scrapy结构及各部件介绍
1.总览,数据流图:
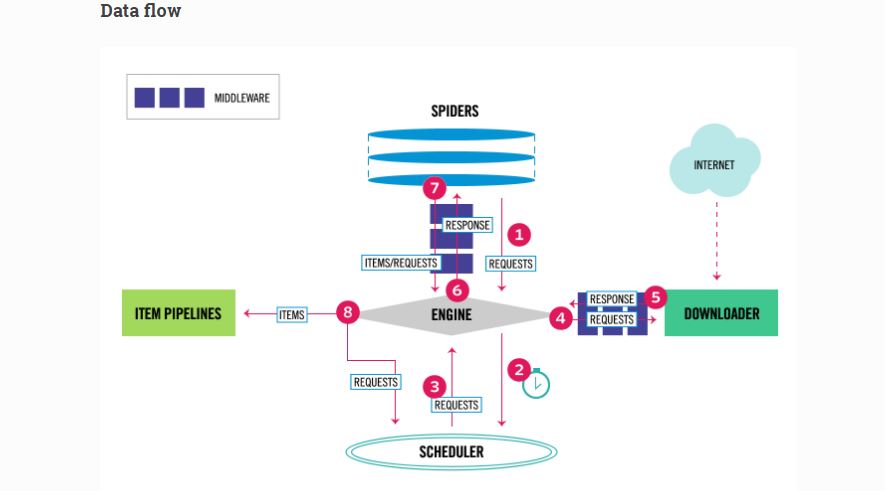
2.Engine:引擎负责控制系统所有组件之间的数据流,并在发生某些操作时触发事件。
3.Scheduler:调度程序接收来自引擎的请求,并将它们排入队列,并在之后,当Engine需要的时候,将requests发送给engine。
4.Downloader:下载器负责提取网页并将它们馈送到引擎,然后引擎将其发送给spider。
5.Spiders:蜘蛛是Scrapy用户编写的自定义类,用于解析响应并从中提取item项目(也称为抓取的项目)或追加的其他请求。详情已经在上一篇文章中介绍过了,这里就不重复了。
6.Item Pipeline:Item Pipeline负责处理被蜘蛛提取的item, 典型的任务包括清理,验证和持久性(如将项目存储在数据库中)。 这一部分在上一篇文章中也详细的介绍过了。
7.Downloader middlewares:下载器中间件是位于引擎和下载器之间的特定的钩子,当它们从引擎传递到下载器时处理请求,以及从下载器传递到引擎的响应。使用下载中间件可以达成如下的目的:
- 在将请求发送到下载器之前处理请求(即在Scrapy将请求发送到网站之前)。在传递给蜘蛛之前改变接收到的响应;在传递给蜘蛛之前改变接收到的响应;
- 发送新的请求,而不是将接收到的响应传递给蜘蛛;
- 发送新的请求,而不是将接收到的响应传递给蜘蛛;向蜘蛛传递响应而不需要获取网页;
扔掉一些请求。
使用下载中间件:
7.1 激活下载中间件:
设置:
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.CustomDownloaderMiddleware': 543,}
修改设置的方法,在上一篇博文中有详细的介绍。
住:
DOWNLOADER_MIDDLEWARES设置与在Scrapy中定义的DOWNLOADER_MIDDLEWARES_BASE设置合并(并且不意味着被覆盖),然后按顺序排序以获得最终的启用中间件的排序列表:第一个中间件是靠近引擎的第一个中间件,最后一个是一个靠近下载器。换句话说,每个中间件的process_request()方法将以增加的中间件顺序(100,200,300,...)调用,每个中间件的process_response()方法将按降序调用。
要决定分配给中间件的顺序,请参阅DOWNLOADER_MIDDLEWARES_BASE设置(在上一篇文章中有详细的介绍),并根据要插入中间件的位置选择一个值。顺序很重要,因为每个中间件都执行不同的操作,而您的中间件可能依赖于之前(或后续)正在使用的中间件。
如果要禁用内置中间件(在DOWNLOADER_MIDDLEWARES_BASE中定义并默认启用的中间件),则必须在项目的DOWNLOADER_MIDDLEWARES设置中定义它,并将None指定为其值。例如,如果您要禁用用户代理中间件:
7.2 编写自己的下载中间件:
原函数位于:class scrapy.downloadermiddlewares.DownloaderMiddleware
每一个下载中间件,都定义了以下的一个或者多个函数:
7.2.1 process_request(request, spider):
返回 None,返回一个Response对象,返回一个Request对象,或者抛出IgnoreRequest。
每一个通过下载中间件的requests请求都要经过这个函数。
如果返回值为None,则运行其他的下载中间件,直到有下载处理器可以执行这个requests请求。
如果返回一个response对象,scrapy就不会再唤醒其他的process_request()方法或者process_exception()方法,或者其他的能返回response对象的下载函数,这个response对象将在process_response()函数中被处理。
如果返回一个request对象,scrapy将停止运行process_requests()函数,调度器将重新调度新加入的request对象。
如果引发IgnoreRequest异常,则将调用已安装的下载器中间件的process_exception()方法。 如果它们都不处理异常,则调用请求(Request.errback)的errback函数。 如果没有代码处理引发的异常,它将被忽略,并且不会被记录(不像其他异常)。
| Parameters: |
|
|---|
关于request和spider对象,在上一篇文章中都有详细的介绍。
7.2.2 process_response(request, response, spider)
process_response() 返回一个 Response 对象,一个 Request 对象 ,或者升起一个IgnoreRequest异常。
如果它返回一个响应(可能是相同的响应,或者是一个全新的响应),那么响应将继续用中间件链(开头就提到了,中间件不止一个)中下一个中间件的process_response()来处理。
如果它返回一个Request对象,则中间件链将暂停,并且返回的请求将被调度器重新调度以备将来下载。 这与从process_request()返回请求的行为是一样的。
如果引发IgnoreRequest异常,则调用请求(Request.errback)的errback函数。 如果没有代码处理引发的异常,它将被忽略,并且不会被记录(不像其他异常)。
| Parameters: |
|
|---|
相应的对象都在上一篇文章中都有详细的介绍。
7.2.3 process_exception(request, exception, spider):
当下载处理程序或process_request()(来自下载中间件)引发异常(包括IgnoreRequest异常)时,Scrapy调用process_exception()
process_exception()应该返回 None,,一个 Response对象, 或者一个 Request 对象。
如果它返回None,Scrapy将继续处理这个异常,执行已安装中间件的任何其他process_exception()方法,直到所有的中间件全部被执行完,默认的异常处理开始。
如果它返回一个Response对象,则启动已安装中间件的process_response()方法链,Scrapy不会打扰其他任何中间件的process_exception()方法。
如果它返回一个Request对象,则返回的请求将被调度器重新调用以备将来下载。 这会停止执行中间件的process_exception()方法,就像返回响应一样。
| Parameters: |
|---|
接下来,我们介绍一些scrapy内置的中间件,以便利用他们编写自己的下载中间件。
7.2.4 CookiesMiddleware:
源文件位于:class scrapy.downloadermiddlewares.cookies.CookiesMiddleware
这个中间件可以处理需要cookies的网站,比如那些使用会话的网站。 它跟踪由Web服务器发送的cookie,并将其发送给(从蜘蛛)后续请求,就像浏览器一样。
