MoCo V1:视觉领域也能自监督啦
何凯明从 CVPR 2020 上发表的 MoCo V1(Momentum Contrast for Unsupervised Visual Representation Learning),到前几天挂在arxiv上面的 MoCo V3(An Empirical Study of Training Self-Supervised Visual Transformers),MoCo一共走过了三个版本。
今天介绍 MoCo 系列第一版 MoCo v1 就是在 SimCLR 发表前经典的图像自监督学习方法,MoCo v1 和 v2 是针对 CNN 设计的,而 MoCo v3 是针对 Transformer 结构设计的,反映了 MoCo 系列对视觉模型的普适性。
[TOC]
自监督学习 Self-Supervised Learning
一般机器学习分为有无监督学习,无监督学习和强化学习。而自监督学习(Self-Supervised Learning)是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。而在视觉模型中,MoCo 之所以经典是创造出了一个固定的视觉自监督的模式:
Unsupervised Pre-train, Supervised Fine-tune.
预训练模型使用自监督方法,下游任务使用监督方法微调
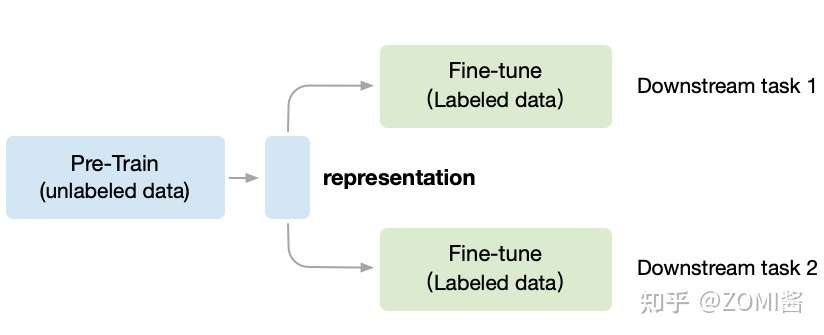
对应图中,预训练阶段使用无标签的数据集 (unlabeled data),因为带标签的(labeled data)数据收集非常昂贵,需要大量的新一代农民工去标注,成本是相当高。 相反,无标签的数据集收集很方便,不需要大量的新一代农民工。

