第三章——供机器读取的数据(XML)
本书使用的文件、代码:https://github.com/huangtao36/data_wrangling
第三章使用的数据文件:
XML数据

XML中有两个位置可以保存数据:
1、两个标签之间:<Display>71</Display>
2、标签的属性:<Dim Category="SEX" Code="BTSX"/>——其中Category的属性值是“SEX”,Code的属性值是"BTSX"。
XML的属性可以保存特定标签的额外信息,这些标签又嵌套在另一个标签中。
实现代码(基于Python3)
from xml.etree import ElementTree as ET
tree = ET.parse('data-text.xml')
root = tree.getroot() #获取树的根元素
data = root.find('Data')
all_data = []
for observation in data:
record = {}
for item in observation:
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
if lookup_key == 'Numeric':
rec_key = 'NUMERIC'
rec_value = item.attrib['Numeric']
else:
rec_key = item.attrib[lookup_key]
rec_value = item.attrib['Code']
record[rec_key] = rec_value
all_data.append(record)
print (all_data)
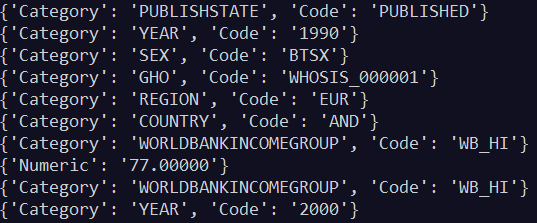
输出(部分):

(输出的是单行数据,为了直观,这里进行了处理。)
代码解释
from xml.etree import ElementTree as ET
本例中使用的是ElementTree、还可以使用lxml、minidom这两种库来解析XML文件,在此不做说明
获取Observation元素中的内容
由上面的样本可知,我们使用的数据是包含在一个<Data>...</Data>中的,这里使用根元素的find方法可以利用标签名来搜索子元素。
from xml.etree import ElementTree as ET
tree = ET.parse('data-text.xml')
root = tree.getroot() #获取树的根元素
data = root.find('Data')
for observation in data:
for item in observation:
print(item.attrib)
输出(部分):
from xml.etree import ElementTree as ET
tree = ET.parse('data-text.xml')
root = tree.getroot() #获取树的根元素
data = root.find('Data')
all_data = []
for observation in data:
record = {}
for item in observation:
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
rec_key = item.attrib[lookup_key]
print(rec_key)
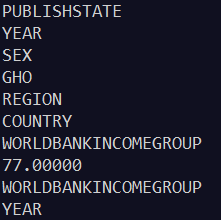
上面代码得到了数据的键,但还没有取得相应的值。
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
from xml.etree import ElementTree as ET
tree = ET.parse('data-text.xml')
root = tree.getroot() #获取树的根元素
data = root.find('Data')
all_data = []
for observation in data:
record = {}
for item in observation:
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
if lookup_key == 'Numeric':
rec_key = 'NUMERIC'
rec_value = item.attrib['Numeric']
else:
rec_key = item.attrib[lookup_key]
rec_value = item.attrib['Code']
print(rec_key,rec_value)

第三章——供机器读取的数据(XML)的更多相关文章
- 第三章——供机器读取的数据(CSV与JSON)
本书使用的文件.代码:https://github.com/huangtao36/data_wrangling 机器可读(machine readable)文件格式: 1.逗号分隔值(Comma-Se ...
- python数据处理(一)之供机器读取的数据 csv,json,xml
代码与资料 https://github.com/jackiekazil/data-wrangling 1 csv 1.1导入csv数据 1.2将代码保存到文件中并在命令行中运行 2.json 2 导 ...
- 第三章:使用ListView展示数据
一.ImageList:存储图像集合 Images 存储的所有图像 ImageSize 图像的大小 ColorDepth 颜色数 TransparentColor 被视为透明的颜色 先设置ColorD ...
- 数据库-第三章 关系数据库标准语言SQL-3.3 数据查询
数据查询 例: 一.单表查询 1.定义 是指仅涉及一个表的查询 2.选择表中的若干列 查询指定列 例: 查询全部列 例: 查询经过计算的值 例: 3.选择表中的若干元组 消除取值重复的行 例: 查询满 ...
- SQL SERVER 2012 第三章 使用INSERT语句添加数据
INSERT [TOP (<expression>) [PERCENT] [INTO] <tabular object>[(column list)][OUTPUT <o ...
- (第二章第三部分)TensorFlow框架之读取二进制数据
系列博客链接: (第二章第一部分)TensorFlow框架之文件读取流程:https://www.cnblogs.com/kongweisi/p/11050302.html (第二章第二部分)Tens ...
- Laxcus大数据管理系统2.0(5)- 第三章 数据存取
第三章 数据存取 当前的很多大数据处理工作,一次计算产生几十个GB.或者几十个TB的数据已是正常现象,驱动数百.数千.甚至上万个计算机节点并行运行也已经不足为奇.但是在数据处理的后面,对于这种在网络间 ...
- CentOS6安装各种大数据软件 第三章:Linux基础软件的安装
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- (第二章第二部分)TensorFlow框架之读取图片数据
系列博客链接: (第二章第一部分)TensorFlow框架之文件读取流程:https://www.cnblogs.com/kongweisi/p/11050302.html 本文概述: 目标 说明图片 ...
随机推荐
- ethereum(以太坊)(实例)--"安全的远程购买"
pragma solidity ^0.4.10; contract Safebuy{ uint public price; address public seller; address public ...
- 一条sql 执行查询列表 返回分页数据以及总数 totalCount
SELECT ID,Name,Age,Addr,Tel,COUNT(1) OVER() AS totalFROM dbo.Student WHERE Age>22 ORDER BY id DES ...
- Centos7 安装ipython 和 ipython3
[root@localhost ~]# wget https://pypi.python.org/packages/79/63/b671fc2bf0051739e87a7478a207bbeb45cf ...
- python函数的四种参数传递方式
python中函数传递参数有四种形式 fun1(a,b,c) fun2(a=1,b=2,c=3) fun3(*args) fun4(**kargs) 四种中最常见是前两种,基本上一般点的教程都会涉及, ...
- 北京Uber优步司机奖励政策(3月21日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 转:asp.net mvc ef 性能监控调试工具 MiniProfiler
MiniProfiler官网:http://miniprofiler.com/ MiniProfiler的一个特别有用的功能是它与数据库框架的集成.除了.NET原生的 DbConnection类,Mi ...
- hive自定义函数——hive streaming
Hadoop Streaming提供了一个便于进行MapReduce编程的工具包,使用它可以基于一些可执行命令.脚本语言或其他编程语言来实现Mapper和 Reducer,Streaming方式是基于 ...
- ElasticSearch-Java-low-level-rest-client官方文档翻译
人肉翻译,非谷歌机翻,部分地方添加了个人的理解,并做了分割,如有错误请在评论指出.转载请指明原链接,尊重个人劳动成果. High-Level-Rest-Client基于Low-Level ...
- 02-JVM内存模型:虚拟机栈与本地方法栈
一.虚拟机栈(VM Stack) 1.1)什么是虚拟机栈 虚拟机栈是用于描述java方法执行的内存模型. 每个java方法在执行时,会创建一个“栈帧(stack frame)”,栈帧的结构分为“局部变 ...
- 聊聊Bug引发事故该不该追求责任
最近读极客时间朱赟的一篇文章有感,在这也聊一下,在互联网的公司大多数以迭代的方式上线需求,节奏一般都比较快,经常会一个需求当天来了第二天就上线,开发和测试时间总共就两天,中间还穿插着别的需求测试,不像 ...