系统架构--分布式计算系统spark学习(三)
通过搭建和运行example,我们初步认识了spark。
大概是这么一个流程
------------------------------ ---------------------- ----------------------
| Application(spark shell) | <=> | Spark Master | <=> | Spark Slavers |
------------------------------ ---------------------- ----------------------
application 发送任务到master,master 接受任务,把上下文分解成一堆task list,把task下发给 Slavers去完成,
slavers完成之后,把结果上报给master,master汇总所有slavers的执行结果,返回给Application。
这里Application,可以是我们自己编写的进程(里面包含要进行分布式计算的数据位置,数据挖掘的算法等)。
但是我们可以看到官方的框架跟我们运行的几个进程好像对不上。
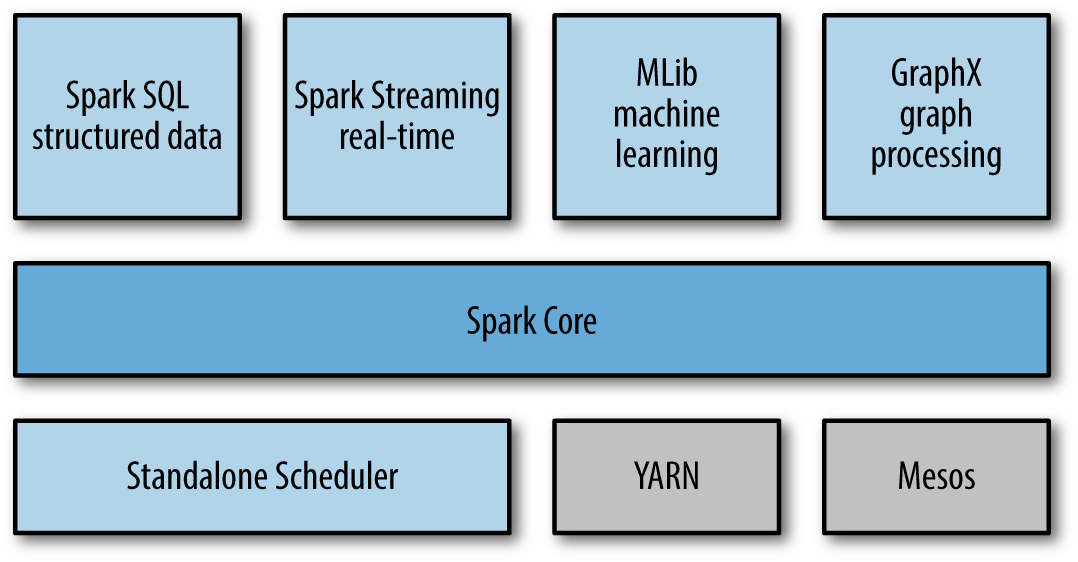
从图里面看到,spark跟mahout一样,更像是一个框架,提供核心功能,然后在核心基础上,又提供很多插件或者说库。
我们之前运行的standalone模式,由Standalone Scheduler来进行集群管理的,这个spark自带的, 看到它使跟Mesos,YARN放在一个层面的,YARN和Mesos怎么管理集群,不清楚,
但清楚的是,spark和它们兼容,可以运行在其之上。
Cluster Managers Under the hood, Spark is designed to efficiently scale up from one to many thousands of compute nodes. To achieve this while maximizing flexibility, Spark can run over a variety of cluster managers, including Hadoop YARN, Apache Mesos, and a simple cluster manager included in Spark itself called the Standalone Scheduler. If you are just installing Spark on an empty set of machines, the Standalone Scheduler provides an easy way to get started; if you already have a Hadoop YARN or Mesos cluster, however, Spark’s support for these cluster managers allows your applications to also run on them. Chapter 7 explores the different options and how to choose the correct cluster manager.
Spark SQL、Spark Streaming、MLlib等,是在spark core基础上的插件,方便开发者使用sql、支持stream流式数据(疑问:这个跟storm处理是否一样?),机器学习等。
这里最关键的就是spark core了,实现了基本的函数、任务调度、内存管理、容灾等。其中RDDS提供大部分API来跟spark master和其他插件进行交互。
Spark Core
Spark Core contains the basic functionality of Spark, including components for task scheduling, memory management, fault recovery, interacting with storage systems, and more. Spark Core is also home to the API that defines resilient distributed datasets (RDDs), which are Spark’s main programming abstraction. RDDs represent a collection of items distributed across many compute nodes that can be manipulated in parallel. Spark Core provides many APIs for building and manipulating these collections.
回过头来,看看我们启动的几个进程:
//spark shell
root 0.2 6.2 s000 S+ :29下午 :21.81 /usr/bin/java -cp :/private/var/spark/conf:/private/var/spark/lib/spark-assembly-1.3.-hadoop2.4.0.jar:/private/var/spark/lib/datanucleus-api-jdo-3.2..jar:/private/var/spark/lib/datanucleus-core-3.2..jar:/private/var/spark/lib/datanucleus-rdbms-3.2..jar -Dscala.usejavacp=true -Xms1g -Xmx1g org.apache.spark.deploy.SparkSubmit
--class org.apache.spark.repl.Main spark-shell
//spark master and worker root 0.8 12.7 pts/ Sl : : java -cp :/var/spark/sbin/../conf:/var/spark/lib/spark-assembly-1.3.-hadoop2.4.0.jar -XX:MaxPermSize=128m -Dspark.akka.logLifecycleEvents=true -Xms512m -Xmx512m
org.apache.spark.deploy.master.Master --ip qp-zhang --port --webui-port
root 0.9 11.3 ? Sl : : java -cp :/var/spark/sbin/../conf:/var/spark/lib/spark-assembly-1.3.-hadoop2.4.0.jar -XX:MaxPermSize=128m -Dspark.akka.logLifecycleEvents=true -Xms512m -Xmx512m
org.apache.spark.deploy.worker.Worker spark://qp-zhang:7077
是由不同的class基于spark core 和其他组件实现的。
系统架构--分布式计算系统spark学习(三)的更多相关文章
- Spark Standalone Mode 单机启动Spark -- 分布式计算系统spark学习(一)
spark是个啥? Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发. Spark和Hadoop有什么不同呢? Spark是基于map reduce算法实现的分布式计算,拥 ...