在无监督CV领域,第一阶段叫做in a task-agnostic way,在训练模型参数的时候,Self-Supervised Learning 就想不用带标签的数据,先把初始化网络模型的权重参数训练到基本可用,得到一个中间权重参数结果,我们把它叫做 Visual Representation。
第二阶段叫做in a task-specific way,根据下游任务 (Downstream Tasks) 使用带标签的数据集把参数训练到精度达标,这时使用的数据集量就不用太多了,因为参数经过了阶段一的预训练啦。
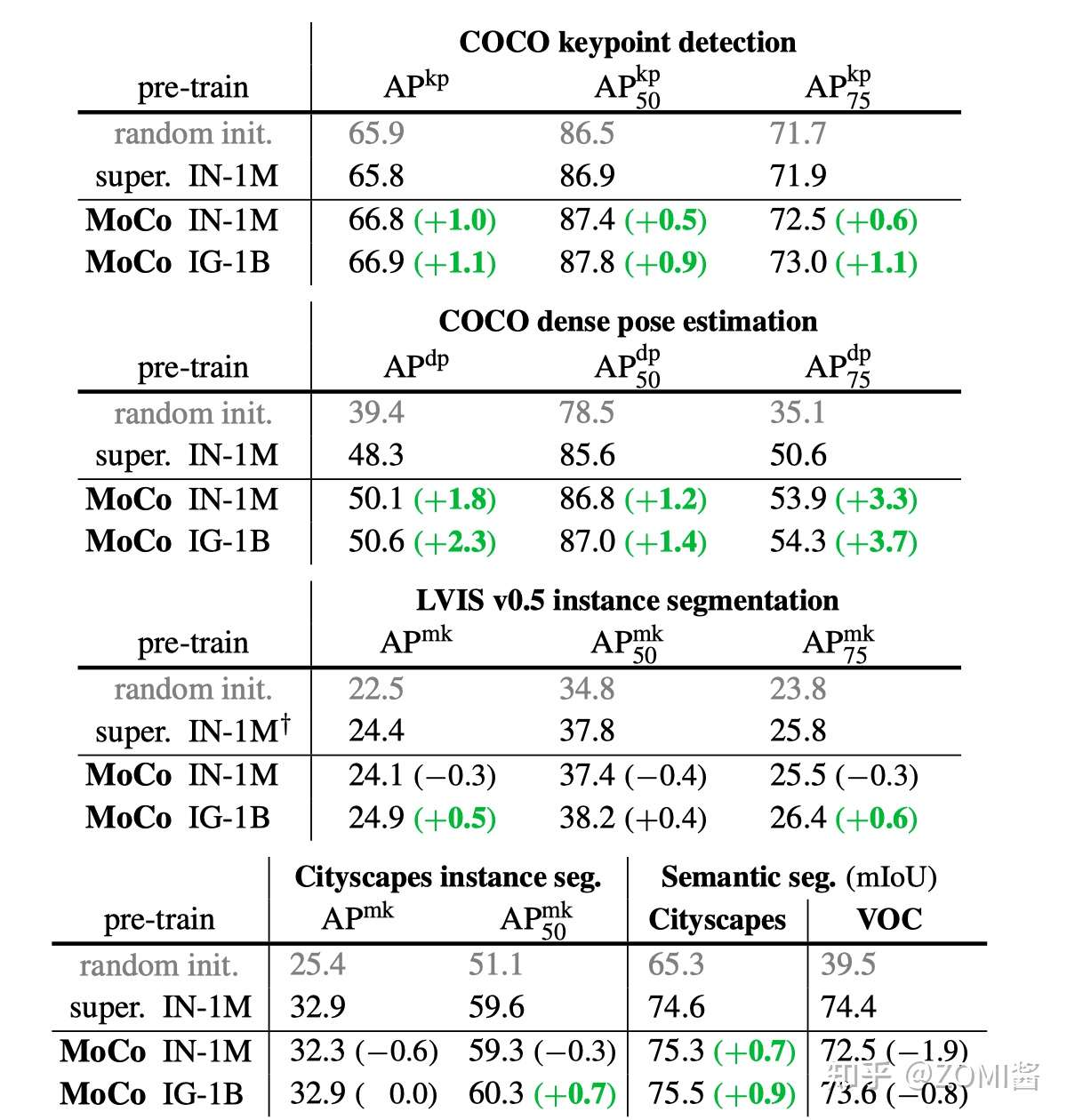
MoCo 遵循这个思想,预训练的 MoCo 模型也会得到 Visual Representation,然后通过 Fine-tune 以适应各种各样的下游任务(比如目标检测、语义分割等)。下面图中的实验结果表明,MoCo在 7 个检测/语义分割任务(PASCAL VOC, COCO, 其他的数据集)上可以超过了监督学习训练版本。
自监督学习的关键可以概括为两点:Pretext Task,Loss Function,在下面分别介绍。
Contrastive loss
Contrastive loss 来自于 2006年 Yann LeCun 组的工作(Dimension- ality reduction by learning an invariant mapping)。
Contrastive loss 的思想是想让:1)相近的样本之间的距离越小越好。2)不似样本之间的距离如果小于m,则通过互斥使其距离接近m。文章对第二个点有个形象的解释,就像长度为m的弹簧,如果它被压缩,则会因为斥力恢复到长度m。
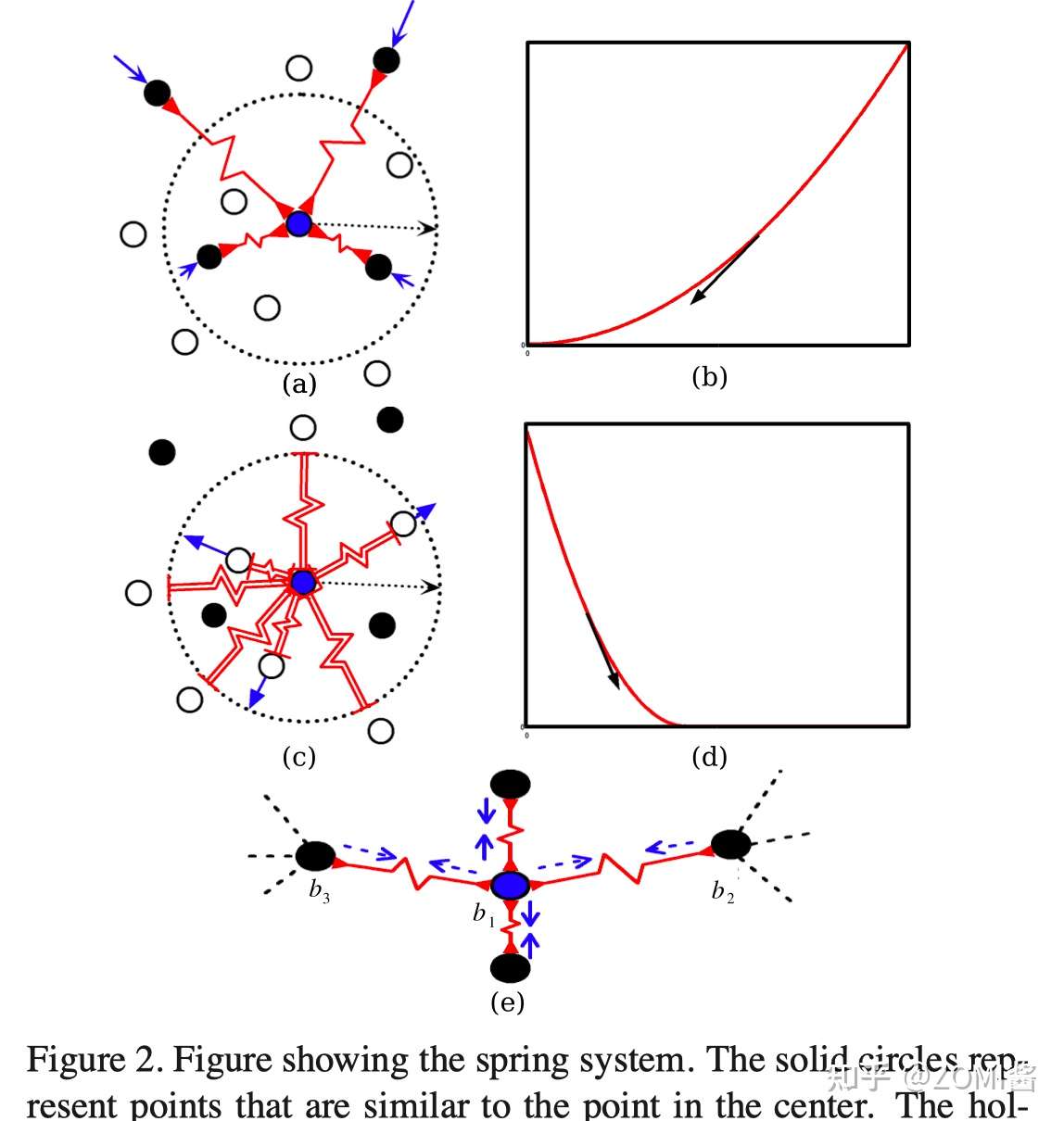
