sppNet论文学习
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 深度神经网络中用于视觉识别的空间金字塔池化
1.INTRODUCTION
一般的深度神经网络都会设定一个固定的输入图片大小,比如 224*224,因此一般在数据处理时我们会将输入的数据进行裁剪或按比例缩放,在这种情况下就会导致输入的图片出现目标内容缺失或者是目标内容发生形变,即尺度误差或者形变误差,导致检测精确度的下降
所以提出了一种带着另一种池化策略——空间金字塔池化的网络,用来减少上面固定图片大小的需要。该新的网络结构叫做SPP-net,不管输入图片的大小/比例是什么,都能够生成固定长度的表征representation。金字塔池化对目标变形是鲁棒的。因为这些优点,SPP-net应该改善所有基于CNN的图像分类方法。在ImageNet 2012数据集中,我们证明了SPP-net能够增强各种各样的有着不同设计的CNN网络结构的精度,在PASCAL VOC 2007和Caltech101数据集中,SPP-net使用单一的完整图像表示并且不使用微调,得到了最优的分类结果
SPP-net对于目标检测也同样十分重要。使用SPP-net,我们仅从整个图像中计算一次feature maps,然后在随机区域(即子图片sub-images)上池化特征,用来为训练这个detectors生成固定长度的表征representation。该方法避免了重复计算卷积特征。在处理测试图像时,该方法比R-CNN快24-102倍,并且在PASCAL VOC 2007数据集中获得更好的效果
在ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014比赛中,一共有38个队伍,该方法在目标检测中排名第二,在图片分类中排名第三
该方法解决了一个CNNs在训练和测试时都会遇见的技术问题:就是需要输入一个固定的图片大小(如224*224),其限制了图片的宽高比(aspect ratio)和输入图片的大小。所以当提供的是任意大小的图片时,目前主要的方法就是将图片修改为固定大小,要么通过裁剪图片,要么通过变形图片来得到这个效果,如下图所示:

但是剪切的区域可能并不 完全包含整个目标,就像上面的车一样,只有一部分的车身;同时变形的内容可能会导致不想要的几何扭曲。因为内容的缺失和扭曲,识别精度也可能会损失。除此之外,一个预先定义好的大小在目标大小不同时就不适用了。因此固定的输入大小忽视了上面这些关于大小的问题
为什么CNN要固定输入大小呢?一个CNN主要包含两个部分:卷积层和接下来的全连接层。卷积层使用滑动窗口方法进行操作,输出的feature maps表示了activation的空间布置,如下图对feature maps的可视化:
实际上卷积层是不需要固定的输入图片大小的,并且能够生成任意大小的feature maps。
在另一方面,根据全连接层的定义,它们需要固定的大小/长度输入。因此固定大小的限制仅来自在网络更深阶段的全连接层。
所以我们将介绍SPP(spatial pyramid pooling)这个能够网络移除固定大小限制的方法。具体来说,我们将添加一个SPP层在最后一个卷积层的后面。该SPP层吃话卷积层的输出feature,并生成固定长度的输出,用该输出作为全连接层(或其他分类器)的输入。换句话说,我们在网络层次的较深阶段(即卷积层和全连接层之间)执行"聚合"来避免在一开始对输入图片的剪切和变形的需要。下图就展示了该网络结构添加SPP层后的变化,该网络结构叫做SPP-net:

spatial pyramid pooling(别名有spatial pyramid matching和SPM)作为在机器视觉领域最成功方法之一的Bag-of-Words(BoW)模型的一个扩展。它从精细到粗糙,将图片划分成一个个小部分,并将本地特征集合到上面。在目前的CNNs流行之前,SPP在一段时间内是用于分类和检测的,具有领先地位并在竞争中获胜的系统中重要的成分。然而SPP并没有被考虑作为CNNs的内容。可见SPP对于深度CNNs有着几个显著的特性:
- 不管输入大小是什么,SPP都能够生成固定长度的输出。然而之前深度网络的滑动窗口池化方法是做不到这点的
- SPP使用了多级空间箱(multi-level spatial bins),然后滑动窗口池化方法仅使用一个窗口大小。多级池化方法显示对目标变形有着较强的鲁棒性
- 多亏输入大小的灵活性,SPP能够池化从不同大小中抽取出来的特征
实验证明以上因素提高了深度网络的检测精度
SPP-net不仅让从随机大小图片/窗口生成用于测试的表征representation成为可能,还允许在训练时使用不同大小和比例的图像。使用不同大小图片训练能够增加scale-invariance和减少过拟合。
对于接受不同输入大小的一个单一网络,我们通过共享所有参数的多个网络来近似它,然而这些网络中的每一个都使用固定的输入。即虽然SPPnet能够接受任意尺度图片的输入,但是训练的难点在于现在所有的深度学习框架都需要固定的输入,所以这里提出了一个简单的多尺度训练方法。在每一个迭代中,使用给定的输入大小训练网络,并且在下一个迭代中转换成另一个输入大小。实验表明,该多尺度训练与传统的单尺度训练一样进行了收敛,且测试精度较高
SPP在优势在于对于具体的CNN设计是正交的。在ImageNet 2012数据集中,一系列使用没有SPP的对应项进行的的控制实验证明了SPP改进了目前发布的4个不同CNN结构。这些结构有不同的过滤器的数量/大小、strides、深度或其他设计。因此,我们有理由推测SPP应该能够改进更复杂(更深入和更大)的卷积架构。
SPP-net在目标检测中
在主要的目标检测方法R-CNN[7]中,通过深度卷积网络提取候选窗口的特征。该方法对VOC和ImageNet数据集均有较好的检测精度。但是R- CNN的特征计算是费时的,因为它反复地将深度卷积网络应用到每幅图像数千个扭曲区域的原始像素上。
在本文中,我们证明了我们只需要在整个图像上运行卷积层一次(无论窗口的数量),然后通过SPP-net在特征图feature maps上提取特征。这种方法的速度比R-CNN快100多倍。注意,在特征图feature maps(而不是图像区域)上训练/运行检测器detector实际上是一个更流行的想法。但是SPP-net继承了深度CNN特征图feature maps的强大功能,以及SPP对任意窗口大小的灵活性,使其具有出色的准确性和效率。在我们的实验中,基于spp-net的系统(建立在R-CNN管道上)的计算速度比R-CNN快24-102倍,但具有更好或相近的精度。采用最新的EdgeBoxes[25]快速提案方法,我们的系统处理一个图像需要0.5秒(包括所有步骤)。这使得我们的方法在实际应用中很实用。
2.DEEP NETWORKS WITH SPATIAL PYRA- MID POOLING
1)Convolutional Layers and Feature Maps
