Java同步数据结构之SynchronousQueue
前言
严格来说SynchronousQueue并不是像它的名字那样是一种Queue,它更像是一个数据接力的交汇点,还记得在介绍Exchanger的时候提到过Exchanger可以看作是SynchronousQueue的双向形式吗,Exchanger是一种可以同时容纳多对线程进行两两交换数据的场所,所以Exchanger的重点是交换(双向)数据,而SynchronousQueue只是一方将自己的数据交给另一方,并不会接收来自另一方的数据,即SynchronousQueue是对数据的一种单向传递,所以Exchanger可用看着是SynchronousQueue的双向形式。
虽然Exchanger与SynchronousQueue有这种相似性,但是它们两者的实现是完全不同的,只是最终达到的效果有这种类比性而已。Exchanger的实现是通过一个长度在约束的最大范围内不断伸缩的数组来存储一方的数据,当另一方到来时,通过将其映射到特定数组下标来实现数据交换或等待,当然这只是最简单的思想。SynchronousQueue的实现分别针对公平/非公平性的支持采用双队列/双堆栈来实现数据存储,虽然采用的数据结构不同,但是中心思想是一致的:当相同类型的线程(都是数据提供方或者数据接收者)到来时都将它们排队进入队列/堆栈,当与上一次入队的操作互补的线程(一方是数据提供者,另一方是数据接收者)到来时,就完成数据传递,然后它们双双出队返回。
SynchronousQueue的实现目标主要就是阻塞每一个操作,直到与其互补的操作出现,才完成数据传递交接返回。例如,当一个线程执行put(提供数据的生产者)操作,如果队列/堆栈中上一次入队的操作是take(请求数据的消费者),这时它们形成互补,那么它们进行数据交接,双双出队并返回;如果队列/堆栈为空或上一次入队的操作也是put操作,那么当前线程只能入队等待,反之亦然。当然SynchronousQueue同时也提供了相应的非阻塞以及指定超时时间的互补操作 offer/poll,它们在执行的时候或在指定的超时时间内,如果没有出现与其互补的操作则立即返回,例如,一个线程执行无超时时间的offer操作,这时候如果队列/堆栈中不存在与其互补的操作 poll或take,那么它将立即出队返回(offer提供的数据也不会保留在队列/堆栈中),而不是像put那样非要等到一个与其互补的操作出现拿走它的数据,反之亦然。
由此可见SynchronousQueue其实是一种阻塞队列,实际上SynchronousQueue虽然也是集合框架的实现类,但是它并没有容量,即size返回0,isEmpty返回true,所有Collection的相关方法(包括迭代器)都将把SynchronousQueue当成一个空队列处理,因为只有存在互补操作的瞬间,才会发生数据的交接,这时候才可以说存在数据,其它时候都是无意义的。在SynchronousQueue的实现中,将这种互补操作的数据交接称之为“fulfill”,正在交接称之为“fulfilling”,还没有开始交接为“unfulfilled”,交接完成为“fulfilled”,后到达的互补线程称之为“Fulfillers”,了解这些对源码的了解将容易的多。
使用实例
在阅读源码之前,先通过一个例子了解一下SynchronousQueue的特性:
static void test1() throws Exception{
SynchronousQueue sq = new SynchronousQueue();
CompletableFuture putFuture = CompletableFuture.runAsync(() -> {
try{
sq.put("AS");//can't be offer
}catch (Exception e){
e.printStackTrace();
}
});
TimeUnit.SECONDS.sleep(2); //等待2秒,才启动消费线程
CompletableFuture takeResultFuture = CompletableFuture.supplyAsync(() -> {
try{
return sq.take();
//or return sq.poll(5, TimeUnit.SECONDS);
}catch (Exception e){
e.printStackTrace();
}
return null;
});
CompletableFuture.allOf(putFuture, takeResultFuture);
System.out.println(takeResultFuture.get());
}
示例中, 一个线程先执行put(“AS”),另一个线程执行take,这样就可以完成数据的传递,最终takeResultFuture将得到“AS”,在上例中,put操作不能用offer替代,因为该线程先执行,offer在执行的时候另一个线程可能还没有执行,offer将立即返回,等到消费线程执行take时,已经没有与其互补的操作了,所以take将被阻塞,直到下一个与其互补的操作offer、put操作出现如果成功与其完成数据交接,才返回。另外,消费线程也可以使用 sq.poll(5, TimeUnit.SECONDS);替代,这时候poll会等待5秒,在这五秒之内,put线程肯定已经执行就绪,所以肯定可以与其发生数据交接。
源码解读
根据Java Doc, SynchronousQueue为了支持可选的公平策略,即为等待的生产者和消费者线程排序,分别扩展了W. N. Scherer III和M. L. Scott在2004年10月的第18届分布式计算年会上提出的“Nonblocking Concurrent Objects with Condition Synchronization”中描述的双堆栈和双队列算法。LIFO的堆栈用于非公平模式,FIFO的队列用于公平模式,两者的性能大体相似。FIFO通常在争用情况下支持更高的吞吐量,但LIFO在普通应用程序中维护更高的线程局部性。双队列/双堆栈的解释是指在任何给定时间要么持有数据(被put操作提供),要么请求数据(take操作),要么为空的队列。fulfill操作即是出队一个互补的节点,SynchronousQueue的内部是无锁的实现,都是基于CAS + Park 来实现线程的阻塞等待。
总之,SynchronousQueue内部有两种实现,堆栈用于非公平模式,队列用于公平模式,它们都扩展了内部抽象类Transferer,该抽象类只定义了一个抽象方法transfer,因为put和take操作是对称的,所以把它们的实现都统一到了这一个方法中,所以不论是put/offer还是take/poll都是调用的相应的transfer实现,该抽象类的定义如下:
/**
* Shared internal API for dual stacks and queues. 用于双堆栈和队列共享内部API。
*/
abstract static class Transferer<E> { /**
* Performs a put or take. 执行put或take操作。
*
* @param e if non-null, the item to be handed to a consumer;//如果非空,则是被传递给消费者的数据;
* if null, requests that transfer return an item offered by producer.
* // 如果为空,则请求该transfer返回生产者提供的数据。 * @param timed if this operation should timeout //如果该操作应该超时
* @param nanos the timeout, in nanoseconds
* @return if non-null, the item provided or received; if null,
* the operation failed due to timeout or interrupt --
* the caller can distinguish which of these occurred
* by checking Thread.interrupted.
