yolo回归型的物体检测
本弱又搬了另外一个博客的讲解:
缩进YOLO全称You Only Look Once: Unified, Real-Time Object Detection,是在CVPR2016提出的一种目标检测算法,核心思想是将目标检测转化为回归问题求解,并基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。YOLO与Faster RCNN有以下区别:
- Faster RCNN将目标检测分解为分类为题和回归问题分别求解:首先采用独立的RPN网络专门求取region proposal,即计算图1中的P(objetness);然后对利用bounding box regression对提取的region proposal进行位置修正,即计算图1中的Box offsets(回归问题);最后采用softmax进行分类(分类问题)。
- YOLO将物体检测作为一个回归问题进行求解:输入图像经过一次网络,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。

缩进可以看出,YOLO将整个检测问题整合为一个回归问题,使得网络结构简单,检测速度大大加快;由于网络没有分支,所以训练也只需要一次即可完成。这种“把检测转化为回归问题”的思路非常有效,之后的很多检测算法(包括SSD)都借鉴了此思路。
1. YOLO网络结构

缩进上图2中展示了YOLO的网络结构。相比Faster RCNN,YOLO结构简单而,网络中只包含conv,relu,pooling和全连接层,以及最后用来综合信息的detect层。其中使用了1x1卷积用于多通道信息融合(若不明白1x1卷积请查看上一篇Faster RCNN文章)。
2. YOLO核心思想

图3
YOLO的工作过程分为以下几个过程:
(1) 将原图划分为SxS的网格。如果一个目标的中心落入某个格子,这个格子就负责检测该目标。
(2) 每个网格要预测B个bounding boxes,以及C个类别概率Pr(classi|object)。这里解释一下,C是网络分类总数,由训练时决定。在作者给出的demo中C=20,包含以下类别:
人person
鸟bird、猫cat、牛cow、狗dog、马horse、羊sheep
飞机aeroplane、自行车bicycle、船boat、巴士bus、汽车car、摩托车motorbike、火车train
瓶子bottle、椅子chair、餐桌dining table、盆景potted plant、沙发sofa、显示器tv/monitor
在YOLO中,每个格子只有一个C类别,即相当于忽略了B个bounding boxes,每个格子只判断一次类别,这样做非常简单粗暴。
(3) 每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的box中含有目标的置信度和这个bounding box预测的有多准两重信息:

如果有目标落中心在格子里Pr(Object)=1;否则Pr(Object)=0。 第二项是预测的bounding box和实际的ground truth之间的IOU。
缩进所以,每个bounding box都包含了5个预测量:(x, y, w, h, confidence),其中(x, y)代表预测box相对于格子的中心,(w, h)为预测box相对于图片的width和height比例,confidence就是上述置信度。需要说明,这里的x, y, w和h都是经过归一化的,之后有解释。
(4) 由于输入图像被分为SxS网格,每个网格包括5个预测量:(x, y, w, h, confidence)和一个C类,所以网络输出是SxSx(5xB+C)大小
(5) 在检测目标的时候,每个网格预测的类别条件概率和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:

显然这个class-specific confidence score既包含了bounding box最终属于哪个类别的概率,又包含了bounding box位置的准确度。最后设置一个阈值与class-specific confidence score对比,过滤掉score低于阈值的boxes,然后对score高于阈值的boxes进行非极大值抑制(NMS, non-maximum suppression)后得到最终的检测框体。
3. YOLO中的Bounding Box Normalization
缩进YOLO在实现中有一个重要细节,即对bounding box的坐标(x, y, w, h)进行了normalization,以便进行回归。作者认为这是一个非常重要的细节。在原文2.2 Traing节中有如下一段:
Our final layer predicts both class probabilities and bounding box coordinates.
We normalize the bounding box width and height by the image width and height so that they fall between 0 and 1.
We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1.
缩进接下来分析一下到底如何实现。

图4 SxS网格与bounding box关系(图中S=7,row=4且col=1)
缩进如图4,在YOLO中输入图像被分为SxS网格。假设有一个bounding box(如图4红框),其中心刚好落在了(row,col)网格中,则这个网格需要负责预测整个红框中的dog目标。假设图像的宽为widthimage,高为heightimage;红框中心在(xc,yc),宽为widthbox,高为heightbox那么:
(1) 对于bounding box的宽和高做如下normalization,使得输出宽高介于0~1:

(2) 使用(row, col)网格的offset归一化bounding box的中心坐标:

经过上述公式得到的normalization的(x, y, w, h),再加之前提到的confidence,共同组成了一个真正在网络中用于回归的bounding box;而当网络在Test阶段(x, y, w, h)经过反向解码又可得到目标在图像坐标系的框,解码代码在darknet detection_layer.c中的get_detection_boxes()函数,关键部分如下:
- boxes[index].x = (predictions[box_index + 0] + col) / l.side * w;
- boxes[index].y = (predictions[box_index + 1] + row) / l.side * h;
- boxes[index].w = pow(predictions[box_index + 2], (l.sqrt?2:1)) * w;
- boxes[index].h = pow(predictions[box_index + 3], (l.sqrt?2:1)) * h;
而w和h就是图像宽高,l.side是上文中提到的S。
4. YOLO训练过程
缩进对于任何一种网络,loss都是非常重要的,直接决定网络效果的好坏。YOLO的Loss函数设计时主要考虑了以下3个方面
(1) bounding box的(x, y, w, h)的坐标预测误差。
缩进在检测算法的实际使用中,一般都有这种经验:对不同大小的bounding box预测中,相比于大box大小预测偏一点,小box大小测偏一点肯定更不能被忍受。所以在Loss中同等对待大小不同的box是不合理的。为了解决这个问题,作者用了一个比较取巧的办法,即对w和h求平方根进行回归。从后续效果来看,这样做很有效,但是也没有完全解决问题。
(2) bounding box的confidence预测误差
缩进由于绝大部分网格中不包含目标,导致绝大部分box的confidence=0,所以在设计confidence误差时同等对待包含目标和不包含目标的box也是不合理的,否则会导致模型不稳定。作者在不含object的box的confidence预测误差中乘以惩罚权重λnoobj=0.5。
缩进除此之外,同等对待4个值(x, y, w, h)的坐标预测误差与1个值的conference预测误差也不合理,所以作者在坐标预测误差误差之前乘以权重λcoord=5(至于为什么是5而不是4,我也不知道T_T)。
(3) 分类预测误差
缩进即每个box属于什么类别,需要注意一个网格只预测一次类别,即默认每个网格中的所有B个bounding box都是同一类。
所以,YOLO的最终误差为下:
Loss = λcoord * 坐标预测误差 + (含object的box confidence预测误差 + λnoobj * 不含object的box confidence预测误差) + 分类误差
=

-------------------------------------------------------下面是一点参考内容--------------------------------------------------------
缩进在各种常用框架中实现网络中一般需要完成forward与backward过程,forward函数只需依照Loss编码即可,而backward函数简需要计算残差delta。这里单解释一下YOLO的负反馈,即backward的实现方法。在UFLDL教程中网络正向传播方式定义为:
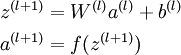
而最后一层反向传播残差定义为:
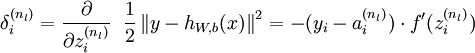
对于YOLO来说,最后一层是detection_layer,而倒数第二层是connected_layer(全连接层),之间没有ReLU层,即相当于最后一层的激活函数为:

那么,对于detection_layer的残差就变为:

只需计算每一项的参数训练目标值与网络输出值之差,反向回传即可,与代码对应。其他细节读者请自行分析代码,不再介绍。
5. 结果分析
缩进在论文中,作者给出了YOLO与Fast RCNN检测结果对比,如下图。YOLO对背景的误判率(4.75%)比Fast RCNN的误判率(13.6%)低很多。但是YOLO的定位准确率较差,占总误差比例的19.0%,而fast rcnn仅为8.6%。这说明了YOLO中把检测转化为回归的思路有较好的precision,但是bounding box的定位方法还需要进一步改进。

