Flink快速入门
安装:下载并启动
Flink可以在Linux、Mac OS X以及Windows上运行。为了能够运行Flink,唯一的要求是必须安装Java 7.x或者更高版本。对于Windows用户来说,请参考 Flink on Windows 文档,里面介绍了如何在Window本地运行Flink。
下载
从下载页面(http://flink.apache.org/downloads.html)下载所需的二进制包。你可以选择任何与 Hadoop/Scala 结合的版本。比如 Flink for Hadoop 2。
启动一个local模式的Flink集群
启动一个local模式的Flink集群非常地简单,我们可以按照以下的步骤来操作:
1、进入到下载的目录;
2、解压下载的文件;
3、启动Flink。
操作命令如下:
$ cd ~/Downloads # Go to download directory$ tar xzf flink-*.tgz # Unpack the downloaded archive$ cd flink-1.0.0$ bin/start-local.sh # Start Flink |
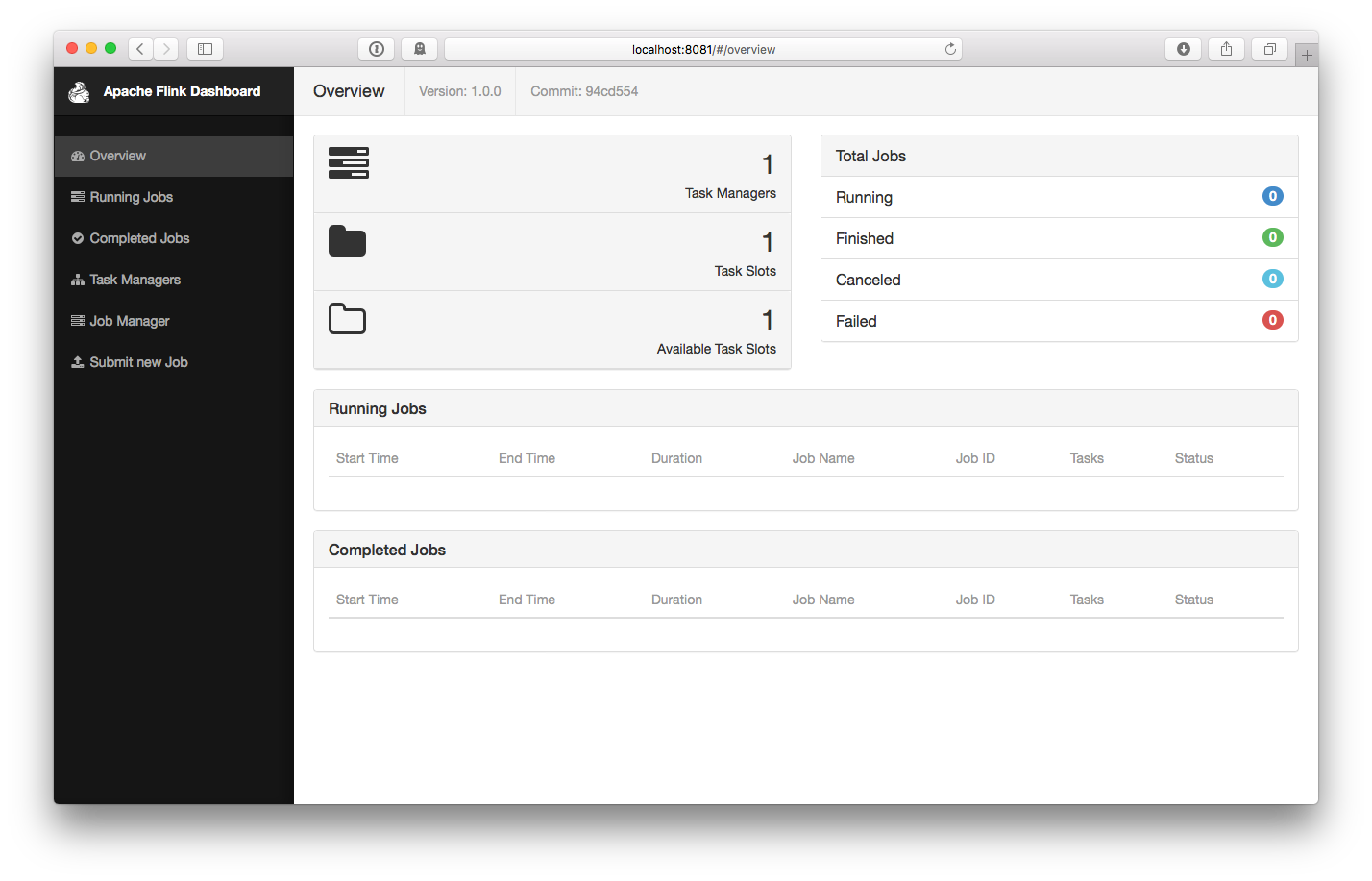
打开https://www.iteblog.com:8081检查Jobmanager和其他组件是否正常运行。Web前端应该显示了只有一个可用的 TaskManager。
运行例子
现在,我们来运行SocketTextStreamWordCount例子,它从socket中获取文本,然后计算每个单词出现的次数。操作步骤如下:
1、首先,我们使用netcat来启动本地服务器:
$ nc -l -p 9000 |
2、然后我们就可以提交Flink程序了:
$ bin/flink run examples/streaming/SocketTextStreamWordCount.jar \ --hostname localhost \ --port 9000Printing result to stdout. Use --output to specify output path.04/05/2016 16:03:36 Job execution switched to status RUNNING.04/05/2016 16:03:36 Source: Socket Stream -> Flat Map(1/1) switched to SCHEDULED 04/05/2016 16:03:36 Source: Socket Stream -> Flat Map(1/1) switched to DEPLOYING 04/05/2016 16:03:36 Keyed Aggregation -> Sink: Unnamed(1/1) switched to SCHEDULED 04/05/2016 16:03:36 Keyed Aggregation -> Sink: Unnamed(1/1) switched to DEPLOYING 04/05/2016 16:03:36 Keyed Aggregation -> Sink: Unnamed(1/1) switched to RUNNING 04/05/2016 16:03:36 Source: Socket Stream -> Flat Map(1/1) switched to RUNNING 04/05/2016 17:00:43 Source: Socket Stream -> Flat Map(1/1) switched to FINISHED 04/05/2016 17:00:43 Keyed Aggregation -> Sink: Unnamed(1/1) switched to FINISHED 04/05/2016 17:00:43 Job execution switched to status FINISHED. |
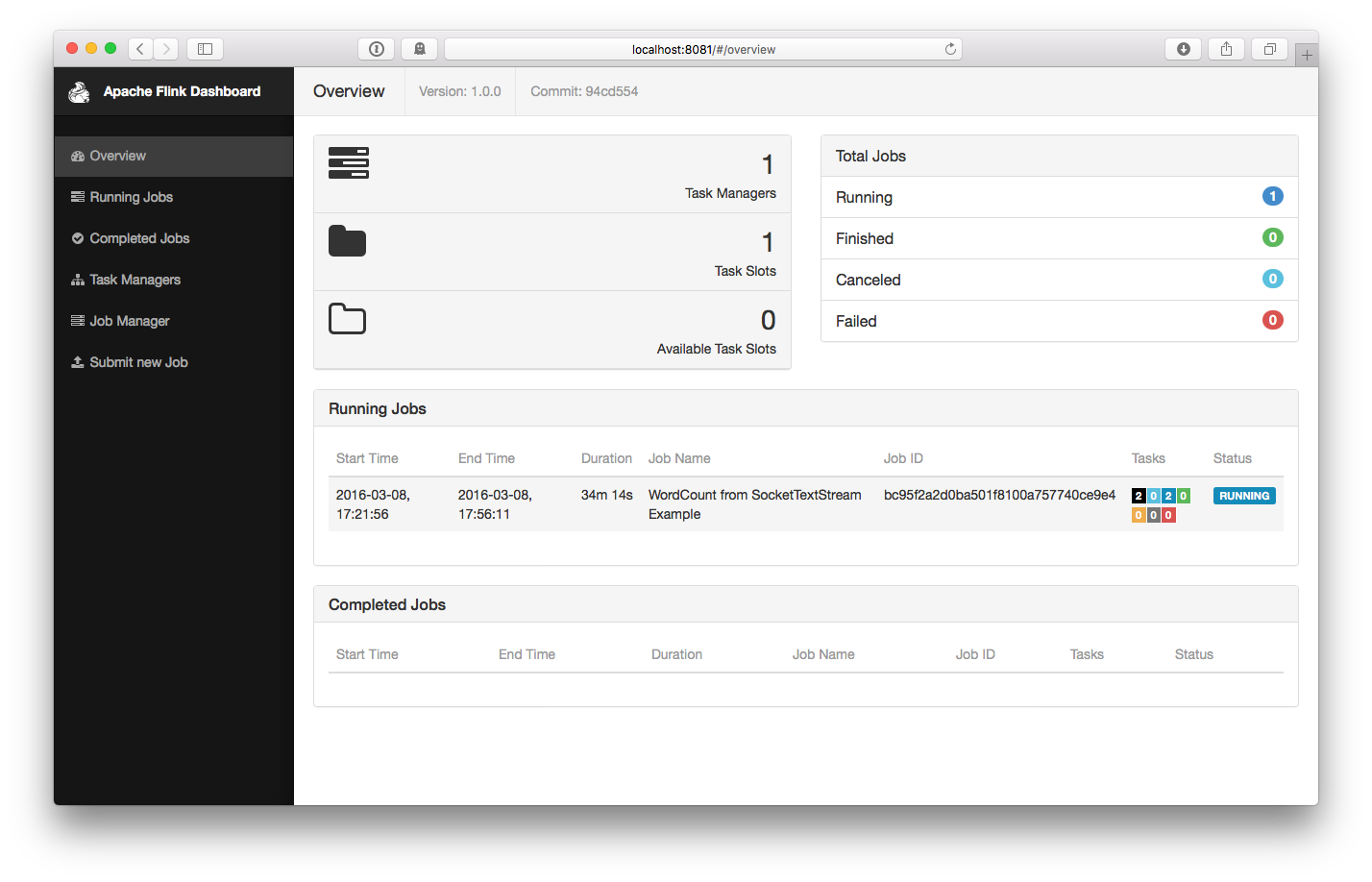
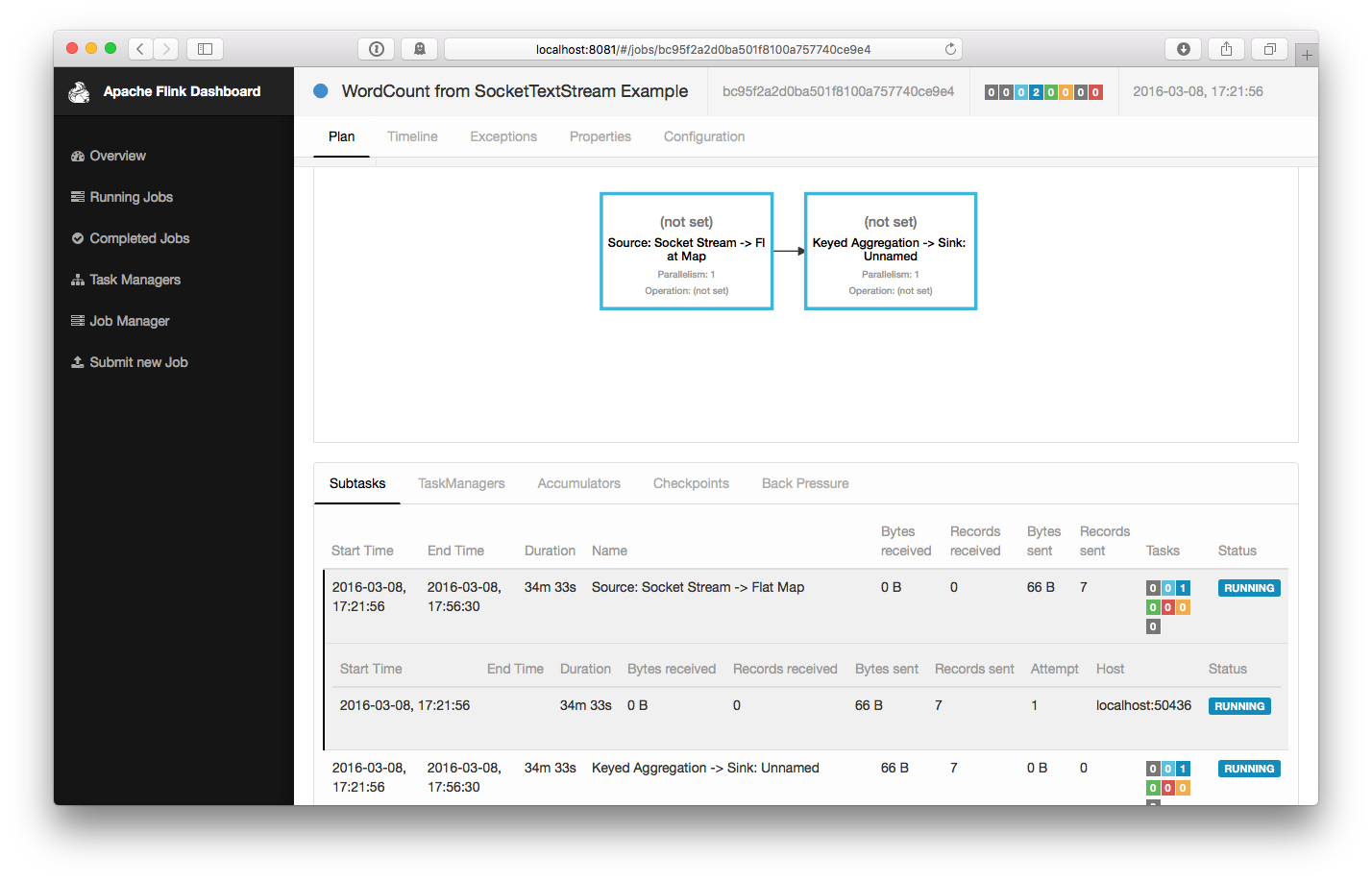
这个程序和socket进行了连接,并等待输入。我们可以在WEB UI中检查Job是否正常运行:
3、计数会打印到标准输出stdout。监控JobManager的输出文件(.out文件),并在nc中敲入一些单词:
$ nc -l -p 9000lorem ipsumipsum ipsum ipsumbye |
.out 文件会立即打印出单词的计数:
$ tail -f log/flink-*-jobmanager-*.out(lorem,1)(ipsum,1)(ipsum,2)(ipsum,3)(ipsum,4)(bye,1) |
要停止 Flink,只需要运行:
$ bin/stop-local.sh |

集群模式安装
在集群上运行 Flink 是和在本地运行一样简单的。需要先配置好 SSH 免密码登录 和保证所有节点的目录结构是一致的,这是保证我们的脚本能正确控制任务启停的关键。然后我们就可以按照下面步骤来操作:
1、在每台节点上,复制解压出来的 flink 目录到同样的路径下。
2、选择一个 master 节点 (JobManager) 然后在 conf/flink-conf.yaml 中设置 jobmanager.rpc.address 配置项为该节点的 IP 或者主机名。确保所有节点有有一样的 jobmanager.rpc.address 配置。
3、将所有的 worker 节点 (TaskManager)的 IP 或者主机名(一行一个)填入 conf/slaves 文件中。
现在,你可以在 master 节点上启动集群:bin/start-cluster.sh。