返回值如果非空,就是被提供或者接受的数据;如果返回值为空,则操作因为超时或者线程中断而失败,
调用者可以通过Thread.interrupted查看中断标记来区分是中断还是超时。
*/
abstract E transfer(E e, boolean timed, long nanos);
}
从Transferer的定义可以看出,该方法就是被take/poll或put/offer调用,如果是put/offer操作,该方法的第一个参数e就是提供的数据,如果是take/poll操作,第一个参数e就是null;布尔值timed表示是否是定时等待。如果操作超时或者被中断,那么该方法返回null,否则返回put/offer提供的数据,下面就来分析下堆栈和队列的不同实现。
非公平堆栈实现
/** Dual stack */ 双堆栈
static final class TransferStack<E> extends Transferer<E> {
/*
* This extends Scherer-Scott dual stack algorithm, differing,
* among other ways, by using "covering" nodes rather than
* bit-marked pointers: Fulfilling operations push on marker
* nodes (with FULFILLING bit set in mode) to reserve a spot
* to match a waiting node. 这扩展了scher - scott双堆栈算法,不同的是,它使用“覆盖”节点而不是位标记指针:
在标记节点上执行push操作(在模式位上标记Fulfilling标志)来保留一个位置来匹配等待的节点。 Fulfilling操作将标记成Fulfilling的节点压入堆栈来匹配等待的节点。
*/ /* Modes for SNodes, ORed together in node fields */ snode的模式,在节点字段中组合在一起
/** Node represents an unfulfilled consumer */ 表示unfulfilled的消费者
static final int REQUEST = 0; /** Node represents an unfulfilled producer */ 表示unfulfilled的生产者
static final int DATA = 1; /** Node is fulfilling another unfulfilled DATA or REQUEST */ 节点正在fulfilling另一个unfulfilled的数据或请求
static final int FULFILLING = 2; /** Returns true if m has fulfilling bit set. */ 如果 m 有fulfilling标记位返回true,表示正在交接数据即fulfilling
static boolean isFulfilling(int m) { return (m & FULFILLING) != 0; } /** Node class for TransferStacks. */
static final class SNode {
volatile SNode next; // next node in stack 栈中的下一个节点
volatile SNode match; // the node matched to this 与此匹配的节点
volatile Thread waiter; // to control park/unpark 阻塞当前节点的线程
Object item; // data; or null for REQUESTs 节点数据;对于消费者来说为null
int mode; //节点的模式 //注意:item和mode字段不需要被volatile修饰,因为它们总是在其他volatile/原子操作之前写,之后读。
// Note: item and mode fields don't need to be volatile
// since they are always written before, and read after,
// other volatile/atomic operations. SNode(Object item) {
this.item = item;
} boolean casNext(SNode cmp, SNode val) {//将当前节点的下一个节点从cmp更新成val
return cmp == next &&
UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
} /**
* Tries to match node s to this node, if so, waking up thread. 尝试将s节点与当前节点匹配,如果匹配成功则唤醒线程。
* Fulfillers call tryMatch to identify their waiters. Fulfillers
* Waiters block until they have been matched.
Fulfillers 通过调用 tryMatch 确定它们的等待者。Fulfillers等待者被阻塞直到它们被匹配。
*
* @param s the node to match
* @return true if successfully matched to s
*/
boolean tryMatch(SNode s) { //如果match为nul,尝试将节点s设置成当前节点的match
if (match == null && //还没有被其它Fulfillers 匹配,那么尝试与它配对
UNSAFE.compareAndSwapObject(this, matchOffset, null, s)) {
Thread w = waiter;
if (w != null) { // waiters need at most one unpark
waiter = null;
LockSupport.unpark(w); //唤醒等待的线程Waiters。
}
return true; //返回true
}
/*
* 已经和s匹配过了也返回true、否则返回false。
* match == s这种情况就发生在transfer的情况3:即当前节点与s的匹配被其它线程抢先帮助完成了
* 所以当该方法再次调用的时候,match其实已经指向了s。
*/
return match == s;
} /**
* Tries to cancel a wait by matching node to itself. 尝试通过将节点与自身匹配来取消等待。
*/
void tryCancel() {
UNSAFE.compareAndSwapObject(this, matchOffset, null, this); //将match设置成自己,避免被其它线程匹配
} boolean isCancelled() {//如果节点match指向自己的话就是已经取消等待
return match == this;
} // Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long matchOffset;
private static final long nextOffset; static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = SNode.class;
matchOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("match"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
} /** The head (top) of the stack */ 栈顶节点head
volatile SNode head; boolean casHead(SNode h, SNode nh) { //更新栈顶节点,尝试将栈顶节点从h 更新成nh
return h == head &&
UNSAFE.compareAndSwapObject(this, headOffset, h, nh);
} /**
* Creates or resets fields of a node. Called only from transfer
* where the node to push on stack is lazily created and
* reused when possible to help reduce intervals between reads
* and CASes of head and to avoid surges of garbage when CASes
* to push nodes fail due to contention. 创建或重置节点的字段。只有在要推入堆栈的节点是延迟创建并且可重用的时候从transfer调用,
以帮助减少读操作和CAS置换head之间的间隔,并避免由于竞争而导致push节点的CAS操作失败时出现垃圾激增。 */
static SNode snode(SNode s, Object e, SNode next, int mode) {
if (s == null) s = new SNode(e);//s为空才创建新节点,否则更新原节点的字段。
s.mode = mode;
s.next = next;
return s;
}
以上代码是堆栈实现类TransferStack的一些基础定义,它确实扩展了抽象类Transferer,这里我们先不研究它的具体实现,先看看它的基础定义,TransferStack有个内部类SNode即是将入队操作入队时封装的节点类,采用了链表的方式进行节点维护,即包括下一个节点next,还有一个与其互补节点match(当互补节点达到时设置),以及节点数据项item(put/offer提供的),最重要的mode字段,表示当前节点的模式,即当前节点代表的操作是数据提供(put/offer)还是数据消费(take/poll)。
关于堆栈实现中的int型节点模式字段mode,其实它由两部分组成(两个二进制位),二进制位的最低位表示当前节点的操作类型(即是数据提供还是数据消费),第二位表示当前节点是否找到与其互补的节点,例如,当mode为0(REQUEST常量)表示当前节点是数据消费者(即take/poll操作),为1(DATA常量)表示数据提供者(put/offer操作),当与其互补节点到达时,mode的二进制将变成 1X:消费者的二进制即10,生产者的二进制即11,所以源码中的isFulfilling方法通过将mode与2(二进制10)按位与就可以得到二进制的高位指示的值,即是否找到互补节点,正在完成数据交接。
head变量指向堆栈的栈顶,即最近入栈的节点,因为堆栈是后进先出,所以总是后进入的节点(栈顶)首先被互补节点匹配出栈,即数据交接的匹配总是发生在栈顶head节点上。只有栈顶head出栈只后,那些之前入栈的节点才会依次往上移动一个位置。下面看看它的核心实现:
/**
* Puts or takes an item. 放置或者拿出一个item
*/
@SuppressWarnings("unchecked")
E transfer(E e, boolean timed, long nanos) {
/*
* Basic algorithm is to loop trying one of three actions:
* 基本算法是循环尝试下面三个动作之一:
*
* 1. If apparently empty or already containing nodes of same
* mode, try to push node on stack and wait for a match,
* returning it, or null if cancelled.
