Kafka教程(二)API开发-生产者、消费者、topic
一、地址
1、实时更新的思维导图
https://www.mubucm.com/doc/4uqlpedefuj
2、图片
二、具体内容
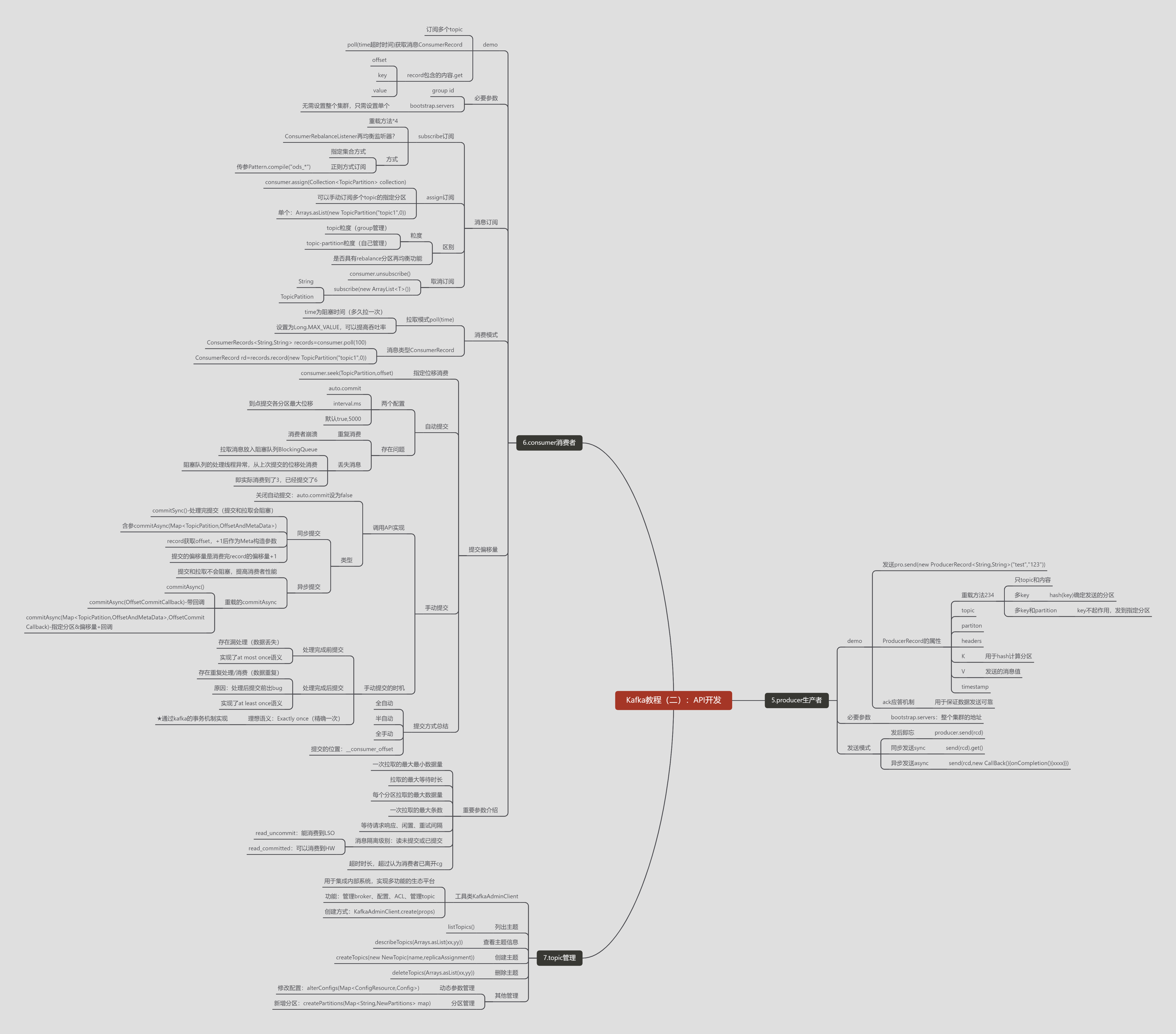
- 5.producer生产者
- demo
- 发送pro.send(new ProducerRecord<String,String>("test","123"))
- ProducerRecord的属性
- 重载方法234
- 只topic和内容
- 多key
- hash(key)确定发送的分区
- 多key和partition
- key不起作用,发到指定分区
- topic
- partiton
- headers
- K
- 用于hash计算分区
- V
- 发送的消息值
- timestamp
- ack应答机制
- 用于保证数据发送可靠
- 必要参数
- bootstrap.servers:整个集群的地址
- 发送模式
- 发后即忘
- producer.send(rcd)
- 同步发送sync
- send(rcd).get()
- 异步发送async
- send(rcd,new CallBack(){onCompletion(){xxxx}})
- 6.consumer消费者
- demo
- 订阅多个topic
- poll(time超时时间)获取消息ConsumerRecord
- record包含的内容.get
- offset
- key
- value
- 必要参数
- group id
- bootstrap.servers
- 无需设置整个集群,只需设置单个
- 消息订阅
- subscribe订阅
- 重载方法*4
- ConsumerRebalanceListener再均衡监听器?
