零基础解读ChatGPT:对人类未来工作是威胁还是帮助?
摘要:火到现在的ChatGPT到底是什么?它背后有哪些技术?对于我们的工作和生活会有啥影响?快来一起了解吧~
本文分享自华为云社区《零基础解读ChatGPT:对人类未来工作是威胁还是帮助?》,作者:关耳山石。
前言
年前到现在,一直被ChatGPT的新闻轰炸,现在还越来越热闹了,关于ChatGPT技术,关于人与ChatGPT未来发展的讨论,网络上众说纷纭。我就让同事从海外注册账号,直接问了ChatGPT这个问题,最后用Stable Diffusion生成了ChatGPT眼中未来的图像,如下图:

关于这幅景象,它是这么描述的:


于是,作为一位严谨的“民科”和积极的开发者,立即开始跟随潮流,了解新技术 !希望能与大家一起交流看法,欢迎大家留言讨论~
一、ChatGPT是什么?
1、ChatGPT背后的公司们·OpenAI&微软
要聊ChatGPT,必须得先聊OpenAI。这本来是一家搞全栈AI创新的非盈利组织,重点研究物理机器人,背后甚至还有钢铁侠、彼得·蒂尔、YC总裁Sam(任CEO)等一众硅谷大佬身影,而GPT系列模型只是众多研究方向之一。
因为非盈利组织无法进行融资,就搞了个商业的壳子,吸引了微软投资,最后达成的结果是:OpenAI要优先使用微软的技术(主要是Azure),微软得到了OpenAI技术的使用权,这也是ChatGPT与微软之间的联系。
2、ChatGPT背后技术·GPT-3.5
GPT这模型已经发展四代了,目前开放了GPT-3的API(收费的),ChatGPT用的是GPT-3.5,还有一代GPT-4没见过(据说Bing融合的就是这个)。
这个东西到底是干啥的,如果感兴趣,建议去看李宏毅老师的视频,省流版就是: 文字接龙机器人,一个学了2/3的互联网知识,整个Wikipedia,多个书籍库,以及一套“自动补齐”能力的文字接龙机器人。
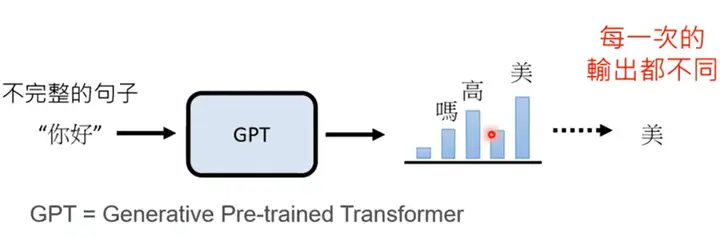
(引至李宏毅老师的视频)
但是平时咱们用的输入法基本也会一些文字接龙,但是接起来的感觉前言不搭后语的,为啥ChatGPT就行了呢?网上还找不着GPT-3.5相关的材料,只能研究研究GPT-3的创新点去推断了:
- 模型相当大
1750亿参数,这个参数大概意思是表示每个字/词出现的可能性。到底有多大,看下图就有个直观的感受。
当然,训练数据量也极其的大,大约是4990亿个Token(简单理解为字/词),号称学了2/3个互联网、整个Wikipedia和几个书籍库。按照这个信息量,一定是高度冗余的,也是绝对充分了。
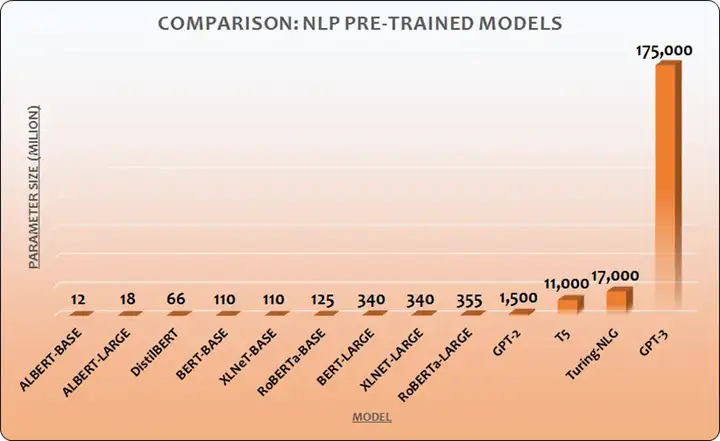
(图片源于网络)
- “加钱”效果相当好
这玩意还有个很神奇的地方,就是有钱能使它推磨,“加价”的效果立竿见影:从趋势来看,模型越大,效果越好。想必将来还会有更大的模型出来,毕竟有多大钱,GPT能创造多少奇迹嘛!(DeepMind还做了个推导,算出来一个模型参数与数据量的最优线性关系)
- 通用性相当好
这也算个特别牛的事情,不用进行额外的“调教”,已经学会了干很多事,简直是AI工程师的福音。