其中 W 是网络权重;Y 是成对标签,如果 X1,X2 这对样本属于同一个类,Y=0,属于不同类则 Y=1。Dw 是 X1 与 X2 在潜变量空间的欧几里德距离。当 Y=0,调整参数最小化X1与X2 之间的距离。当 Y=1,如果 X1与X2 之间距离大于 m,则不做优化;如果 X1 与 X2 之间的距离小于 m, 则增大两者距离到 m。
最后的实际效果就像论文给出的实验结果,训练完后在Mnist手写字体数据集上4和9明确的分开出来了。

Pretext Task
Pretext Task(译作:借口、托辞)是无监督学习领域的一个常见的术语,专指通过完成暂时的任务A,能够对后续的任务B、C、D有帮助。下面针对NLP和CV有两种主要的Pretext模式。
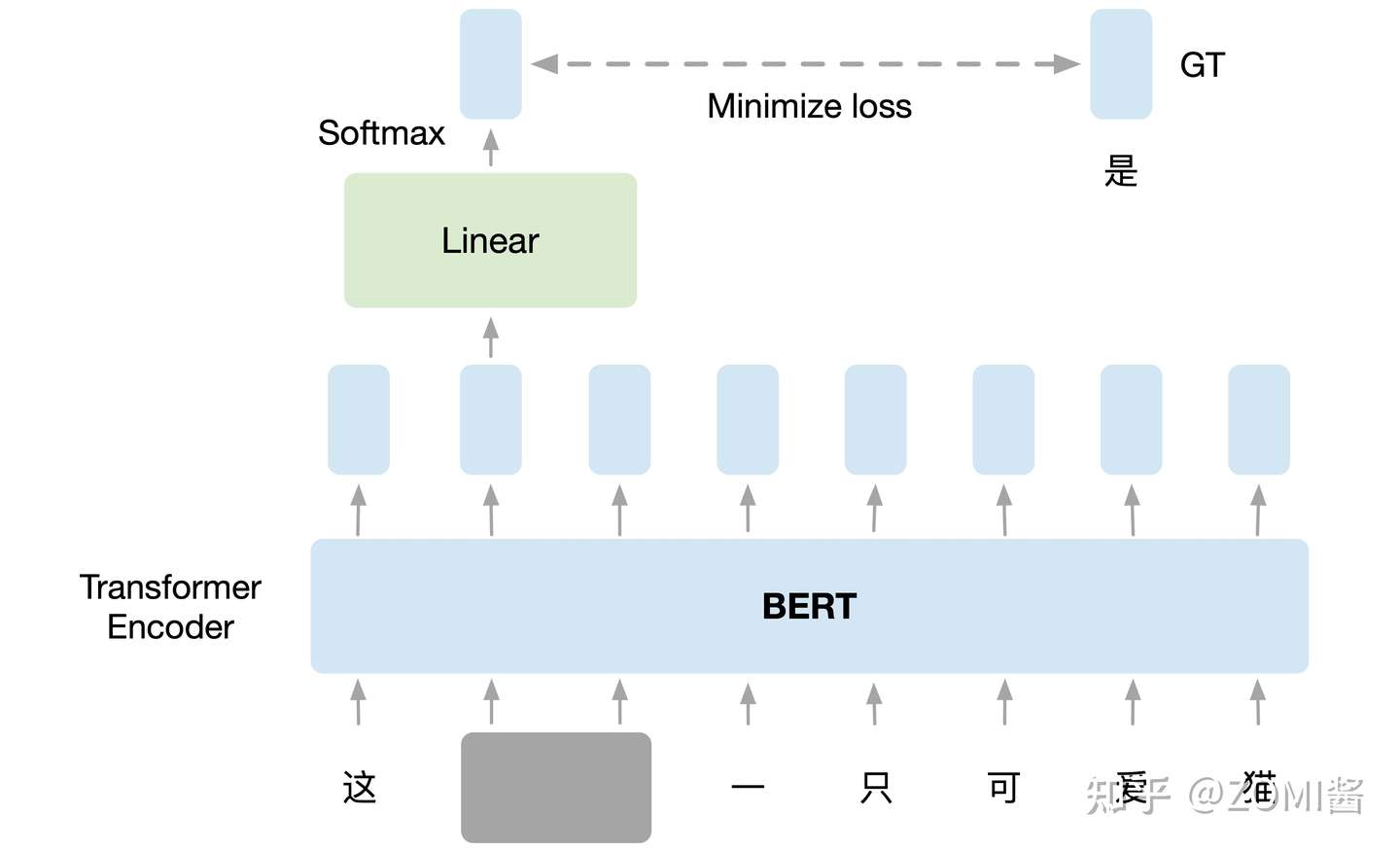
- NLP领域的 Pretext Task:在训练 BERT 的时候,预训练过程进行作填空的任务。
如下图所示,把输入文字里面的一部分随机盖住,就是直接用一个掩码 Mask 把要盖住的token(字符或者一个字)给遮盖住,换成一个特殊的字符。接下来把这个盖住的 token 对应位置输出的向量执行线性变换 Linear Transformation,对输出执行softmax计算输出关于每一个字的概率分布。因为这时候 BERT 并不知道被掩盖住的字是 "湾" ,但是输入的原始数据是知道这个信息的,所以损失就是让这个输出和被盖住的 "湾" 越接近越好。这个任务和下游任务毫不相干,但是 BERT 就是通过 Pretext Task 学习到了很好的 Language Representation 作为预训练模型,很好地适应了下游任务。
(2) CV领域的 Pretext Task:在训练 SimCLR 的时候,预训练过程让模型区分相似和不相似的图像。
