使用 LoRA 进行 Stable Diffusion 的高效参数微调
LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题。目前超过数十亿以上参数的具有强能力的大模型 (例如 GPT-3) 通常在为了适应其下游任务的微调中会呈现出巨大开销。 LoRA 建议冻结预训练模型的权重并在每个 Transformer 块中注入可训练层 (秩-分解矩阵)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了 GPU 的内存要求。研究人员发现,通过聚焦大模型的 Transformer 注意力块,使用 LoRA 进行的微调质量与全模型微调相当,同时速度更快且需要更少的计算。
用于 Diffusers 的 LoRA
尽管 LoRA 最初是为大模型提出的,并在 transformer 块上进行了演示,但该技术也可以应用于其他地方。在微调 Stable Diffusion 的情况下,LoRA 可以应用于将图像表示与描述它们的提示相关联的交叉注意层。下图的细节 (摘自 Stable Diffusion 论文) 并不重要,只需要注意黄色块是负责建立图文之间的关系表示就行。
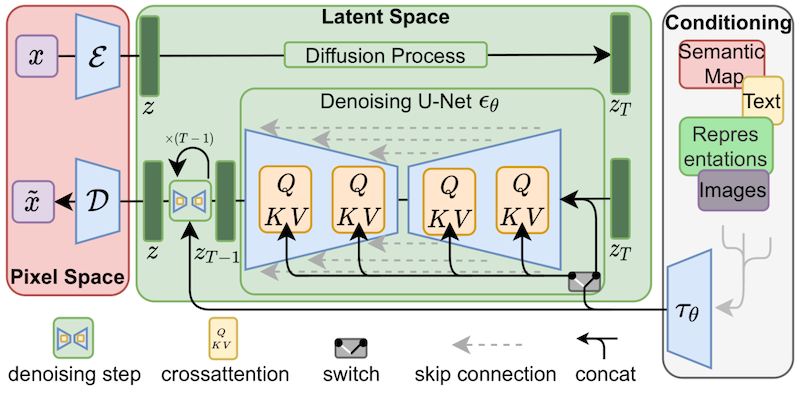
据我们所知,Simo Ryu (GitHub 用户名 @cloneofsimo) 是第一个提出适用于 Stable Diffusion 的 LoRA 实现的人。如果想查看相关示例和许多其他有趣的讨论和见解。请一定要看看 他们的 GitHub 项目。
为了将 LoRA 的可训练矩阵注入到与交叉注意力层一样深的模型中,过去人们需要以富有想象力 (但脆弱) 的方式破解 diffusers 的源代码。如果 Stable Diffusion 向我们展示了一件事,那就是社区总是会想出办法来改变和调整模型以达到创造性目的,我们喜欢这样!由于许多其他原因,提供操纵交叉注意力层的灵活性可能是有益的,例如更容易采用 xFormers 等优化技术。 Prompt-to-Prompt 等其他创意项目可以使用一些简单的方法来访问这些层,因此我们决定 为用户提供一种通用的方法来做到这一点。自 12 月下旬以来,我们一直在测试,并在我们的 diffusers 中正式发布。
我们一直在与 @cloneofsimo 合作,为 Dreambooth 和全微调方法提供 Diffusions 中的 LoRA 训练支持!这些技术提供了以下好处:
- 更快的训练速度
- 计算要求较低。我们可以在具有 11 GB VRAM 的 2080 Ti 中创建一个全微调模型!