*
* 如果栈为空或者栈中已经存在了模式相同的节点(都是读或写),就尝试将当前节点压入栈顶等待被匹配,最后返回。
* 如果当前节点在等待过程中被取消,则返回null。
*
* 2. If apparently containing node of complementary mode,
* try to push a fulfilling node on to stack, match
* with corresponding waiting node, pop both from
* stack, and return matched item. The matching or
* unlinking might not actually be necessary because of
* other threads performing action 3:
*
* 如果栈包含一个与当前操作模式互补(即可以匹配)的节点,则尝试将当前线程作为作为满足匹配条件(模式打上fulfilling标记)的新节点入栈,
* 并和栈中相应的等待节点进行匹配,匹配完成之后将这一对相匹配的节点都从栈中弹出,返回匹配的数据。
* 实际上匹配和出栈这两个节点不是必须的,因为可能其它线程执行了行为3,即帮助它们完成了匹配和出栈。
*
* 3. If top of stack already holds another fulfilling node,
* help it out by doing its match and/or pop
* operations, and then continue. The code for helping
* is essentially the same as for fulfilling, except
* that it doesn't return the item.
*
* 如果当前栈顶元素找到了和它匹配的节点(即栈顶节点处于fulfilling模式),当前线程会尝试帮助它们完成匹配和弹出操作,
* 然后继续处理当前线程自己的操作。帮助的代码与情况2中匹配的代码本质上是相同的,只是它不返回匹配的对象。
*
*/ SNode s = null; // constructed/reused as needed
int mode = (e == null) ? REQUEST : DATA; //传入对象为空表示消费者(take),不为空表示生产者(put) for (;;) {
SNode h = head;
// 情况1:如果栈为空或与栈顶节点模式相同
if (h == null || h.mode == mode) {
//如果定时等待已经超时或者时间本身为0(offer)
if (timed && nanos <= 0) {
if (h != null && h.isCancelled()) //栈顶节点已经取消了,清除它,继续循环比较新的栈顶节点
casHead(h, h.next); // pop cancelled node
else
//这里直接返回null,针对已经超时或者等待时间为0(offer),栈为空或栈顶节点模式相同,返回null
return null;
}
//构造新节点,压入栈顶。这里延迟创建节点实例可以避免CAS失败导致垃圾快速增长
else if (casHead(h, s = snode(s, e, h, mode))) {
SNode m = awaitFulfill(s, timed, nanos); //等待被匹配或者取消(中断或超时)才返回
//在返回后,如果发现返回的结果等于自身,则说明在等待过程中已经取消了,则将节点从栈中清除
if (m == s) { // wait was cancelled
clean(s);
return null;
}
/*
* 阻塞醒来后,如果发现有新的节点插入到当前节点s的前面成为了新的栈顶节点
* 那么该新节点就是与当前节点s匹配的节点
/
if ((h = head) != null && h.next == s)
//同时将两个节点都出队,辅助s的匹配操作
casHead(h, s.next); // help s's fulfiller
//是消费者(读)就返回匹配到的对象,是生产者(写)就返回本身携带的对象
return (E) ((mode == REQUEST) ? m.item : s.item);
}
}
/*
* 情况2:栈不为空,并且与栈顶节点模式不同,并且栈顶节点还没有找到可以匹配节点(模式中没有Fulfilling标记)
* 说明当前操作与栈顶节点h是可以匹配的互补节点。
*/
else if (!isFulfilling(h.mode)) { // try to fulfill
//栈顶节点已经取消了,重置栈顶节点继续循环,会重新判断当前操作与新的Head是否可以匹配
if (h.isCancelled()) // already cancelled
casHead(h, h.next); // pop and retry
//构造新匹配节点(模式打上fulfilling标记),压入栈顶
else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) {
/*
* 循环,让s与原来的head(h)进行匹配,匹配成功则返回匹配的数据,
* 匹配失败(等待被匹配者取消了等待)则移除那个与s互补的节点,继续与它的下一个节点进行匹配,
* 直到成功或到达堆栈结尾。若最终都没成功则重新外层循环。
*/
for (;;) { // loop until matched or waiters disappear
//s.next 就是要与s匹配的模式不同的那个节点,也就是原来的栈顶节点
SNode m = s.next; // m is s's match
/*
* m == null,表示事先准备与s匹配的节点m取消了等待,并且后面已经没有节点了
* 因为如果m取消了,m.next不为空,那么此时m就将指向m.next,所以m == null,
* 其实也表示栈空(all waiters are gone)
*/
if (m == null) { // all waiters are gone
//把s节点从栈顶弹出,重新循环。
casHead(s, null); // pop fulfill node
//将s重置为空,下一次循环重新创建实例
s = null; // use new node next time
//退出内循环,继续外层主循环
break; // restart main loop
}
SNode mn = m.next;
//尝试匹配,匹配成功会唤醒m节点对应的线程
if (m.tryMatch(s)) {
//匹配成功,将s、m都出队,m.next成为新的栈顶
casHead(s, mn); // pop both s and m
//是消费者就返回匹配到的对象,是生产者就返回本身携带的对象
return (E) ((mode == REQUEST) ? m.item : s.item);
} else // lost match
/*
* 没有匹配成功,可能是s与m匹配的过程中,m节点取消了等待,将match指向了自己
* 将m节点移除,让s.next指向m.next即mn,继续循环让s与新的next进行匹配
*/
s.casNext(m, mn); // help unlink
}
}
}
//情况3:说明栈顶节点正在被匹配,mode变量的二进制位第2位为1,则辅助栈顶节点与其next节点完成匹配
else { // help a fulfiller
//m 和 h 就是理论上正在匹配的一对节点
SNode m = h.next; // m is h's match
//m == null,表示事先准备与h匹配的节点m取消了等待
if (m == null) // waiter is gone
//把栈顶节点弹出,重新循环
casHead(h, null); // pop fulfilling node
else {
//否则,帮助它们完成匹配
SNode mn = m.next;
//尝试匹配m 、 h
if (m.tryMatch(h)) // help match
//匹配成功,将h、m都出队,m.next成为新的栈顶
casHead(h, mn); // pop both h and m
else // lost match
//没有匹配成功,可能是h与m匹配的过程中,m节点取消了等待,将match指向了自己
h.casNext(m, mn); // help unlink
}
}
}
} /**
* Spins/blocks until node s is matched by a fulfill operation.
* 自旋/阻塞,直到节点s被fulfill操作匹配。 * @param s the waiting node
* @param timed true if timed wait true为定时等待
* @param nanos timeout value
* @return matched node, or s if cancelled 返回匹配的节点,或者如果取消返回s
*/
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
/*
* When a node/thread is about to block, it sets its waiter
* field and then rechecks state at least one more time
* before actually parking, thus covering race vs
* fulfiller noticing that waiter is non-null so should be
* woken.
当一个节点/线程将要阻塞时,它会设置它的waiter字段,然后在实际阻塞之前至少要重新检查一次状态,
fulfiller会注意到waiter是非空的,因此应该被唤醒。 *
* When invoked by nodes that appear at the point of call
* to be at the head of the stack, calls to park are
* preceded by spins to avoid blocking when producers and
* consumers are arriving very close in time. This can
* happen enough to bother only on multiprocessors.
当调用点上出现在堆栈顶部的节点调用park时,调用之前会有自旋,以避免在生产者和消费者到达非常接近时阻塞。
这种情况只会发生在多处理器上。
*
* The order of checks for returning out of main loop
* reflects fact that interrupts have precedence over
* normal returns, which have precedence over
* timeouts. (So, on timeout, one last check for match is
* done before giving up.) Except that calls from untimed
* SynchronousQueue.{poll/offer} don't check interrupts
* and don't wait at all, so are trapped in transfer
* method rather than calling awaitFulfill.