如下图所示,假设现在有1张图片 x ,先对 x 进行数据增强,得到2张增强以后的图片 x_i, x_j 。接下来把增强后的图片 x_i, x_j 输入到Encoder里面,注意这2个Encoder是共享参数的,得到representation h_i 和 h_j ,再把 h_i 和 h_j 通过 Projection head 得到 representation z_i 和 z_j。下面的目标就是最大化同一张图片得到的 z_i 和 z_j ,最小化不同张图片得到的 z_i 和 z_j。其具体的结构表达式是:
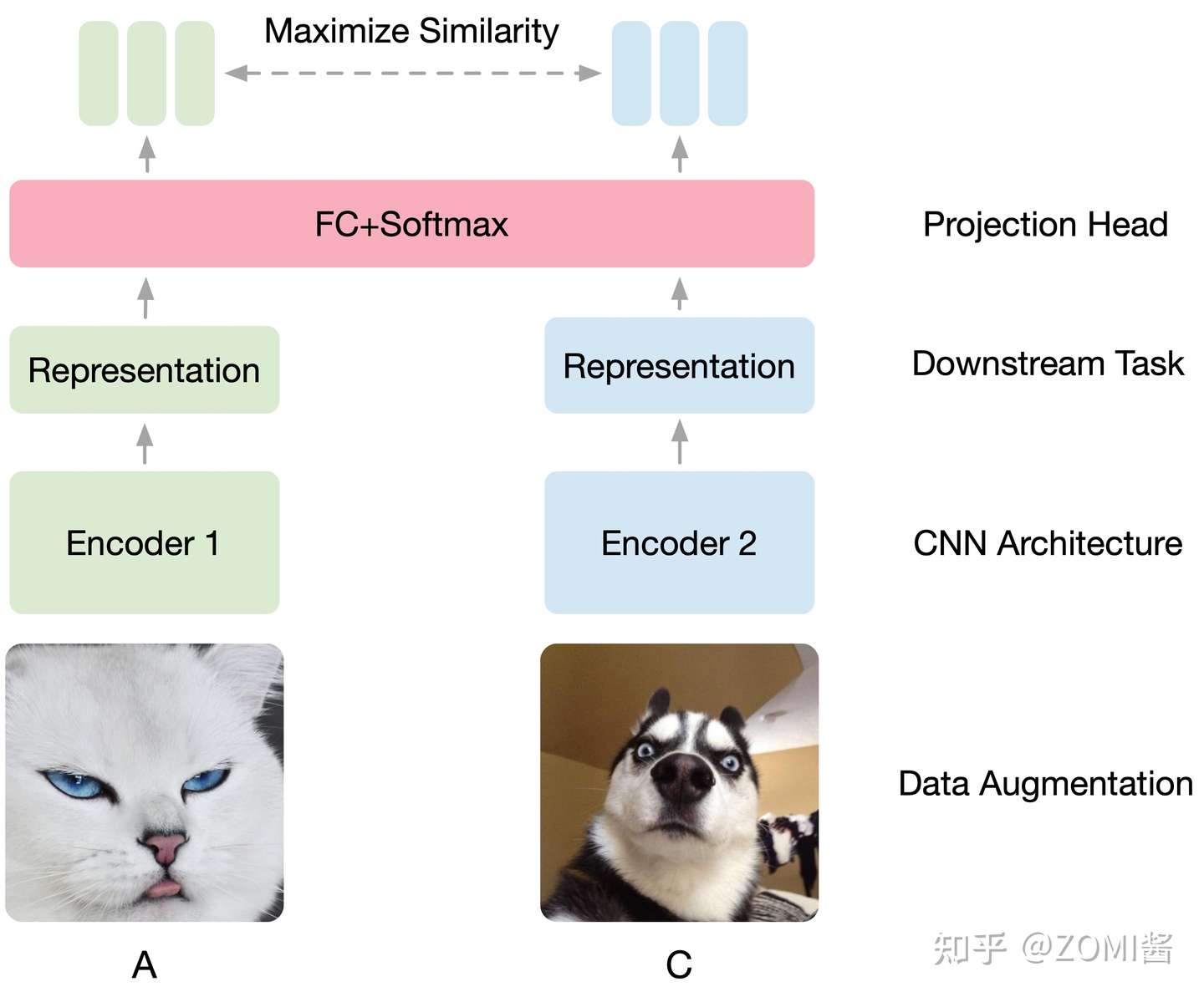
通过上图方式训练视觉模型,学习到了很好的视觉预训练模型的表达 Image Representation,在下游任务只要稍微进行 Fine-tune,效果就会比有很大的提升。
MoCo V1 原理
整篇文章其实主要是在介绍如何用对比学习去无监督地学习视觉的表征。
基本原理
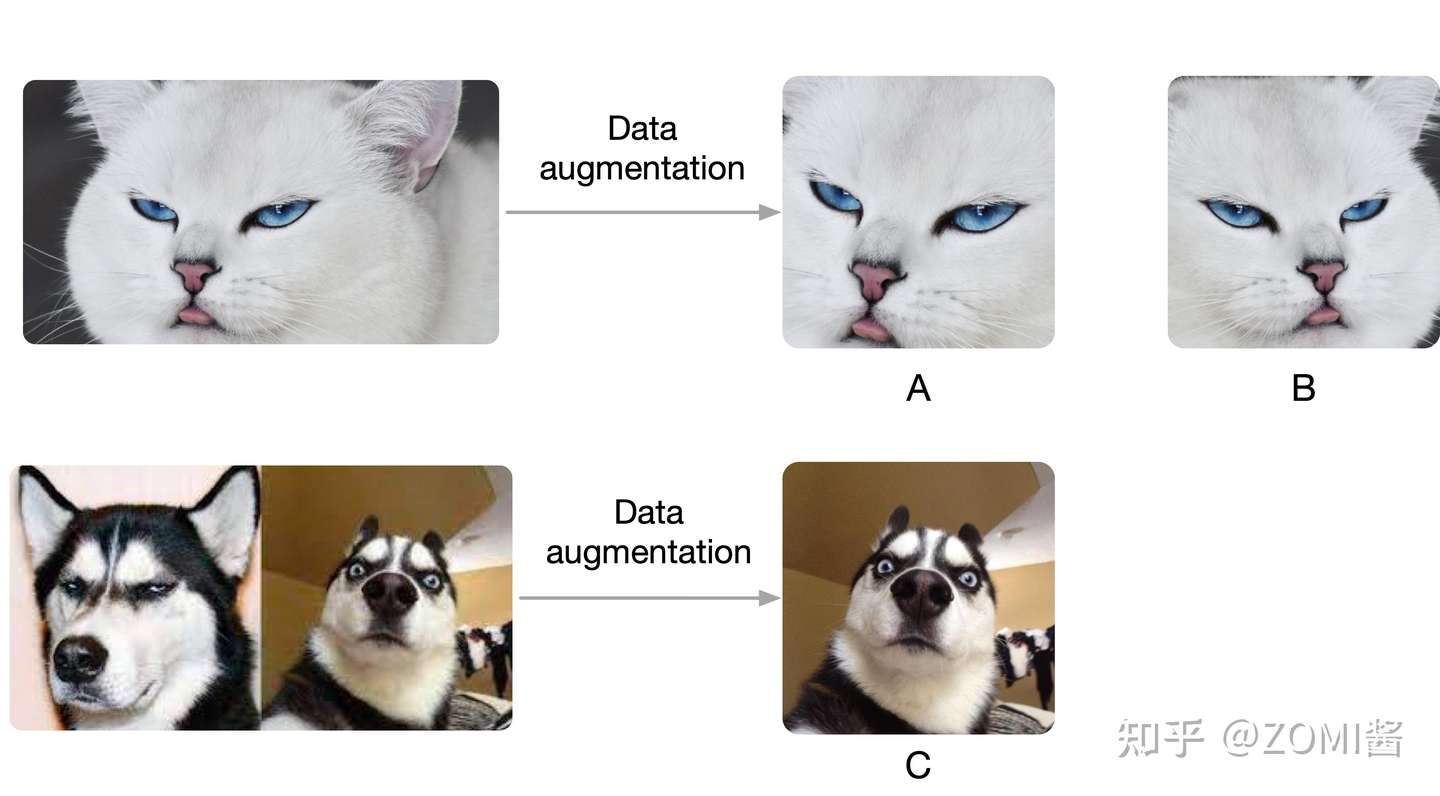
先考虑一个任务,现在有两个图片,图片1和图片2。先在图片1中通过数据增益产生两张图片,记作A,B,在图片2中截出一个patch记作C,现在把B和C放到样本库里面,样本库图片的位置随机打乱,然后以A作为查找的对象,让你从样本库中找到与A对应的图片。
假设随机裁剪了A,B, C三个图,然后将A设为被预测的对象,然后A通过encoder1编码为向量q,接着B、C经过encoder2编码为k1和k2。q和k1算相似度得到S1,q和k2算相似度得到S2。我们的目的是想要让机器学出来A和B是一类(关联性强),而A和C其它不是(关联性弱)。
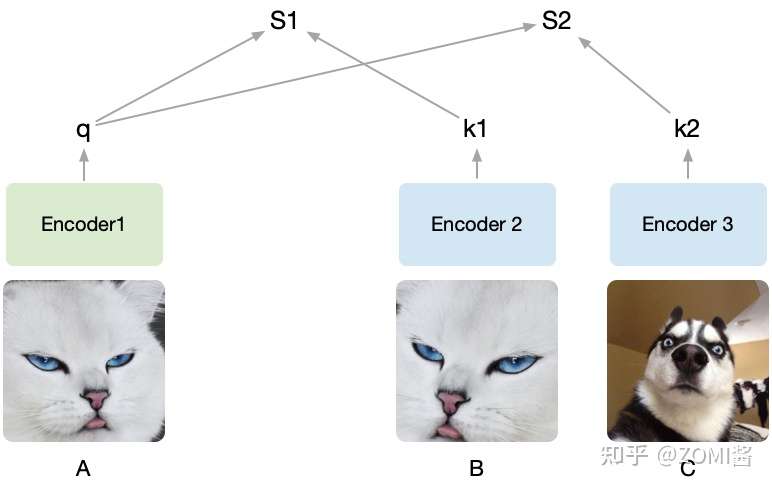
