Flink学习笔记:Flink开发环境搭建
本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1. 创建Flink项目及依赖管理
1.1创建Flink项目
官网创建Flink项目有两种方式:
https://ci.apache.org/projects/flink/flink-docs-release-1.6/quickstart/java_api_quickstart.html
方式一:
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-quickstart-java \
-DarchetypeVersion=1.6.2
方式二
$ curl https://flink.apache.org/q/quickstart.sh | bash -s 1.6.2

这里我们仍然使用第一种方式创建Flink项目。
打开终端,切换到对应的目录,通过maven创建flink项目
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.6.2
项目构建过程中需要输入groupId,artifactId,version和package
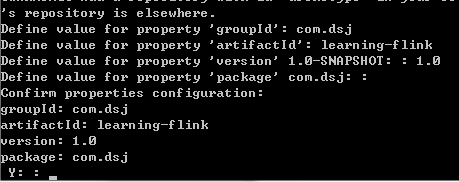
Flink项目创建成功

打开IDEA工具,点击open。

选择刚刚创建的flink项目
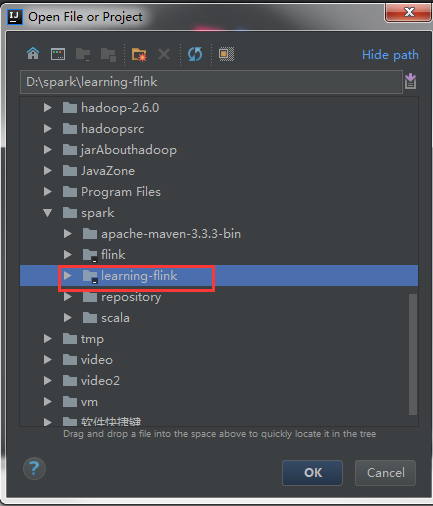
Flink项目已经成功导入IDEA开发工具

通过maven打包测试运行
mvn clean package
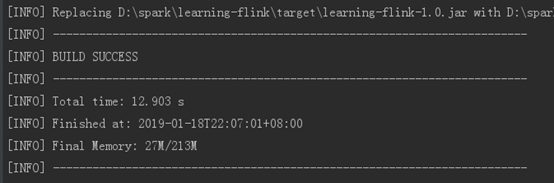
刷新target目录可以看到刚刚打包的flink项目

1.2. Flink依赖
Core Dependencies(核心依赖):
1.核心依赖打包在flink-dist*.jar里
2.包含coordination, networking, checkpoints, failover, APIs, operations (such as windowing), resource management等必须的依赖
注意:核心依赖不会随着应用打包(<scope>provided</scope>)
3.核心依赖项尽可能小,并避免依赖项冲突
Pom文件中添加核心依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.6.2</version>
<scope>provided</scope>
</dependency>
注意:不会随着应用打包。
User Application Dependencies(应用依赖):
connectors, formats, or libraries(CEP, SQL, ML)、
注意:应用依赖会随着应用打包(scope保持默认值就好)
Pom文件中添加应用依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.11</artifactId>
<version>1.6.2</version>
</dependency>
注意:应用依赖按需选择,会随着应用打包,可以通过Maven Shade插件进行打包。
1.3. 关于Scala版本
Scala各版本之间是不兼容的(你基于Scala2.12开发Flink应用就不能依赖Scala2.11的依赖包)。
只使用Java的开发人员可以选择任何Scala版本,Scala开发人员需要选择与他们的应用程序的Scala版本匹配的Scala版本。
1.4. Hadoop依赖
不要把Hadoop依赖直接添加到Flink application,而是:
export HADOOP_CLASSPATH=`hadoop classpath`
Flink组件启动时会使用该环境变量的
特殊情况:如果在Flink application中需要用到Hadoop的input-/output format,只需引入Hadoop兼容包即可(Hadoop compatibility wrappers)
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_2.11</artifactId>
<version>1.6.2</version>
</dependency>
1.5 Flink项目打包
Flink 可以使用maven-shade-plugin对Flink maven项目进行打包,具体打包命令为mvn clean package。
2. 自己编译Flink
2.1安装maven
1.下载
到maven官网下载安装包,这里我们可以选择使用apache-maven-3.3.9-bin.tar.gz。
2.解压
将apache-maven-3.3.9-bin.tar.gz安装包上传至主节点的,然后使用tar命令进行解压
tar -zxvf apache-maven-3.3.9-bin.tar.gz
3.创建软连接
ln -s apache-maven-3.3.9 maven
4.配置环境变量
vi ~/.bashrc
export MAVEN_HOME=/home/hadoop/app/maven
export PATH=$MAVEN_HOME/bin:$PATH
5.生效环境变量
source ~/.bashrc
6.查看maven版本
mvn –version
7. settings.xml配置阿里镜像
添加阿里镜像
<mirror>
<id>nexus-osc</id>
<mirrorOf>*</mirrorOf>
<name>Nexus osc</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central</url>