从主循环返回的检查顺序反映了这样一个事实:中断优先于正常返回,而正常返回优先于超时。
(因此,在超时时,要在放弃之前进行最后一次匹配检查。) 除了来自非定时同步队列的调用。
poll/offer的非定时调用不检查中断且根本不需要等待,因此只会在transfer方法中返回,而不会调用awaitFulfill。 */
final long deadline = timed ? System.nanoTime() + nanos : 0L;//如果有等待时间,计算超时截至时间
Thread w = Thread.currentThread();
int spins = (shouldSpin(s) ? //如果应该自旋,获取定时等待或非定时等待的自旋次数
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel(); //如果中断则尝试取消。尝试将match指向自己,避免再被其它线程匹配。
SNode m = s.match;
if (m != null)
return m; //取消了则返回自身s,否则返回匹配的节点。
if (timed) { //如果还没有被匹配或取消,是定时等待
nanos = deadline - System.nanoTime();
if (nanos <= 0L) { //等待时间已经超时,尝试取消。
s.tryCancel();
continue; //使用continue,在放弃之前会再循环一次,避免漏掉已经匹配的节点。
}
}
//没有中断,没有取消,或定时等待没有超时
if (spins > 0) //应该自旋,每次自旋都会判断下一次是否还需要自旋,以及自旋的次数。
spins = shouldSpin(s) ? (spins-1) : 0;
else if (s.waiter == null) //准备进入阻塞之前先设置waiter,下一次循环再次检测状态之后才阻塞
s.waiter = w; // establish waiter so can park next iter
else if (!timed)
LockSupport.park(this); //非定时阻塞
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos); //定时阻塞
}
} /**
判断节点s是否应该自旋。
* Returns true if node s is at head or there is an active fulfiller.
* 如果s是栈顶节点或者堆栈为空或者当前时刻正好存在一个活动的fulfiller,返回true。
*
* 堆栈为空或者s是栈顶节点应该自旋很好理解,因为s就是栈中当前时刻最优先出队/被匹配的节点。
* 因此在自旋的过程中,随时可能有新的线程进来就可以完成与当前线程的匹配,从而减少当前线程的一次挂起;
*
* 但是当前时刻存在一个活动的fulfiller为什么也应该自旋呢?存在的fulfiller当然是优先尝试与栈顶节点匹配,
* 如果节点s不是栈顶,那么理论上来说是不大可能被该fulfiller线程匹配的,
* 只有在该fulfiller匹配的过程中刚好位于该fulfiller与s节点之间的所有节点都取消了,自然而然就轮到s节点了。
*/
boolean shouldSpin(SNode s) {
SNode h = head;
return (h == s || h == null || isFulfilling(h.mode));
} /**
* Unlinks s from the stack. 从堆栈中分离s节点,
会清除栈顶至s.next(如果next已经取消,则至next.next)之间所有已经取消的节点。
*/
void clean(SNode s) {
// 将引用置null,方便垃圾回收。
s.item = null; // forget item
s.waiter = null; // forget thread /*
* At worst we may need to traverse entire stack to unlink
* s. If there are multiple concurrent calls to clean, we
* might not see s if another thread has already removed
* it. But we can stop when we see any node known to
* follow s. We use s.next unless it too is cancelled, in
* which case we try the node one past. We don't check any
* further because we don't want to doubly traverse just to
* find sentinel.
* 在最坏的情况下,我们可能需要遍历整个堆栈来分离s节点。
* 因为如果有多个线程并发调用clean方法,由于另一个线程可能已经移除了s节点,我们可能找不到s节点。
* 但是我们可以在遍历到s的下一个节点或者下下个节点(s.next已经取消)时停止。
* 我们使用s的下一个节点s.next,除非它也被取消了,在这种情况下,我们尝试下下个节点。
* 我们不再进一步检查该下下个节点是否取消,因为我们不想为了找到它而重复遍历。
*
* 如果它的下下个节点也取消了,那么就是最坏的情况,要遍历整个堆栈。
*/ SNode past = s.next;
if (past != null && past.isCancelled()) //s.next已经取消,取下下个节点,不论它是否也取消了
past = past.next; // Absorb cancelled nodes at head 移除堆栈头部已经取消的连续节点,重新确定栈顶节点
SNode p;
while ((p = head) != null && p != past && p.isCancelled())
casHead(p, p.next); // Unsplice embedded nodes
while (p != null && p != past) { //移除当前有效栈顶节点与past节点之间已经取消的节点
SNode n = p.next;
if (n != null && n.isCancelled())
p.casNext(n, n.next);
else
p = n;
}
}
关于堆栈实现的逻辑通过注释很容易理解, 简单来说,如果堆栈为空或当前操作与栈顶节点模式相同(都是生产者或都是消费者)那么构造成新的节点入栈成为新的栈顶以 自旋 + 阻塞的方式进行等待,如果发现当前操作与栈顶节点模式互补,那么将当前操作的模式打上fulfilling标记,然后入栈成为新的栈顶(入栈抢占栈顶的过程是可以被其它互补操作抢先的,但一旦入栈成功那么其它操作再也不能抢走与其匹配的next节点,除非它的next节点自己取消了等待),接着再完成该栈顶节点与其next节点的数据匹配交接,成功就唤醒等待节点将两个节点都出栈返回,失败(说明与其互补的节点中断或超时而取消了)则继续与栈中下下个节点(因为那些后续节点肯定都是与当前操作模式互补的)匹配交接数据,直到成功或者堆栈结尾,另外当标记为fulfilling的互补节点入栈之后,再还没完成匹配之前,后续到达的其它操作也会帮助它们完成数据交接匹配。
在节点取消之后会将match指向自身,这样不但可以用于检测取消的标志,还可以方便垃圾回收。在节点取消之后,需要执行clean清理方法对节点进行清除,清理的时候需要遍历堆栈直到被清理节点的下一个或下下个节点为止。

上图例展示了堆栈中原来是三个put操作,后来的互补操作take完成匹配的过程,最终堆栈中还剩下两个put操作等待互补的操作来匹配,如果匹配过程中put(C)由于中断或超时取消了,那么流程变成: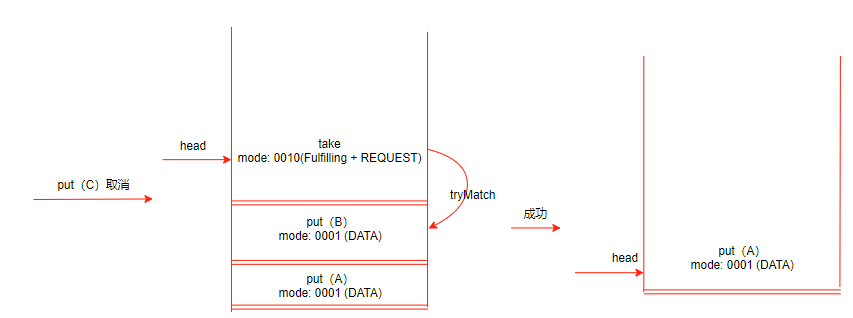
最终如果take与put(B)完成了匹配,那么堆栈中最后只剩下put (A)在等待被互补操作匹配交接数据。
以上对于后进先出LIFO堆栈的实现,通过将一个个操作根据是否提供了数据构造成不同模式的节点推入堆栈,如果新节点与入栈前的栈顶节点操作是互补的,即一个是数据提供方,一个是数据获取方,那么新入栈的节点将被标记成“Fulfilling”,表示它找到了与之操作的互补的节点,将要完成数据匹配,当它们完成匹配之后,唤醒与其互补的等待节点线程,让这对互补操作的节点都出栈,最后各自的线程返回。在新入栈节点被标记成“Fulfilling”之后,还没有完成匹配出栈之前,其它到达的操作都会帮助它们完成匹配过程,注意并不是抢占匹配的优先权,而是等(或帮助)它们完成匹配出栈之后,与栈中剩下的节点进行比较看是否是入栈等待还是匹配。在堆栈实现中,无论新达到的操作是否与栈顶节点互补都会被构造成节点入栈,然后再继续等待,或者匹配之后出栈。
堆栈实现中对由于超时或中断而取消的节点的清理,需要遍历堆栈直到被取消节点s的下一个s.next或下下目标节点s.next.next(当s.next也取消了),遍历的过程中就会移除所有那些从栈顶到目标节点之间已经取消的节点,由于多线程的并行性,很可能该目标节点在遍历过程中提前被其它调用清理方法的线程清理掉了,这种最坏的情况下就可能需要遍历完整个堆栈。
堆栈是后进先出的数据结构,SynchronousQueue在对节点进行匹配时是从栈顶开始的,所以它是非公平的SynchronousQueue实现。
公平队列实现
上面理解了非公平的堆栈实现,下面开始公平实现即队列,因为队列是一种公平的先进先出FIFO的队列。