以下设置(在setting.py中设置)可用于配置Cookie中间件:
COOKIES_ENABLEDCOOKIES_DEBUG
通过使用request()函数中的meta参数,可以保持每个蜘蛛的多个cookie会话。 默认情况下,它使用一个cookie jar(session),但是你可以传递一个标识符来使用不同的标识符。
例如:
for i, url in enumerate(urls):
yield scrapy.Request(url, meta={'cookiejar': i},
callback=self.parse_page)
请记住,cookiejar元键并不会与request函数绑定。 你需要继续传递下去的请求。 例如:
def parse_page(self, response):
# do some processing
return scrapy.Request("http://www.example.com/otherpage",
meta={'cookiejar': response.meta['cookiejar']},
callback=self.parse_other_page)
COOKIES_ENABLED:
默认值:True
是否启用Cookie中间件。 如果禁用,则不会将cookie发送到Web服务器。
COOKIES_DEBUG:
默认:False
如果启用,Scrapy会记录在请求中发送的所有Cookie(即Cookie头)以及在响应中收到的所有Cookie(即Set-Cookie头)。
7.2.5 DefaultHeadersMiddleware
源文件位于:
class scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware
该中间件设置在DEFAULT_REQUEST_HEADERS设置中指定的所有默认请求标头。
7.2.6 DownloadTimeoutMiddleware
源文件位于:class scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware
设置下载超时,这个中间件在setting.py中设置DOWNLOAD_TIMEOUT的值,或者设置spider属性download_timeout 的值。
注:
也可以使用download_timeout Request.meta键设置每个请求的下载超时时间; 即使在禁用了DownloadTimeoutMiddleware的情况下也是如此。
7.2.7 HttpAuthMiddleware
源文件位于:class scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware
这个中间件使用基本访问验证(又称HTTP验证)验证某些蜘蛛生成的所有请求,要启用某些蜘蛛的HTTP身份验证,要设置这些蜘蛛的http_user和http_pass属性。
例如:
from scrapy.spiders import CrawlSpider
class SomeIntranetSiteSpider(CrawlSpider):
http_user = 'someuser'
http_pass = 'somepass'
name = 'intranet.example.com'
# .. rest of the spider code omitted ...
7.2.8 HttpCacheMiddleware
源文件位于:class scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware
该中间件为所有的HTTP请求和响应提供低级缓存。 它必须与缓存存储后端以及缓存策略结合使用。
Scrapy附带三个HTTP缓存存储后端:
- Filesystem storage backend (default)
- DBM storage backend
- LevelDB storage backend
可以在setting.py中设置HTTPCACHE_STORAGE来更改HTTP缓存存储后端。 或者你也可以实现你自己的存储后端(这里就不一一介绍了,具体的内容可以查看官方文档)。
Scrapy附带两个HTTP缓存策略:
- RFC2616 policy
此策略提供符合RFC2616的HTTP缓存,即HTTP缓存控制感知,旨在连续运行,以避免下载未修改的数据(以节省带宽并加速爬网)。
策略具体如下:
不存储尝试没有 no-store cache-control 指令的响应/请求
如果设置了no-cache cache-control指令,即使是最新的响应,也不要从缓存提供响应
根据max-age cache-control计算生存周期
根据Expires响应头中计算生存周期
使用Last-Modified响应计算生存周期(Firefox使用的启发式)
根据age响应头计算当前age值
根据Date头计算当前的age值
根据Last-Modified响应头重新验证陈旧的响应
基于ETag响应头重新验证陈旧的响应
为每一个没有Date头的响应设置Date头
在requests中支持max-stale cache-control指令
这使得蜘蛛可以配置完整的RFC2616缓存策略,但是避免在逐个请求的基础上进行重新验证,同时保持与HTTP规范的一致性。
例:
添加缓存控制:max-stale = 600请求标头接受超过其过期时间不超过600秒的响应。
- Dummy policy (default)
此政策没有任何HTTP缓存控制指令的意识。 每个请求及其相应的响应都被缓存。 当再次看到相同的请求时,响应被返回而不从Internet传送任何东西。
Dummy策略对于更快速地测试蜘蛛(无需每次都等待下载)以及在Internet连接不可用时尝试离线蜘蛛非常有用。 我们的目标是能够像以前一样“重播”蜘蛛跑。
为了使用这个政策,需要设置:
HTTPCACHE_POLICY (位于scrapy.extensions.httpcache.DummyPolicy)
可以在setting.py中设置HTTPCACHE_POLICY更改HTTP缓存策略。 或者你也可以实施你自己的政策。
禁止缓存,可以将requests中的meta的dont_cache 的值设为True来实现。
7.2.9 HttpCompressionMiddleware
源文件位于:class scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware
该中间件允许从网站发送/接收压缩(gzip,deflate)流量。
如果安装了brotlipy,该中间件还支持解码brotli-compressed响应。
使用这个中间件需要在setting.py中设置COMPRESSION_ENABLED Default: True
7.2.10 HttpProxyMiddleware
源文件位于:class scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware
