python自动华 (四)
Python自动化 【第四篇】:Python基础-装饰器 生成器 迭代器 Json & pickle
目录:
- 装饰器
- 生成器
- 迭代器
- Json & pickle 数据序列化
- 软件目录结构规范
1. Python装饰器
装饰器:本质是函数,(功能是装饰其它函数)就是为其他函数添加附加功能
原则:
>不能修改被装饰的函数的源代码
>不能修改被装饰的函数的调用方式
实现装饰器知识储备:
>函数即“变量”
>高阶函数
a)把一个函数名当做实参传给另外一个函数(在不修改源代码的请情况下)
b)返回值中包含函数名(不修改函数的调用方式)
>嵌套函数
高阶函数+嵌套函数=》装饰器
1.1 函数的调用顺序:
Python不允许函数在未声明之前对其进行引用或者调用
错误案例一:
def foo():
print 'in the foo'
bar()
foo()
错误案例二:
def foo():
print 'foo'
bar()
foo()
def bar():
print 'bar'
以上两个案例都会报错:NameError: global name 'bar' is not defined
正确案例一:
def bar():
print 'in the bar'
def foo():
print 'in the foo'
bar()
foo()
正确案例二:
def foo():
print 'in the foo'
bar()
def bar():
print 'in the bar'
foo()
(python为解释执行,函数foo在调用前已经声明了bar和foo,所以bar和foo无顺序之分)
1.2 高阶函数
高阶函数需满足以下两个条件:
a)某一函数当做参数传入另一函数中(在不修改源代码的请情况下)
b)返回值中包含函数名(不修改函数的调用方式)
高阶函数示例:
def bar():
print("In the bar")
def foo(func):
res = func()
return res
foo(bar)
高阶函数进阶:
def foo(func):
return func
print 'Function body is %s' %(foo(bar))
print 'Function name is %s' %(foo(bar).func_name)
foo(bar)()
#foo(bar)() 等同于bar=foo(bar)然后bar()
bar=foo(bar)
bar()
1.3 内嵌函数和变量作用域
定义:在一个函数体内创建另外一个函数,这种函数就叫内嵌函数(基于python支持静态嵌套域)
函数嵌套示范:
def foo():
def bar():
'in the bar'
bar()
foo()
局部作用域和全局作用域的访问顺序
x=0
def grandpa():
# x=1
def dad():
x=2
def son():
x=3
print x
son()
dad()
grandpa()
范例一:函数参数固定
def decorartor(func):
def wrapper(n):
'starting'
func(n)
'stopping'
return wrapper
def test(n):
'in the test arg is %s' % n
decorartor(test)('Tom')
范例二:函数参数不固定
def decorartor(func):
def wrapper(*args, **kwargs):
'starting'
func(*args, **kwargs)
'stopping'
return wrapper
def test(n, x=1):
'in the test arg is %s' % n
decorartor(test)('alex', x=2)
无参装饰器
import time
def decorator(func):
def wrapper(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
stop = time.time()
'run time is %s ' % (stop - start)
timeout
return wrapper
@decorator
def test(list_test):
for i in list_test:
time.sleep(0.1)
'-' * 20, i
# decorator(test)(range(10))
test(range(10))
有参装饰器
import time
def timer(timeout=0):
def decorator(func):
def wrapper(*args, **kwargs):
start = time.time()
func(*args, **kwargs)
stop = time.time()
'run time is %s ' % (stop - start)
timeout
return wrapper
return decorator
@timer(2)
def test(list_test):
for i in list_test:
time.sleep(0.1)
'-' * 20, i
# timer(timeout=10)(test)(range(10))
test(range(10))
2. 生成器
a = [i*2 for I in range(10)] #列表生成式
一边循环一边计算的机制,称为生成器:generator
要创建一个generator,有很多种方法。
第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
>>> L = [x * x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range(10))
>>> g
<generator object <genexpr> at 0x1022ef630>
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
>>> next(g) 0 >>> next(g) 1 >>> next(g) 4 >>> next(g) 9 >>> next(g) 16 >>> next(g) 25 >>> next(g) 36 >>> next(g) 49 >>> next(g) 64 >>> next(g) 81 >>> next(g) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
当然,上面这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象
>>> g = (x * x for x in range(10))
>>> for n in g:
... print(n)
...
