四十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
倒排索引原理
就是将一句话进行分词并记录分词所存在的文章,当用户搜索词时可以直接查找到当前词所存在的文章
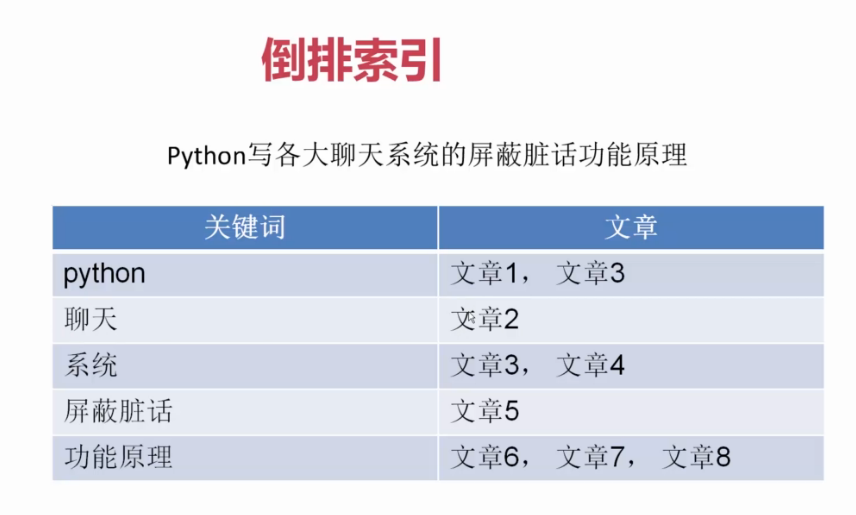
倒排索引分词权重记录(词瓶)

分词权重记录,是通过(TF-IDF)来实现的,详情https://baike.so.com/doc/433640-459181.html
倒排索引待解决的问题
这些问题elasticsearch(搜索引擎)已经解决

四十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引的更多相关文章
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
随机推荐
- python基础之类的进阶
一.__setitem__,__getitem,__delitem__ #把对象操作属性模拟成字典的格式 class Foo: def __init__(self,name): self.name=n ...
- 文件下载(StreamingHttpResponse流式输出)
文件下载(StreamingHttpResponse流式输出) HttpResponse会直接使用迭代器对象,将迭代器对象的内容存储成字符串,然后返回给客户端,同时释放内存.可以当文件变大看出这是一个 ...
- 我的Android进阶之旅------>解决Error:Unable to find method 'org.gradle.api.internal.project.ProjectInternal.g
错误描述 今天在Github上面下载了一份代码,然后导入到Android Studio中直接报了如下图所示的错误: 错误描述如下: Error: Unable to find method 'org. ...
- Android图片加载框架Picasso最全使用教程5
在之前的四篇博客中,我们学习了所有的关于Picasso的主要方法,我们也对这个Picasso有了一个很深的认识,下面就主要对Picasso自身进行分析,这样的话,会让我们更了解Picasso的核心方法 ...
- C#数组的笔记
Array.Copy的笔记: 1.将值类型的元素装箱位引用类型的元素,比如讲一个Int32[]的元素复制到Object[]中 2.将引用类型的元素拆箱为值类型的元素 3.加宽CLR基元值类型,比如讲一 ...
- Nullable类型的问题处理
public class Calc { public long? Number { get; set; } public long Number1 { get; set; } public long ...
- javaEE中的spring配置笔记
0 JavaEE的工程目录 0.1 WebContent 项目的主目录,在eclipse新建工程时可以自己命名,部署时会把该文件夹的内容发布到tomcat的webapps里. 该目录下可以建立 ...
- 利用C#查看特定服务是否安装
需求:想通过C#代码来查看IIS服务或者MSMQ是否已经安装 分析:IIS服务和MSMQ安装完成后都会创建windows服务,所以我们只需要查看对应的服务是否存在即可. 准备工作: IIS服务名称:W ...
- Nginx 301与302配置
说明 1.首先看一个完整代码示例,关于nginx 301 302跳转的. 301跳转设置: server { listen 80; server_name 123.com; rewrite ^/(.* ...
- mysql全库搜索指定字符串
mysql全库搜索指定字符串 DELIMITER // DROP PROCEDURE IF EXISTS `proc_FindStrInAllDataBase`; # CALL `proc_FindS ...