Pyspider爬虫教程
Pyspider爬虫教程
一、安装
1、 安装pip
(1)准备工作
yum install –y make gcc-c++ python-devel libxml2-devel libxslt-devel
(2)安装setuptools
https://pypi.python.org/pypi/setuptools/
python setup.py install
(3)安装pip
https://pypi.python.org/pypi/pip
python setup.py install
2、 安装pyspider
(1)安装pyspider及其依赖
pip install pyspider
OR
pip install --allow-all-external pyspider[all]
3、 安装可选库
pip install rsa
4、 phantomjs
下载后复制至/bin/
二、部署pyspider服务器
(1)配置pyspider.conf
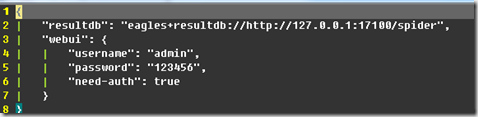
配置eagles引擎和生成结果数据库,配置用户名。密码等
(2)运行install.sh安装脚本
(3)/etc/init.d/pyspider start 启动服务即可
三、使用
(1)ip:5000直接打开网页客户端

(2)点击创建脚本
(3)编写脚本,直接调试
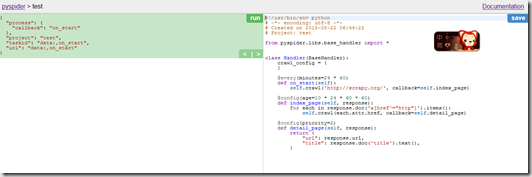
(4)选择“running“点击运行
四、爬虫教程(1)—抓取简单的静态页面
静态页面的抓取最简单,获取HTML页面进行标签抽取即可,例子如下:
贵阳晚报新闻文章抓取:http://www.gywb.com.cn/
# Handler类和入口函数class Handler(BaseHandler):crawl_config = {}@every(minutes=24 * 60)def on_start(self):for url in urlList:self.crawl(url, callback=self.index_page)
self.crawl抓取贵阳晚报首页的url,跳转到回调函数index_page
# 回调函数index_page# config age:10天不刷新# response.url:抓取的url# response.doc(pyquery):获取标签内容,参数:pyquery标签# 通过又一次抓取url到detail_page@config(age=10 * 24 * 60 * 60)def index_page(self, response):for each in response.doc('a[href^="http"]').items():for url in urlList:if ('%s%s' % (url, 'content/') in each.attr.href) and \ # 字符串连接(not ("#" in each.attr.href)): # 判断#是否在href里面self.crawl(each.attr.href, callback=self.detail_page)
详细页面detail_page:获取文章标题,文章内容,时间等
# config priority:调用优先级@config(priority=2)def detail_page(self, response):# article titleartTitle = response.doc(artTitleSelector1).text().strip() # 获取文章标题, artTitleSelector1:pyquery标签,如:h1[class="g-content-t text-center"]
完整代码如下:
#!/usr/bin/env python# -*- encoding: utf-8 -*-# Created on 2015-05-12 10:41:03# Project: GYWBfrom pyspider.libs.base_handler import *import reurlList = [ "http://www.gywb.com.cn/" ]keyWords = [ #u"贵阳",#u"交通",u"违章",u"交警",u"交通管理",#u"交通管理局",u"交管局" ]# article titleartTitleSelector1 = 'h1[class="g-content-t text-center"]'artTitleSelector2 = 'div[class="detail_title_yy"] h1'# article contentartContentSelector1 = 'div[class="g-content-c"] p'artContentSelector2 = 'div[class="detailcon"] p'# publish timeartPubTimeSelector1 = '#pubtime_baidu'artPubTimeFilter1 = r'[^\d]*'artPubTimeSelector2 = '.detail_more'artPubTimeFilter2 = r'[\d\-\:\ ]*'class Handler(BaseHandler):crawl_config = {}@every(minutes=24 * 60)def on_start(self):for url in urlList:self.crawl(url, callback=self.index_page)@config(age=10 * 24 * 60 * 60)def index_page(self, response):for each in response.doc('a[href^="http"]').items():for url in urlList:if ('%s%s' % (url, 'content/') in each.attr.href) and \(not ("#" in each.attr.href)):self.crawl(each.attr.href, callback=self.detail_page)@config(priority=2)def detail_page(self, response):for each in response.doc('a[href^="http"]').items():self.crawl(each.attr.href, callback=self.index_page)# article titleartTitle = response.doc(artTitleSelector1).text().strip()if artTitle == '':artTitle = response.doc(artTitleSelector2).text().strip()if artTitle == '':return NoneartContent = response.doc(artContentSelector1).text().strip()if artContent == '':artContent = response.doc(artContentSelector2).text().strip()artPubTime = response.doc(artPubTimeSelector1).text().strip()if artPubTime != '':match = re.match (artPubTimeFilter1, artPubTime)if match != None:artPubTime = artPubTime[len(match.group()):]else:artPubTime = response.doc(artPubTimeSelector2).text().strip()match = re.match (artPubTimeFilter1, artPubTime)if match != None:artPubTime = artPubTime[len(match.group()):]match = re.search (artPubTimeFilter2, artPubTime)if match != None:artPubTime = match.group()artPubTime = artPubTime.strip()for word in keyWords:if word in artContent:return {#"url": response.url,#"title": response.doc('title').text(),"title" : artTitle,"time" : artPubTime,"content" : artContent,}else:return None
五、爬虫教程(2)—HTTP请求的页面(如登陆后抓取)
例子:爱卡汽车论坛:http://a.xcar.com.cn/bbs/forum-d-303.html
首先登陆就需要用户名和密码,但是好的网站都需要对用户名和密码进行加密的。所以我们只能模拟登陆方式,获取用户名和密码的加密类型,从而来进行模拟登陆,模拟登陆就需要获取浏览器的cookie
class Handler(BaseHandler):crawl_config = {}@every(minutes=24 * 60)def on_start(self):cookies = getCookies() # 获取cookiefor url in URL_LIST:self.crawl(url, cookies = cookies, callback=self.index_page) # 传入cookie模拟登陆
那么怎么样才能获取cookie呢?
(1)获取post提交的data,可以使用Firefox的httpfox插件或者wireshark来对包进行抓取
下面是采用Firefox的httpfox插件进行抓取

从上图可以看出,post_data包含username和password,还有chash和dhash等,当然这些都是进行加密后的。
所以在程序中需要获取post_data
def getPostData(self):url = self.login_url.strip() # 登陆的urlif not re.match(r'^http://', url):return None, Nonereq = urllib2.Request(url)resp = urllib2.urlopen(req)login_page = resp.read()# 获取html表单数据doc = HTML.fromstring (login_page)post_url = doc.xpath("//form[@name='login' and @id='login']/@action")[0][1:]chash = doc.xpath("//input[@name='chash' and @id='chash']/@value")[0]dhash = doc.xpath("//input[@name='dhash' and @id='dhash']/@value")[0]ehash = doc.xpath("//input[@name='ehash' and @id='ehash']/@value")[0]formhash = doc.xpath("//input[@name='formhash']/@value")[0]loginsubmit = doc.xpath("//input[@name='loginsubmit']/@value")[0].encode('utf-8')cookietime = doc.xpath("//input[@name='cookietime' and @id='cookietime']/@value")[0]username = self.account # 账户password = self.encoded_password # 密码#组合post_datapost_data = urllib.urlencode({'username' : username,'password' : password,'chash' : chash,'dhash' : dhash,'ehash' : ehash,'loginsubmit' : loginsubmit,'formhash' : formhash,'cookietime' : cookietime,})return post_url, post_data
#将post_data作为参数模拟登陆def login(self):post_url, post_data = self.getPostData()post_url = self.post_url_prefix + post_urlreq = urllib2.Request(url = post_url, data = post_data)resp = urllib2.urlopen(req)return True