/** Dual Queue */ 双队列
static final class TransferQueue<E> extends Transferer<E> {
/*
* This extends Scherer-Scott dual queue algorithm, differing,
* among other ways, by using modes within nodes rather than
* marked pointers. The algorithm is a little simpler than
* that for stacks because fulfillers do not need explicit
* nodes, and matching is done by CAS'ing QNode.item field
* from non-null to null (for put) or vice versa (for take).
*
* 这扩展了scher - scott双队列算法,与其他方法不同的是,它使用节点内的模式而不是标记指针。
* 由于fulfillers不需要构造成新节点,匹配由互补节点自己完成的对节点数据的CAS更新操作,因此该算法比堆栈算法简单一些。
* item字段从非null到null(用于put),反之亦然(用于take)。
*/ /** Node class for TransferQueue. */
static final class QNode {
volatile QNode next; // next node in queue 队列中的下一个节点
volatile Object item; // CAS'ed to or from null 节点数据
volatile Thread waiter; // to control park/unpark 阻塞当前节点的线程
final boolean isData; // 节点的读写标记,类似堆栈的模式 QNode(Object item, boolean isData) {
this.item = item;
this.isData = isData;
} boolean casNext(QNode cmp, QNode val) {//将当前节点的下一个节点从cmp更新成val
return next == cmp &&
UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
} boolean casItem(Object cmp, Object val) {//将当前节点的数据从cmp更新成val
return item == cmp &&
UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
} /**
* Tries to cancel by CAS'ing ref to this as item. 尝试通过将节点数据指向自身来取消等待。
*/
void tryCancel(Object cmp) {
UNSAFE.compareAndSwapObject(this, itemOffset, cmp, this);
} boolean isCancelled() { //如果节点数据item指向自己的话就是已经取消等待
return item == this;
} /**
* Returns true if this node is known to be off the queue
* because its next pointer has been forgotten due to
* an advanceHead operation.
* 如果当前节点已经不在队列中,即通过advanceHead操作将next指向自己了,则返回true。
*/
boolean isOffList() {
return next == this;
} // Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset; static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = QNode.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
} /** Head of queue */
transient volatile QNode head; //队列头
/** Tail of queue */
transient volatile QNode tail; //队列尾
/**
* Reference to a cancelled node that might not yet have been
* unlinked from queue because it was the last inserted node
* when it was cancelled.
* 指向一个已取消的节点,该节点可能尚未从队列中解除链接,因为它是在取消时最后插入的节点。
*/
transient volatile QNode cleanMe; //初始化队列的时候,创建一个虚拟节点,既是头节点也是尾节点。
TransferQueue() {
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
} /**
* Tries to cas nh as new head; if successful, unlink
* old head's next node to avoid garbage retention.
* 尝试将头节点从h设置成nh,如果成功将原来的节点next指向自己,方便垃圾回收。
*/
void advanceHead(QNode h, QNode nh) {
if (h == head &&
UNSAFE.compareAndSwapObject(this, headOffset, h, nh))
h.next = h; // forget old next
} /**
* Tries to cas nt as new tail. 尝试将尾节点从t设置成nt
*/
void advanceTail(QNode t, QNode nt) {
if (tail == t)
UNSAFE.compareAndSwapObject(this, tailOffset, t, nt);
} /**
* Tries to CAS cleanMe slot.尝试将cleanMe从cmp重置为val
*/
boolean casCleanMe(QNode cmp, QNode val) {
return cleanMe == cmp &&
UNSAFE.compareAndSwapObject(this, cleanMeOffset, cmp, val);
}
以上代码是队列实现类TransferQueue的一些基础定义,它同样扩展了抽象类Transferer,从以上的基础定义看出队列的节点类实现是静态内部类QNode,相比起堆栈实现的SNode,队列的QNode要简单一些,它只由下一个节点引用next、节点数据item、阻塞的相关线程waiter、以及布尔型的节点模式字段组成,对比SNode,它少了匹配节点引用match,以及二进制位表示的模式字段,这是因为队列的实现比起堆栈要简单,堆栈实现需要将每一个操作都封装成节点入栈,而队列的实现则只有在当操作与队列尾节点模式不互补时才需要被封装成节点入队,否则就直接尝试完成匹配返回。下面来看看它的具体实现:
/**
* Puts or takes an item. 放置或者拿出一个item
*/
@SuppressWarnings("unchecked")
E transfer(E e, boolean timed, long nanos) {
/* Basic algorithm is to loop trying to take either of
* two actions:
* 基本算法是循环尝试下面两个动作之一:
*
* 1. If queue apparently empty or holding same-mode nodes,
* try to add node to queue of waiters, wait to be
* fulfilled (or cancelled) and return matching item.
*
* 如果队列为空或者持有相同模式的节点,则尝试将节点加入到等待队列中,等待被fulfilled(或者取消)并返回匹配的数据。
*
* 2. If queue apparently contains waiting items, and this
* call is of complementary mode, try to fulfill by CAS'ing
* item field of waiting node and dequeuing it, and then
* returning matching item.
*
* 如果队列中包含等待节点,并且当前操作是与其模式互补的,尝试通过CAS设置等待节点的item字段来fulfill,并将等待节点出队,然后返回匹配的数据。
*
* In each case, along the way, check for and try to help
* advance head and tail on behalf of other stalled/slow
* threads.