考虑使用最流行的7层结构,前五层为卷积层,并且每个卷积层后面都跟着池化层,后两层是全连接层,然后是N个输出的softmax,N为类别的数量。这种深度网络需要固定的输入大小,可是我们注意到需要固定的大小只是因为全连接层要求固定长度向量作为输入。在另一方面,卷积层接受任意大小的输入。卷积层使用滑动过滤器,而且他们的输出和输入有着完全相同的宽高比(aspect ratio),该输出被叫做feature maps,即特征图——它们不仅涉及回应的强度,而且还涉及它们的空间位置
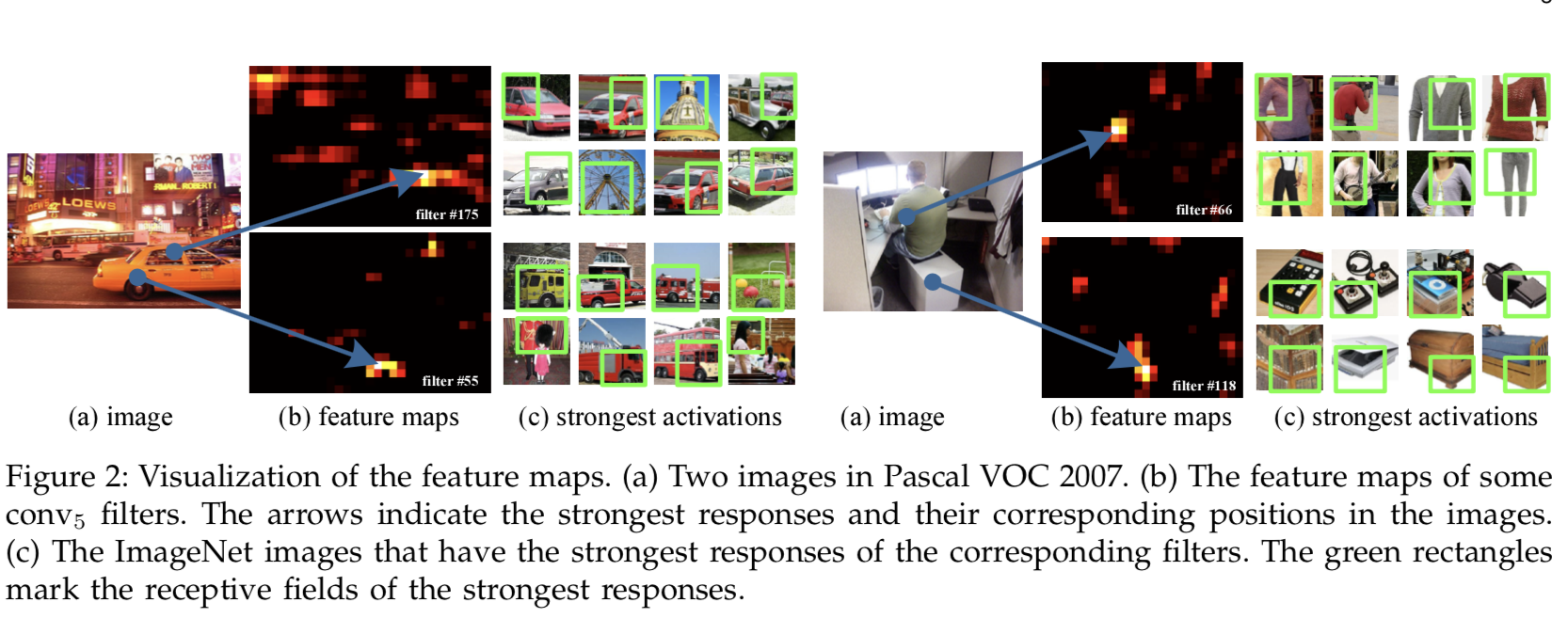
在figure 2中,我们可视化了一些特征图。他们被conv5层的一些过滤器生成。c图展示了在ImageNet数据集中这些过滤器中的最强的激活图片。我们可以看见一个过滤器能够被一些语义内容所激活。比如第55个过滤器(即左边b图下面的那张)更容易被一些圆形所激活;第66个过滤器(即右边b图上面的那张)更容易被∧这样的形状所激活;第118个过滤器(即右边b图下面的那张)更容易被∨这样的形状所激活。在输入图像(即a图中)中的这些形状将在相应的位置激活特征图(即剪头指向处)。其实就是第55个filter会激活图像中的圆形,第175个过滤器会激活类似车窗的部分,所以亮光表明处其实就是输入图像的车轮和车窗的位置
值得注意的是我们在Figure 2中生成的特征图是没有使用固定的输入大小的。这些通过深卷积层生成的特征图类似于在传统方法中的特征图。在那些方法中,SIFT向量或图像patches被稀疏抽取并编码,比如通过向量量化、稀疏编码或Fisher kernels。这些编码特征组成了特征图,然后被Bag-of-words(BoW)池化或空间金字塔。类似地,深层卷积特性也可以用类似的方式进行池化
2)The Spatial Pyramid Pooling Layer
卷积层接受任意输入大小,但是他们生成不同大小的输出。分类器(SVM/softmax)或全连接层需要固定长度的向量。这样的向量可以通过Bag-of-words(BoW)方法将这些特征池化在一起来生成。空间金字塔池化方法将BoW改进成能通过在本地空间bins中池化来保持空间信息。这些空间bins有着与图片大小成比例的大小,所以不管图片大小是多少,bins的数量是固定的。这与以前深度网络的滑动窗口池化方法是相反的,以前方法的滑动窗口数量是取决于输入大小的
为了对任意大小的图片采用深度网路,我们将替换最后一个池化层,即最后一个卷积层后面的pool5层为空间金字塔池化层。下图将阐述该方法:

注意:上面的三种不同刻度的划分,即4*4、2*2和1*1,每一种刻度我们称之为:金字塔的一层
在每一个空间bins中,我们将池化每个过滤器的回应(该论文中使用的是Max pooling)。该空间金字塔池化的输出是kM维的向量,M为bins的数量,k是上一层卷积层的过滤器数量,这里是256。该固定维度的向量是全连接层的输入。
从上图我们可以看见左边的bins有16个,中间的bins有4个,右边的bins有1个,所以计算得到最后的向量维度为 16*256 + 4*256 + 1*256 = 21*256维。这样无论conv5卷积层的输出是11*11或13*13或等等,都能够让其变为21*256这一个固定长度的向量,作为全连接层的输入
使用空间金字塔池化后,输入图像可以为任何大小。这不仅允许任意宽高比,而且允许任意大小的图像。我们可以调整输入图像为任意大小(比如min(w,h)=180,224,即宽高的最小值),并使用相同的深度网络。当输入图像是不同的大小时,网络(有着相同过滤器大小)将在不同的大小中抽取特征。大小在传统方法中起着重要作用,比如SIFT向量经常从多个大小(取决于patches的大小和高斯过滤器)中抽取出来。我们将展示大小scales对深度网络精度的重要性