# 通过本地浏览器cookie文件获取cookie# 账号进行md5加密COOKIES_FILE = '/tmp/pyspider.xcar.%s.cookies' % hashlib.md5(ACCOUNT).hexdigest()COOKIES_DOMAIN = 'xcar.com.cn'def getCookies():CookiesJar = cookielib.MozillaCookieJar(COOKIES_FILE)if not os.path.isfile(COOKIES_FILE):CookiesJar.save()CookiesJar.load (COOKIES_FILE)CookieProcessor = urllib2.HTTPCookieProcessor(CookiesJar)CookieOpener = urllib2.build_opener(CookieProcessor, urllib2.HTTPHandler)for item in HTTP_HEADERS:CookieOpener.addheaders.append ((item ,HTTP_HEADERS[item]))urllib2.install_opener(CookieOpener)if len(CookiesJar) == 0:xc = xcar(ACCOUNT, ENCODED_PASSWORD, LOGIN_URL, POST_URL_PREFIX)if xc.login(): # 判断登陆成功,保存cookieCookiesJar.save()else:return NoneCookiesDict = {}# 选择对本次登陆的cookiefor cookie in CookiesJar:if COOKIES_DOMAIN in cookie.domain:CookiesDict[cookie.name] = cookie.valuereturn CookiesDict
怎样查看用户名和密码的加密类型?——通过查看js文件
查看登陆login.js和表单信息login.php
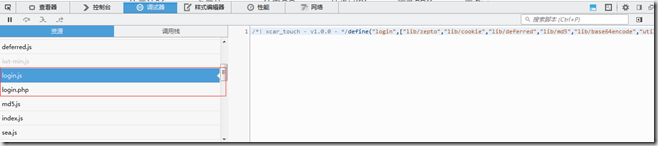
发现:username是采用base64加密,password是先采用md5加密,然后再进行base64加密

完整代码如下:
#!/usr/bin/env python# -*- encoding: utf-8 -*-# Created on 2015-05-14 17:39:36# Project: test_xcarfrom pyspider.libs.base_handler import *from pyspider.libs.response import *from pyquery import PyQueryimport osimport reimport urllibimport urllib2import cookielibimport lxml.html as HTMLimport hashlibURL_LIST= [ 'http://a.xcar.com.cn/bbs/forum-d-303.html' ]THREAD_LIST_URL_FILTER = 'bbs/forum-d-303'THREAD_LIST_URL_REG = r'bbs\/forum-d-303(-\w+)?\.'ACCOUNT = 'ZhangZujian'# 32-bit MD5 HashENCODED_PASSWORD = 'e3d541408adb57f4b40992202c5018d8'LOGIN_URL = 'http://my.xcar.com.cn/logging.php?action=login'POST_URL_PREFIX = 'http://my.xcar.com.cn/'THREAD_URL_REG = r'bbs\/thread-\w+-0'THREAD_URL_HREF_FILTER = 'bbs/thread-'THREAD_URL_CLASS_LIST = [ 'prev', 'next' ]THREAD_THEME_SELECTOR = 'h2'POST_ITEM_SELECTOR = '.posts-con > div'POST_TIME_SELECTOR = '.pt-time > span'POST_MEMBER_SELECTOR = '.pt-name'POST_FLOOR_SELECTOR = '.pt-floor > span'POST_CONTENT_SELECTOR = '.pt-cons'# THREAD_REPLY_SELECTOR = ''# !!! Notice !!!# Tasks that share the same account MUST share the same cookies fileCOOKIES_FILE = '/tmp/pyspider.xcar.%s.cookies' % hashlib.md5(ACCOUNT).hexdigest()COOKIES_DOMAIN = 'xcar.com.cn'# USERAGENT_STR = 'Mozilla/5.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12A366 Safari/600.1.4'HTTP_HEADERS = {'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',# 'Accept-Encoding' : 'gzip, deflate, sdch','Accept-Language' : 'zh-CN,zh;q=0.8,en;q=0.6','Connection' : 'keep-alive','DNT' : '1','Host' : 'my.xcar.com.cn','Referer' : 'http://a.xcar.com.cn/','User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36',}class xcar(object):def __init__(self, account, encoded_password, login_url, post_url_prefix):self.account = accountself.encoded_password = encoded_passwordself.login_url = login_urlself.post_url_prefix = post_url_prefixdef login(self):post_url, post_data = self.getPostData()post_url = self.post_url_prefix + post_urlreq = urllib2.Request(url = post_url, data = post_data)resp = urllib2.urlopen(req)return