- 小了很多的训练模型。由于原始模型已冻结,我们注入了新层进行训练,因此我们可以将新层的权重保存为大小约为 3 MB 的单个文件。这比 UNet 模型的原始大小小一千倍
我们对最后一点特别兴奋。为了让用户分享他们出色的微调或 dreamboothed 模型,他们必须分享最终模型的完整副本。其他想要试用它们的用户必须在他们最喜欢的 UI 中下载经过微调的权重,这会增加大量存储和下载成本。截至今天,大约有 1,000 个 Dreambooth 模型在 Dreambooth 概念库中注册,可能还有更多未在库中注册。
使用 LoRA,现在可以发布 单个 3.29 MB 文件 以允许其他人使用你的微调模型。
(感谢 GitHub 用户 @mishig25,他是我了解到的首个在平常对话中将 dreamboothing 作为动词的人)。
LoRA 微调
Stable Diffusion 的全模型微调过去既缓慢又困难,这也是 Dreambooth 或 Textual Inversion 等轻量级方法变得如此流行的部分原因。使用 LoRA,在自定义数据集上微调模型要容易得多。
Diffusers 现在提供了一个 LoRA 微调脚本,可以在低至 11 GB 的 GPU RAM 中运行而无需借助到诸如 8-bit 优化器之类的技巧。这里展示了您如何借助它来使用 Lambda Labs Pokémon 数据集 微调模型:
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="/sddata/finetune/lora/pokemon"
export HUB_MODEL_ID="pokemon-lora"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--dataloader_num_workers=8 \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=15000 \
--learning_rate=1e-04 \
--max_grad_norm=1 \
--lr_scheduler="cosine" --lr_warmup_steps=0 \
--output_dir=${OUTPUT_DIR} \
--push_to_hub \
--hub_model_id=${HUB_MODEL_ID} \
--report_to=wandb \
--checkpointing_steps=500 \
--validation_prompt="Totoro" \
--seed=1337
这里需要注意的一件事是学习率为“1e-4”,远大于常规微调的通常学习率(通常为“~1e-6”的数量级)。这是上次运行的 W&B dashboard,在 2080 Ti GPU (11 GB 内存)。我没有尝试优化超参数,所以请自行尝试!Sayak 在 T4 (16 GB 内存) 上又跑了一次,这是 他的最终模型,这里是 使用它的演示空间。

有关 diffusers 中 LoRA 支持的更多详细信息,请参阅 我们的文档——它将始终与实现保持同步。
推理
正如我们所讨论的,LoRA 的主要优势之一是您可以通过训练比原始模型大小少几个数量级的权重来获得出色的结果。我们设计了一个推理过程,允许在未修改的 Stable Diffusion 模型权重之上加载额外的权重。让我们看看它是如何工作的。
首先,我们将使用 Hub API 自动确定用于微调 LoRA 模型的基本模型是什么。从 Sayak的模型 开始,我们可以使用这段代码:
from huggingface_hub import model_info
# LoRA weights ~3 MB
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
info = model_info(model_path)
model_base = info.cardData["base_model"]
print(model_base) # CompVis/stable-diffusion-v1-4
此代码段将打印他用于微调的模型,即“CompVis/stable-diffusion-v1-4”。就我而言,我从 Stable Diffusion 1.5 版开始训练我的模型,因此如果您使用 我的 LoRA 模型 运行相同的代码,您会看到输出是 runwayml/stable-diffusion-v1-5。
如果您使用 --push_to_hub 选项,我们在上一节中看到的微调脚本会自动填充有关基本模型的信息。正如您在 pokemon-lora 的介绍文档 中所见,这被记录为模型存储库的“自述文件”文件中的元数据标签。
在我们确定了用于使用 LoRA 进行微调的基础模型之后,我们加载了一个正常的稳定扩散管道。我们将使用 DPMSolverMultistepScheduler 对其进行自定义,以实现非常快速的推理:
import torch
from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler
pipe = StableDiffusionPipeline.from_pretrained(model_base, torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
神奇的地方来了。我们从 hub 加载 LoRA 权重 在常规模型权重之上,将 pipline 移动到 cuda 设备并运行推理:
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
image = pipe("Green pokemon with menacing face", num_inference_steps=25).images[0]
image.save("green_pokemon.png")
用 LoRA 进行 Dreamboothing
Dreambooth 允许您向 Stable Diffusion 模型“教授”新概念。 LoRA 与 Dreambooth 兼容,过程类似于微调,有几个优点:
- 训练更快。
- 我们只需要几张我们想要训练的主题的图像 (通常 5 或 10 张就足够了)。
- 如果需要,我们可以调整文本编码器,以提高对训练主体的保真度。
要使用 LoRA 训练 Dreambooth,您需要使用 此 diffusers 脚本。请看一下 README、文档 和 我们的超参数探索博文 了解详细信息.
