: Single-Stream Temporal Action Proposals
SST: Single-Stream Temporal Action Proposals 2017-06-11 14:28:00 本文提出一种 时间维度上的 proposal 方法,进行行为的识别.本 ...
- 论文阅读: End-to-end Learning of Action Detection from Frame Glimpses in Videos
End-to-End Learning of Action Detection from Frame Glimpses in Videos CVPR 2016 Motivation: 本 ...
- TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals(ICCV2017)
Motivation 实现快速和准确地抽取出视频中的语义片段 Proposed Method -提出了TURN模型预测proposal并用temporal coordinate regression来 ...
- SST:Single-Stream Temporal Action Proposals论文笔记
SST:Single-Stream Temporal Action Proposals 这是本仙女认认真真读完且把算法全部读懂(其实也不是非常懂)的第一篇论文 CVPR2017 一作 论文写作的动机m ...
- Background Suppression Network for Weakly-supervised Temporal Action Localization [Paper Reading]
研究内容:弱监督时域动作定位 结果:Thumos14 mAP0.5 = 27.0 ActivityNet1.3 mAP0.5 = 34.5 从结果可以看出弱监督这种瞎猜的方式可以PK掉早些时候的一些全 ...
- CTAP: Complementary Temporal Action Proposal Generation论文笔记
主要观点:基于sliding window(SW)类的方法,如TURN,可以达到很高的AR,但定位不准:基于Group的方法,如TAG,AR有明显的上界,但定位准.所以结合两者的特长,加入Comple ...
- CTAP: Complementary Temporal Action Proposal Generation (ECCV2018)
互补时域动作提名生成 这里的互补是指actionness score grouping 和 sliding window ranking这两种方法提proposal的结合,这两种方法各有利弊,形成互补 ...
- C 语言高效编程的几招——A few action of efficient C language programming
编写高效简洁的C 语言代码,是许多软件工程师追求的目标.本文就工作中的一些体会和经验做相关的阐述,不对的地方请各位指教. 第1 招:以空间换时间 计算机程序中最大的矛盾是空间和时间的矛盾,那么,从这个 ...
- LPAT: Learning to Predict Adaptive Threshold for Weakly-supervised Temporal Action Localization [Paper Reading]
Motivation: 阈值分割的阈值并没有通过模型训练学出来,而是凭借主观经验设置,本文通过与背景得分比较提取对应的proposal,不用阈值的另一篇文章是Shou Zheng的AutoLoc,通过 ...
随机推荐
- 数值分析之数值积分 4.X
求积公式 \[\int_{a}^{b} f(x) \mathrm{d} x \approx \sum_{k=0}^{n} A_{k} f\left(x_{k}\right) \] \(A_k\) 为求 ...
- doskey: windows版 Alias
1.编辑doskey.bat文件 2.打开注册表寻找.HKEY_CURRENT_USER \ Software \ Microsoft \ Command Processor (自行百度) 3.添加d ...
- kubeSphere+kubernetes 集群更新证书
模拟问题点 使用kubernetes时错误提示 yang@master:~$ kubectl get nodes Unable to connect to the server: x509: cert ...
- Angular单页应用程式 (SPA)+Azure AD重新导向登入
一.app.module.ts中设定应用程式 1.将MSAL Angular相关设置封装为auth.module.ts import { NgModule } from '@angular/core' ...
- 华为&思科设备默认的路由协议优先级
华为&思科设备默认的路由协议优先级 华为设备默认路由协议优先级 在华为的设备中,路由器分别定义了外部优先级和内部优先级. 外部优先级是指用户可以手工为各路由协议配置的优先级; 内部优先级不能被 ...
- mysql5.7 不兼容问题
通过navicat工具导入psc数据库备份文件,报错如下,mysql版本5.7 执行如下语句不通过 DROP TABLE IF EXISTS `guard_user`; CREATE TABLE `g ...
- 一加5T刷入魔趣
0.准备工作 1.安装adb工具 2.下载twrp 3.5t系统包. 1.解锁bootloader 先进入原版系统,打开开发者选项,允许USB调试,勾选允许OEM解锁,高级重启选项 打开命令行输入: ...
- potoshop制作一寸照片
potoshop制作一寸照片 经常因为各种原因需要提供1寸照片,第一反应应还是跑照相馆专业.但是疫情封闭在家怎么高,刚好把偶尔使用一次的potoshop用起来,解决照片制作问题,一来能省几毛钱买茶叶蛋 ...
- ScrollView 滚动条
<style name="fa_SlideTabRecyclerView"> <item name="android:scrollbarThumbVer ...
- JVM系列(三):JVM内存结构和参数说明
一.概述,内存结构图 二.堆Heap,存放对象实例,是垃圾回收的主要区域,非堆的内存不进行GC,GC会导致程序运行中断, 物理上可以不连续,堆空间不足时会产生OutOfMemoryException, ...