</mirror>
2.2安装jdk
编译flink要求jdk8或者以上版本,这里已经提前安装好jdk1.8,具体安装配置不再赘叙,查看版本如下:
[hadoop@cdh01 conf]$ java -version
java version "1.8.0_51"
Java(TM) SE Runtime Environment (build 1.8.0_51-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.51-b03, mixed mode)
2.3下载源码
登录github:https://github.com/apache/flink,获取flink下载地址:https://github.com/apache/flink.git
打开Flink主节点终端,进入/home/hadoop/opensource目录,通过git clone下载flink源码:
git clone https://github.com/apache/flink.git
错误1:如果Linux没有安装git,会报如下错误:
bash: git: command not found
解决:git安装步骤如下所示:
1.安装编译git时需要的包(注意需要在root用户下安装)
yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel
yum install gcc perl-ExtUtils-MakeMaker
2.删除已有的git
yum remove git
3.下载git源码
先安装wget
yum -y install wget
使用wget下载git源码
wget https://www.kernel.org/pub/software/scm/git/git-2.0.5.tar.gz
解压git
tar xzf git-2.0.5.tar.gz
编译安装git
cd git-2.0.5
make prefix=/usr/local/git all
sudo make prefix=/usr/local/git install
echo "export PATH=$PATH:/usr/local/git/bin" >> ~/.bashrc
source ~/.bashrc
查看git版本
git –version
错误2:git clone https://github.com/apache/flink.git
Cloning into 'flink'...
fatal: unable to access 'https://github.com/apache/flink.git/': SSL connect error
解决:
升级 nss 版本:yum update nss
2.4切换对应flink版本
使用如下命令查看flink版本分支
git tag
切换到flink对应版本(这里我们使用flink1.6.2)
git checkout release-1.6.2
2.5编译flink
进入flink 源码根目录:/home/hadoop/opensource/flink,通过maven编译flink
mvn clean install -DskipTests -Dhadoop.version=2.6.0
报错:
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 06:58 min
[INFO] Finished at: 2019-01-18T22:11:54-05:00
[INFO] Final Memory: 106M/454M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal on project flink-mapr-fs: Could not resolve dependencies for project org.apache.flink:flink-mapr-fs:jar:1.6.2: Could not find artifact com.mapr.hadoop:maprfs:jar:5.2.1-mapr in nexus-osc (http://maven.aliyun.com/nexus/content/repositories/central) -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :flink-mapr-fs
报错缺失flink-mapr-fs,需要手动下载安装。
解决:
1.下载maprfs jar包
通过手动下载maprfs-5.2.1-mapr.jar包,下载地址地址:https://repository.mapr.com/nexus/content/groups/mapr-public/com/mapr/hadoop/maprfs/5.2.1-mapr/
2.上传至主节点
将下载的maprfs-5.2.1-mapr.jar包上传至主节点的/home/hadoop/downloads目录下。
3.手动安装
手动安装缺少的包到本地仓库
mvn install:install-file -DgroupId=com.mapr.hadoop -DartifactId=maprfs -Dversion=5.2.1-mapr -Dpackaging=jar -Dfile=/home/hadoop/downloads/maprfs-5.2.1-mapr.jar
4.继续编译
使用maven继续编译flink(可以排除刚刚已经安装的包)
mvn clean install -Dmaven.test.skip=true -Dhadoop.version=2.7.3 -rf :flink-mapr-fs
报错:
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 05:51 min
[INFO] Finished at: 2019-01-18T22:39:20-05:00
[INFO] Final Memory: 108M/480M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.1:compile (default-compile) on project flink-mapr-fs: Compilation failure: Compilation failure:
[ERROR] /home/hadoop/opensource/flink/flink-filesystems/flink-mapr-fs/src/main/java/org/apache/flink/runtime/fs/maprfs/MapRFileSystem.java:[70,44] package org.apache.hadoop.fs does not exist
[ERROR] /home/hadoop/opensource/flink/flink-filesystems/flink-mapr-fs/src/main/java/org/apache/flink/runtime/fs/maprfs/MapRFileSystem.java:[73,45] cannot find symbol
[ERROR] symbol: class Configuration
[ERROR] location: package org.apache.hadoop.conf
[ERROR] /home/hadoop/opensource/flink/flink-filesystems/flink-mapr-fs/src/main/java/org/apache/flink/runtime/fs/maprfs/MapRFileSystem.java:[73,93] cannot find symbol
[ERROR] symbol: class Configuration
缺失org.apache.hadoop.fs包,报错找不到。
解决:
flink-mapr-fs模块的pom文件中添加如下依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
继续往后编译:
mvn clean install -Dmaven.test.skip=true -Dhadoop.version=2.7.3 -rf :flink-mapr-fs
又报错:
[ERROR] Failed to execute goal on project flink-avro-confluent-registry: Could not resolve dependencies for project org.apache.flink:flink-avro-confluent-registry:jar:1.6.2: Could not find artifact io.confluent:kafka-schema-registry-client:jar:3.3.1 in nexus-osc (http://maven.aliyun.com/nexus/content/repositories/central) -> [Help 1]
[ERROR]
报错缺少kafka-schema-registry-client-3.3.1.jar 包
解决:
手动下载kafka-schema-registry-client-3.3.1.jar包,下载地址如下:
将下载的kafka-schema-registry-client-3.3.1.jar上传至主节点的目录下/home/hadoop/downloads
手动安装缺少的kafka-schema-registry-client-3.3.1.jar包
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=3.3.1 -Dpackaging=jar -Dfile=/home/hadoop/downloads/kafka-schema-registry-client-3.3.1.jar
继续往后编译
mvn clean install -Dmaven.test.skip=true -Dhadoop.version=2.7.3 -rf :flink-mapr-fs


Flink学习笔记:Flink开发环境搭建的更多相关文章
- Cocos2dx 学习笔记整理----开发环境搭建
最近在学习cocos2dx,预备将学习过程整理成笔记. 需要的工具和环境整理一下: 使用的版本 cocos2dx目前已经出到了v3.1.1,学习和项目的话还是用2.2.3为宜,毕竟不大想做小白鼠,并且 ...
- PHP学习笔记(1) - 开发环境搭建
运行环境:phpstudy 它基本包括运行php应用需要的一切,php. apache.mysql,一键傻瓜安装 装好之后只需要配置虚拟主机和修改host文件就可以支持多站点 下载: http://w ...
- angular2.0学习笔记1.开发环境搭建 (node.js和npm的安装)
开发环境, 1.安装Node.js®和npm, node 6.9.x 和 npm 3.x.x 以上的版本. 更老的版本可能会出现错误,更新的版本则没问题. 控制台窗口中运行命令 node -v 和 n ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Nutch1.7学习笔记:基本环境搭建及使用
Nutch1.7学习笔记:基本环境搭建及使用 作者:雨水,时间:2013-10-31博客地址:http://blog.csdn.net/gobitan 说明:Nutch有两个主版本1.x和2.x,它们 ...
