Hadoop 部署之 HBase (四)
一、HBase是什么
- HBase是建立在Hadoop文件系统之上的分布式面向列的数据库。它是一个开源项目,是横向扩展的。
- HBase是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据。它利用了Hadoop的文件系统(HDFS)提供的容错能力。
- 它是Hadoop的生态系统,提供对数据的随机实时读/写访问,是Hadoop文件系统的一部分。
- 人们可以直接或通过HBase的存储HDFS数据。使用HBase在HDFS读取消费/随机访问数据。 HBase在Hadoop的文件系统之上,并提供了读写访问。
HBase 和 HDFS
| HDFS | HBase |
|---|---|
| HDFS是适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找。 | HBase提供在较大的表快速查找 |
| 它提供了高延迟批量处理;没有批处理概念。 | 它提供了数十亿条记录低延迟访问单个行记录(随机存取)。 |
| 它提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。 |
HBase的存储机制
HBase是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。总之,在一个HBase:
- 表是行的集合。
- 行是列族的集合。
- 列族是列的集合。
- 列是键值对的集合。

二、HBase 集群部署
1、下载安装
# 下载安装包
wget http://archive.apache.org/dist/hbase/1.2.6/hbase-1.2.6-bin.tar.gz
# 解压安装包
tar xf hbase-1.2.6-bin.tar.gz
mv hbase-1.2.6 /usr/local/hbase
# 创建目录
mkdir -p /home/hbase/{log,pid,tmp}
2、配置 HBase 环境变量
编辑文件/etc/profile.d/hbase.sh。
# HBASE ENV
export HBASE_HOME=/usr/local/hbase
export PATH=$PATH:$HBASE_HOME/bin
使HADOOP环境变量生效
source /etc/profile.d/hbase.sh
三、HBase 配置(namenode01)
1、配置 hbase-env.sh
编辑文件/usr/local/hbase/conf/hbase-env.sh,修改如下信息。
export JAVA_HOME=/usr/java/default
export HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop
export HBASE_LOG_DIR=/home/hbase/log
export HBASE_PID_DIR=/home/hbase/pid
export HBASE_MANAGES_ZK=false
2、配置region服务器 regionservers
编辑文件/usr/local/hbase/conf/regionservers,修改为如下。
datanode01
datanode02
datanode03
3、配置列式存储 hbase-site.xml
编辑文件/usr/local/hbase/conf/hbase-site.xml,修改为如下。
<configuration>
<!--region服务器的共享目录,用来持久存储HBase的数据 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://namenode01:9000/hbase</value>
</property>
<!--本地文件系统的临时文件夹,可以修改为一个更为持久的目录-->
<property>
<name>hbase.tmp.dir</name>
<value>/home/hbase/tmp</value>
</property>
<!--HBase集群的运行模式,false表示单机模式,true表示集群模式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--HBase Master应该绑定的端口-->
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<!--HBase Master的Web UI服务端口-->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<!--HBase RegionServer绑定的端口-->
<property>
<name>hbase.regionserver.port</name>
<value>60020</value>
</property>
<!--HBase RegionServer的Web UI服务端口-->
<property>
<name>hbase.regionserver.info.port</name>
<value>60030</value>
</property>
<!--ZooKeeper的zoo.cfg配置文件中的属性,ZooKeeper面向客户端服务的端口-->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<!--ZooKeeper会话超期时间-->
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<!--ZooKeeper Quorum中的服务器列表,使用逗号分隔-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk01:2181,zk02:2181,zk03:2181</value>
</property>
<!--ZooKeeper的zoo.cfg配置文件中的属性,ZooKeeper集群中单个节点接收的单个客户端请求的并发数-->
<property>
<name>hbase.zookeeper.property.maxClientCnxns</name>
<value>300</value>
</property>
</configuration>
4、将配置文件复制到其他节点
cd /usr/local/hbase/conf
scp * datanode01:/usr/local/hbase/conf
scp * datanode02:/usr/local/hbase/conf
scp * datanode03:/usr/local/hbase/conf
四、HBase 启动
1、在namenode01执行
start-hbase.sh
2、检查 HBase
[root@namenode01 conf]# jps
14512 NameNode
14786 ResourceManager
15204 HMaster
15405 Jps
[root@datanode01 ~]# jps
3509 DataNode
3621 NodeManager
3238 HRegionServer
1097 QuorumPeerMain
3839 Jps
[root@datanode02 ~]# jps
3668 Jps
3048 HRegionServer
3322 DataNode
3434 NodeManager
1101 QuorumPeerMain
[root@datanode03 ~]# jps
3922 DataNode
4034 NodeManager
4235 Jps
1102 QuorumPeerMain
3614 HRegionServer
3、HBase 的 WEB 界面
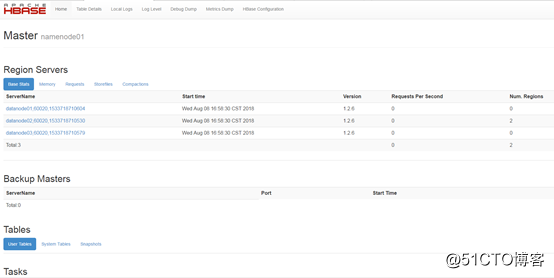
访问 http://192.168.1.200:60010/master-status
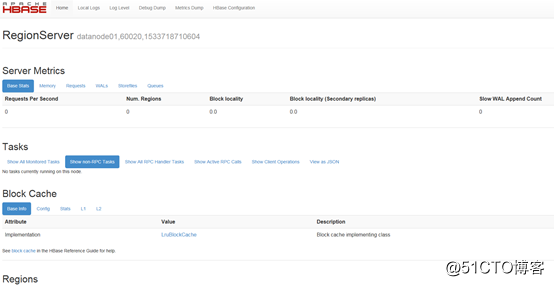
访问 http://192.168.1.201:60030/rs-status
4、进入 hbase shell 验证
[root@namenode01 ~]# hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017
hbase(main):001:0> list
TABLE
0 row(s) in 0.2210 seconds
=> []
hbase(main):002:0> status
1 active master, 0 backup masters, 3 servers, 0 dead, 0.6667 average load
Hadoop 部署之 HBase (四)的更多相关文章
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- hbase、zookeeper及hadoop部署
一 机器192.168.0.203 hd203: hadoop namenode & hbase HMaster192.168.0.204 hd204: hadoop datanode &am ...