举个例子,我们有个相似需求推荐的场景,是基于BERT的基础模型,加上一堆(上千条)人工标注的训练数据集,再调优一把,才能使用在我们的场景里。有了这个大力仔,就不需要这一套了,直接拿来即用。而且还有个比较有意思的,哪怕要教模型做点事,也不需要工程师了,直接在输入里写上寥寥几个例子(In Context Learning),模型就学会了。
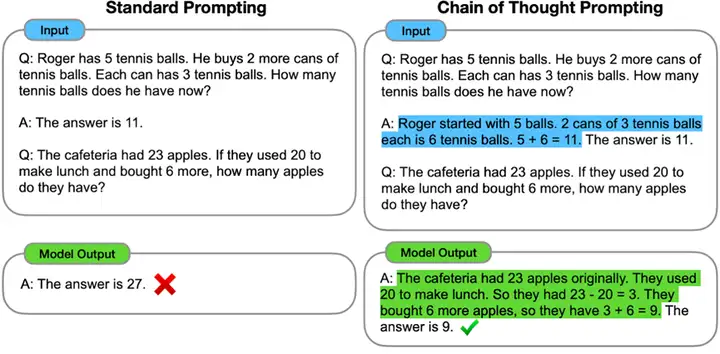
- “意识”涌现相当惊人
学名叫Chain-of-Thought,思维链,这是最让人惊讶和细思极恐的了。
就是当模型足够大,层数足够多的时候,居然还就从量变到质变了,产生了一些类人的逻辑思维能力。这玩意我没看到更深刻的解释,但是从表象上看,确实会做一些逻辑题了。比如算算数、做一些逻辑推理。
PS:我从网上看到一个数据,列在这里做个备注 - OpenAI的GPT 3的规模为175B,Google的LaMDA规模为137B,PaLM的规模为540B,DeepMind的Gogher规模为280B等,不一而足。国内也有中文巨型模型,比如清华&智谱GLM规模130B,华为“盘古”规模200B,百度“文心”规模260B,浪潮“源1.0”规模245B。(规模 = 模型的参数规模,单位是Billion)
(图片源于网络)
3、从GPT-3.5到ChatGPT的意义
如果说GPT-3是理论或底层能力的创新,那么ChatGPT的创新就是工程和商业层面的,甚至是一个里程碑式的。
- 这是一个“现象级”的产品
首先,我认为,将一个大众无法理解的技术,变成“现象级”产品,是ChatGPT的最牛创新,使得“AI使能”落入寻常百姓家,与每个人产生了化学反应,所以这绝对是划时代的。
Google 2022年I/O大会的时候,我也做了一波洞察,看到LaMDA、PaLM的展示,能够体验的人极少,感知到其魅力的也是极少的。而ChatGPT做了个简陋的Playground就迅速抢占了大众的心智,看到有数据说,从0~100万用户只用了5天,过亿只用了2个月,基本没有额外的获客成本。甚至还让竞争对手意识到,再不搞起早起五更都赶不上晚集了。以至于前几天Google不仅召回了两位创始人,快速规划对话式搜索的上线,还大笔投资了OpenAI的“港湾”组织 – Anthropic)。
从工程上,我理解ChatGPT是GPT-3.5的一个优化应用。简单说,就是先人肉标注一些GPT-3.5返回数据,以教GPT-3.5说话,然后用强化学习的算法来持续评价,最终实现了这么个神奇的模型。(号称用到了40+的人力来持续教AI做事,据说还有肯尼亚的低价劳工。)
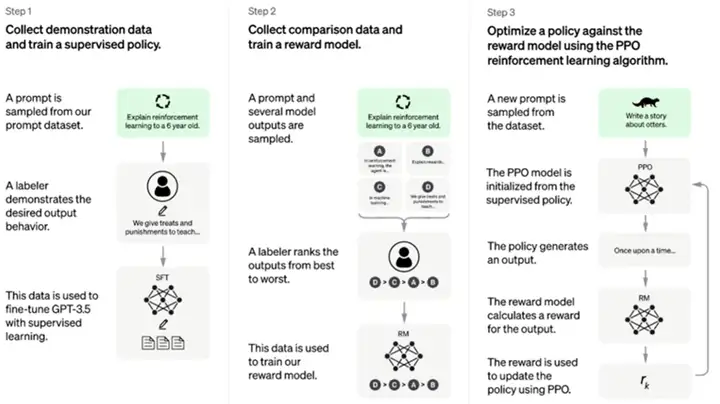
- 可惜不开源
ChatGPT不开源,GPT-3.5模型也不开源。两者都不支持在中国使用(包括HK),所以网络上开始有二道贩子开始倒卖,或直接接到微信上付费使用。两者目前都有商业化的手段,GPT模型是直接卖API,ChatGPT出了Plus版,20美刀一个月,优先使用。(GPT-1模型和GPT-2的部分小规模模型是开源的,OpenAI的理由是,大规模模型能力太强大,怕被坏人利用)
二、ChatGPT会对我们产生什么影响?