该中间件通过设置Request对象meta中proxy的值来设置HTTP代理以用于请求。
像Python标准库模块urllib和urllib2一样,它遵守以下环境变量:
http_proxyhttps_proxyno_proxy
您还可以将每个请求的meta.proxy设置为像http:// some_proxy_server:port或http:// username:password @ some_proxy_server:port这样的值。 请记住,该值将优先于http_proxy / https_proxy环境变量,并且也会忽略no_proxy环境变量。
HttpProxyMiddleware设置:
HTTPPROXY_ENABLED = True
HTTPPROXY_AUTH_ENCODING = 'latin-1'
在scrapy.settings.default_setting.py中为默认设置,可以在setting.py处做相应的修改,在上篇文章中有详细的描述。
7.2.11 RedirectMiddleware
源文件位于:class scrapy.downloadermiddlewares.redirect.RedirectMiddleware
这个中间件根据响应状态来处理请求的重定向。
请求经过的URL(被重定向)可以在redirect_urls Request.meta键中找到。
RedirectMiddleware可以通过以下设置进行配置(更多信息请参阅设置文档,在上篇博文中有详细的介绍):
REDIRECT_ENABLEDREDIRECT_MAX_TIMES
如果Request.meta将dont_redirect键设置为True,则该中间件将忽略该请求。
如果你想在你的蜘蛛中处理一些重定向状态码,你可以在handle_httpstatus_list spider属性中指定这些。
例如,如果你想让重定向中间件忽略301和302响应(并将它们传递给你的蜘蛛),你可以这样做:
class MySpider(CrawlSpider):
handle_httpstatus_list = [301, 302]
Request.meta的handle_httpstatus_list键也可以用来指定在每个请求的基础上允许哪些响应码。 如果想处理任何响应码的请求,可以将meta key handle_httpstatus_all设置为True。
RedirectMiddleware的设置包括:
REDIRECT_ENABLED = True
REDIRECT_MAX_TIMES = 20 # uses Firefox default setting
REDIRECT_PRIORITY_ADJUST = +2
在scrapy.settings.default_setting.py中为默认设置,可以在setting.py处做相应的修改,在上篇文章中有详细的描述。
7.2.12 MetaRefreshMiddleware
原文位于:class scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware
该中间件处理基于html标签meta-refresh的重定向请求。
MetaRefreshMiddleware可以通过以下设置在setting.py中进行配置:
METAREFRESH_ENABLEDMETAREFRESH_MAXDELAY
该中间件遵守在RedirectMiddleware中描述的requests.meta键,REDIRECT_MAX_TIMES设置,dont_redirect和redirect_urls。
MetaRefreshMiddleware的设置包括:
METAREFRESH_ENABLED = True
METAREFRESH_MAXDELAY = 100
在scrapy.settings.default_setting.py中为默认设置,可以在setting.py处做相应的修改,在上篇文章中有详细的描述。
7.2.13 RetryMiddleware
源文件位于:class scrapy.downloadermiddlewares.retry.RetryMiddleware
这个中间件用于重试可能由临时问题(如连接超时或HTTP 500错误)导致的失败请求。
一旦蜘蛛抓取所有常规(非失败)页面,抓取过程就收集失败的页面,并在最后重新安排。 一旦没有更多的失败页面重试,这个中间件发送一个信号(retry_complete),所以其他扩展可以连接到该信号。
可以通过以下设置配置RetryMiddleware:
RETRY_ENABLEDRETRY_TIMESRETRY_HTTP_CODES
如果Request.meta将dont_retry键设置为True,则该中间件将忽略该请求。
设置包括:
RETRY_ENABLED = True
RETRY_TIMES = 2 # initial response + 2 retries = 3 requests
RETRY_HTTP_CODES = [500, 502, 503, 504, 408]
RETRY_PRIORITY_ADJUST = -1
在scrapy.settings.default_setting.py中为默认设置,可以在setting.py处做相应的修改,在上篇文章中有详细的描述。
7.2.14 RobotsTxtMiddleware
源文件位于:class scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware
这个中间件使用robots.txt过滤请求。
为确保Scrapy尊重robots.txt,请确保中间件已启用且ROBOTSTXT_OBEY设置已启用。
如果Request.meta将dont_obey_robotstxt键设置为True,则即使启用ROBOTSTXT_OBEY,该中间件也会忽略该请求。
7.2.15 DownloaderStats
源文件位于:
class scrapy.downloadermiddlewares.stats.DownloaderStats
存储所有通过它的请求,响应和异常的统计信息的中间件。
要使用此中间件,您必须启用DOWNLOADER_STATS设置。
7.2.16 UserAgentMiddleware
源文件位于:class scrapy.downloadermiddlewares.useragent.UserAgentMiddleware
允许蜘蛛覆盖默认用户代理的中间件。
为了使蜘蛛覆盖默认的用户代理,必须设置其user_agent属性。
7.2.17 AjaxCrawlMiddleware
源文件位于:class scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware
这个中间件根据meta-fragment html标签查找“AJAX可抓取”的特殊页面,详情请参见https://developers.google.com/webmasters/ajax-crawling/docs/getting-started。
