Go项目实战:打造高并发日志采集系统(一)
项目结构
本系列文章意在记录如何搭建一个高可用的日志采集系统,实际项目中会有多个日志文件分布在服务器各个文件夹,这些日志记录了不同的功能。随着业务的增多,日志文件也再增多,企业中常常需要实现一个独立的日志采集系统,实时采集各个日志信息,并记录和输出到控制台或网页上,方便监控和查询。
本文日志采集系统架构如下
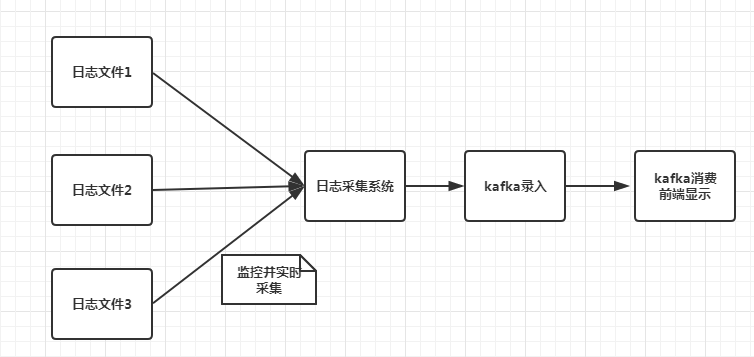
日志采集系统监控各个日志文件,当日志文件有日志录入时,日志采集系统实时获取日志内容并下入kafka队列中,之后可以实现Web端从kafaka取出信息,并前端显示。也可以将kafka的信息控制台输出,这个主要是看具体需求。本系列文章主要讲述如何搭建kafaka服务,编写高并发日志采集系统,稳定高效录入信息,以及从kafka中读取采集的日志。
本节目标
1 配置kafka,并启动消息队列。
2 编写代码向kafka录入消息,并且从kafka读取消息。
kafka简介和搭建
Kafka是一种高吞吐量的分布式发布订阅消息系统,由Java编写,内部使用了zookeeper(分布式应用程序协调服务),所以安装Kafka之前需要先安装jdk和zookeeper。
JDK安装
去官网https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html下载jdk,按步骤安装。之后配置环境变量即可。
Zookeeper安装
这里说下windows安装流程,linux类似。
从网址http://zookeeper.apache.org/releases.html下载zookeeper,之后解压即可使用。我在windows创建了一个文件夹D:\kafkazookeeper,将zookeeper解压到该文件夹。打开D:\kafkazookeeper\zookeeper-3.4.14\conf,把zoo_sample.cfg复制一份命名为zoo.cfg,从文本编辑器里打开zoo.cfg修改如下内容
dataDir=D:\\kafkazookeeper\\zookeeper-3.4.14\\data
dataLogDir=D:\\kafkazookeeper\\zookeeper-3.4.14\\log
目录根据你个人设置就行了。接下来添加如下环境变量
ZOOKEEPER_HOME: D:\kafkazookeeper\zookeeper-3.4.14
Path: 在现有的值后面添加 ";%ZOOKEEPER_HOME%\bin;
ZOOKEEPER_HOME值就是你的kafka安装目录。接下来进入D:\kafkazookeeper\zookeeper-3.4.14\bin启动zkServer.cmd
看到zookeeper服务跑起来了,默认端口为2181,不要关闭。
kafka安装
下载地址http://kafka.apache.org/downloads.html
将其解压到我自己的D:\kafkazookeeper目录下,打开D:\kafkazookeeper\kafka_2.12-2.2.0\config修改log.dirs,设置为
log.dirs=D:\\kafkazookeeper\\kafka_2.12-2.2.0\\logs
在kafka目录里执行如下命令,启动kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties
测试kafka
创建topics
在kafka目录里执行如下命令
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
这样我们创建了一个主题,这个主题相当于一个标签,用于消息读写。
打开一个Producer
同样在kafka目录下执行
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
这样我们基于test主题启动了一个生产者
打开一个Consumer
同样在kafka目录下执行
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