由于提前知道A和B是同一张图截出来的,而C不是,因此希望S1(A和B的相似度)尽可能高而S2(A和C的相似度)尽可能低。把B打上是正类的标签,把C打上是负类的标签,即同一张图片截出来的patch彼此为正类,不同的图片截出来的记为负类,由于这种方式只需要设定一个规则,然后让机器自动去打上标签,基于这些自动打上的标签去学习,所以也叫做自监督学习,MoCo就是通过不需要借助手工标注去学习视觉表征。
MoCo通过构建一个动态的负类队列来进行对比学习,依旧通过上面的例子来说,一般要学到好的表征需要比较多的负类样本,但是由于计算资源限制又不能加入太多的负类样本,并且我们也不希望负类样本是一成不变的,因此提出了就有了 dynamic dictionary with a queue。
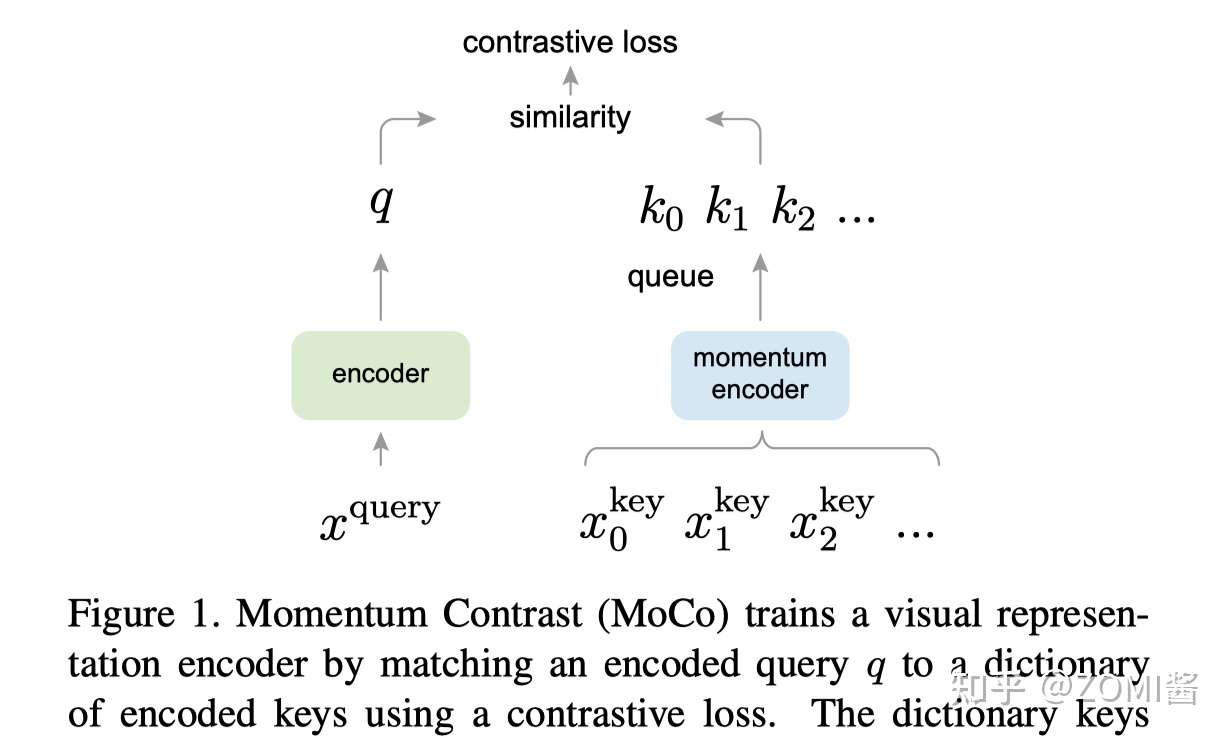
x^query可以类比上面的图A,x^key类比是图B和图C,图中的encoder可以是CNN,queue就是样本队列,剩下momentum encoder和contrastive loss。
contrastive loss
对比学习关注的是能不能区别出同类和非同类的样本,Contrastive loss有很多不同的形式,MoCo使用的是InfoNCE,表达式如下:
这里通过点积来计算 q 和 k 的相似度,k+ 是指正样本经过momentum encoder编码成的向量,注意的是里面对照样本里面只有一个正样本,其余都是负样本,至于分母 τ 就是softmax的温度参数,用来控制概率分布的尖锐和平滑。
momentum encoder
原始的自监督学习方法里面的这一批负样本就相当于是有个字典 (Dictionary),字典的key就是负样本,字典的value就是负样本通过 Encoder 之后得到的特征向量。
那么现在问题来了:这一批负样本,即字典的大小是多大呢?