注:
Scrapy在没有这个中间件的情况下可以找到像“http://example.com/!#foo=bar”这样的URL的“AJAX可抓取”页面。 但是当URL不包含“!#”时,AjaxCrawlMiddleware是必需的。 这通常是“索引”或“主”网页的情况。
AjaxCrawlMiddleware 的设置:
AJAXCRAWL_ENABLED = False
在scrapy.settings.default_setting.py中为默认设置,可以在setting.py处做相应的修改,在上篇文章中有详细的描述。
通常在进行广泛抓取的时候才会使用到这个中间件。
注:
关于广泛抓取:
Scrapy的默认设置已针对特定网站进行了优化。这些网站通常由一个单一的Scrapy蜘蛛来处理,虽然这不是必需的或者是必需的(例如,有一些通用的蜘蛛可以处理任何给定的网站)。
除了这种“重点抓取”之外,还有一种常见的抓取方式,覆盖了大量(可能无限)的域名,并且只受时间或其他任意限制,而不是在域名被抓取到完成时停止,当没有更多的要求执行。这些被称为“广泛爬行”,是搜索引擎使用的典型爬虫。
这些是广泛爬行中常见的一些常见属性:
- 抓取许多域(通常是无界的)而不是一组特定的站点
- 不一定要抓取域名才能完成,因为这样做不切实际(或不可能),而是按时间或爬网页数来限制抓取
- 在逻辑上更简单(与具有许多提取规则的非常复杂的蜘蛛相反),因为数据经常在单独的阶段中被后处理
- 同时抓取许多域,这使得他们可以通过不受任何特定站点约束(每个站点缓慢爬取以尊重礼貌,但许多站点并行抓取)来实现更快的爬网速度,
如上所述,Scrapy默认设置针对重点抓取进行了优化,而不是广泛抓取。但是,由于其异步架构,Scrapy非常适合执行快速广泛爬网。官方文档总结了在使用Scrapy进行广泛搜索时需要注意的一些事项,以及Scrapy设置的具体建议,以便实现高效的全面爬网。
8. Spider Middleware(蜘蛛中间件)
蜘蛛中间件是Scrapy蜘蛛处理机制的钩子框架,您可以插入自定义功能来处理发送给蜘蛛进行处理的response,和从蜘蛛生成的request和item。
使用蜘蛛中间件:
8.1 激活:
在setting.py中设置SPIDER_MIDDLEWARES的属性为蜘蛛中间件的路径。
例如:
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
}
SPIDER_MIDDLEWARES设置与Scrapy中定义的SPIDER_MIDDLEWARES_BASE设置(并不意味着被覆盖)合并,然后按顺序排序以获得最终的启用中间件排序列表:第一个中间件是靠近引擎的中间件,最后一个是一个靠近蜘蛛。换句话说,每个中间件的process_spider_input()方法将以增加的中间件的顺序(100,200,300,...)被调用,并且每个中间件的process_spider_output()方法将按降序调用。
要决定分配给中间件的顺序,请参阅SPIDER_MIDDLEWARES_BASE设置,并根据要插入中间件的位置选择一个值。顺序很重要,因为每个中间件都执行不同的操作,而您的中间件可能依赖于之前(或后续)正在使用的中间件。
SPIDER_MIDDLEWARES_BASE:
{
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware': 800,
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
}
如果要禁用内置中间件(在SPIDER_MIDDLEWARES_BASE中定义并且在默认情况下启用的中间件),则必须在项目SPIDER_MIDDLEWARES设置中定义它,并将None指定为其值。例如,如果您要禁用OffsiteMiddleware:
SPIDER_MIDDLEWARES = {
'myproject.middlewares.CustomSpiderMiddleware': 543,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': None,
}
最后,请记住,某些中间件可能需要通过特定的设置启用。 有关更多信息,请参阅每个中间件文档。
下面将介绍一些相关的中间件,以便我们编写自己的中间件。
8.2 编写自己的蜘蛛中间件:
蜘蛛中间的原函数位于:class scrapy.spidermiddlewares.SpiderMiddleware
每个蜘蛛中间件都至少有以下函数中的一个。
process_spider_input(response, spider)
这个方法被每一个通过蜘蛛中间件进入蜘蛛的response对象唤醒,并对这些响应进行处理。
process_spider_input()的返回值为None或引发一个异常。
如果它返回None,Scrapy将执行所有其他中间件处理这个响应,直到响应被传递给蜘蛛进行处理。
如果引发异常,Scrapy其他蜘蛛中间件的process_spider_input()将不会在被唤醒,此时,唤醒request errback。errback的输出传递给process_spider_output(),或者在process_spider_exception()方法中引发异常。
| Parameters: |
|
|---|
process_spider_output(response, result, spider):
这个方法被spider处理的结果唤醒,之后处理这些从spider发来的响应。
process_spider_output()必须返回Request,dict或Item的迭代对象。
| Parameters: |
|
|---|
process_spider_exception(response, exception, spider)
这个方法被一个蜘蛛或者一个process_spider_input()的异常唤醒。
process_spider_exception()应该返回None或一个Response,dict或Item的迭代对象。
如果它返回None,Scrapy将继续处理这个异常,在下面的中间件组件中的process_spider_exception()方法,直到没有中间件组件被遗留,异常到达引擎(它被记录和丢弃的地方)。
如果它返回一个可迭代的process_spider_output()管道,并且不会调用其他process_spider_exception()。
| Parameters: |
|
|---|
process_start_requests(start_requests, spider)
这个方法是通过spider的start_request请求来调用的,除了没有关联response,并且只返回request(不是item)之外,它和process_spider_output()方法类似。
它接收一个迭代(在start_requests参数中),并且必须返回另一个可迭代的Request对象。
注:
process_start_requests()有什么用?
