<node.js爬虫>制作教程
前言:最近想学习node.js,突然在网上看到基于node的爬虫制作教程,所以简单学习了一下,把这篇文章分享给同样初学node.js的朋友。
目标:爬取 http://tweixin.yueyishujia.com/webapp/build/html/ 网站的所有门店发型师的基本信息。
思路:访问上述网站,通过chrome浏览器的network对网页内容分析,找到获取各个门店发型师的接口,对参数及返回数据进行分析,遍历所有门店的所有发型师,直到遍历完毕,同事将信息存储到本地。
步骤一:安装node.js
下载并安装node,此步骤比较简单就不详细解释了,有问题的可以直接问一下度娘。
步骤二:建立工程
1)打开dos命令条,cd进入想要创建项目的路径(我将此项目直接放在了E盘,以下皆以此路径为例);
2)mkdir node (创建一个文件夹用来存放项目,我这里取名为node);
3)cd 进入名为node的文件夹,并执行npm init初始化工程(期间会让填写一些信息,我是直接回车的);
步骤三:创建爬取到的数据存放的文件夹
1)创建data文件夹用来存放发型师基本信息;
2)创建image文件夹用来存储发型师头像图片;
此时工程下文件如下:

步骤四:安装第三方依赖包(fs是内置模块,不需要单独安装)
1)npm install cheerio –save
2)npm install superagent –save
3)npm install async –save
4)npm install request –save
分别简单解释一下上面安装的依赖包:
cheerio:是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现,则能够对请求结果进行解析,解析方式和jQuery的解析方式几乎完全相同;
superagent:能够实现主动发起get/post/delete等请求;
async:async模块是为了解决嵌套金字塔,和异步流程控制而生,由于nodejs是异步编程模型,有一些在同步编程中很容易做到的事情,现在却变得很麻烦。Async的流程控制就是为了简化这些操作;
request:有了这个模块,http请求变的超简单,Request使用简单,同时支持https和重定向;