- 方式
- 指定集合方式
- 正则方式订阅
- 传参Pattern.compile("ods_*")
- assign订阅
- consumer.assign(Collection<TopicPartition> collection)
- 可以手动订阅多个topic的指定分区
- 单个:Arrays.asList(new TopicPartition("topic1",0))
- 区别
- 粒度
- topic粒度(group管理)
- topic-partition粒度(自己管理)
- 是否具有rebalance分区再均衡功能
- 取消订阅
- consumer.unsubscribe()
- subscribe(new ArrayList<T>())
- String
- TopicPatition
- 消费模式
- 拉取模式poll(time)
- time为阻塞时间(多久拉一次)
- 设置为Long.MAX_VALUE,可以提高吞吐率
- 消息类型ConsumerRecord
- ConsumerRecords<String,String> records=consumer.poll(100)
- ConsumerRecord rd=records.record(new TopicPartition("topic1",0))
- 提交偏移量
- 指定位移消费
- consumer.seek(TopicPartition,offset)
- 自动提交
- 两个配置
- auto.commit
- interval.ms
- 到点提交各分区最大位移
- 默认true,5000
- 存在问题
- 重复消费
- 消费者崩溃
- 丢失消息
- 拉取消息放入阻塞队列BlockingQueue
- 阻塞队列的处理线程异常,从上次提交的位移处消费
- 即实际消费到了3,已经提交了6
- 手动提交
- 调用API实现
- 关闭自动提交:auto.commit设为false
- 类型
- 同步提交
- commitSync()-处理完提交(提交和拉取会阻塞)
- 含参commitAsync(Map<TopicPatition,OffsetAndMetaData>)
- record获取offset,+1后作为Meta构造参数
- 提交的偏移量是消费完record的偏移量+1
- 异步提交
- 提交和拉取不会阻塞,提高消费者性能
- 重载的commitAsync
- commitAsync()
- commitAsync(OffsetCommitCallback)-带回调
- commitAsync(Map<TopicPatition,OffsetAndMetaData>,OffsetCommitCallback)-指定分区&偏移量+回调
- 手动提交的时机
- 处理完成前提交
- 存在漏处理(数据丢失)
- 实现了at most once语义
- 处理完成后提交
- 存在重复处理/消费(数据重复)
- 原因:处理后提交前出bug
- 实现了at least once语义
- 理想语义:Exactly once(精确一次)
- ★通过kafka的事务机制实现
- 提交方式总结
- 全自动
- 半自动
- 全手动
- 提交的位置:__consumer_offset
- 重要参数介绍
- 一次拉取的最大最小数据量
- 拉取的最大等待时长
- 每个分区拉取的最大数据量
- 一次拉取的最大条数
- 等待请求响应、闲置、重试间隔
- 消息隔离级别:读未提交或已提交
- read_uncommit:能消费到LSO
- read_committed:可以消费到HW
- 超时时长,超过认为消费者已离开cg
- 7.topic管理
- 工具类KafkaAdminClient
- 用于集成内部系统,实现多功能的生态平台
- 功能:管理broker、配置、ACL、管理topic
- 创建方式:KafkaAdminClient.create(props)
- 列出主题
- listTopics()
- 查看主题信息
- describeTopics(Arrays.asList(xx,yy))
- 创建主题
- createTopics(new NewTopic(name,replicaAssignment))
- 删除主题
- deleteTopics(Arrays.asList(xx,yy))
- 其他管理
- 动态参数管理
- 修改配置:alterConfigs(Map<ConfigResource,Config>)
- 分区管理
- 新增分区:createPartitions(Map<String,NewPartitions> map)
Kafka教程(二)API开发-生产者、消费者、topic的更多相关文章
- Hadoop生态圈-Kafka的旧API实现生产者-消费者
Hadoop生态圈-Kafka的旧API实现生产者-消费者 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.旧API实现生产者-消费者 1>.开启kafka集群 [yinz ...
- Hadoop生态圈-Kafka的新API实现生产者-消费者
Hadoop生态圈-Kafka的新API实现生产者-消费者 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Kafka 教程(二)-安装与基础操作
单机安装 1. 安装 java 2. 安装 zookeeper [这一步可以没有,因为 kafka 自带了 zookeeper] 3. 安装 kafka 下载链接 kafka kafka 是 scal ...