Truedef getPostData(self):url = self.login_url.strip()if not re.match(r'^http://', url):return None, Nonereq = urllib2.Request(url)resp = urllib2.urlopen(req)login_page = resp.read()doc = HTML.fromstring (login_page)post_url = doc.xpath("//form[@name='login' and @id='login']/@action")[0][1:]chash = doc.xpath("//input[@name='chash' and @id='chash']/@value")[0]dhash = doc.xpath("//input[@name='dhash' and @id='dhash']/@value")[0]ehash = doc.xpath("//input[@name='ehash' and @id='ehash']/@value")[0]formhash = doc.xpath("//input[@name='formhash']/@value")[0]loginsubmit = doc.xpath("//input[@name='loginsubmit']/@value")[0].encode('utf-8')cookietime = doc.xpath("//input[@name='cookietime' and @id='cookietime']/@value")[0]username = self.accountpassword = self.encoded_passwordpost_data = urllib.urlencode({'username' : username,'password' : password,'chash' : chash,'dhash' : dhash,'ehash' : ehash,'loginsubmit' : loginsubmit,'formhash' : formhash,'cookietime' : cookietime,})return post_url, post_datadef getCookies():CookiesJar = cookielib.MozillaCookieJar(COOKIES_FILE)if not os.path.isfile(COOKIES_FILE):CookiesJar.save()CookiesJar.load (COOKIES_FILE)CookieProcessor = urllib2.HTTPCookieProcessor(CookiesJar)CookieOpener = urllib2.build_opener(CookieProcessor, urllib2.HTTPHandler)for item in HTTP_HEADERS:CookieOpener.addheaders.append ((item ,HTTP_HEADERS[item]))urllib2.install_opener(CookieOpener)if len(CookiesJar) == 0:xc = xcar(ACCOUNT, ENCODED_PASSWORD, LOGIN_URL, POST_URL_PREFIX)if xc.login():CookiesJar.save()else:return NoneCookiesDict = {}for cookie in CookiesJar:if COOKIES_DOMAIN in cookie.domain:CookiesDict[cookie.name] = cookie.valuereturn CookiesDictclass Handler(BaseHandler):crawl_config = {}@every(minutes=24 * 60)def on_start(self):cookies = getCookies()for url in URL_LIST:self.crawl(url, cookies = cookies, callback=self.index_page)@config(age=10 * 24 * 60 * 60)def index_page(self, response):cookies = getCookies()for each in response.doc('a[href*="%s"]' % THREAD_URL_HREF_FILTER).items():if re.search(THREAD_URL_REG, each.attr.href) and \'#' not in each.attr.href:self.crawl(each.attr.href, cookies = cookies, callback=self.detail_page)for each in response.doc('a[href*="%s"]' % THREAD_LIST_URL_FILTER).items():if re.search(THREAD_LIST_URL_REG, each.attr.href) and \'#' not in each.attr.href:self.crawl(each.attr.href, cookies = cookies, callback=self.index_page)@config(priority=2)def detail_page(self, response):cookies = getCookies()if '#' not in response.url:for each in response.doc(POST_ITEM_SELECTOR).items():floorNo = each(POST_FLOOR_SELECTOR).text()url = '%s#%s' % (response.url, floorNo)self.crawl(url, cookies = cookies, callback=self.detail_page)return Noneelse:floorNo = response.url[response.url.find('#')+1:]for each in response.doc(POST_ITEM_SELECTOR).items():if each(POST_FLOOR_SELECTOR).text() == floorNo:theme = response.doc(THREAD_THEME_SELECTOR).text()time = each(POST_TIME_SELECTOR).text()member = each(POST_MEMBER_SELECTOR).text()content = each(POST_CONTENT_SELECTOR).text()return {# "url" : response.url,# "title" : response.doc('title').text(),'theme' : theme,'floor' : floorNo,'time' : time,'member' : member,'content' : content,}