步骤五:编写爬虫程序代码
打开hz.js,编写代码:
var superagent = require('superagent');
var cheerio = require('cheerio');
var async = require('async');
var fs = require('fs');
var request = require('request');
var page=1; //获取发型师处有分页功能,所以用该变量控制分页
var num = 0;//爬取到的信息总条数
var storeid = 1;//门店ID
console.log('爬虫程序开始运行......');
function fetchPage(x) { //封装函数
startRequest(x);
}
function startRequest(x) {
superagent
.post('http://tweixin.yueyishujia.com/v2/store/designer.json')
.send({
// 请求的表单信息Form data
page : x,
storeid : storeid
})
// Http请求的Header信息
.set('Accept', 'application/json, text/javascript, */*; q=0.01')
.set('Content-Type','application/x-www-form-urlencoded; charset=UTF-8')
.end(function(err, res){
// 请求返回后的处理
// 将response中返回的结果转换成JSON对象
if(err){
console.log(err);
}else{
var designJson = JSON.parse(res.text);
var deslist = designJson.data.designerlist;
if(deslist.length > 0){
num += deslist.length;
// 并发遍历deslist对象
async.mapLimit(deslist, 5,
function (hair, callback) {
// 对每个对象的处理逻辑
console.log('...正在抓取数据ID:'+hair.id+'----发型师:'+hair.name);
saveImg(hair,callback);
},
function (err, result) {
console.log('...累计抓取的信息数→→' + num);
}
);
page++;
fetchPage(page);
}else{
if(page == 1){
console.log('...爬虫程序运行结束~~~~~~~');
console.log('...本次共爬取数据'+num+'条...');
return;
}
storeid += 1;
page = 1;
fetchPage(page);
}
}
});
}
fetchPage(page);
function saveImg(hair,callback){
// 存储图片
var img_filename = hair.store.name+'-'+hair.name + '.png';
var img_src = 'http://photo.yueyishujia.com:8112' + hair.avatar; //获取图片的url
//采用request模块,向服务器发起一次请求,获取图片资源
request.head(img_src,function(err,res,body){
if(err){
console.log(err);
}else{
request(img_src).pipe(fs.createWriteStream('./image/' + img_filename)); //通过流的方式,把图片写到本地/image目录下,并用发型师的姓名和所属门店作为图片的名称。
console.log('...存储id='+hair.id+'相关图片成功!');
}
});
// 存储照片相关信息