在spider中间件中实现这个方法时,你应该总是返回一个iterable(跟在input之后),而不是消耗所有的start_requests迭代器,因为它可能非常大(甚至是无界),这可能会导致内存溢出。 Scrapy引擎被设计为在有能力处理它们的时候提取启动请求,所以当有其他一些停止蜘蛛的条件(比如时间限制或者item / page count)的时候,start_requests迭代器就不会是没有止尽的了。
| Parameters: |
|
|---|
8.3 一些内置的蜘蛛中间件:
8.3.1 DepthMiddleware
源码位于:class scrapy.spidermiddlewares.depth.DepthMiddleware
DepthMiddleware是一个Scrapy中间件,用于跟踪站点内部每个请求的深度。 它可以用来限制最大的深度或类似的东西。
DepthMiddleware可以通过以下设置进行配置:
DEPTH_LIMIT- The maximum depth that will be allowed to crawl for any site. If zero, no limit will be imposed.DEPTH_STATS- Whether to collect depth stats.DEPTH_PRIORITY- Whether to prioritize the requests based on their depth.
默认设置位于scarpy.setting.default_setting.py,可以在setting.py中修改设置。
DEPTH_LIMIT = 0
DEPTH_STATS = True
DEPTH_PRIORITY
8.3.2 HttpErrorMiddleware
源码位于:class scrapy.spidermiddlewares.httperror.HttpErrorMiddleware
过滤掉不成功的(错误的)HTTP响应,这样蜘蛛就不必处理它们,减小开销,并使蜘蛛逻辑更加简洁。
根据HTTP标准,成功的响应是那些状态码在200-300范围内的响应。
如果您仍想处理该范围之外的响应代码,则可以使用handle_httpstatus_list spider属性或HTTPERROR_ALLOWED_CODES(但是这个我在源码中并没有找到,可能是和版本有关系)设置来指定蜘蛛能够处理的响应代码。
例如,如果你想要你的蜘蛛来处理404响应,你可以这样做:
class MySpider(CrawlSpider):
handle_httpstatus_list = [404]
Request.meta的handle_httpstatus_list关键字也可以用来指定在每个请求的基础上允许哪些响应代码。 如果您想允许请求的任何响应代码,您也可以将meta key handle_httpstatus_all设置为True。
但是请记住,除非你真的知道你在做什么,否则处理非200的回答通常是一个坏主意。
状态码详细解析:https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
8.3.3 OffsiteMiddleware
源码位于:
class scrapy.spidermiddlewares.offsite.OffsiteMiddleware
过滤蜘蛛所涉及域之外的URL请求。
这个中间件过滤出每个请求的主机名不在蜘蛛的allowed_domains属性中。allowed_domains 列表中任何域的所有子域也都是允许的。 例如。 规则www.example.org也将允许bob.www.example.org但不是www2.example.com和example.com。
当你的蜘蛛返回一个不属于蜘蛛所涉及域名的请求时,这个中间件会记录一条类似于这个的调试信息:
DEBUG: Filtered offsite request to 'www.othersite.com': <GET http://www.othersite.com/some/page.html>
为了避免在日志中填写过多的噪音,只会为每个新过滤的域打印这些消息之一。 因此,例如,如果过滤了www.othersite.com的另一个请求,则不会打印日志消息。 但是,如果过滤了someothersite.com的请求,则会打印一条消息(但仅限于过滤的第一个请求)。
如果蜘蛛没有定义allowed_domains属性,或者属性是空的,异地中间件将允许所有的请求。
如果请求具有设置的dont_filter属性,则即使其域未在允许的域中列出,OffsiteMiddleware也将允许该请求。
8.3.4 RefererMiddleware
源码位于:class scrapy.spidermiddlewares.referer.RefererMiddleware
根据生成它的Response的URL填充Request Referer头。
RefererMiddleware设置:
REFERER_ENABLED = True
REFERRER_POLICY = 'scrapy.spidermiddlewares.referer.DefaultReferrerPolicy'
默认设置位于scarpy.setting.default_setting.py,可以在setting.py中修改设置。
您还可以使用特殊的“referrer_policy” Request.meta键为每个请求设置Referrer策略,其值与REFERRER_POLICY设置相同。
REFERRER_POLICY的可接受值
要么是一个scrapy.spidermiddlewares.referer.ReferrerPolicy子类的路径 - 一个自定义策略或一个内置的策略(参见下面的类),
或者W3C定义的标准字符串值之一,
或特殊的“scrapy-default”。
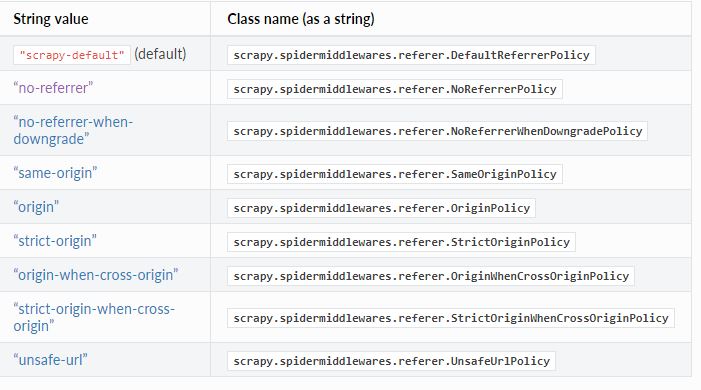
class scrapy.spidermiddlewares.referer.DefaultReferrerPolicy
“no-referrer-when-downgrade”的变体,按照no-referrer-when-downgrade策略添加refer头,但是当父请求是file:// 或者s3:// scheme是,refer请求头将不会被发送。这个策略可能会导致跨域访问,如果要保证同源策略,那么应该选用“same-origin”策略。
class scrapy.spidermiddlewares.referer.NoReferrerPolicy
最简单的策略是“NoReferrerPolicy”,它不引用任何引用信息以及从特定请求客户端向任何源发出的请求。 refer标题将被完全省略。
class scrapy.spidermiddlewares.referer.NoReferrerWhenDowngradePolicy