有趣的是,最粗糙的金字塔级别仅有1个bins,能够包含整个图像。这实际上相当于一个‘global pooling’操作,该操作也在一些并行的工作中进行了研究。在[31]中,[32]采用全局平均池来减小模型大小,同时减小过拟合;在[33]中,在所有fc层之后的测试阶段使用全局平均池化,以提高准确性;在[34]中,全局最大池化用于弱监督对象识别。全局池化操作对应于传统的Bag-of-words方法。
3)Training the Network
理论上,上面的网络结构可以使用标准的后向传播来进行训练,不管输入图像的大小。但实际上,GPU实现(如cuda-convnet[3]和Caffe[35])最好在固定的输入图像上运行。接下来,我们描述了我们的训练解决方案,它利用了这些GPU实现,同时仍然保留了空间金字塔池化特性。
Single-size training
和之前的工作一样,我们首先考虑一个网络,它包含从图像中截取的固定大小的输入(224×224)。裁剪是为了增加数据。对于给定大小的图像,我们可以预先计算空间金字塔池所需的bins大小。考虑conv5之后的特征图,其大小为a×a(如13×13)。使用金字塔级别的n*n个bins来实现将该池化级别作为滑动窗口池化,窗口的大小为win=⌈a/n⌉,步长为str = ⌊a/n⌋ ,⌈·⌉ 和 ⌊·⌋ 表示向上和向下取整。l级别的金字塔代表实现l个这样的层。因此下一个全连接层fc6将串联l个输出。下面的图显示在cuda-convnet风格中配置为3级别的金字塔池化(3*3,2*2,1*1):

因为上一个卷积层conv5的输出为13*13,所以当pool为3*3时,窗口大小为5*5,步长为4,才能让输出为3*3的输出,以此类推。
我们单一大小single-size训练的主要目的是支持多级池化行为。实验表明,这是提高精度的原因之一。
Multi-size training
我们的网络与SPP预计将适用于任何大小的图像。为了解决训练中图像大小变化的问题,我们考虑了一组预定义的大小。我们考虑两种尺寸:180×180加到224×224。训练的时候224*224通过裁剪得到,我们没有选择从224*224裁剪一个更小的180×180区域,而是将上述224×224区域调整resize为180×180。因此,这两种尺度下的区域仅在分辨率上不同,而在内容/布局上是相同的。为了使网络能够接受180×180的输入,我们实现了另一个固定大小输入为180×180的网络。 在这个例子中,conv5卷积层的输出特征图大小为a*a=10*10。然后我们仍然使用公式win=⌈a/n⌉,步长为str = ⌊a/n⌋来实现每个金字塔池化级别。这个180*180输入网络的空间金字塔池化层的输出有着与224*224网络相同的固定长度。因此,这个180*180输入网络有着和224*224网络每一层完全相同的参数。从另一方面来说,在训练中我们通过两个共享参数的固定大小的网络实现了不同输入大小的SPP网络
为了减少从一个网络(例如,224)切换到另一个网络(例如,180)的开销,我们在一个网络上训练每个完整迭代epoch,然后切换到另一个网络(保留所有权重),以完成下一个完整迭代。在实验中,我们发现这种多尺度训练的收敛速度与上述单尺度训练相似。其实就是两种尺寸的网络是共享了所有的参数,即用两种尺寸的输入训练出一个网络,该两种尺寸图片轮流训练网络,更新参数,以得到该网络。即先用224*224的图像训练一个epoch,再用180*180的图像训练一个epoch