var html = '姓名:'+hair.name+'<br>职业:'+hair.jobtype+'<br>职业等级:'+hair.jobtitle+'<br>简介:'+hair.simpleinfo+'<br>个性签名:'+hair.info+'<br>剪发价格:'+hair.cutmoney+'元<br>店名:'+hair.store.name+'<br>地址:'+hair.store.location+'<br>联系方式:'+hair.telephone+'<br>头像:<img src='+img_src+' style="width:200px;height:200px;">';
fs.appendFile('./data/' +hair.store.name+'-'+ hair.name + '.html', html, 'utf-8', function (err) {
if (err) {
console.log(err);
}
});
callback(null, hair);
}
步骤六:运行爬虫程序
输入node hz.js命令运行爬虫程序,效果图如下:
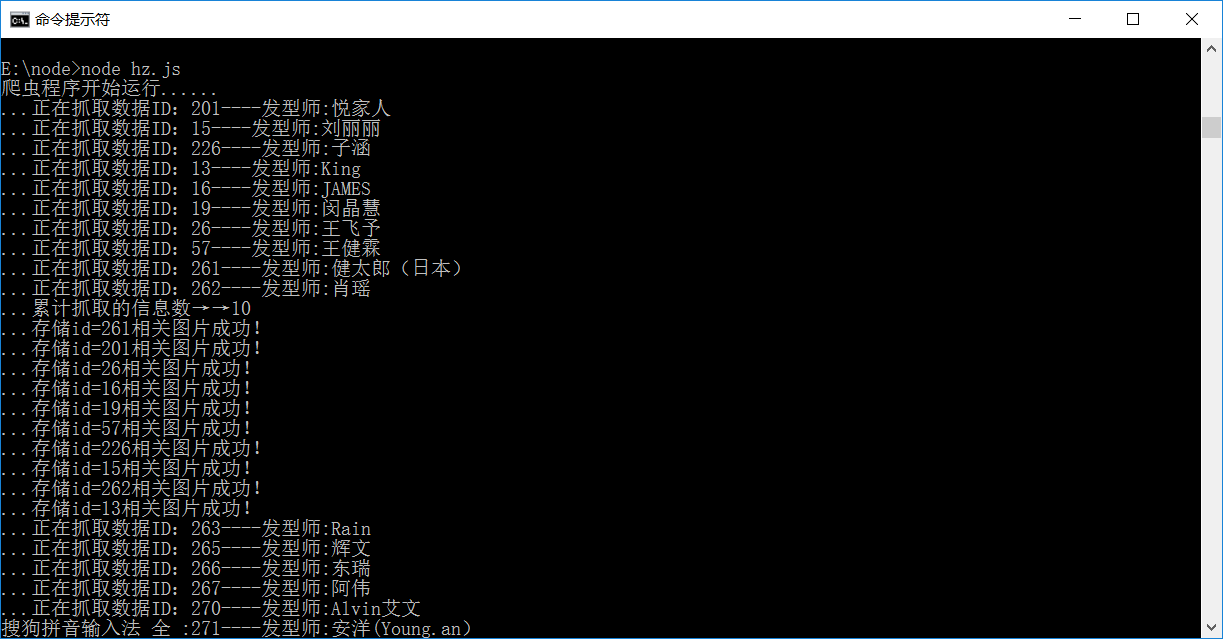
运行成功后,发型师基本信息以html文件的形式存储在data文件夹中,发型师头像图片存储在image文件夹下:
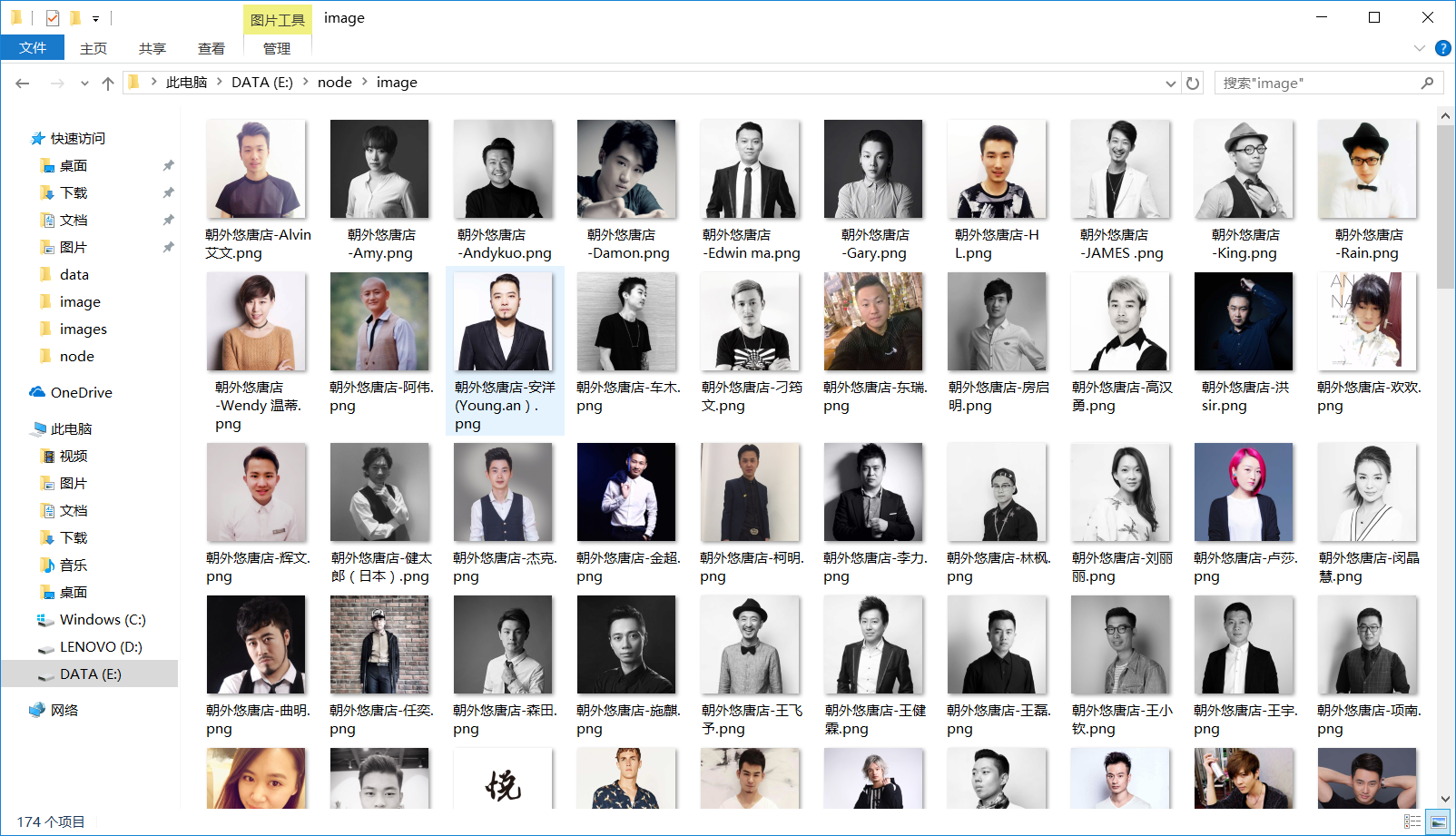
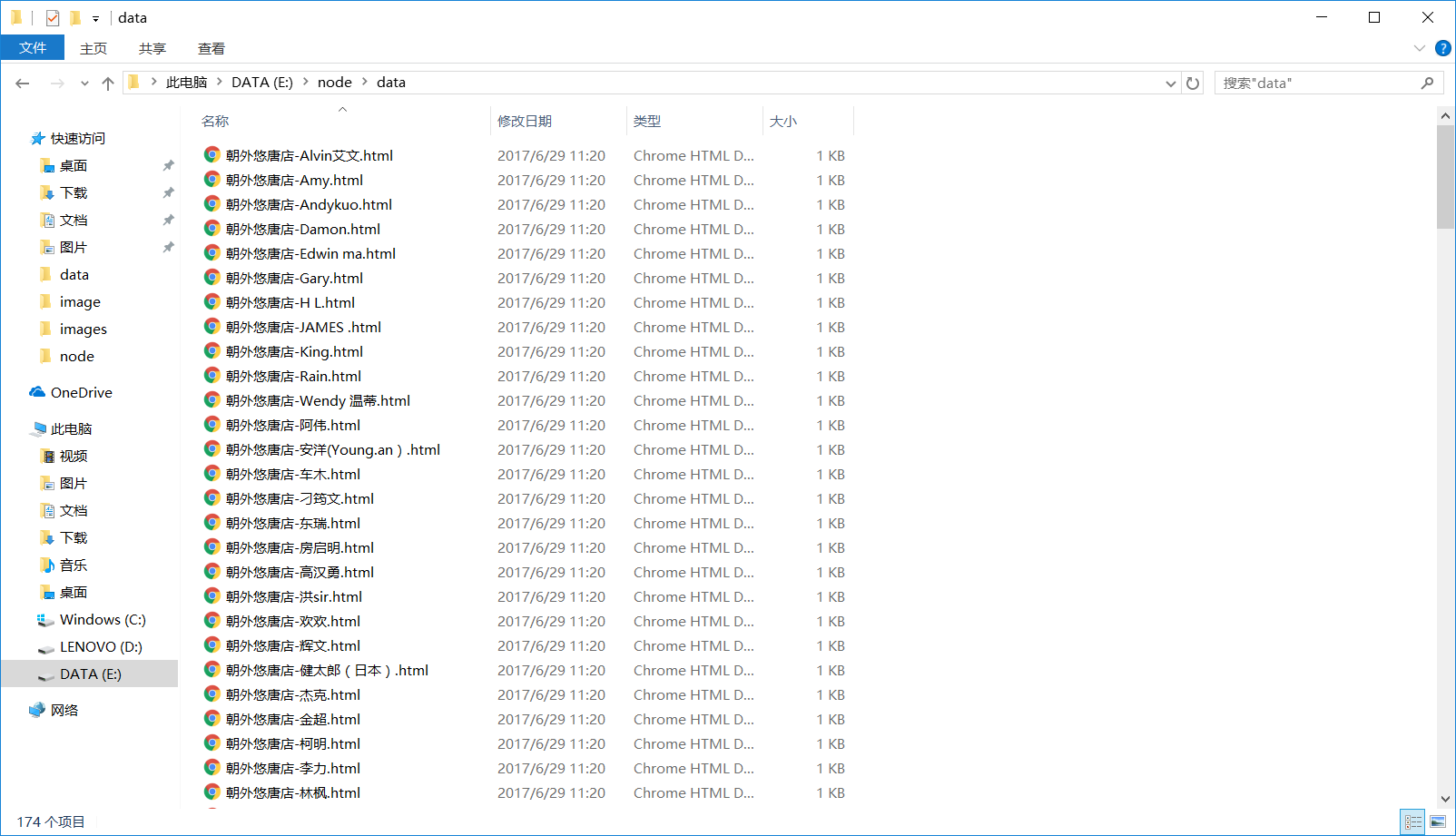
后记:到此一款基于node.js制作的简单爬虫就大功告成了,由于我也是初学者,好多地方也不是很理解,但好在是自己完成了,不足之处敬请谅解。
代码下载地址:https://github.com/yanglei0323/nodeCrawler
<node.js爬虫>制作教程的更多相关文章
- node.js爬虫
这是一个简单的node.js爬虫项目,麻雀虽小五脏俱全. 本项目主要包含一下技术: 发送http抓取页面(http).分析页面(cheerio).中文乱码处理(bufferhelper).异步并发流程 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- Node.js aitaotu图片批量下载Node.js爬虫1.00版
即使是https网页,解析的方式也不是一致的,需要多试试. 代码: //====================================================== // aitaot ...