负样本的规模就是 batch size,即字典的大小就是 batch size。
举个例子,假设 batch size = 256,那么对于给定的一个样本 ,选择一个正样本 (经过data augmentation的图像)。然后选择256个负样本,然后使用 loss function 来将与正样本之间的距离拉近,负样本之间的距离推开到系数m。
毫无疑问是 batch size 越大效果越好的,这一点在 SimCLR 中也得到了证明。但是,由于硬件的影响 batch size 不能设置过大,因此很难应用大量的负样本。因此效率较低,如图(a)。
于是图(b)采用一个较大的memory bank存储较大的字典:对于给定的一个样本 ,选择一个正样本 (经过data augmentation的图像)。采用一个较大的 memory bank 存储较大的字典,这个 memory bank 具体存储的是所有样本的表征 representation(涵盖所有的样本,比如样本一共有60000个,那么memory bank大小就是60000,字典大小也是60000)。采样其中的一部分负样本 ,然后使用Contrastive loss将 q 与正样本之间的距离拉近,负样本之间的距离推开。这次只更新 Encoder 的参数,和采样的key值 。因为这时候没有了 Encoder 的反向传播,所以支持memory bank容量很大。
但是,这一个step更新的是 Encoder 的参数,和几个采样的key值 ,下个step更新的是 Encoder 的参数,和几个采样的key值 ,Encoder 的参数每个step都更新,但是某一个 key 可能很多个step才被采样到更新一次,而且一个epoch只会更新一次。这就出现了一个问题:每个step编码器都会进行更新,这样最新的 query 采样得到的 key 可能是好多个step之前的编码器编码得到的 key,因此丧失了一致性。
从这一点来看,(a)端到端自监督学习方法的一致性最好,但是受限于batchsize的影响。而(b)采用一个memory bank存储较大的字典,一致性却较差。
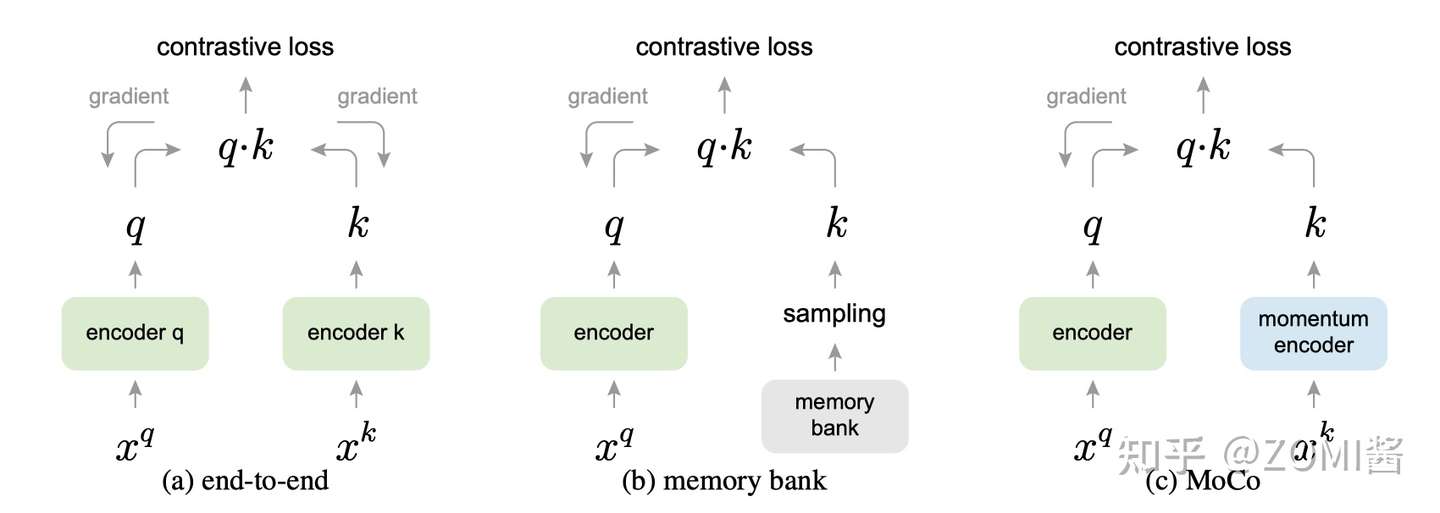
实现对比学习可以有以上三种形式。在(a)中,encoder q和encoder k都是端对端一起训练,encoder q和encoder k可以是两个不同的网络。(b)的话是把对比的样本全部存到一个memory bank中,训练的时候之间从memory bank中采样。
(c)就是MoCo的做法,与(a)不同的是,右边的 Encoder 是不直接通过反向传播来训练的,而是优化器产生的动量更新,更新的表达式如下。
θ_k 是右边 Encoder 的参数,m默认设为0.999,θ_q 是左边编码 query 的 Encoder,θ_q 通过反向传播来更新,θ_k 则是通过 θ_q 动量更新。为什么采用这样的方式来更新?论文给出的解释是 θ_k 直接通过反向传播来更新的效果并不好,因为 θ_k 快速的变化会导致 key 的表征不稳定,但是动量更新很好地解决了这个问题。
现在的 Momentum Encoder 的更新是通过4式,以动量的方法更新的,不涉及反向传播,所以 输入的负样本 (negative samples) 的数量可以很多,具体就是 Queue 的大小可以比较大,那当然是负样本的数量越多越好了。这就是 Dictionary as a queue 的含义,即通过动量更新的形式,使得可以包含更多的负样本。而且 Momentum Encoder 的更新极其缓慢,所以Momentum Encoder 的更新相当于是看了很多的 Batch,也就是很多负样本。
MoCo的每个step都会更新Momentum Encoder,虽然更新缓慢,但是每个step都会通过式(4)更新 Momentum Encoder,这样 Encoder 和 Momentum Encoder 每个step 都有更新,就解决了一致性的问题。
MoCo V1算法理解
如果还没有了解清楚的话,可以来看下算法训练的伪代码,也许会更清晰一点。

- 数据增强:
现在我们有一堆无标签的数据,拿出一个 Batch,代码表示为 x,也就是 张图片,分别进行两种不同的数据增强,得到 x_q 和 x_k,则 x_q 是 张图片,x_k 也是 张图片。
for x in loader: # 输入一个图像序列x,包含N张图,没有标签
x_q = aug(x) # 查询queue的图 (数据增强得到)
x_k = aug(x) # 模板图 (数据增强得到)- 分别通过 Encoder 和 Momentum Encoder:
x_q 通过 Encoder 得到特征 q,维度是 NxC,这里特征空间由一个长度为 C=128 的向量表示。
x_k 通过 Momentum Encoder 得到特征 k,维度是 NxC。
q = f_q.forward(x_q) # 提取查询特征,输出NxC
k = f_k.forward(x_k) # 提取模板特征,输出NxC- Momentum Encoder的参数不更新:
# 不使用梯度更新f_k的参数,假设用于提取模板的表示应该是稳定的,不应立即更新
k = k.detach()- 计算 N 张图片的自己与自己的增强图的特征的匹配度:
# 这里bmm是分批矩阵乘法,输出Nx1,也就是自己与自己的增强图的特征的匹配度
l_pos = bmm(q.view(N,1,C), k.view(N,C,1))这里得到的 l_pos 的维度是 (N, 1, 1),N 代表 N 张图片的自己与自己的增强图的特征的匹配度。
- 计算 N 张图片与队列中的 K 张图的特征的匹配度:
# 输出Nxk,自己与上一批次所有图的匹配度(全不匹配)
l_neg = mm(q.view(N,C), queue.view(C,K))这里得到的 l_neg 的维度是 (N, K),代表 N 张图片与队列 Queue 中的 K 张图的特征的匹配度。
- 把 4, 5 两步得到的结果concat起来:
logits = cat([l_pos, l_neg], dim=1) # 输出 Nx(1+k)这里得到的 logits 的维度是 (N, K+1),把它看成是一个矩阵的话呢,有 N 行,代表一个 Batch Size 里面的 N 张图片。每一行的第1个元素是某张图片自己与自己的匹配度。
- NCE损失函数,就是为了保证自己与自己衍生的匹配度输出越大越好,否则越小越好:
labels = zeros(N)
# NCE损失函数,就是为了保证自己与自己衍生的匹配度输出越大越好,否则越小越好
loss = CrossEntropyLoss(logits/t, labels)
loss.backward()- 更新 Encoder 的参数:
update(f_q.params) # f_q 使用梯度立即更新- Momentum Encoder 的参数使用动量更新:
# 这里使用动量法更新
f_k.params = m * f_k.params + (1 - m) * f_q.params- 更新队列,删除最老的一个 Batch,加入一个新的 Batch:
enqueue(queue, k) # 为了生成反例,所以引入了队列
dequeue(queue)MoCo V1 实验部分
- 实验一:Linear Classification Protocol
评价一个自监督模型的性能,最关键和最重要的实验莫过于 Linear Classification Protocol 了,它也叫做 Linear Evaluation,具体做法就是先使用自监督的方法预训练 Encoder,这一过程不使用任何 label。预训练完以后 Encoder 部分的权重也就确定了,这时候把它的权重冻结住,同时在 Encoder 的末尾添加 Global Average Pooling 和一个线性分类器 (FC+softmax),并在固定数据集上做 Fine-tune,这一过程使用全部的 label。
上述方法在(a)原始的端到端自监督学习方法,(b)采用一个较大的memory bank存储较大的字典,(c)MoCo方法的结果对比如下图。
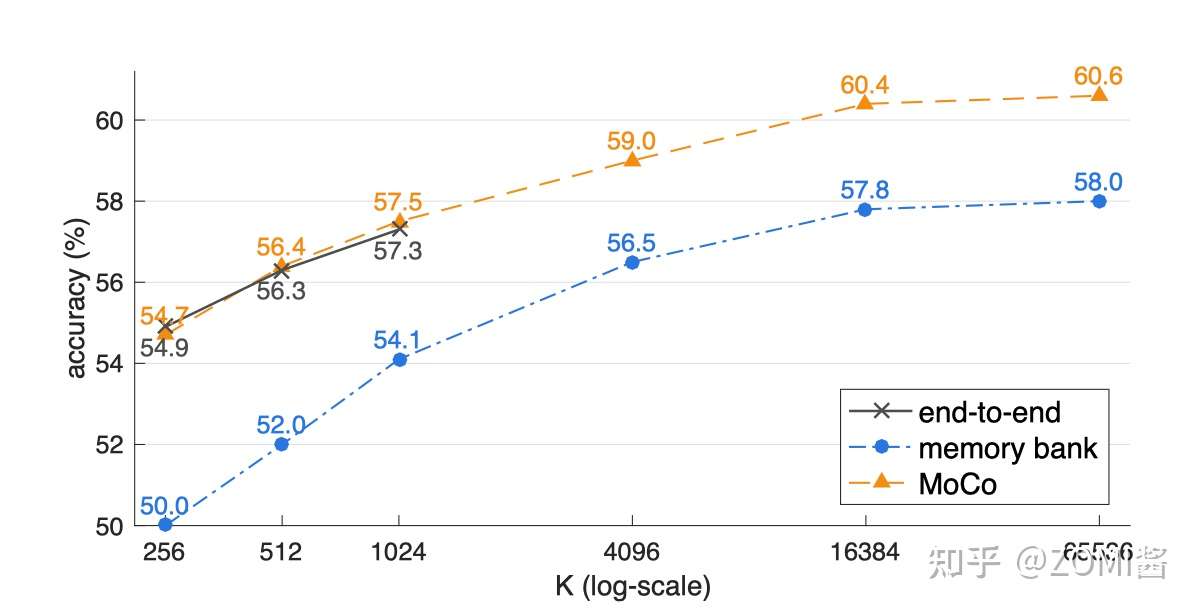
看到图中的3条曲线都是随着 K 的增加而上升的,证明对于每一个样本来讲,正样本的数量都是一个,随着负样本数量的上升,自监督训练的性能会相应提升。我们看图中的黑色线(a)最大取到了1024,因为这种方法同时使用反向传播更新 Encoder 和 Encoder 的参数,所以 Batch size 的大小受到了显存容量的限制。同时橙色曲线是最优的,证明了MoCo方法的有效性。
- 实验四:下游任务 Fine-tune 结果
有了预训练好的模型,就相当于是已经把参数训练到了初步成型,这时候再根据下游任务 (Downstream Tasks) 的不同去用带标签的数据集把参数训练到完全成型,那这时用的数据集量就不用太多了,因为参数经过了第1阶段就已经训练得差不多了。
本文的下游任务是:PASCAL VOC Object Detection 以及 COCO Object Detection and Segmentation,主要对比的对象是 ImageNet 预训练模型 (ImageNet supervised pre-training),注意这个模型是使用100%的 ImageNet 标签训练的。
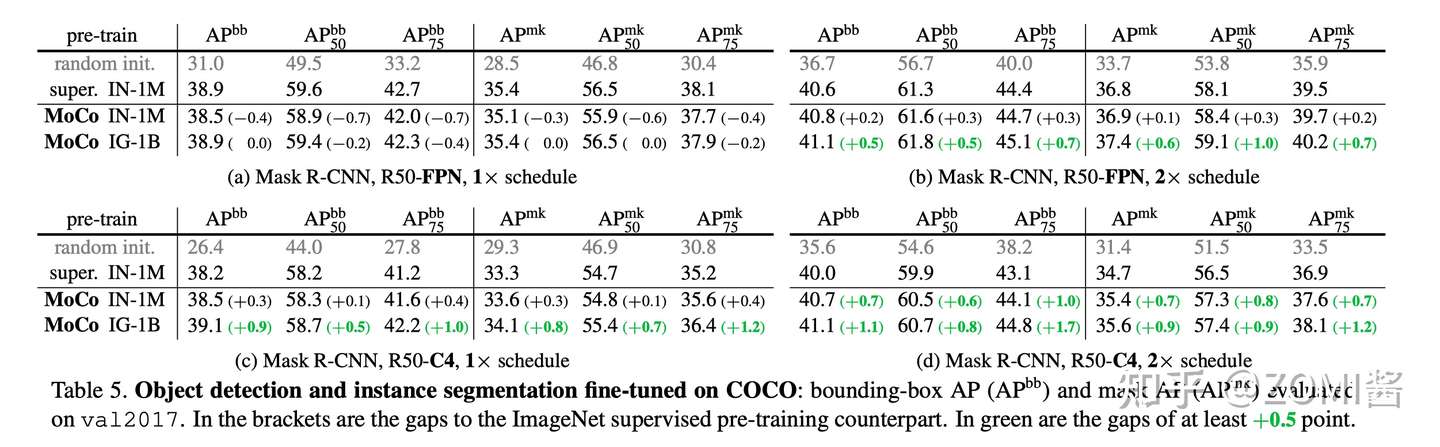
如下图是在 trainval07+12 (约16.5k images) 数据集上 Fine-tune 之后的结果,当Backbone 使用 R50-dilated-C5 时,在 ImageNet-1M 上预训练的 MoCo 模型的性能与有监督学习的性能是相似的。在 Instagram-1B 上预训练的 MoCo 模型的性能超过了有监督学习的性能。当Backbone 使用 R50-dilated-C5 时,在 ImageNet-1M 或者 Instagram-1B 上预训练的 MoCo 模型的性能都超过了有监督学习的性能。
引用
[1] Hadsell, Raia, Sumit Chopra, and Yann LeCun. "Dimensionality reduction by learning an invariant mapping." 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06). Vol. 2. IEEE, 2006.