我们的多尺寸培训的主要目的是模拟不同的输入大小,同时仍然可以利用现有的优化过的固定尺寸的网络实现。除了上述两种尺度的实现外,我们还测试了一个变量,该变量使用s×s作为输入,s在每个epoch中随机且均匀地从[180,224]采样。我们在实验部分报告了这两种变量的结果。
注意上面单一/多种大小解决方案只用于训练。在测试阶段,就直接将任意大小的图像应用到SPP网络中
4.SPP-NET FOR OBJECT DETECTION
上面的部分主要讲的是SPP-net在图像分类中的应用,即在之前的分类网络中添加一层SPP层即可
下面讲的是讲其用在目标检测上,与R-CNN做对比:
参考https://blog.csdn.net/qq_35451572/article/details/80273222
一次特征提取
RCNN是多个regions+多次CNN+单个pooling,而SPP则是单个图像+单次CNN+多个region+多个pooling

算法流程:
- 首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
- 特征提取阶段。这一步就是和R-CNN最大的区别了,同样是用卷积神经网络进行特征提取,但是SPP-Net用的是金字塔池化。这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度是大大地快啊。江湖传说可一个提高100倍的速度,因为R-CNN就相当于遍历一个CNN两千次,而SPP-Net只需要遍历1次。
- 最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
在特征提取上,速度提升了好多,R-CNN是直接从原始图片中提取特征,它在每张原始图片上提取2000个Region Proposal,然后对每一个候选区域框进行一次卷积计算,差不多要重复2000次,而SPP-net则是在卷积原始图像之后的特征图上提取候选区域的特征。所有的卷积计算只进行了一次,效率大大提高。
缺点
SPP已有一定的速度提升,它在ConvNet的最后一个卷积层才提取proposal,但是依然有不足之处。和R-CNN一样,它的训练要经过多个阶段,特征也要存在磁盘中,另外,SPP中的微调只更新spp层后面的全连接层,对很深的网络这样肯定是不行的。
5.结论
SPP是一个灵活的解决方案,可以处理不同的规模、大小和宽高比。这些问题在视觉识别中很重要,但在深度网络环境中却很少被考虑。提出了一种利用空间金字塔池化层训练深度网络的方法。结果表明,该网络在分类/检测任务中具有较高的精度,大大加快了基于神经网络的检测速度。我们的研究还表明,在基于深度网络的识别中,许多经过时间检验的计算机视觉技术/见解仍然可以发挥重要作用。
sppNet论文学习的更多相关文章
- Faster RCNN论文学习
Faster R-CNN在Fast R-CNN的基础上的改进就是不再使用选择性搜索方法来提取框,效率慢,而是使用RPN网络来取代选择性搜索方法,不仅提高了速度,精确度也更高了 Faster R-CNN ...
- Fast RCNN论文学习
Fast RCNN建立在以前使用深度卷积网络有效分类目标proposals的工作的基础上.使用了几个创新点来改善训练和测试的速度,同时还能增加检测的精确度.Fast RCNN训练VGG16网络的速度是 ...