*
* 在每一种情况下,在整个过程中,检查并试图帮助推进头和尾代表其他停滞/缓慢的线程。
*
* The loop starts off with a null check guarding against
* seeing uninitialized head or tail values. This never
* happens in current SynchronousQueue, but could if
* callers held non-volatile/final ref to the
* transferer. The check is here anyway because it places
* null checks at top of loop, which is usually faster
* than having them implicitly interspersed.
*
* 循环以null检查开始,以防止看到未初始化的头节点和尾节点。
* 这在当前的同步队列中从未发生过,但如果调用者持有 非volatile/final的transferer引用,则可能发生。
* 无论如何,检查都在这里,因为它将null检查放在循环的顶部,这通常比隐式地穿插检查要快。
*/ QNode s = null; // constructed/reused as needed
boolean isData = (e != null); //传入对象为空表示消费者(take),不为空表示生产者(put) for (;;) {
QNode t = tail;
QNode h = head;
//如果transferer还未初始化完成,自旋等待。
//这里只会在调用者持有的transferer引用没有被volatile/final修饰的时候才可能发生。
//因为构造transferer实例与将其赋值给一个非volatile/final变量之间不存在happens-before 关系。
if (t == null || h == null) // saw uninitialized value
continue; // spin //情况1:队列为空或者持有(队尾节点)相同模式的节点
if (h == t || t.isData == isData) { // empty or same-mode
QNode tn = t.next;
if (t != tail) // inconsistent read 有新节点入队,重新循环
continue;
if (tn != null) { // lagging tail 有新节点入队,但还没来得及将新节点设置成尾节点。
advanceTail(t, tn); //帮助新入队的节点完成成为新的尾节点,然后重新循环
continue;
}
if (timed && nanos <= 0) // can't wait 定时等待超时,直接返回null
return null;
if (s == null)
s = new QNode(e, isData); //构造新节点
//先尝试将该新节点挂在当前尾节点的后面,失败表示被其它新节点抢先入队,重新循环重试。
if (!t.casNext(null, s)) // failed to link in
continue;
//在将新节点挂到当前尾节点的后面只后,再将其设为新的尾节点。
advanceTail(t, s); // swing tail and wait //等待互补的节点来匹配或者等待中断超时
Object x = awaitFulfill(s, e, timed, nanos);
//在等待返回后,如果发现返回的结果等于自身,则说明在等待过程中已经取消了(中断或超时),则将节点从队列中清除
if (x == s) { // wait was cancelled
clean(t, s);
return null;
}
//等待等到了互补的节点,如果当前节点还没有出队,将其出队
if (!s.isOffList()) { // not already unlinked
//如果当前节点是排在最头部的节点,即 head->s-s1-s2...这种情况,那么既然s要出队,就需要重新设置head
//就是把原来的head出队了,当前节点变成了新的head节点。
advanceHead(t, s); // unlink if head
if (x != null) // and forget fields
s.item = s; //如果当前节点是一个请求数据的消费者,需要把获取到的数据忘记,方便垃圾回收。
s.waiter = null;
}
return (x != null) ? (E)x : e; //消费者返回获取的数据,生产者返回自己提供的数据 }
//情况2:队列不为空,并且当前操作与其(尾节点)模式互补的
else { // complementary-mode
//head.next就是与其互补的节点,稍后会尝试与其匹配
QNode m = h.next; // node to fulfill
//队列这时候发生了变化:
//(1)有新节点入队 t != tail,(2)等待的节点取消(中断或超时)了等待 m == null,(3)已经被其它线程抢先匹配了 h != head
if (t != tail || m == null || h != head)
continue; // inconsistent read 重新循环 //只有在m还没有被其它线程匹配,也没有取消时才尝试与其配对(m.casItem(x, e))
//否则不论m是取消了,还是被其它线程抢先匹配了,都将其出队(advanceHead(h, m))
Object x = m.item;
if (isData == (x != null) || // m already fulfilled
x == m || // m cancelled
!m.casItem(x, e)) { // lost CAS
advanceHead(h, m); // dequeue and retry
continue;
}
//成功匹配,将被匹配的m出队(其实还是出队的head,m变成了新的head)
advanceHead(h, m); // successfully fulfilled
LockSupport.unpark(m.waiter); //唤醒等待线程,使其返回
return (x != null) ? (E)x : e; //当前操作是消费者则返回获取的数据,否则返回自己提供的数据
}
}
} /**
* Spins/blocks until node s is fulfilled.
*
* @param s the waiting node
* @param e the comparison value for checking match
* @param timed true if timed wait
* @param nanos timeout value
* @return matched item, or s if cancelled
*/
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* Same idea as TransferStack.awaitFulfill */
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
//如果当前节点s就是排在最前面的(head.next),很可能立即就有互补线程来匹配,所以应该自旋
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted()) //如果中断了就取消(将item指向自身)
s.tryCancel(e);
Object x = s.item;
if (x != e) //节点已经取消(中断或超时)或者被互补线程匹配了数据,可用返回了
return x;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) { //定时等待超时了,也取消,然后返回
s.tryCancel(e);
continue;
}
}
if (spins > 0) //自旋
--spins;
else if (s.waiter == null) // 准备进入阻塞之前先设置waiter,下一次循环再次检测状态之后才阻塞
s.waiter = w;
else if (!timed)
LockSupport.park(this); //非定时阻塞
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos); //定时阻塞
}
} /**
* Gets rid of cancelled node s with original predecessor pred.使用原来的前驱节点pred删除已取消的节点s。
*/
void clean(QNode pred, QNode s) {
s.waiter = null; // forget thread
/*
* At any given time, exactly one node on list cannot be
* deleted -- the last inserted node. To accommodate this,
* if we cannot delete s, we save its predecessor as
* "cleanMe", deleting the previously saved version
* first. At least one of node s or the node previously
* saved can always be deleted, so this always terminates.
*
* 清理节点的时候,只有非尾节点才能立即被清理,对于尾节点(也即最后一个入队的节点)不能立即清理,
* 而是将其前驱节点保存到 cleanMe字段,等下一次调用clean方法的时候,发现尾节点已经变化了,
* 即上一次保存的节点由尾节点变成了非尾节点的时候才将其清理掉,这是对尾节点的延迟清理方式。 * 在任意时刻,都不能删除队列中最后插入的那个节点。为了适应这种情况,
* 如果我们不能删除节点s,我们将其前驱节点保存到"cleanMe"字段,先删除之前保存的版本。
* 至少节点s或者之前保存的节点总是能够被删除,所以结束。
*/ //如果s与其前驱节点已经断开连接,不做处理,直接返回。
while (pred.next == s) { // Return early if already unlinked
QNode h = head;
QNode hn = h.next; // Absorb cancelled first node as head
/*
* 如果第一个有效节点(head.next)已经取消了,需要将其出队。
* 这里并不是直接使head.next出队,而是使head出队,使head.next成为head。
* advanceHead还会将出队的head.next指向自身(h.next = h)使原来的head出队.