使用“no-referrer-when-downgrade”策略发送refer头部。
class scrapy.spidermiddlewares.referer.SameOriginPolicy
“同源”策略规定,当从特定请求客户端发出同源请求时,将剥离完整URL作为引用者信息,另一方面,跨境请求将不包含引荐来源信息。 Referer HTTP标头将不会被发送。
class scrapy.spidermiddlewares.referer.OriginPolicy
“OriginPolicy”策略规定,当从特定的请求客户端发出同源请求和跨源请求时,只有请求客户端源的ASCII序列被作为引用者信息发送。
class scrapy.spidermiddlewares.referer.StrictOriginPolicy
"StrictOriginPolicy”策略在发出请求时发送请求客户端的来源的ASCII序列:
从受TLS保护的环境设置对象到可能可信的URL,以及
从非TLS保护的环境设置对象到任何来源。
另一方面,从受TLS保护的请求客户端请求非潜在可信的URL将不包含引荐者信息。 Referer HTTP标头将不会被发送。
class scrapy.spidermiddlewares.referer.OriginWhenCrossOriginPolicy
仅在发生跨域访问时发送只包含 host 的 Referrer,同域下还是完整的。它与 Origin Only 的区别是多判断了是否 Cross-origin。需要注意的是协议、域名和端口都一致,才会被浏览器认为是同域;
class scrapy.spidermiddlewares.referer.StrictOriginWhenCrossOriginPolicy
“strict-origin-when-cross-origin”策略规定,当从特定的请求客户端发出同源请求时,剥离用作引用者的完整URL作为引用者信息发送,并且只有 请求客户端进行跨域请求时的来源:
从受TLS保护的环境设置对象到可能可信的URL,以及
从非TLS保护的环境设置对象到任何来源。
另一方面,来自受TLS保护的客户端请求不可信的URL将不包含引荐者信息。 Referer HTTP标头将不会被发送。
class scrapy.spidermiddlewares.referer.UnsafeUrlPolicy
无论是否发生协议降级,无论是本站链接还是站外链接,统统都发送 Referrer 信息。正如其名,这是最宽松而最不安全的策略;
策略参考链接:
https://www.w3.org/TR/referrer-policy
https://imququ.com/post/referrer-policy.html
8.3.5 UrlLengthMiddleware
class scrapy.spidermiddlewares.urllength.UrlLengthMiddleware
过滤URL长度大于URLLENGTH_LIMIT的请求
UrlLengthMiddleware可以通过以下设置进行配置(更多信息请参阅上一篇博文):
URLLENGTH_LIMIT - 允许抓取的网址的最大网址长度。
9. Extensions
扩展框架提供了一种将您自己的自定义功能插入Scrapy的机制。
扩展只是在扩展初始化时在Scrapy启动时实例化的常规类。
9.1 Extensions设置
扩展程序使用Scrapy setting.py来管理其设置,就像任何其他Scrapy代码一样。
扩展名习惯是以自己的名字为前缀设置,以避免与现有的(和将来的)扩展名相冲突。 例如,处理Google Sitemaps的假设性扩展将使用像GOOGLESITEMAP_ENABLED,GOOGLESITEMAP_DEPTH等设置。
9.2 导入并激活拓展功能
实例化:
扩展在启动时通过实例化扩展类的单个实例来加载和激活。 因此,所有的扩展初始化代码都必须在类构造函数(__init__方法)中执行。
激活:
在setting.py中添加EXTENSIONS的路径,例如:
EXTENSIONS = {
'scrapy.extensions.corestats.CoreStats': 500,
'scrapy.extensions.telnet.TelnetConsole': 500,
}
EXTENSIONS_BASE是默认的拓展:
{
'scrapy.extensions.corestats.CoreStats': 0,
'scrapy.extensions.telnet.TelnetConsole': 0,
'scrapy.extensions.memusage.MemoryUsage': 0,
'scrapy.extensions.memdebug.MemoryDebugger': 0,
'scrapy.extensions.closespider.CloseSpider': 0,
'scrapy.extensions.feedexport.FeedExporter': 0,
'scrapy.extensions.logstats.LogStats': 0,
'scrapy.extensions.spiderstate.SpiderState': 0,
'scrapy.extensions.throttle.AutoThrottle': 0,
}
不同的拓展通常是不相干的,所有,顺序值都为0,如果要添加相互关联的拓展,则需要更改顺序值。
如果要禁用拓展,则在extensions中将相关的拓展的顺序值设为:None。
9.3 编写自己的拓展:
这里我们将实现一个简单的扩展来说明上一节中描述的概念。 这个扩展将每次记录一条消息:
- 一只蜘蛛被打开
- 一只蜘蛛被关闭
- 特定数量的项目被刮掉
该extensions将通过MYEXT_ENABLED设置启用,项目数将通过MYEXT_ITEMCOUNT设置指定。
这里是这种扩展的代码:
import logging
from scrapy import signals
from scrapy.exceptions import NotConfigured logger = logging.getLogger(__name__) class SpiderOpenCloseLogging(object): def __init__(self, item_count):
self.item_count = item_count
self.items_scraped = 0 @classmethod
def from_crawler(cls, crawler):
# first check if the extension should be enabled and raise
# NotConfigured otherwise
if not crawler.settings.getbool('MYEXT_ENABLED'):
raise NotConfigured # get the number of items from settings