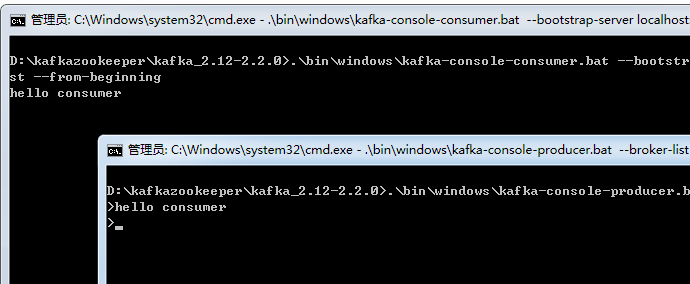
我们在生产者窗口写一些消息注入hello consumer,消费者窗口会取出消息并显示 hello consumer
实现代码向kafka写入消息
func main() {
config := sarama.NewConfig()
// 等待服务器所有副本都保存成功后的响应
config.Producer.RequiredAcks = sarama.WaitForAll
// 随机的分区类型:返回一个分区器,该分区器每次选择一个随机分区
config.Producer.Partitioner = sarama.NewRandomPartitioner
// 是否等待成功和失败后的响应
config.Producer.Return.Successes = true
// 使用给定代理地址和配置创建一个同步生产者
producer, err := sarama.NewSyncProducer([]string{"localhost:9092"}, config)
if err != nil {
panic(err)
}
defer producer.Close()
//构建发送的消息,
msg := &sarama.ProducerMessage{
//Topic: "test",//包含了消息的主题
Partition: int32(10), //
Key: sarama.StringEncoder("key"), //
}
inputReader := bufio.NewReader(os.Stdin)
for{
value, _ , err := inputReader.ReadLine()
if err != nil {
fmt.Printf("error:", err.Error())
return
}
msgType , _, err := inputReader.ReadLine()
msg.Topic = string(msgType)
fmt.Println("topic is : ",msg.Topic)
fmt.Println("value is : ",string(value))
msg.Value = sarama.ByteEncoder(value)
partition, offset, err := producer.SendMessage(msg)
if err != nil {
fmt.Println("Send message Fail")
fmt.Println(err.Error())
}
fmt.Printf("Partition = %d, offset=%d\n", partition, offset)
}
}
上述代码基于本地端口9092创建了生产者,然后构造了消息的分区大小以及Key值,接下来循环读取终端录入信息,第一行为value,第二行为topic,然后将消息发送到kafka,并且打印存储的分区和位移。
我们运行我们的程序,录入消息,可以看到消息发送到kafka后被消费者获取。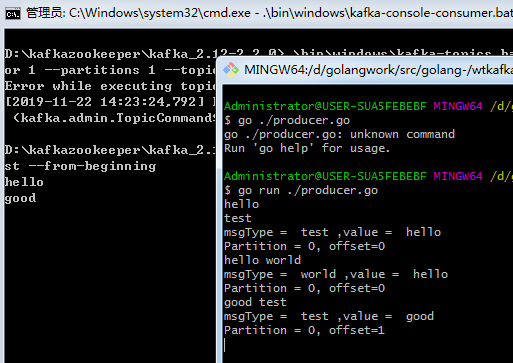
下一篇,我们完善消费者程序,并且实现文件监控和读取
。
谢谢关注我的公众号

Go项目实战:打造高并发日志采集系统(一)的更多相关文章
- Go项目实战:打造高并发日志采集系统(六)
前情回顾 前文我们完成了日志采集系统的日志文件监控,配置文件热更新,协程异常检测和保活机制. 本节目标 本节加入kafka消息队列,kafka前文也介绍过了,可以对消息进行排队,解耦合和流量控制的作用 ...
- Go项目实战:打造高并发日志采集系统(二)
日志统计系统的整体思路就是监控各个文件夹下的日志,实时获取日志写入内容并写入kafka队列,写入kafka队列可以在高并发时排队,而且达到了逻辑解耦合的目的.然后从kafka队列中读出数据,根据实际需 ...
- Go项目实战:打造高并发日志采集系统(三)
前文中已经完成了文件的监控,kafka信息读写,今天主要完成配置文件的读写以及热更新.并且规划一下系统的整体结构,然后将之前的功能串起来形成一套完整的日志采集系统. 前情提要 上一节我们完成了如下目标 ...