其他方法
对轻松微调的追求并不新鲜。除了 Dreambooth 之外,textual inversion 是另一种流行的方法,它试图向训练有素的稳定扩散模型教授新概念。使用 Textual Inversion 的主要原因之一是经过训练的权重也很小且易于共享。然而,它们只适用于单个主题 (或一小部分主题),而 LoRA 可用于通用微调,这意味着它可以适应新的领域或数据集。
Pivotal Tuning 是一种尝试将 Textual Inversion 与 LoRA 相结合的方法。首先,您使用 textual inversion 技术向模型教授一个新概念,获得一个新的标记嵌入来表示它。然后,您使用 LoRA 训练该 token 嵌入以获得两全其美。
我们还没有使用 LoRA 探索过 Pivotal Tuning。欢迎挑战?
英文原文: https://huggingface.co/blog/lora
原文作者: Pedro Cuenca, Sayak Paul
中文译者: innovation64 (李洋)
审校: zhongdongy (忠东)
使用 LoRA 进行 Stable Diffusion 的高效参数微调的更多相关文章
- NLP突破性成果 BERT 模型详细解读 bert参数微调
https://zhuanlan.zhihu.com/p/46997268 NLP突破性成果 BERT 模型详细解读 章鱼小丸子 不懂算法的产品经理不是好的程序员 关注她 82 人赞了该文章 Goo ...
- PID参数整定快速入门(调节器参数整定方法)
PID调节器参数整定方法很多,常见的工程整定方法有临界比例度法.衰减曲线法和经验法.云润仪表以图文形式分别介绍调节器参数整定方法. 临界比例度法一个调节系统,在阶跃干扰作用下,出现既不发散也不衰减的等 ...
- PID参数整定
PID参数整定方法很多,常见的工程整定方法有临界比例度法.衰减曲线法和经验法.云南昌晖仪表制造有限公司以图文形式介绍以临界比例度法和衰减曲线法整定调节器PID参数方法.临界比例度法一个调节系统,在阶跃 ...
- 从NLP任务中文本向量的降维问题,引出LSH(Locality Sensitive Hash 局部敏感哈希)算法及其思想的讨论
1. 引言 - 近似近邻搜索被提出所在的时代背景和挑战 0x1:从NN(Neighbor Search)说起 ANN的前身技术是NN(Neighbor Search),简单地说,最近邻检索就是根据数据 ...
- prometheus-operator 详细总结(helm一键安装)
一.介绍prometheus-operator 二.查看配置rbac授权 三.helm安装prometheus-operator 四.配置监控k8s组件 五.granafa添加新数据源 六.监控mys ...
- [Deep-Learning-with-Python]计算机视觉中的深度学习
包括: 理解卷积神经网络 使用数据增强缓解过拟合 使用预训练卷积网络做特征提取 微调预训练网络模型 可视化卷积网络学习结果以及分类决策过程 介绍卷积神经网络,convnets,深度学习在计算机视觉方面 ...
- [Deep-Learning-with-Python]机器学习基础
机器学习类型 机器学习模型评估步骤 深度学习数据准备 特征工程 过拟合 解决机器学习问题的一般性流程 机器学习四分支 二分类.多分类以及回归问题都属于监督学习--目标是学习训练输入和对应标签之间的关系 ...