item_count = crawler.settings.getint('MYEXT_ITEMCOUNT', 1000) # instantiate the extension object
ext = cls(item_count) # connect the extension object to signals
crawler.signals.connect(ext.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(ext.spider_closed, signal=signals.spider_closed)
crawler.signals.connect(ext.item_scraped, signal=signals.item_scraped) # return the extension object
return ext def spider_opened(self, spider):
logger.info("opened spider %s", spider.name) def spider_closed(self, spider):
logger.info("closed spider %s", spider.name) def item_scraped(self, item, spider):
self.items_scraped += 1
if self.items_scraped % self.item_count == 0:
logger.info("scraped %d items", self.items_scraped)
9.4 内置的拓展:
9.4.1 Log Stats extension
源码位于:class scrapy.extensions.logstats.LogStats
记录抓取的页面和抓取的items等基本统计信息。
9.4.2 Core Stats extension
源码位于:class scrapy.extensions.corestats.CoreStats
核心信息收集
9.4.3 Memory usage extension
源码位于:class scrapy.extensions.memusage.MemoryUsage
注:这个拓展在windows下是不能工作的。
监控在scrapy使用期间内核的使用情况。
相关的设置有:
MEMUSAGE_ENABLED = True
MEMUSAGE_LIMIT_MB = 0
MEMUSAGE_NOTIFY_MAIL = []
MEMUSAGE_WARNING_MB = 0
9.4.4 Memory debugger extension
源码位于:class scrapy.extensions.memdebug.MemoryDebugger
调试内存使用的扩展。 它收集有关以下信息:
- Python垃圾收集器未收集的对象
- 不应该活着的对象。 有关更多信息,请参阅使用trackref调试内存泄漏
要启用此扩展,请打开MEMDEBUG_ENABLED设置。 信息将被存储在stats中。
9.4.5 Close spider extension
源码位于:class scrapy.extensions.closespider.CloseSpider
当满足一些条件时自动关闭蜘蛛,对每个条件使用特定的关闭原因。
关闭蜘蛛的条件可以通过以下设置进行配置:
CLOSESPIDER_TIMEOUTCLOSESPIDER_ITEMCOUNTCLOSESPIDER_PAGECOUNTCLOSESPIDER_ERRORCOUNT
默认是:
CLOSESPIDER_TIMEOUT = 0
CLOSESPIDER_PAGECOUNT = 0
CLOSESPIDER_ITEMCOUNT = 0
CLOSESPIDER_ERRORCOUNT = 0
9.4.5 StatsMailer extension
源码位于:class scrapy.extensions.statsmailer.StatsMailer
这个简单的扩展可以用来发送一个通知电子邮件,每当一个域名已经完成,包括Scrapy统计收集。 电子邮件将发送给STATSMAILER_RCPTS设置中指定的所有收件人。
9.4.6 Debugging extensions
堆栈跟踪转储扩展Stack trace dump extension
源码位于:class scrapy.extensions.debug.StackTraceDump
9.4.7 Debugger extension
源码位于:class scrapy.extensions.debug.Debugger
在收到SIGUSR2信号时,在正在运行的Scrapy进程中调用Python调试器。 调试器退出后,Scrapy进程继续正常运行。
此扩展只适用于POSIX兼容的平台(即不是Windows)。
10.1.1 class scrapy.crawler.Crawler(spidercls, settings)
这个类必须实例化scrapy.spiders.Spider子类和scrapy.settings.Settings对象。通过from_crawler类方法传递给extension,访问crawler对象的主要接口。
属性包括:
self.extensions = ExtensionManager.from_crawler(self)
self.settings.freeze()
self.crawling = False
self.spider = None
self.engine = None
self.signals = SignalManager(self)
self.stats = load_object(self.settings['STATS_CLASS'])(self)
等等。
其中:
settings:
此抓取工具的设置管理器。
这被扩展和中间件用来访问这个爬虫的Scrapy设置。
有关Scrapy设置的介绍,请参阅上一篇博文。
有关API,请阅读下文setting的接口。
signals:
这个爬虫的信号管理器。
这是由扩展和中间件使用Scrapy功能。
有关信号的介绍,请参阅Signals。
有关API,请参阅下文的SignalManager类。
stats:
此抓取工具的统计信息收集器。
这用于扩展和中间件来记录其行为的统计信息,或访问由其他扩展收集的统计信息。
有关统计信息收集的介绍,请参阅统计信息收集。
有关API,请参阅下文StatsCollector类。
engine:
执行引擎,协调调度程序,下载程序和蜘蛛之间的核心爬行逻辑。
某些扩展可能需要访问Scrapy引擎,以检查或修改下载程序和调度程序的行为,尽管这是一种高级用法,并且此API尚不稳定。
spider:
蜘蛛目前正在爬行。 这是构建爬网程序时提供的spider类的一个实例,它是在crawl()方法中给出的参数之后创建的。
crawl(*args, **kwargs):