- 使用Win32 API实现生产者消费者线程同步
使用win32 API创建线程,创建信号量用于线程的同步 创建信号量 语法例如以下 HANDLE semophore; semophore = CreateSemaphore(lpSemaphoreA ...
- RabbitMQ入门学习系列(二),单生产者消费者
友情提示 我对我的文章负责,发现好多网上的文章 没有实践,都发出来的,让人走很多弯路,如果你在我的文章中遇到无法实现,或者无法走通的问题.可以直接在公众号<爱码农爱生活 >留言.必定会再次 ...
- 【Windows】用信号量实现生产者-消费者模型
线程并发的生产者-消费者模型: 1.两个进程对同一个内存资源进行操作,一个是生产者,一个是消费者. 2.生产者往共享内存资源填充数据,如果区域满,则等待消费者消费数据. 3.消费者从共享内存资源取数据 ...
- Python 使用python-kafka类库开发kafka生产者&消费者&客户端
使用python-kafka类库开发kafka生产者&消费者&客户端 By: 授客 QQ:1033553122 1.测试环境 python 3.4 zookeeper- ...
- Kafka技术内幕 读书笔记之(三) 生产者——消费者:高级API和低级API——基础知识
1. 使用消费组实现消息队列的两种模式 分布式的消息系统Kafka支持多个生产者和多个消费者,生产者可以将消息发布到集群中不同节点的不同分区上:消费者也可以消费集群中多个节点的多个分区上的消息 . 写 ...
- centos7单机安装kafka,进行生产者消费者测试
[转载请注明]: 原文出处:https://www.cnblogs.com/jstarseven/p/11364852.html 作者:jstarseven 码字挺辛苦的..... 一.k ...
- kafka集群搭建和使用Java写kafka生产者消费者
1 kafka集群搭建 1.zookeeper集群 搭建在110, 111,112 2.kafka使用3个节点110, 111,112 修改配置文件config/server.properties ...
随机推荐
- kvm上已安装的虚拟机修改为桥接网络
kvm上安装的虚拟机默认使用的nat网络格式,现在已经调整kvm主机为桥接方式了,但是已经安装的虚拟机还是nat方式,所以需要修改一下 让KVM虚拟主机使用桥接网络br0 修改虚拟机的配置文件,默认存 ...
- 17. Fluentd输出插件:out_copy用法详解
copy即复制,out_copy的作用就是将日志事件复制到多个输出,这样就可以对同一份日志做不同类型的分析处理. out_copy内置于Fluentd,无需单独安装. 示例配置 <match p ...
- 基于python的端口扫描
前言 端口扫描是指某些别有用心的人发送一组端口扫描消息,试图以此侵入某台计算机,并了解其提供的计算机网络服务类型(这些网络服务均与端口号相关).端口扫描是计算机解密高手喜欢的一种方式.攻击者可以通过它 ...
- Optional源码解析与实践
1 导读 NullPointerException在开发过程中经常遇到,稍有不慎小BUG就出现了,如果避免这个问题呢,Optional就是专门解决这个问题的类,那么Optional如何使用呢?让我们一 ...
- Python中list列表的常见操作
Python的list是一个列表,用方括号包围,不同元素间用逗号分隔. 列表的数据项不需要具有相同的类型.(列表还可以嵌套,即列表中的列表) 每个元素都有一个索引(表示位置),从0开始:可以用索引-1 ...
- WPF开发经验-实现自带触控键盘的TextBox
一 引入 项目有个新需求,当点击或触碰TextBox时,基于TextBox的相对位置,弹出一个自定义的Keyboard,如下图所示: 二 KeyboardControl 先实现一个自定义的Keyboa ...
- C++面向对象编程之虚函数与多态和继承和复合下的构造和析构
1.对于非虚函数,是不希望派生类对该函数重新定义: 对于virtual函数,在父类已经有默认定义后,并希望子类重新定义它: 对于pure virtual函数,父类没有默认定义,派生类必须要重新定义它: ...
- NOIP2003 普及组 洛谷P1045 麦森数 (快速幂+高精度)
有两个问题:求位数和求后500位的数. 求位数:最后减去1对答案的位数是不影响的,就是求2p的位数,直接有公式log10(2)*p+1; 求后500位的数:容易想到快速幂和高精度: 1 #includ ...
- Windows Socket 接口简介
Windows Socket接口是Windows下网络编程的接口,在介绍Windows Socket接口之前,首先要简单介绍一下TCP/IP协议和描述网络系统架构的 OSI模型,以及TCP/IP模型 ...
- JavaFx 使用字体图标记录
原文:JavaFx 使用字体图标记录 - Stars-One的杂货小窝 之前其实也是研究过关于字体图标的使用,还整了个库Tornadofx学习笔记(4)--IconTextFx开源库,整合5000+个 ...