0
1
4
9
16
25
36
49
64
81
所以,我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
上面的函数可以输出斐波那契数列的前N个数:
>>> fib(10)
1
1
2
3
5
8
13
21
34
55
done
仔细观察,可以看出,fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
def fib(max):
n,a,b = 0,0,1
while n < max:
#print(b)
yield b
a,b = b,a+b
n += 1
return 'done'
这就是定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
>>> f = fib(6) >>> f <generator object fib at 0x104feaaa0>
这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
data = fib(10)
print(data)
print(data.__next__())
print(data.__next__())
print("干点别的事")
print(data.__next__())
print(data.__next__())
print(data.__next__())
print(data.__next__())
print(data.__next__())
#输出
<generator object fib at 0x101be02b0> 1 1 干点别的事 2 3 5 8 13
在上面fib的例子,我们在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。
同样的,把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
>>> for n in fib(6): ... print(n) ... 1 1 2 3 5 8
但用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
>>> g = fib(6)
>>> while True:
... try:
... x = next(g)
... print('g:', x)
... except StopIteration as e:
... print('Generator return value:', e.value)
... break
...
g: 1
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done
还可通过yield实现在单线程的情况下实现并发运算的效果
import time
def consumer(name):
print("%s 准备吃包子啦!" %name)
while True:
baozi = yield print("包子[%s]来了,被[%s]吃了!" %(baozi,name)) def producer(name):
c = consumer('A')
c2 = consumer('B')
c.__next__()
c2.__next__()
print("老子开始准备做包子啦!")
for i in range(10):
time.sleep(1)
print("做了2个包子!")
c.send(i)
c2.send(i) producer("Tom")
3. 迭代器
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
*可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator
可以使用isinstance()判断一个对象是否是Iterator对象:
1 >>> from collections import Iterator
2
3 >>> isinstance((x for x in range(10)), Iterator)
4
5 True
6
7 >>> isinstance([], Iterator)
8
9 False
10
11 >>> isinstance({}, Iterator)
12
13 False
14
15 >>> isinstance('abc', Iterator)
16
17 False
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True
Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
小结:
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的,例如
for x in [1, 2, 3, 4, 5]:
pass
实际上完全等价于:
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循环
break
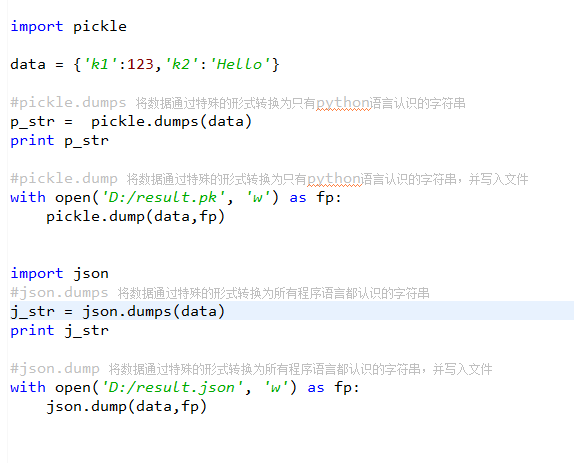
4. json和pickle
用于序列化的两个模块
json,用于字符串和python数据类型间进行转换
pickle,用于python特有的类型和python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
5. 软件目录结构规范
设计软件目录结构为了达到以下两点:
>可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
>可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
目录组织方式:
假设你的项目名为foo, 我比较建议的最方便快捷目录结构这样就足够了:
Foo/ |-- bin/ | |-- foo | |-- foo/ | |-- tests/ | | |-- __init__.py | | |-- test_main.py | | | |-- __init__.py | |-- main.py | |-- docs/ | |-- conf.py | |-- abc.rst | |-- setup.py |-- requirements.txt |-- README
简要解释一下:
>bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。
>foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。
>docs/: 存放一些文档。
>setup.py: 安装、部署、打包的脚本。
>requirements.txt: 存放软件依赖的外部Python包列表。
>README: 项目说明文件。
python自动华 (四)的更多相关文章
- python自动华 (十四)
Python自动化 [第十四篇]:HTML介绍 本节内容: Html 概述 HTML文档 常用标签 2. CSS 概述 CSS选择器 CSS常用属性 1.HTML 1.1概述 HTML是英文Hyper ...