- 提交任务到spark master -- 分布式计算系统spark学习(四)
部署暂时先用默认配置,我们来看看如何提交计算程序到spark上面. 拿官方的Python的测试程序搞一下. qpzhang@qpzhangdeMac-mini:~/project/spark-1.3. ...
- 让spark运行在mesos上 -- 分布式计算系统spark学习(五)
mesos集群部署参见上篇. 运行在mesos上面和 spark standalone模式的区别是: 1)stand alone 需要自己启动spark master 需要自己启动spark slav ...
- Spark Standalone Mode 多机启动 -- 分布式计算系统spark学习(二)(更新一键启动slavers)
捣鼓了一下,先来个手动挡吧.自动挡要设置ssh无密码登陆啥的,后面开搞. 一.手动多台机链接master 手动链接master其实上篇已经用过. 这里有两台机器: 10.60.215.41 启动mas ...
- 2020年大厂Java面试题(基础+框架+系统架构+分布式+实战)
前言 作为一个Java开发者,Java架构师应该是大家的一个职业目标了吧. 要成为Java架构师,首先你要是一个高级Java工程师,熟练使用各种框架,并知道它们实现的原理.jvm虚拟机原理.调优,懂得 ...
- Storm系统架构以及代码结构学习
转自:http://blog.csdn.net/androidlushangderen/article/details/45955833 storm学习系列:http://blog.csdn.net/ ...
- Spark 学习(三) maven 编译spark 源码
spark 源码编译 scala 版本2.11.4 os:ubuntu 14.04 64位 memery 3G spark :1.1.0 下载源码后解压 1 准备环境,安装jdk和scala,具体参考 ...
- 第2-1-1章 FastDFS分布式文件服务背景及系统架构介绍
目录 1 背景 1.1 为什么需要分布式文件服务 1.1.1 单机时代 1.1.2 独立文件服务器 1.1.3 分布式文件系统 1.2 什么是FastDFS 2 系统架构 2.1 Tracker集群 ...
- 浅谈大型web系统架构
动态应用,是相对于网站静态内容而言,是指以c/c++.php.Java.perl..net等服务器端语言开发的网络应用软件,比如论坛.网络相册.交友.BLOG等常见应用.动态应用系统通常与数据库系统. ...
随机推荐
- strcmp在CTF中的案例
当strcmp比较出错的时候就会为null.null即为0故输出flag. strcmp(arr,str); ?test[]=1 <?php define('FLAG', 'pwnhub{THI ...
- SSL/TLS协议运行机制的概述_转
转自:SSL/TLS协议运行机制的概述 作者: 阮一峰 日期: 2014年2月 5日 互联网的通信安全,建立在SSL/TLS协议之上. 本文简要介绍SSL/TLS协议的运行机制.文章的重点是设计思想和 ...
- html 处理
近期做了一个后台管理网站,后台页面都是Html页面,里面再通过ajax访问后台服务.要做到比较好的用户体验,即:如果用户没有登录或没有权限马上调到登录页面,而不是等到页面加载后再ajax时判断是否登录 ...
- 核函数(kernel function)
百度百科的解释: 常用核函数: 1.线性核(Linear Kernel): 2.多项式核(Polynomial Kernel): 3.径向基核函数(Radial Basis Function),也叫高 ...
- Spring Cloud的子项目,大致可分成两类
Spring Cloud的子项目,大致可分成两类,一类是对现有成熟框架”Spring Boot化”的封装和抽象,也是数量最多的项目:第二类是开发了一部分分布式系统的基础设施的实现,如Spring Cl ...
- java---多线程及线程的概念
如果对什么是线程.什么是进程仍存有疑惑,请先Google之,因为这两个概念不在本文的范围之内. 用多线程只有一个目的,那就是更好的利用cpu的资源,因为所有的多线程代码都可以用单线程来实现.说这个话其 ...
- mysql --mysqli::multi_query 和 mysqli_multi_query
语法: 对象化:bool mysqli::multi_query ( string $query ) 过程化:bool mysqli_multi_query ( mysqli $link , stri ...
- 【BZOJ】1644: [Usaco2007 Oct]Obstacle Course 障碍训练课(bfs)
http://www.lydsy.com/JudgeOnline/problem.php?id=1644 这和原来一题用dp来做的bfs很像啊orz.. 我们设f[i][j][k]代表i,j这个点之前 ...
- 【BZOJ】1691: [Usaco2007 Dec]挑剔的美食家(set+贪心)
http://www.lydsy.com/JudgeOnline/problem.php?id=1691 懒得打平衡树了.... 而且multiset是很快的... 排到了rank1 T_T 贪心就是 ...
- [转]Loadrunner随机生成15位数字串
Loadrunner随机生成15位数字串 PS:http://www.51testing.com/html/43/6343-19789.html 今天看到一个网友的问题,是想生成一个15位的数字串来进 ...