首先,我们得先认识到,ChatGPT只是众多LLM中比较会秀的一个。GPT系列属于大规模语言模型(LLM)前沿中的一支,DeepMind(搞AlphaGo下围棋的那公司)、Google、FB,都有自己的优秀实践。从技术能力上,我觉得还远没有到比哪个更好的程度,倒是ChatGPT这一波秀出圈以后,大家找金主爸爸要钱会更容易了,这是个大家都开心的事儿。
关于替代人类工作的讨论,用微软CEO纳德拉的话说:“信息的整合、转译和流通,变得廉价”。因此对于所有与信息整合、转译和流通相关的工作,还是会有影响。
侵入“创造性”工作
GPT模型已经离谱到,直接把图案转成向量喂给它,就能帮我们补齐图片(image-gpt)的地步,或许我们曾以为的文案、绘图,甚至是编码这些曾经被认为无法被AI替代的工作都将被入侵。
取代“搜索和问答”
人类在已有知识的搜索和输出上,可能永远无法超过AI。Google已经开始加快LaMDA的速度,然后是微软继续加注OpenAI并开始在Bing中融入,再然后StackOverflow(技术类知识问答界的明珠)用户量降了3200万,所以我觉得,大模型是靠谱的,替代也是迟早的事儿。
让AI应用更简单
ChatGPT的Zero-shot效果显著(LLM有三种学习方式,Few-shot、One-shot、Zero-shot,讲人话就是举多反一、举一反一、无中生有),这个能力在语言模型中,影响极其深远。简单来说,就是我们如果想在项目中引入AI能力,GPT很好的通用性、极少的“调教”量会使得工程上更简单。
ChatGPT背后基础模型能力成熟且强,更多此类大模型被打造出来后,使得千千万万的AI加持变成可能,实现“AI使能”落入寻常百姓家。
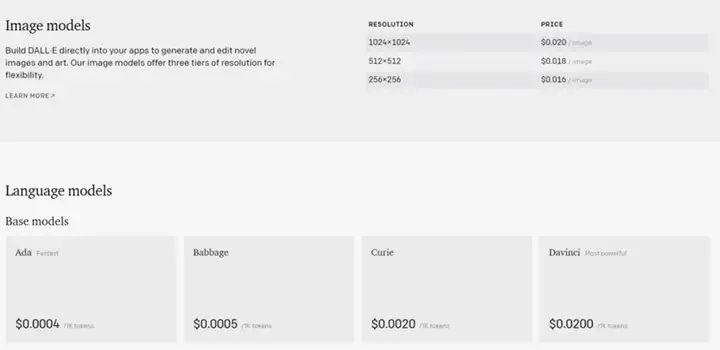
而且,OpenAI卖通用AI的API的生意还是可以赚钱的(见下图,1k token大约等于750个字,看着不算贵,默认还有18刀的体验费用),这里不得不开个玩笑:AI工程师们,你们把AI的道拓宽了,把自己的道都走窄了啊!