- 局部敏感哈希-Locality Sensitivity Hashing
一. 近邻搜索 从这里开始我将会对LSH进行一番长篇大论.因为这只是一篇博文,并不是论文.我觉得一篇好的博文是尽可能让人看懂,它对语言的要求并没有像论文那么严格,因此它可以有更强的表现力. 局部敏感哈 ...
- 【swupdate文档 三】SWUpdate: 嵌入式系统的软件升级
SWUpdate: 嵌入式系统的软件升级 概述 本项目被认为有助于从存储媒体或网络更新嵌入式系统.但是,它应该主要作为一个框架来考虑,在这个框架中可以方便地向应用程序添加更多的协议或安装程序(在SWU ...
- 影像优化 OptimizeRaster工具包介绍
Esri OptimizeRasters是一个高效.可配置的开源工具包. OptimizeRasters提供了以下功能: 影像格式转换和压缩.支持输出优化栅格格式:MRF.分块TIFF.云存储优化Ge ...
随机推荐
- 国产图形化的msf——Viper初体验
目录 免责声明: Viper简介 安装 使用 免责声明: 本文章仅供学习和研究使用,严禁使用该文章内容对互联网其他应用进行非法操作,若将其用于非法目的,所造成的后果由您自行承担,产生的一切风险与本文作 ...
- nginx rewrite参数 以及 $1、$2参数解析(附有生产配置实例)
在nginx的配置中,是否对rewrite的配置模糊不清,还有令人迷惑的$1.$2...参数,(其实$1.$2参数在shell脚本中经常用到,用来承接传递的参数).本篇从反向代理配置的角度帮助理解一下 ...
- 【RocketMQ】顺序消息实现原理
全局有序 在RocketMQ中,如果使消息全局有序,可以为Topic设置一个消息队列,使用一个生产者单线程发送数据,消费者端也使用单线程进行消费,从而保证消息的全局有序,但是这种方式效率低,一般不使用 ...
- python中调用C代码
首先我们需要明晰为什么我们需要在python中调用C语言的代码,原因不外乎有二: 其一,python不擅长"大量运算"任务,而擅长于编写简单,"IO密集型作业" ...
- 【书籍知识回顾与总结-2022】Java语言重点知识-多线程编程、流式编程
一.多线程编程 二.流式编程 1.目的 简化集合和数组的操作 注意:每个流只能使用一次 2.获取流的方式 (1)单列集合:stream方法 KeySet()/values()/EntrySet() ( ...
- C++日期和时间编程总结
一,概述 二,C-style 日期和时间库 2.1,数据类型 2.2,函数 2.3,数据类型与函数关系梳理 2.4,时间类型 2.4.1,UTC 时间 2.4.2,本地时间 2.4.3,纪元时间 2. ...
- 微服务11:熔断、降级的Hystrix实现(附源码)
微服务1:微服务及其演进史 微服务2:微服务全景架构 微服务3:微服务拆分策略 微服务4:服务注册与发现 微服务5:服务注册与发现(实践篇) 微服务6:通信之网关 微服务7:通信之RPC 微服务8:通 ...
- 6、发送验证码功能(Redis)
一.业务需求: 1.后端随机生成短信验证码,并在服务器端保存一定时间(redis): 2.将短信验证码发给用户: 3.用户输入短信验证码提交后,在后端与之前生成的短信验证码作比较,如果相同说明验证成功 ...
- 学会了selenium 模拟鼠标操作,你就可以偷懒点点点了
前言 我们在做 Web 自动化的时候,有时候页面的元素不需要我们点击,值需要把鼠标移动上去就能展示各种信息. 这个时候我们可以通过操作鼠标来实现,接下来我们来讲一下使用 selenium 做 Web ...
- [ 赛后总结 ] CSP-J 2022
前言 今年没考好,估分 100+60+0+10=170pts ,大概能混个2=,没什么用. 这下好了,期中也砸了,已经排到全校 30 开外了,果然鱼和熊掌不可兼得,况且我双双落空,接下来怕是想搞也搞不 ...