- Django:学习笔记(1)——开发环境配置
Django:学习笔记(1)——开发环境配置 Django的安装与配置 安装Django 首先,我们可以执行python -m django --version命令,查看是否已安装django. 如果 ...
- python学习之python开发环境搭建
Python简介 Python是一种面向对象.解释型计算机程序设计语言.Python语法简洁而清晰,具有丰富和强大的类库等等众多的特性,这是来自百度百科的介绍,在百度百科还能看到它的更详细的介绍信息, ...
- Scala学习1————scala开发环境搭建(windows 10)
Scala开发环境搭建 先讲几点我学习scala的目的或者原因吧: JVM在企业中的霸主地位,Scala也是JVM上的语言,很有可能未来会从Java过度到Scala也不是不可能. 先进的函数式编程和面 ...
- php学习笔记1--开发环境搭建:apache+php+mysql
php开发环境搭建:apache + php + mysql1.下载apache,php及mysql安装包2.安装apache:下载的apache若是.msi可直接双击,按指示一步一步安装:(若操作系 ...
- Beaglebone Back学习三(开发环境搭建)
开发环境搭建 1 Ubuntu环境搭建 2 Window环境搭建 3 开发板环境搭建 1 Ubuntu环境搭建 (1)安装必要的网络工具 samba nfs tftp vmware-tools sam ...
随机推荐
- MySQL多表查询回顾
----------------------siwuxie095 MySQL 多表查询回顾 以客户和联系人为例(一对多) 1.内连接 /*内连接写法一*/ select * from t_custom ...
- sqlserver 文件与文件组的使用和优化
文件和文件组填充策略 文件组对组内的所有文件都使用按比例填充策略.当数据写入文件组时,SQL Server 数据库引擎按文件中的可用空间比例将数据写入文件组中的每个文件,而不是将所有数据都写入 ...
- Python代码规范利器Flake8
写代码其实是需要规范的,团队中更是如此:不然 Google 也不会发布各种编码规范,耳熟能详的有Google C++ 风格指南,Google Python 风格指南,等等. 这些规范有用吗?有用也没用 ...
- Windows环境下搭建MosQuitto服务器
Windows环境下搭建MosQuitto服务器 2018年04月16日 22:00:01 wistronpj 阅读数:1185 摘自:https://blog.csdn.net/pjlxm/art ...
- HDU 6097 Mindis (计算几何)
题意:给一个圆C和圆心O,P.Q是圆上或圆内到圆心距离相等的两个点,在圆上取一点D,求|PD| + |QD|的最小值 析:首先这个题是可以用三分过的,不过也太,.... 官方题解: 很不幸不总是中垂线 ...
- JAVA中简单的MD5加密类(MD5Utils)
MD5加密分析: JDK API: 获取对象的API: 加密的API: package cn.utils; import java.security.MessageDigest; im ...
- 通过面试题学习零散知识:Java面试题整理
一.如何看待面试题 对于喜欢学习的开发者来说,我们抛开工作和生活的时间,剩余的时间并不多,如果都用于学习的话,也不可能学的下所有感兴趣的技术点,精力也跟不上,我是深感如是.而面试题一般都是零碎的知识 ...
- 编写高质量代码改善C#程序的157个建议——建议113:声明变量前考虑最大值
建议113:声明变量前考虑最大值 假设正在开发一个工资系统,其中一个模块负责处理加薪.代码如下: static void Main(string[] args) { ; salary = (); Co ...
- numpy.convolve()
卷积函数: numpy.convolve(a, v, mode='full') Parameters: a : (N,) array_like First one-dimensional input ...
- iOS设计模式之单例
单例模式的意思就是这个类只有一个实例,这个类就是单例类.在iOS中有不少都是单例NSNull,NSFileManager ,UIApplication,NSUserDefaults ,UIDevice ...