[2] Chen, Ting, et al. "A simple framework for contrastive learning of visual representations." International conference on machine learning. PMLR, 2020.
[3] He, Kaiming, et al. "Momentum contrast for unsupervised visual representation learning." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
[4] https://zhuanlan.zhihu.com/p/364446773
[5] https://zhuanlan.zhihu.com/p/46
MoCo V1:视觉领域也能自监督啦的更多相关文章
- paper 94:视觉领域博客资源1之中国部分
这是收录的图像视觉领域的博客资源的第一部分,包含:中国内地.香港.台湾 这些名人大家一般都熟悉,本文仅收录了包含较多资料的个人博客,并且有不少更新,还有些名人由于分享的paper.code或者数据集不 ...
- paper 14 : 图像视觉领域部分开源代码
做图像处理,没有一定的知识储备是不可能的,但是一定要学会“借力打力”,搜集一些很实用的开源代码,你们看看是否需要~~ 场景识别: SegNet: A Deep Convolutional Encode ...
- Valse2019笔记——弱监督视觉理解
程明明(南开大学):面向开放环境的自适应视觉感知 (图片来自valse2019程明明老师ppt) 面向识别与理解的神经网络共性技术 深度神经网络通用架构 -- VggNet(ICLR'15).ResN ...
- (转) SLAM系统的研究点介绍 与 Kinect视觉SLAM技术介绍
首页 视界智尚 算法技术 每日技术 来打我呀 注册 SLAM系统的研究点介绍 本文主要谈谈SLAM中的各个研究点,为研究生们(应该是博客的多数读者吧)作一个提纲挈领的摘要.然后,我 ...
- LUSE: 无监督数据预训练短文本编码模型
LUSE: 无监督数据预训练短文本编码模型 1 前言 本博文本应写之前立的Flag:基于加密技术编译一个自己的Python解释器,经过半个多月尝试已经成功,但考虑到安全性问题就不公开了,有兴趣的朋友私 ...
- 论文解读《Momentum Contrast for Unsupervised Visual Representation Learning》俗称 MoCo
论文题目:<Momentum Contrast for Unsupervised Visual Representation Learning> 论文作者: Kaiming He.Haoq ...
- (转) OpenCV学习笔记大集锦 与 图像视觉博客资源2之MIT斯坦福CMU
首页 视界智尚 算法技术 每日技术 来打我呀 注册 OpenCV学习笔记大集锦 整理了我所了解的有关OpenCV的学习笔记.原理分析.使用例程等相关的博文.排序不分先后,随机整理的 ...
- 如何从零开始系统化学习视觉SLAM?
由于显示格式问题,建议阅读原文:如何从零开始系统化学习视觉SLAM? 什么是SLAM? SLAM是 Simultaneous Localization And Mapping的 英文首字母组合,一般翻 ...
- 转:SLAM算法解析:抓住视觉SLAM难点,了解技术发展大趋势
SLAM(Simultaneous Localization and Mapping)是业界公认视觉领域空间定位技术的前沿方向,中文译名为“同步定位与地图构建”,它主要用于解决机器人在未知环境运动时的 ...
随机推荐
- 面试题|Docker的优缺点
开源Linux 长按二维码加关注~ 上一篇:Linux中几个正则表达式的用法 Docker解决的问题: 由于不同的机器有不同的操作系统,以及不同的库和组件,在将一个应用部署到多台机器上需要进行大量的环 ...
- 1 Mybatis动态SQL
Mybatis动态SQL 1. 注解开发 我们也可以使用注解的形式来进行开发,用注解来替换掉xml. 使用注解来映射简单语句会使代码显得更加简洁,但对于稍微复杂一点的语句,Java 注解不仅力不从 ...
- 将MySQL查询结果导出到Excel
总结将mysql的查询结果导出到文件的方法 总结 使用命令 select user, host, password from mysql.user into outfile '/tmp/user.xl ...
- 299. Bulls and Cows - LeetCode
Question 299. Bulls and Cows Solution 题目大意:有一串隐藏的号码,另一个人会猜一串号码(数目相同),如果号码数字与位置都对了,给一个bull,数字对但位置不对给一 ...
- 594. Longest Harmonious Subsequence - LeetCode
Question 594. Longest Harmonious Subsequence Solution 题目大意:找一个最长子序列,要求子序列中最大值和最小值的差是1. 思路:构造一个map,保存 ...
- MySQL执行计划explain
一.简介 分析查询慢的原因,在查询语句前加explain即可.如: 二.输出格式 2.0 测试数据 # 表user_info CREATE TABLE `user_info` ( `id` bigin ...
- Git分离头指针
Git头指针 Git中有HEAD头指针的概念.HEAD头指针通常指向某个分支的最近一次提交,但我们也可以改变它的指向,使其指向某个commit,此时处于分离头指针的状态. 如下,改变HEAD的指向,g ...
- 缓存&PWA实践
缓存&PWA 实践 一.背景 从上一篇<前端动画实现与原理分析>,我们从 Performance 进行动画的性能分析,并根据 Performance 分析来优化动画.但,前端不仅仅 ...
- js 定时器 Timer
1 /* Timer 定时器 2 3 parameter: 4 func: Function; //定时器运行时的回调; 默认 null 5 speed: Number; //延迟多少毫秒执行一次 f ...
- linux-ext4格式文件误删除,该如何恢复?
在开始进行实验之前,我已经新建了一个空目录/data,并将该目录挂载了一块新硬盘,将硬盘分区格式化为ext4的格式,所以当我操作/data目录下的文件及文件夹的时候,实际上就是针对新挂载的硬盘进行数据 ...