- Go项目实战:打造高并发日志采集系统(四)
前情回顾 前文我们完成了如下目标1 项目架构整体编写2 使框架支持热更新 本节目标 在前文的框架基础上,我们1 将之前实现的日志监控功能整合到框架中.2 一个日志对应一个监控协程,当配置热更新后根据新 ...
- Go项目实战:打造高并发日志采集系统(五)
前情回顾 前文我们完成了如下功能1 根据配置文件启动多个协程监控日志,并启动协程监听配置文件.2 根据配置文件热更新,动态协调日志监控.3 编写测试代码,向文件中不断写入日志并备份日志,验证系统健壮性 ...
- 《实战java高并发程序设计》源码整理及读书笔记
日常啰嗦 不要被标题吓到,虽然书籍是<实战java高并发程序设计>,但是这篇文章不会讲高并发.线程安全.锁啊这些比较恼人的知识点,甚至都不会谈相关的技术,只是写一写本人的一点读书感受,顺便 ...
- 《实战Java高并发程序设计》读书笔记
文章目录 第二章 Java并行程序基础 2.1 线程的基本操作 2.1.1 线程中断 2.1.2 等待(wait)和通知(notify) 2.1.3 等待线程结束(join)和谦让(yield) 2. ...
- 【实战Java高并发程序设计 7】让线程之间互相帮助--SynchronousQueue的实现
[实战Java高并发程序设计 1]Java中的指针:Unsafe类 [实战Java高并发程序设计 2]无锁的对象引用:AtomicReference [实战Java高并发程序设计 3]带有时间戳的对象 ...
- 【实战Java高并发程序设计6】挑战无锁算法:无锁的Vector实现
[实战Java高并发程序设计 1]Java中的指针:Unsafe类 [实战Java高并发程序设计 2]无锁的对象引用:AtomicReference [实战Java高并发程序设计 3]带有时间戳的对象 ...
随机推荐
- 洛谷P1462 通往奥格瑞玛的道路(SPFA+二分答案)
题目背景 在艾泽拉斯大陆上有一位名叫歪嘴哦的神奇术士,他是部落的中坚力量 有一天他醒来后发现自己居然到了联盟的主城暴风城 在被众多联盟的士兵攻击后,他决定逃回自己的家乡奥格瑞玛 题目描述 在艾泽拉斯, ...
- LoadRunner(8)
一.脚本关联技术 引入: 打开WebTours首页,点击administration连接: 具有大量管理项,LR为了模拟一些特效设置的选项,实际项目中不存在. -> 选择第三项: Set LO ...
- HAL UART DMA 数据收发
UART使用DMA进行数据收发,实现功能,串口2发送指令到上位机,上位机返回数据给串口2,串口2收到数据后由串口1进行转发,该功能为实验功能 1.UART与DMA通道进行绑定 void HAL_UAR ...
- 【pip】使用
错误及解决 install 1.pip install aip 报错[Windows,python3.6] ERROR: Could not find a version that satisfies ...
- jQuery.trim()方法
定义和用法 $.trim() 函数用于去除字符串两端的空白字符. 注意:$.trim()函数会移除字符串开始和末尾处的所有换行符,空格(包括连续的空格)和制表符.如果这些空白字符在字符串中间时,它们将 ...
- [转载]ac mysql 无法远程连接
Mac mysql 无法远程连接 2018年07月23日 10:56:02 feixiang2039 阅读数 2866 版权声明:本文为博主原创文章,遵循CC 4.0 by-sa版权协议,转载请附 ...
- prometheus部署
1.prometheus安装 软件下载: wget https://dl.grafana.com/oss/release/grafana-6.4.2-1.x86_64.rpm https://gith ...
- metal2 里 programmable blending 和image block的区别 语法以及persistent thread group的语法
programmable blending 刚接触这个概念的时候 挺激动的 因为能解决很多管线里面的问题 比如 切一次rt再切回来 为了做read write same rt 有了这个 就不用切啦 可 ...
- [Sping Boot] Build a REST CRUD API with Hibernate
pom.xml: <dependencies> <dependency> <groupId>org.springframework.boot</groupId ...
- HDU 6071 - Lazy Running | 2017 Multi-University Training Contest 4
/* HDU 6071 - Lazy Running [ 建模,最短路 ] | 2017 Multi-University Training Contest 4 题意: 四个点的环,给定相邻两点距离, ...