缩进综上所述,YOLO有如下特点:
- 快。YOLO将物体检测作为回归问题进行求解,整个检测网络pipeline简单,且训练只需一次完成。
- 背景误检率低。YOLO在训练和推理过程中能“看到”整张图像的整体信息,而基于region proposal的物体检测方法(如Fast RCNN)在检测过程中,只“看到”候选框内的局部图像信息。因此,若当图像背景(非物体)中的部分数据被包含在候选框中送入检测网络进行检测时,容易被误检测成物体[1]。
- 识别物体位置精准性差,√w和√h策略并没有完全解决location准确度问题。
- 召回率低,尤其是对小目标。
缺陷:
YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
yolo回归型的物体检测的更多相关文章
- 物体检测丨浅析One stage detector「YOLOv1、v2、v3、SSD」
引言 之前做object detection用到的都是two stage,one stage如YOLO.SSD很少接触,这里开一篇blog简单回顾该系列的发展.很抱歉,我本人只能是蜻蜓点水,很多细节也 ...
- 手把手教你用深度学习做物体检测(五):YOLOv1介绍
"之前写物体检测系列文章的时候说过,关于YOLO算法,会在后续的文章中介绍,然而,由于YOLO历经3个版本,其论文也有3篇,想全面的讲述清楚还是太难了,本周终于能够抽出时间写一些YOLO算法 ...
- 『计算机视觉』物体检测之RefineDet系列
Two Stage 的精度优势 二阶段的分类:二步法的第一步在分类时,正负样本是极不平衡的,导致分类器训练比较困难,这也是一步法效果不如二步法的原因之一,也是focal loss的motivation ...
- YOLT:将YOLO用于卫星图像目标检测
之前作者用滑动窗口和HOG来进行船体监测,在开放水域和港湾取得了不错的成绩,但是对于不一致的复杂背景,这个方法的性能会下降.为了解决这个缺点,作者使用YOLO作为物体检测的流水线,这个方法相比于HOG ...
- 10分钟学会使用YOLO及Opencv实现目标检测(下)|附源码
将YOLO应用于视频流对象检测 首先打开 yolo_video.py文件并插入以下代码: # import the necessary packages import numpy as np impo ...
- 物体检测之FPN及Mask R-CNN
对比目前科研届普遍喜欢把问题搞复杂,通过复杂的算法尽量把审稿人搞蒙从而提高论文的接受率的思想,无论是著名的残差网络还是这篇Mask R-CNN,大神的论文尽量遵循著名的奥卡姆剃刀原理:即在所有能解决问 ...
- 转-------基于R-CNN的物体检测
基于R-CNN的物体检测 原文地址:http://blog.csdn.net/hjimce/article/details/50187029 作者:hjimce 一.相关理论 本篇博文主要讲解2014 ...
- 机器学习_线性回归和逻辑回归_案例实战:Python实现逻辑回归与梯度下降策略_项目实战:使用逻辑回归判断信用卡欺诈检测
线性回归: 注:为偏置项,这一项的x的值假设为[1,1,1,1,1....] 注:为使似然函数越大,则需要最小二乘法函数越小越好 线性回归中为什么选用平方和作为误差函数?假设模型结果与测量值 误差满足 ...
- 物体检测丨Faster R-CNN详解
这篇文章把Faster R-CNN的原理和实现阐述得非常清楚,于是我在读的时候顺便把他翻译成了中文,如果有错误的地方请大家指出. 原文:http://www.telesens.co/2018/03/1 ...
随机推荐
- Eve-NG-Toolkit
Eve-NG-Toolkit 来源 http://www.emulatedlab.com/archives/694 参考 http://eve-ng.cn/doku.php http://foru ...
- [SHOI2011]双倍回文 manacher
题面: 洛谷:[SHOI2011]双倍回文‘ 题解: 首先有一个性质,本质不同的回文串最多O(n)个. 所以我们可以对于每个i,求出以这个i为结尾的最长回文串,然后以此作为长串,并判断把这个长串从中间 ...
- 【EF】EntityFramework DBFirst的使用
一.前言 久闻EF大名,之前做C/S产品用的是Dapper对SqlLite进行ORM.然后接触公司授权系统后发现用的是EntityFramework对SQLSever进行ORM.授权系统 ...
- 【BZOJ4596】黑暗前的幻想乡(矩阵树定理,容斥)
[BZOJ4596]黑暗前的幻想乡(矩阵树定理,容斥) 题面 BZOJ 有\(n\)个点,要求连出一棵生成树, 指定了一些边可以染成某种颜色,一共\(n-1\)种颜色, 求所有颜色都出现过的生成树方案 ...
- MySQL用户授权
一.授权语法格式 grant 权限列表 on 数据库名.表名 to '用户名'@'客户端主机' [identified by '密码']; 单词: privileges [ˈprivilidʒz] ...
- 阿里云ECS环境部署 centos 6.5
阿里云ESC服务器1 先挂载磁盘 参考:http://help.aliyun.com/view/11108189_13491193.html?spm=5176.2020520101.121.2.1wc ...
- 服务器启动脚本 /etc/rc.local
#启动php-frm/home/www/php/sbin/php-fpm #启动搜索引擎/home/www/se/bin/xs-ctl.sh start #启动lighttpd/home/www/li ...
- Win8Metro(C#)数字图像处理--2.40二值图像轮廓提取
http://dongtingyueh.blog.163.com/blog/static/4619453201271481335630/ [函数名称] 二值图像轮廓提取 Contour ...
- [USACO12DEC] 逃跑的BarnRunning Away From…(主席树)
[USACO12DEC]逃跑的BarnRunning Away From- 题目描述 It's milking time at Farmer John's farm, but the cows hav ...
- tomcat8 的 websocket 支持
使用 tomcat8 开发 WebSocket 服务端非常简单,大致有如下两种方式. 1.使用注解方式开发,被 @ServerEndpoint 修饰的 Java 类即可作为 WebSocket 服务端 ...