六、爬虫教程(3)使用Phantomjs渲染带js的页面(视频链接抓取)
(1)安装Phantomjs
(2)其实和爬取网页的不同点在于,传入fetch_tpy = 'js'
#!/usr/bin/env python# -*- encoding: utf-8 -*-# Created on 2015-03-20 09:46:20# Project: fly_spiderimport reimport time#from pyspider.database.mysql.mysqldb import SQLfrom pyspider.libs.base_handler import *from pyquery import PyQuery as pqclass Handler(BaseHandler):headers= {"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding":"gzip, deflate, sdch","Accept-Language":"zh-CN,zh;q=0.8","Cache-Control":"max-age=0","Connection":"keep-alive","User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36"}crawl_config = {"headers" : headers,"timeout" : 100}@every(minutes= 1)def on_start(self):self.crawl('http://www.zhanqi.tv/games',callback=self.index_page)@config(age=10 * 24 * 60 * 60)def index_page(self, response):print(response)for each in response.doc('a[href^="http://www.zhanqi.tv/games/"]').items():if re.match("http://www.zhanqi.tv/games/\w+", each.attr.href, re.U):self.crawl(each.attr.href,fetch_type='js', # fetch_type参数js_script=""" # JavaScriptfunction() {setTimeout(window.scrollTo(0,document.body.scrollHeight), 5000);}""",callback=self.list_page)@config(age=1*60*60, priority=2)def list_page(self, response):for each in response.doc('.active > div.live-list-tabc > ul#hotList.clearfix > li > a').items():if re.match("http://www.zhanqi.tv/\w+", each.attr.href, re.U):self.crawl(each.attr.href,fetch_type='js',js_script="""function() {setTimeout(window.scrollTo(0,document.body.scrollHeight), 5000);}""",callback=self.detail_page)@config(age=1*60*60, priority=2)def detail_page(self, response):for each in response.doc('.video-flash-cont').items():d = pq(each)print(d.html())return {"url": response.url,"author":response.doc('.meat > span').text(),"title":response.doc('.title-name').text(),"game-name":response.doc('span > .game-name').text(),"users2":response.doc('div.live-anchor-info.clearfix > div.sub-anchor-info > div.clearfix > div.meat-info > span.num.dv.js-onlines-panel > span.dv.js-onlines-txt > span').text(),"flash-cont":d.html(),"picture":response.doc('.active > img').text(),}
七、附录
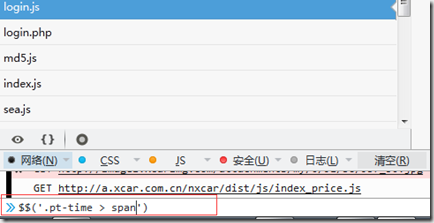
怎样判断获取pyquery的结果是自己想要的?
通过参看元素的命令行,可以查看结果
八、参考
官方教程:http://docs.pyspider.org/en/latest/tutorial/
pyspider 爬虫教程(一):HTML 和 CSS 选择器:http://segmentfault.com/a/1190000002477863
pyspider 爬虫教程(二):AJAX 和 HTTP:http://segmentfault.com/a/1190000002477870
pyspider 爬虫教程(三):使用 PhantomJS 渲染带 JS 的页面:http://segmentfault.com/a/1190000002477913
Pyspider爬虫教程的更多相关文章
- pyspider 爬虫教程(一):HTML 和 CSS 选择器
虽然以前写过 如何抓取WEB页面 和 如何从 WEB 页面中提取信息.但是感觉还是需要一篇 step by step 的教程,不然没有一个总体的认识.不过,没想到这个教程居然会变成一篇译文,在这个 ...