- python自动华 (十七)
Python自动化 [第十七篇]:jQuery介绍 jQuery jQuery是一个兼容多浏览器的javascript库,核心理念是write less,do more(写得更少,做得更多),对jav ...
- python自动华 (十二)
Python自动化 [第十二篇]:Python进阶-MySQL和ORM 本节内容 数据库介绍 mysql 数据库安装使用 mysql管理 mysql 数据类型 常用mysql命令 创建数据库 外键 增 ...
- python自动华 (二)
Python自动化 [第二篇]:Python基础-列表.元组.字典 本节内容 模块初识 .pyc简介 数据类型初识 数据运算 列表.元组操作 字符串操作 字典操作 集合操作 字符编码与转码 一.模块初 ...
- python自动华 (十八)
Python自动化 [第十八篇]:JavaScript 正则表达式及Django初识 本节内容 JavaScript 正则表达式 Django初识 正则表达式 1.定义正则表达式 /.../ 用于定 ...
- python自动华 (十六)
Python自动化 [第十六篇]:JavaScript作用域和Dom收尾 本节内容: javascript作用域 DOM收尾 JavaScript作用域 JavaScript的作用域一直以来是前端开发 ...
- python自动华 (十五)
Python自动化 [第十五篇]:CSS.JavaScript 和 Dom介绍 本节内容 CSS javascript dom CSS position标签 fixed: 固定在页面的某个位置 rel ...
- python自动华 (十)
Python自动化 [第十篇]:Python进阶-多进程/协程/事件驱动与Select\Poll\Epoll异步IO 本节内容: 多进程 协程 事件驱动与Select\Poll\Epoll异步IO ...
- python自动华 (八)
Python自动化 [第八篇]:Python基础-Socket编程进阶 本节内容: Socket语法及相关 SocketServer实现多并发 1. Socket语法及相关 sk = socket.s ...
随机推荐
- java模拟from表单提交,上传图片
/** * java上传表单,有图片 * @param urlStr 上传地址 * @param textMap 表单参数 * @param fileMap 文件参数 key:文件名称 value:文 ...
- win10系统,jdk环境变量配置,编辑系统变量窗口显示旧版单行和新版列表问题
大家好,今天说一下我在配置jdk环境变量时遇到的编辑系统变量窗口显示问题. 首先我们说一下如何配置jdk环境变量. 右击此电脑,点击属性. 跳出如下窗口,点击高级系统设置. 跳出如下窗口,点击环境变量 ...
- js基础——数组的概念及其方法
数组: 概念:是一种特殊的对象. 与普通对象的区别:a.普通对象使用字符串作为属性名,而数组使用数字作为索引来操作元素: b.数组的存储性能比普通对象好 数组的标志:[ ] 数组的索引:是从0开始的整 ...
- VMware安装windows7系统
1.进入VMware系统,选择创建新的虚拟机 2.进入安装页面,选择自定义安装 3.选择虚拟机硬件兼容性,选择与自己软件相匹配的硬件兼容性 4.选择下一步后,选择稍后安装操作系统 5.选择客户机操作系 ...
- 利用Python进行数据分析_Pandas_数据加载、存储与文件格式
申明:本系列文章是自己在学习<利用Python进行数据分析>这本书的过程中,为了方便后期自己巩固知识而整理. 1 pandas读取文件的解析函数 read_csv 读取带分隔符的数据,默认 ...
- redis源码解读--内存分配zmalloc
目录 主要函数 void *zmalloc(size_t size) void *zcalloc(size_t size) void zrealloc(void ptr, size_t size) v ...
- Maven配置、使用
一:什么是Maven Maven项目对象模型(POM),可以通过一小段描述信息来管理项目的构建,报告和文档的项目管理工具软件. Maven提供了开发人员构建一个完整的生命周期框架,开发人员可以自动完成 ...
- ubuntu svn 安装
deepin@deepin:~$ sudo apt-get install rabbitvcs-rabbitvcs-cli rabbitvcs-core rabbitvcs-gedit rabbitv ...
- hdu 6197 array array array LIS
正反跑一次LIS,取最大的长度,如果长度大于n-k就满足条件. ac代码: #include <cstdio> #include <cstring> #include < ...
- 嗯 第二道线段树题目 对左右节点和下标有了更深的理解 hdu1556
Color the ball Time Limit: 9000/3000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...