- Node.js umei图片批量下载Node.js爬虫1.00
这个爬虫在abaike爬虫的基础上改改图片路径和下一页路径就出来了,代码如下: //====================================================== // ...
- Node.js abaike图片批量下载Node.js爬虫1.01版
//====================================================== // abaike图片批量下载Node.js爬虫1.01 // 1.01 修正了输出目 ...
- Node.js abaike图片批量下载Node.js爬虫1.00版
这个与前作的差别在于地址的不规律性,需要找到下一页的地址再爬过去找. //====================================================== // abaik ...
- Node JS爬虫:爬取瀑布流网页高清图
原文链接:Node JS爬虫:爬取瀑布流网页高清图 静态为主的网页往往用get方法就能获取页面所有内容.动态网页即异步请求数据的网页则需要用浏览器加载完成后再进行抓取.本文介绍了如何连续爬取瀑布流网页 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- 养只爬虫当宠物(Node.js爬虫爬取58同城租房信息)
先上一个源代码吧. https://github.com/answershuto/Rental 欢迎指导交流. 效果图 搭建Node.js环境及启动服务 安装node以及npm,用express模块启 ...
随机推荐
- sloop公共程序之初始过程及启动
1:sloop_init() 初始化主要是初始化静态sloop_*** 结构体和填充struct sloop_data 结构体中的成员. //初始化静态存储区给sloop_***结构体 static ...
- Jenkins基于角色的项目权限管理
参考博客:http://www.cnblogs.com/davidwang456/p/3701972.html 一.简介 由于jenkins默认的权限管理体系不支持用户组或角色的配置,因此需要安装第三 ...
- 网站访问日志User Agent对照表
percent useragent system user_agent_string_md5 8.9% Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleW ...
- Hbuider制作app升级包的简单办法 (升级官方提供的案例)
源文档:http://ask.dcloud.net.cn/question/11795 http://ask.dcloud.net.cn/article/199 一.生成移动App资源升级包 5+应用 ...
- Windows API函数大全(精心总结)
WindowsAPI函数大全(精心总结) 目录 1. API之网络函数... 1 2. API之消息函数... 1 3. API之文件处理函数... 2 4. API之打印函数... 5 5. ...
- Python进行数据分析(一)初步学习 对时区进行计数
time_zones[:10] Out[19]: [u'America/New_York', u'America/Denver', u'America/New_York', u'America/Sao ...
- Mahout源码目录说明&&算法集
Mahout源码目录说明 mahout项目是由多个子项目组成的,各子项目分别位于源码的不同目录下,下面对mahout的组成进行介绍: 1.mahout-core:核心程序模块,位于/core目录下: ...
- 从零搭建SSM框架(二)运行工程
启动cnki-manager工程 1.需要在cnki-manager 的pom工程中,配置tomcat插件.启动的端口号,和工程名称. 在cnki-manager的pom文件中添加如下配置: < ...
- 【CodeForces】915 E. Physical Education Lessons 线段树
[题目]E. Physical Education Lessons [题意]10^9范围的区间覆盖,至多3*10^5次区间询问. [算法]线段树 [题解]每次询问至多增加两段区间,提前括号分段后线段树 ...
- 20155117王震宇 2006-2007-2 《Java程序设计》第5周学习总结
教材学习内容总结 try & catch java中的错误会被打包成对象,可以尝试(try)捕捉(catch)代表错误的对象后做一些处理.如果发生错误,会跳到catch的区块并执行. 异常结构 ...