- 从零自学Hadoop(22):HBase协处理器
阅读目录 序 介绍 Observer操作 示例下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,Sour ...
- Hadoop 综合揭秘——HBase的原理与应用
前言 现今互联网科技发展日新月异,大数据.云计算.人工智能等技术已经成为前瞻性产品,海量数据和超高并发让传统的 Web2.0 网站有点力不从心,暴露了很多难以克服的问题.为此,Google.Amazo ...
- Hadoop部署方式-完全分布式(Fully-Distributed Mode)
Hadoop部署方式-完全分布式(Fully-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本博客搭建的虚拟机是伪分布式环境(https://w ...
- Hadoop部署方式-伪分布式(Pseudo-Distributed Mode)
Hadoop部署方式-伪分布式(Pseudo-Distributed Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.下载相应的jdk和Hadoop安装包 JDK:h ...
- Hadoop上配置Hbase数据库
已有环境: 1. Ubuntu:14.04.2 2.jdk: 1.8.0_45 3.hadoop:2.6.0 4.hBase:1.0.0 详细过程: 1.下载最新的Hbase,这里我下载的是hbase ...
- Hadoop 框架基础(四)
** Hadoop 框架基础(四) 上一节虽然大概了解了一下 mapreduce,徒手抓了海胆,不对,徒手写了 mapreduce 代码,也运行了出来.但是没有做更深入的理解和探讨. 那么…… 本节目 ...
- hadoop备战:hbase的分布式安装经验
配置HBase时,首先考虑的肯定是Hbase版本号与你所装的hadoop版本号是否匹配.这一点我在之前 的博客中已经说明清楚,hadoop版本号与hbase版本号的匹配度,那是官方提供的.以下的实验就 ...
随机推荐
- js中in关键字的使用方法
1.for...in 对数组或对象的循环/迭代操作 对于数组循环出来的是数组元素:对于对象循环出来的是对象属性 2.判断对象是否是数组/对象的元素/属性 格式:(变量 in 对象) 当‘对象’是数组时 ...
- CF662C Binary Table (FWT板题)
复习了一发FWT,发现还挺简单的... 没时间写了,就放一个博客吧:Great_Influence 的博客 注意这一句ans[i]=∑j⊗k=if[j]∗dp[k]ans[i]= ∑_{j⊗k=i} ...
- scapy2 爬取全站,以及使用post请求
前情提要: 一:scrapy 爬取妹子网 全站 知识点: scrapy回调函数的使用 二: scrapy的各个组件之间的关系解析 Scrapy 框架 Scrapy是用纯Python实现一个为了爬取网 ...
- 016_编写脚本快速克隆 KVM 虚拟机
#!/bin/bash#本脚本针对 RHEL7.2 或 Centos7.2#本脚本需要提前准备一个 qcow2 格式的虚拟机模板,名称为/var/lib/libvirt/images/.rh7_tem ...
- LibreOJ #6000. 「网络流 24 题」搭配飞行员
二次联通门 : LibreOJ #6000. 「网络流 24 题」搭配飞行员 /* LibreOJ #6000. 「网络流 24 题」搭配飞行员 二分图最大匹配 Dinic最大流 + 当前弧优化 */ ...
- xpath简介备查
xpath简介 xpath 使用路径表达式在xml和html中进行导航 xpath包含标准函数库 xpath是一个w3c的标准 xpath节点关系 父节点 子节点 同袍节点 先辈节点 后代节点 xpa ...
- 检查Object是否存在某个属性
1. in 和 hasOwnProperty in会检查对象和它的整条原型链,hasOwnProperty只会检查对象本身,不会检查原型链 let a = {name: 'rick'} let b = ...
- Python3使用openpyxl读写Excel文件
Python中常用的操作Excel的三方包有xlrd,xlwt和openpyxl等,xlrd支持读取.xls和.xlsx格式的Excel文件,只支持读取,不支持写入.xlwt只支持写入.xls格式的文 ...
- docker安装Tomcat并部署war项目
转载:https://blog.csdn.net/javahighness/article/details/82859596 1进入容器 docker exec -it mytomcat bash 以 ...
- 第11组 Alpha事后诸葛亮
第11组 Alpha事后诸葛亮 组长博客链接 https://www.cnblogs.com/xxylac/p/11924846.html 设想和目标 我们的软件要解决什么问题?是否定义得很清楚? ...