- LINUX搭建PySpider爬虫服务
1.环境搭建 yum update -y yum install gcc gcc-c++ -y yum install python-pip python-devel python-distribut ...
- 搭建pyspider爬虫服务
1. 环境准备 首先yum更新 yum update -y 安装开发编译工具 yum install gcc gcc-c++ -y 安装依赖库 yum install python-pip pytho ...
- Python爬虫教程-30-Scrapy 爬虫框架介绍
从本篇开始学习 Scrapy 爬虫框架 Python爬虫教程-30-Scrapy 爬虫框架介绍 框架:框架就是对于相同的相似的部分,代码做到不出错,而我们就可以将注意力放到我们自己的部分了 常见爬虫框 ...
- pyspider爬虫框架的安装和使用
pyspider是国人binux编写的强大的网络爬虫框架,它带有强大的WebUI.脚本编辑器.任务监控器.项目管理器以及结果处理器,同时支持多种数据库后端.多种消息队列,另外还支持JavaScript ...
- 再次分享 pyspider 爬虫框架 - V2EX
再次分享 pyspider 爬虫框架 - V2EX block
- Python3.x爬虫教程:爬网页、爬图片、自己主动登录
林炳文Evankaka原创作品. 转载请注明出处http://blog.csdn.net/evankaka 摘要:本文将使用Python3.4爬网页.爬图片.自己主动登录.并对HTTP协议做了一个简单 ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
随机推荐
- WebService之XFire和SOAP实例(基于JAVA)
开发环境:jdk1.6 + Tomcat7 + MyEclipse10 源码下载地址张贴在文章最后面:首先是使用WSDL协议实现:这里使用XFire XFire一个免费.开源的SOAP框架,它构建了P ...
- Get请求-Test版
package com.fanqi.test; import java.io.DataInputStream; import java.io.IOException; import java.io.I ...
- c# ,socket编程的一些常用方法
1 命名空间 需要添加的命名空间 using System.Net; using System.Net.Socket; 2 构造新的socket对象 socket原型: public socket ( ...
- Android REST webservice 类
App与后台交互,后台使用的是Jersey RESTful 服务.在APP端使用Android 内部集成的HttpClient接口,无需引入第三方jar包, import org.apache.htt ...
- TCP原理
1.http://coolshell.cn/articles/11564.html 2.http://coolshell.cn/articles/11609.html 3.一站式学习wireshark ...
- POJ 3613 Cow Relays (floyd + 矩阵高速幂)
题目大意: 求刚好经过K条路的最短路 我们知道假设一个矩阵A[i][j] 表示表示 i-j 是否可达 那么 A*A=B B[i][j] 就表示 i-j 刚好走过两条路的方法数 那么同理 我们把 ...
- 我的Android进阶之旅------>Android无第三方Jar包的源代报错:The current class path entry belongs to container ...的解决方法
今天使用第三方Jar包afinal.jar时候.想看一下源码,无法看 然后像加入jar相应的源代码包.也无法加入相应的源代码,报错例如以下:The current class path entry b ...
- [设计模式]迭代子模式 Iterator
迭代子模式又叫做游标cursor模式,是对象的行为模式.迭代子模式可以顺序的访问一个聚集中的元素而不必暴露聚集的内部表象. 迭代子模式被广泛的应用在Java语言的API中的几个设计模式之一.在Java ...
- pyton全栈开发从入门到放弃之数据类型与变量
一.变量 1 什么是变量之声明变量 #变量名=变量值 age=18 gender1='male' gender2='female' 2 为什么要有变量 变量作用:“变”=>变化,“量”=> ...
- Delphi 正则表达式之TPerlRegEx 类的属性与方法(4): Replace
Delphi 正则表达式之TPerlRegEx 类的属性与方法(4): Replace // Replace var reg: TPerlRegEx; begin reg := TPerlRe ...