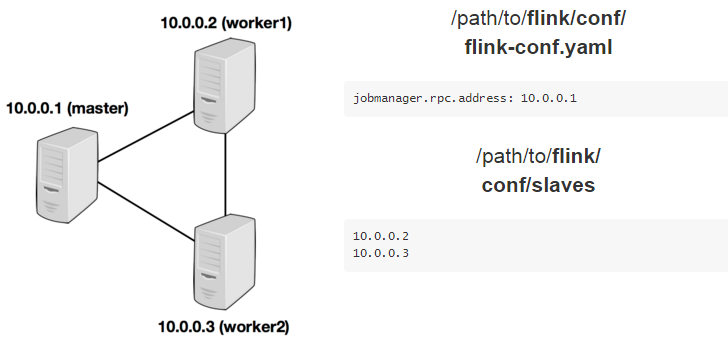
下面的例子阐述了三个节点的集群部署(IP地址从 10.0.0.1 到 10.0.0.3,主机名分别为 master, worker1, worker2)。并且展示了配置文件,以及所有机器上一致的可访问的安装路径。
访问https://ci.apache.org/projects/flink/flink-docs-release-1.0/setup/config.html查看更多可用的配置项。为了使 Flink 更高效的运行,还需要设置一些配置项。
以下都是非常重要的配置项:
1、TaskManager 总共能使用的内存大小(taskmanager.heap.mb)
2、每一台机器上能使用的 CPU 个数(taskmanager.numberOfTaskSlots)
3、集群中的总 CPU 个数(parallelism.default)
4、临时目录(taskmanager.tmp.dirs)
Flink on YARN
你可以很方便地将 Flink 部署在现有的YARN集群上,操作如下:
1、下载 Flink Hadoop2 包: Flink with Hadoop 2
2、确保你的 HADOOP_HOME (或 YARN_CONF_DIR 或 HADOOP_CONF_DIR) __环境变量__设置成你的 YARN 和 HDFS 配置。
3、运行 YARN 客户端:./bin/yarn-session.sh 。你可以带参数运行客户端 -n 10 -tm 8192 表示分配 10 个 TaskManager,每个拥有 8 GB 的内存。
Flink快速入门的更多相关文章
- Flink快速入门--安装与示例运行
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行. 首先要想运行Flin ...