*/
if (hn != null && hn.isCancelled()) {
advanceHead(h, hn);
continue;
}
QNode t = tail; // Ensure consistent read for tail
if (t == h)
return; //队列为空,返回
QNode tn = t.next;
if (t != tail) //尾节点已经变化,即有新节点加入到队列中,重新循环
continue;
//这里说明有新节点入队,但是它只是将新节点设置为原来tail的next,还未来得及将新节点设置为新的tail
if (tn != null) {
advanceTail(t, tn); //帮助它完成身份的转变--改变tail指向新的尾节点
continue;
}
//s不是尾节点,尝试将s从队列中断开连接,即将pred.next指向s.next,成功返回
if (s != t) { // If not tail, try to unsplice
QNode sn = s.next;
if (sn == s || pred.casNext(s, sn))
return;
}
//s是尾节点,
QNode dp = cleanMe;
/*
* cleanMe表示上一次推迟清理的节点的前驱节点。
* cleanMe不为空,表示已经有需要清理的节点,就先尝试清理上一次取消的节点
*
*/
if (dp != null) { // Try unlinking previous cancelled node
QNode d = dp.next; //d就是上一次需要被清理的节点
QNode dn;
/*
* 下面一大堆判断条件,其实就是只有在需要被清理的节点d:
* (1)还存在队列中,(2)确实已经取消了,(3)并且不是尾节点,这些情况下才清理。
* 注意清理的方法dp.casNext(d, dn)是直接放在if判断条件里面的,
* 如果d已经不存在了或者被本次调用清理了就将cleanMe还原成null
*/
if (d == null || // d is gone or d消失了
d == dp || // d is off list or d已经出队了
!d.isCancelled() || // d not cancelled or d没有被取消
(d != t && // d not tail and d不是尾节点
(dn = d.next) != null && // has successor d还有后继节点
dn != d && // that is on list d还没有断开与队列的连接
dp.casNext(d, dn))) // d unspliced 尝试断开d与队列的连接 casCleanMe(dp, null); //重置cleanMe为空
/*
* 与上一次取消的节点是同一个前驱节点,如果上面的if语句已经清理成功,那么s已经被清理
* 否则,s的前驱依然保存在cleanMe字段中,只有等下一次在清理。
*/
if (dp == pred)
return; // s is already saved node
} else if (casCleanMe(null, pred)) //将前驱节点保存到cleanMe字段,返回
return; // Postpone cleaning s 推迟清理s节点
}
} private static final sun.misc.Unsafe UNSAFE;
private static final long headOffset;
private static final long tailOffset;
private static final long cleanMeOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = TransferQueue.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
cleanMeOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("cleanMe"));
} catch (Exception e) {
throw new Error(e);
}
}
}
首先队列的数据存取方式与LinkedBlockingQueue相类似,最开始队列有指向同一个实例的首尾节点head和tail,一但有节点入队(总是从尾部入队)则成为新的尾节点tail,某一个时刻不为空的队列数据像这样:head- > n1- > n2 ->n3 ....nN(tail),即队列有一个非实际的head节点,所有真正的实例节点都在它后面排列;队列中元素的出队都是从对头开始的,假设现在n1要出队,那么实际出队的节点其实是head,只不过将n1携带的数据剥离掉使其成为了新的不携带数据的head:n1(head) -> n2 -> n3....nN(tail)。
队列实现的SynchronousQueue逻辑是这样的:如果队列为空或者当前操作与尾节点(注意是与尾节点比较)模式相同,则将其构造成新的节点从尾部入队,成为新的尾节点;如果当前操作与尾节点模式互补,那么就用head.next(注意是对头节点)与其尝试匹配,匹配就是将当前操作的数据与互补节点的数据item互换,所以item要么从null变成了非空,要么从非空变成null,匹配成功唤醒等待节点,出队那个head.next节点,最后各自线程返回。匹配失败(head.next节点线程超时或中断或被其它线程抢先匹配了)则继续与新的尾节点比较模式,决定是入队等待还是与新的head.next进行尝试匹配。可见队列中的所有节点其实都是模式相同的,一旦互补操作达到,就尝试从队头取走一个节点完成匹配,与堆栈不同的是,队列的节点匹配是可以被其它线程抢占的,所以也不像堆栈实现那样有被后来的操作辅助完成匹配的过程。
队列实现对由于中断或超时而取消的节点的清理与堆栈的实现也是不一样的,对于非尾节点的清理可以直接修改它的前驱节点next指向被取消节点的next即可(被清理的节点真正出队是在当它成为head之后由advanceHead方法完成的),但是对于尾节点的清理则不是这么容易的,这里对尾节点的清理采用了延迟清理的策略,即先将其前驱记录到一个cleanMe的字段,等下一次调用清理时如果发现上一次打算清理的节点从当初的尾节点变成了非尾节点,那么就可以直接通过修改其前驱节点的next指针来达到清理的目得,否则只能继续推迟清理。这里之所以采用这种延迟清理尾节点的策略是因为队列实现中,新节点的入队分两步完成,并且这两个步骤不是原子的:步骤①将当前尾节点tail.next指向新节点;步骤②将新节点设置成新的尾节点tail。所以对于尾节点的清理只能等它成为非尾节点的时候才能进行,否则将可能丢失那些只完成了步骤①,还没来得及完成步骤②的新入队节点。
队列实现的逻辑相对简单一些,即与尾节点模式相同则入队,否则直接尝试与对头节点(head.next)完成数据交接传递,成功则都返回,失败继续与尾节点比较考虑是进行与新的头节点匹配还是入队等待,执行的过程就不再画图举例。
SynchronousQueue
通过上面对SynchronousQueue的公平与非公平策略的相应不同实现分析,已经对SynchronousQueue的原理搞清楚了,然后再来看SynchronousQueue的构造方法和对外提供的相关接口,这些方法才是我们使用SynchronousQueue的时候直接接触的方法。
构造方法
private transient volatile Transferer<E> transferer; /**
* Creates a {@code SynchronousQueue} with nonfair access policy. 默认创建非公平策略的实例
*/
public SynchronousQueue() {
this(false);
} /**
* Creates a {@code SynchronousQueue} with the specified fairness policy.