- 《Explaining and harnessing adversarial examples》 论文学习报告
<Explaining and harnessing adversarial examples> 论文学习报告 组员:裴建新 赖妍菱 周子玉 2020-03-27 1 背景 Sz ...
- 论文学习笔记 - 高光谱 和 LiDAR 融合分类合集
A³CLNN: Spatial, Spectral and Multiscale Attention ConvLSTM Neural Network for Multisource Remote Se ...
- Apache Calcite 论文学习笔记
特别声明:本文来源于掘金,"预留"发表的[Apache Calcite 论文学习笔记](https://juejin.im/post/5d2ed6a96fb9a07eea32a6f ...
- R-CNN论文学习
Rich feature hierarchies for accurate object detection and semantic segmentation Tech report (v5) pr ...
- GoogleNet:inceptionV3论文学习
Rethinking the Inception Architecture for Computer Vision 论文地址:https://arxiv.org/abs/1512.00567 Abst ...
- IEEE Trans 2008 Gradient Pursuits论文学习
之前所学习的论文中求解稀疏解的时候一般采用的都是最小二乘方法进行计算,为了降低计算复杂度和减少内存,这篇论文梯度追踪,属于贪婪算法中一种.主要为三种:梯度(gradient).共轭梯度(conjuga ...
- Raft论文学习笔记
先附上论文链接 https://pdos.csail.mit.edu/6.824/papers/raft-extended.pdf 最近在自学MIT的6.824分布式课程,找到两个比较好的githu ...
随机推荐
- 程序员修仙之路--优雅快速的统计千万级别uv
菜菜,咱们网站现在有多少PV和UV了? Y总,咱们没有统计pv和uv的系统,预估大约有一千万uv吧 写一个统计uv和pv的系统吧 网上有现成的,直接接入一个不行吗? 别人的不太放心,毕竟自己写的,自己 ...
- 关于Mock的一些网站
https://github.com/google/googletest/tree/master/googlemock https://blog.csdn.net/hhb200766/article/ ...
- JavaScript 中 var 和 let 和 const 关键字的区别
var与let.const的区别 在最新的 ES6 中,新添加了两个用于变量声明的关键字 let 和 const 一.var声明的变量会挂载在window上,而let和const声明的变量不会: va ...
- ubuntu安装anaconda3+tensorflow(cpu)+pycharm(windows几乎一样)
网上乱七八糟有的都是别人怎么写自己也怎么写,其实很简单. 首先是anaconda3的安装: 直接上官网:https://www.anaconda.com/download/ 下载下来之后进入文件所在目 ...
- Laravel 队列的简单使用例子
场景: 在一个a系统中注册一个用户时,发送请求到b系统中也注册一个相同信息的账号,考虑到网络有可能错误的原因,所以使用队列去处理 1.修改根目录 .env 文件的QUEUE_CONNECTION字段配 ...
- GO 文件读取常用的方法
方式1: 一行一行的方式读取 其中常用的方法就有:ReadString,ReadLine,ReadBytes ReadLine 返回单个行,不包括行尾字节,就是说,返回的内容不包括\n或者\r\n,返 ...
- AtCoder NIKKEI Programming Contest 2019 C. Different Strokes (贪心)
题目链接:https://nikkei2019-qual.contest.atcoder.jp/tasks/nikkei2019_qual_C 题意:给出 n 种食物,Takahashi 吃下获得 a ...
- hbase的region
一.Region 概念 Region是表获取和分布的基本元素,由每个列族的一个Store组成.对象层级图如下: Table (HBase table) Region (Regions for the ...
- sql server select 1 from 的作用
select 1 from table 语句中的1代表什么意思 在这里我主要讨论的有以下几个select 语句: doo_archive表是一个数据表,表的行数为4行,如下: 分别用三条selec ...
- spring boot, 容器启动后执行某操作
常有在spring容器启动后执行某些操作的需求,现做了一个demo的实现,做一下记录,也希望可以给需要的同学提供参考. 1.spring启动后,以新线程执行后续需要的操作,所以执行类实现Runnabl ...