- flink01--------1.flink简介 2.flink安装 3. flink提交任务的2种方式 4. 4flink的快速入门 5.source 6 常用算子(keyBy,max/min,maxBy/minBy,connect,union,split+select)
1. flink简介 1.1 什么是flink Apache Flink是一个分布式大数据处理引擎,可以对有限数据流(如离线数据)和无限流数据及逆行有状态计算(不太懂).可以部署在各种集群环境,对各种 ...
- [转帖]Flink(一)Flink的入门简介
Flink(一)Flink的入门简介 https://www.cnblogs.com/frankdeng/p/9400622.html 一. Flink的引入 这几年大数据的飞速发展,出现了很多热门的 ...
- Scala快速入门 - 基础语法篇
本篇文章首发于头条号Scala快速入门 - 基础语法篇,欢迎关注我的头条号和微信公众号"大数据技术和人工智能"(微信搜索bigdata_ai_tech)获取更多干货,也欢迎关注我的 ...
- Web Api 入门实战 (快速入门+工具使用+不依赖IIS)
平台之大势何人能挡? 带着你的Net飞奔吧!:http://www.cnblogs.com/dunitian/p/4822808.html 屁话我也就不多说了,什么简介的也省了,直接简单概括+demo ...
- SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=》提升)
SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=>提升,5个Demo贯彻全篇,感兴趣的玩才是真的学) 官方demo:http://www.asp.net/si ...
- 前端开发小白必学技能—非关系数据库又像关系数据库的MongoDB快速入门命令(2)
今天给大家道个歉,没有及时更新MongoDB快速入门的下篇,最近有点小忙,在此向博友们致歉.下面我将简单地说一下mongdb的一些基本命令以及我们日常开发过程中的一些问题.mongodb可以为我们提供 ...
- 【第三篇】ASP.NET MVC快速入门之安全策略(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
- 【番外篇】ASP.NET MVC快速入门之免费jQuery控件库(MVC5+EF6)
目录 [第一篇]ASP.NET MVC快速入门之数据库操作(MVC5+EF6) [第二篇]ASP.NET MVC快速入门之数据注解(MVC5+EF6) [第三篇]ASP.NET MVC快速入门之安全策 ...
随机推荐
- linux 将同后缀名的文件统一移至另一个文件夹
w
- 关于VFS文件系统中的superblock、inode、d_entry和file数据结构
- 解决64位debian下无法安装ia32库的问题
原文地址:http://crunchbang.org/forums/viewtopic.php?pid=277918 因为64位debian源中并没有包括32位的软件包,所提安装ia32会提示依赖无法 ...
- 剑指Offer——合并两个排序的链表
题目描述: 输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则. 分析: 苦力活,使用两个指针分别指向未被合并的两个链表的首部,比较两个首部数值的大小,合并数值 ...
- 【opencv】imread 赋值 深拷贝浅拷贝
import cv2 import copy import os def filter_srcimg(dstimg): ss=3 srcimg=copy.deepcopy(dstimg) #aa=5 ...
- Android在使用WebView时,通过Javascript调用JAVA函数
webView = (WebView) findViewById(R.id.article_webview); //WebView启用Javascript脚本运行 webView.getSetting ...
- Mysql数据库常用操作语句大全
零.用户管理: 1.新建用户: >CREATE USER name IDENTIFIED BY 'ssapdrow'; 2.更改密码: >SET PASSWORD FOR name=PAS ...
- bat命令运行java程序
注意空格 本文主要介绍在window下bat批处理文件调用java的方法. @echo off echo 正在加密,请稍后....echo path:%~dp0 set base=%~dp0 set ...
- jQuery对象和DOM对象之间的转换
jQuery对象不能使用DOM对象的任何方法,DOM对象也不能使用jQuery对象的任何方法.在需要使用时需要对其进行转换. jQuery对象前使用"$",这不是必须的,不这么使用 ...
- 算法总结之动态规划(DP)
适用动态规划的特点 所解决的问题是最优化问题. 所解决的问题具有"最优子结构".可以建立一个递推关系,使得n阶段的问题,可以通过几个k<n阶段的低阶子问题的最优解来求解. 具 ...