三、ChatGPT并非万能
从根子上理解,GPT算法在做的其实是“补齐”工作:即通过学习人类说话的方式,基于上下文,推测后面你打算说啥。具体要回答啥,则完全靠概率计算,靠“违和感”。
如此一来,当下的GPT算法势必就有几个特点:
需要海量的数据、算力和钱
搞个这种算法,总共烧了多少钱呢?22年是5个亿刀,前七年40亿刀,最近微软新加注100亿刀。(我看网上说,ChatGPT训练下来大约1200多万美金,这样看来,微软的投资,还是打好算盘的,钱要花在自己身上才算值)。而且,搜索引擎和信息入口企业已占先机,想要再进入,都需要更多的数据、钱和算力。当然,还需要很多标注人力来调教模型,让其有人的习惯和三观。
真实版“人云亦云”:
类比鹦鹉学舌,有响应不代表有思考,响应够用也不代表足够 优美。虽然它对通识类的知识理解,效果非常好(何谓通识?就是搜索引擎能搜出一堆来的知识,互联网本身信息已经高度冗余了,只是作为个体的人类不太清楚罢了),但其实AI也并不知道自己说的对不对,它只是知道,大家一般都这么说,然后做一些看起来不错的回答。(思维链除外,这个东西细思极恐,只是欺负它目前还没有那么成熟)
时效性问题
即目前ChatGPT学的是2021年前的知识,所以不知道2022年世界杯谁赢了,不过对于这个问题是可解的。OpenAI的WebGPT算法,已经与Bing结合,把最新的信息投喂给模型,如此一来,它也就知道最新消息了。(我不清楚具体是如何实现,猜测应该不是去实时训练基础模型,而是在上层叠加了什么)
四、我们如何利用ChatGPT
这个问题我想再扩大一点,扩大到AIGC这个话题上,AIGC已经被Science列为2022年TOP10科学突破,2022年是当之无愧的AIGC元年,结合我们的日常工作,我认为以下方面是可以快速尝试和引入的:
- 信息摘要和初级创作:主要用于日常办公效率提升的场景
从信息摘要的角度,这就是信息爆炸时代的良药,简要描述为用魔法打败魔法:直接让AI从繁杂的信息中摘取需要的重点内容,节约人力;从初级创作性工作替代上来看, AIGC可以快速帮我们做完早期的工作,更多精力投入“微雕”。
从OpenAI的Codex来看(支撑Github Copilot),对于常用算法、业务逻辑代码、重构(包括跨语言的重构,比如从java改成go)、代码注释(福音啊!)等的代码生成能力已经逐渐成型, 我试着面向GPT编程,效果相当好:语法工整、注释清晰、变量准确(除了逻辑错了一丢丢 – 返回是月末周日,而不是周六)

- 通识类问题解答:主要用于通识类知识搜索和问答场景,在公开域搜索信息,以减少人力搜索和辨别的过程。
- IT系统拟人化:主要用于人机交互场景,这个用途好像很少有人提,可能太偏门了。我觉得其实AIGC特别合适帮我们IT系统的输出更“丝滑”、更“拟人”、更“准确”,优化机器输出更加的“人性化”,符合普遍大众的习惯。
五、写在最后
“吾生也有涯,而知也无涯。以有涯随无涯,殆已!”,我觉得古人的智慧足以回答关于人类与ChatGPT未来发展的问题,在我看来,对于ChatGPT,甚至是更宽广的技术发展来说,科技是为了解放人类的双手,让我们用更充足的精力去进行思考、探索和创造,AI应该成为我们的辅助能力,而不是竞争者。
零基础解读ChatGPT:对人类未来工作是威胁还是帮助?的更多相关文章
- 零基础学习hadoop到上手工作线路指导(中级篇)
此篇是在零基础学习hadoop到上手工作线路指导(初级篇)的基础,一个继续总结. 五一假期:在写点内容,也算是总结.上面我们会了基本的编程,我们需要对hadoop有一个更深的理解: hadoop分为h ...
- 零基础学习hadoop到上手工作线路指导初级篇:hive及mapreduce
此篇是在零基础学习hadoop到上手工作线路指导(初级篇)的基础,一个继续总结.五一假期:在写点内容,也算是总结.上面我们会了基本的编程,我们需要对hadoop有一个更深的理解:hadoop分为h ...
- 考了3年,工作四年,零基础在职终于拿到CFA证书
大家都知道CFA Charterholder是独有的全球公认的投资管理从业人员高职业水平和道德水准的有力证明,是金融界卓越专业成就的象征:CFA资格强调和遵循极其严格的职业操守和道德准则,世界各主要发 ...
- 零基础学习hadoop到上手工作线路指导初级篇:hive及mapreduce(转)
零基础学习hadoop到上手工作线路指导初级篇:hive及mapreduce:http://www.aboutyun.com/thread-7567-1-1.html mapreduce学习目录总结 ...