* 传入true,创建公平的实例,等待线程使用FIFO队列排队
*/
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
构造方法很简单,默认创建使用LIFO的堆栈实现的非公平策略的SynchronousQueue实例,传入true才创建基于FIFO的队列实现的公平策略实例。
数据放入
/**
* 将指定的元素添加到此队列中,等待另一个线程接收它或者被中断。
* 不允许放入null元素,
*/
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
} /**
* 如果另一个线程正在等待接收指定的元素,则将其插入此队列。
* 只有当已经有一个线程正在等待接收数据,该方法立即返回true,否则立即返回false
*/
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
return transferer.transfer(e, true, 0) != null;
}
offer的超时版本的方法并没有贴出来,put的实现是transferer.transfer(e, false, 0),第二个参数timed是false,所以put是非定时的无限制等待方法,直到有线程取走该线程放入的数据或被中断。而offer的实现是transferer.transfer(e, true, 0),第二个参数timed是true,所以是定时等待,但是第三个表示等待时长的参数是0,所以offer会立即返回,如果调用offer的时候存在一个线程正在等待接收数据,则offer方法立即返回true,否则立即返回false。
数据接收
/**
* 检索并删除此队列的头,等待直到另一个线程插入它或者被中断
*/
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
} /**
* 如果另一个线程当前正在放入数据,则检索并删除此队列的头。
*/
public E poll() {
return transferer.transfer(null, true, 0);
}
poll的超时版本的方法并没有贴出来,take的实现是transferer.transfer(null, false, 0),第二个参数timed是false,所以take是非定时的无限制等待方法,直到有线程放入数据被该线程获取到或被中断。而poll的实现是transferer.transfer(null, true, 0),第二个参数timed是true,所以是定时等待,但是第三个表示等待时长的参数是0,所以poll会立即返回,如果调用poll的时候存在一个线程正在放入数据,并被当前线程接收则poll返回接收到的数据,否则返回null。
总之,put/take方法的调用只有等到与其互补的操作出现并完成数据的交接传递才会返回,否则一直等待,除了被中断也会立即返回;而offer/poll这种非阻塞的方法不论数据是否成功交接传递都会立即返回。SynchronousQueue还提供了offer和poll的指定等待超时时长的重载方法,可用于等待指定的时长。
总结
SynchronousQueue是一种特殊的阻塞队列,我们可以把它看作是一种容量为0的集合,因为所有Collection的相关方法(包括迭代器)都将把SynchronousQueue当成一个空队列处理,SynchronousQueue的主要特点就是当一个操作试图放入数据或取走数据的时候,只有出现相应的互补操作才能成功返回,SynchronousQueue可以看作是一种数据交接的工具,例如:一个线程执行了put操作打算放入数据,那么只有出现或者已经存在一个线程试图取走数据(take或poll),并且它们完成了数据的传递才会返回,反之亦然,当然线程被中断也可以使线程立即返回。SynchronousQueue还提供了非阻塞的立即返回操作例如offer、poll,这种方法一般只有在事先已经存在一个互补的阻塞等待操作才有可能奏效,否则多半无功而返。
Java同步数据结构之SynchronousQueue的更多相关文章
- Java同步数据结构之ConcurrentSkipListMap/ConcurrentSkipListSet
引言 上一篇Java同步数据结构之Map概述及ConcurrentSkipListMap原理已经将ConcurrentSkipListMap的原理大致搞清楚了,它是一种有序的能够实现高效插入,删除,更 ...
- Java同步数据结构之LinkedTransferQueue
前言 LinkedTransferQueue是Java并发包中最强大的基于链表的无界FIFO阻塞传输队列.从JDK7开始出现,Doug Lea说LinkedTransferQueue是Concurre ...
- Java同步数据结构之CopyOnWriteArrayList/CopyOnWriteArraySet
前言 前面介绍完了队列(包括双端队列),今天探讨以下Java并发包中一个List的并发数据结构实现CopyOnWriteArrayList,顾名思义CopyOnWriteArrayList也是一种基于 ...
- Java同步数据结构之PriorityBlockingQueue
前言 接下来继续BlockingQueue的另一个实现,优先级阻塞队列PriorityBlockingQueue.PriorityBlockingQueue是一个无限容量的阻塞队列,由于容量是无限的所 ...
- Java同步数据结构之ArrayBlockingQueue
引言 作为BlockingQueue最常见的实现类之一,ArrayBlockingQueue是通过数组实现的FIFO先进先出有界阻塞队列,它的大小在实例被初始化的时候就被固定了,不能更改.该类支持一个 ...
- Java同步数据结构之ConcurrentHashMap
前言 这是Java并发包最后一个集合框架的数据结构,其复杂程度也较以往任何数据结构复杂的多,顾名思义ConcurrentHashMap是线程安全版本的HashMap,总所周知HashMap是非线程安全 ...
- Java同步数据结构之DelayQueue/DelayedWorkQueue
前言 前面介绍了优先级队列PriorityBlockingQueue,顺带也说了一下PriorityQueue,两者的实现方式是一模一样的,都是采用基于数组的平衡二叉堆实现,不论入队的顺序怎么样,ta ...
- Java同步数据结构之Map概述及ConcurrentSkipListMap原理
引言 前面介绍了CopyOnWriteArraySet,本来接着是打算介绍ConcurrentSkipListSet,无耐ConcurrentSkipListSet的内部实现其实是依赖一个Concur ...
- Java同步数据结构之ConcurrentLinkedDeque
前言 由于LinkedBlockingDeque作为双端队列的实现,采用了单锁的保守策略使其不利于多线程并发情况下的使用,故ConcurrentLinkedDeque应运而生,它是一种基于链表的无界的 ...
随机推荐
- C# 普通的辅助类
在数字前面补0 /// <summary> /// 在数字前面添加0 /// </summary> /// <param name="num"> ...
- [daily]使用iptables配置NAT的命令速查
时常,快速的配置一个临时的NAT环境是很常用需求. 但是,每次我都要读iptables的手册,才能配出来.所以,备忘一个速查. DNAT: iptables -t nat -A PREROUTING ...
- 虚拟机ipv6环境搭建操作指南
一.vmware的相关配置 (1)点击编辑,选择虚拟网络编辑器 (2)选择带NAT模式的VMnet8网络,点击NAT设置 (3)在NAT设置中启用IPV6 (4)设置好后,点击应用 (5)再选择镜 ...
- Java 中的多态,一次讲个够之接口实现关系中的多态
上文还没有写完,这一篇继续 Java 中的多态,一次讲个够之继承关系中的多态 https://www.cnblogs.com/qianjinyan/p/10824576.html 接口实现关系,和继承 ...
- 【产品对比】Word开发工具Aspose.Words和Spire.Doc性能和优劣对比一览
转:evget.com/article/2018/4/3/27885.html 概述:Microsoft Office Word是微软公司的一个文字处理器应用程序,作为办公软件必不可少的神器之一,Wo ...
- 09—mybatis注解配置join查询
今天来聊mybatis的join查询,怎么说呢,有的时候,join查询确实能提升查询效率,今天举个left join的例子,来看看mybatis的join查询. 就不写的很细了,把主要代码贴出来了. ...
- Excle导出优化(poi)
搜索词条 1.idea报java.lang.OutOfMemoryError: Java heap space怎么解决? 2.java.lang.OutOfMemoryError: GC overhe ...
- Java8-Executors-No.03
import java.util.Arrays; import java.util.List; import java.util.concurrent.Callable; import java.ut ...
- Time travel HDU - 4418 (概率DP)
对于每个点两个方向(两头只有一个方向)建一个点,然后预处理出每个点走k(1≤k≤n)k(1\le k\le n)k(1≤k≤n)到哪个点,列出方程式高斯消元就行了.记得前面bfsbfsbfs出那些点不 ...
- P2634 [国家集训队]聪聪可可 点分治
思路:点分治 提交:1次 题解: 不需要什么容斥...接着板子题说: 还是基本思路:对于一颗子树,与之前的子树做贡献. 我们把路径的权值在\(\%3\)意义下分类,即开三个桶\(c[0],c[1],c ...