- 零基础学习hadoop到上手工作线路指导(编程篇)
问题导读: 1.hadoop编程需要哪些基础? 2.hadoop编程需要注意哪些问题? 3.如何创建mapreduce程序及其包含几部分? 4.如何远程连接eclipse,可能会遇到什么问题? 5.如 ...
- [学习线路] 零基础学习hadoop到上手工作线路指导(初级篇)
about云课程最新课程Cloudera课程 零基础学习hadoop,没有想象的那么困难,也没有想象的那么容易.在刚接触云计算,曾经想过培训,但是培训机构的选择就让我很纠结.所以索性就自己学习了. ...
- 软件测试面试题-适合零基础和工作多年的re
软件测试面试题整理,可以看看:适合零基础和多年工作经验跳槽的人 有些问题会深挖,就不在整理了 详看图片:
- Nature Biotechnology:人类基因研究走近平民 数据是基础解读更重要
Nature Biotechnology:人类基因研究走近平民 数据是基础解读更重要 5万美元可以做什么?最近,美国斯坦福大学教授斯蒂芬·夸克在国际著名学术期刊<自然·生物技术>发表论文宣 ...
- 零基础,三个月内,找到??? java后端开发工作
一.分析你的问题 出于尊重,先分析一下你的原问题吧,从您的问题,我提取到关键信息:"零基础"."三个月内"."找到工作",最后一个关键词&q ...
- 零基础学习hadoop到上手工作线路指导
零基础学习hadoop,没有想象的那么困难,也没有想象的那么容易.在刚接触云计算,曾经想过培训,但是培训机构的选择就让我很纠结.所以索性就自己学习了.整个过程整理一下,给大家参考,欢迎讨论,共同学习. ...
随机推荐
- 模拟Promise的功能
模拟Promise的功能, 按照下面的步骤,一步一步 1. 新建是个构造函数 2. 传入一个可执行函数 函数的入参第一个为 fullFill函数 第二个为 reject函数: 函数立即执行, 参数函 ...
- 【Java难点攻克】「NIO和内存映射性能提升系列」彻底透析NIO底层的内存映射机制原理与Direct Memory的关系
NIO与内存映射文件 Java类库中的NIO包相对于IO包来说有一个新功能就是 [内存映射文件],在业务层面的日常开发过程中并不是经常会使用,但是一旦在处理大文件时是比较理想的提高效率的手段,之前已经 ...
- Spring面试点汇总
Spring面试点汇总 我们会在这里介绍我所涉及到的Spring相关的面试点内容,本篇内容持续更新 我们会介绍下述Spring的相关面试点: Spring refresh Spring bean Sp ...
- Pytorch 基本操作
Pytorch 基础操作 主要是在读深度学习入门之PyTorch这本书记的笔记.强烈推荐这本书 1. 常用类numpy操作 torch.Tensor(numpy_tensor) torch.from_ ...
- SQL Server下7种“数据分页”方案,全网最全
数据分页往往有三种常用方案. 第一种,把数据库中存放的相关数据,全部读入PHP/Java/C#代码/内存,再由代码对其进行分页操作(速度慢,简易性高). 第二种,直接在数据库中对相关数据进行分页操作, ...
- [深度学习] ncnn编译使用
文章目录 工程 ncnn工程编译使用(cpu) ncnn工程编译使用(vulkan) 参考 工程 ncnn工程编译使用(cpu) 在linux下建立如CMakeLists文件即可编译生成ncnn工程 ...
- 经典 backbone 总结
目录 目录 VGG ResNet Inceptionv3 Resnetv2 ResNeXt Darknet53 DenseNet CSPNet VoVNet 一些结论 参考资料 VGG VGG网络结构 ...
- NC14501 大吉大利,晚上吃鸡!
题目链接 题目 题目描述 最近<绝地求生:大逃杀>风靡全球,皮皮和毛毛也迷上了这款游戏,他们经常组队玩这款游戏. 在游戏中,皮皮和毛毛最喜欢做的事情就是堵桥,每每有一个好时机都能收到不少的 ...
- 发布了一个jar包到中央仓库,我的心好累…
原创:微信公众号 码农参上,欢迎分享,转载请保留出处. 哈喽大家好啊,我是Hydra. 前几天我在网上冲浪的时候,看见有一个老铁在git上给我提了一个issue: 万万没想到,有一天我写的烂代码居然也 ...
- 区块链特辑——solidity语言基础(六)
Solidity语法基础学习 十.实战项目(二): 1.实战准备: ERC20代币接口 ERC20 Token Interface接口 Interface IName {--} ·关键字:interf ...