通过使用给定的args和kwargs参数实例化其spider类,启动爬网程序,同时将执行引擎设置为运动。
返回爬网完成时触发的延迟。
10.1.2 class scrapy.crawler.CrawlerRunner(settings=None):
这是一个方便的助手类,可以跟踪,管理和运行已经设置好的Twisted反应堆内的抓取程序。
CrawlerRunner对象必须用一个Settings对象来实例化。
除非编写手动处理爬网过程的脚本,否则不应该需要该类(因为Scrapy负责相应使用它)。 有关示例,请参阅从脚本运行Scrapy。
crawl(crawler_or_spidercls, *args, **kwargs):
使用提供的参数运行爬网程序。
它会调用给定的Crawler的crawl()方法,同时跟踪它,以便稍后停止。
如果crawler_or_spidercls不是Crawler实例,则此方法将尝试使用此参数创建一个使用当前参数的spider类。
返回爬网完成时触发的延迟。
| Parameters: |
|
|---|
crawlers:
建立一个 从crawl() 启动的crawlers类,并管理这个类。
create_crawler(crawler_or_spidercls):
返回一个 Crawler 对象
- 如果crawler_or_spidercls是一个crawler,它将按原样返回。
- 如果crawler_or_spidercls是一个Spider子类,则为其构建一个新的Crawler。
- 如果crawler_or_spidercls是一个字符串,则该函数在Scrapy项目(使用spider loader)中找到具有该名称的spider,然后为其创建一个Crawler实例。
join():
返回所有爬虫执行完成后的延迟。
stop():
同时停止所有正在进行的抓取工作。
当它们全部结束时,返回一个延迟
10.1.3 class scrapy.crawler.CrawlerProcess(settings=None):
基于上文提到的scrapy.crawler.CrawlerRunner类,
在一个进程中同时运行多个scrapy爬虫的类。
这个类扩展了CrawlerRunner,增加了对启动Twisted reactor和处理关闭信号的支持,比如键盘中断命令Ctrl-C。 它还配置顶级日志记录。
如果你没有在应用程序中运行另一个Twisted reactor,这个工具应该比CrawlerRunner更好。
CrawlerProcess对象必须用一个Settings对象实例化。
除非编写手动处理爬网过程的脚本,否则不应该需要该类(因为Scrapy负责相应使用它)。 有关示例,请参阅从脚本运行Scrapy。
函数基本与CrawlerRunner()类相同,但增加了start(stop_after_crawl=True)函数,、
start(stop_after_crawl=True):
此方法启动Twisted reactor,将其池大小调整为REACTOR_THREADPOOL_MAXSIZE,并根据DNSCACHE_ENABLED和DNSCACHE_SIZE安装DNS缓存。
如果stop_after_crawl为True,那么使用join()将在所有爬虫完成后停止反应堆。
参数:stop_after_crawl(boolean) - 当所有的抓取程序完成时,停止或禁止反应堆。
10.2 Settings API
10.2.1 scrapy.settings.SETTINGS_PRIORITIES
源码位于:scrapy.setting.__init__,py
默认值为:
SETTINGS_PRIORITIES = {
'default': 0,
'command': 10,
'project': 20,
'spider': 30,
'cmdline': 40,
}
设置Scrapy中使用的默认设置优先级的键名和优先级的字典。
每个item定义一个设置入口点,给它一个用于识别的代码名称和一个整数优先级。优先值越大,在程序执行时优先级越高。
scrapy.settings.get_settings_priority(priority):
源码位于:scrapy.__init__py
在SETTINGS_PRIORITIES字典中查找给定的字符串优先级并返回其数字值,或者直接返回给定的数字优先级。
class scrapy.settings.Settings(values=None, priority='project'):
源码位于:scrapy.__init__py
是BaseSettings的子类。
此对象存储Scrapy设置,用于配置内部组件,并可用于任何进一步的自定义。
它是一个直接的子类,支持BaseSettings的所有方法,另外,在实例化之后,实例化对象在scrapy中内置的设置将被填充到这个插件中(extension或middleware)。
class scrapy.settings.BaseSettings(values=None, priority='project'):
源码位于:scrapy.__init__py
这个类的实例像字典一样,但是存储了它们的(键,值)对的优先级,并且可以被冻结(即被标记为不可变)。
在实例化的时候可以通过attributes设置属性,如果优先级是字符串的话,那么将在SETTINGS_PRIORITIES中查找优先级名称。 否则,应该提供一个特定的整数。
创建对象后,可以使用set()方法加载或更新新设置,并且可以使用字典的方括号表示法或实例的get()方法及其值转换变体来访问。 当请求存储的key时,将检索具有最高优先级的值。
copy()方法:
进行当前设置的深层复制。
此方法返回Settings类的新实例,并使用相同的值和优先级填充。
对新对象的修改不会反映在原始设置上。
copy_to_dict():
复制当前设置并转换为字典。
这个方法返回一个新的字典,其中填入了与当前设置相同的值和优先级。
对返回的字典的修改不会反映在原始设置上。
此方法可用于在Scrapy shell中打印设置。
freeze():
禁用对当前设置的进一步更改。
调用此方法后,设置的当前状态将变为不可变。 尝试通过set()方法及其变体更改值将不可能,并将被警告。
frozencopy():、
copy()返回对象的freeze()方法的别称(copy后的设置不能被改变)。
get(name, default=None):
获取设置值,不影响其原始类型。
Parameters:
- name (string) – the setting name
- default (any) – the value to return if no setting is found
getbool(name, default=False):
获取一个布尔值的设置值。
1,'1',True'和'True'返回True,0,'0',False,'False'和None返回False。
例如,使用此方法时,通过设置为“0”的环境变量填充的设置将返回False。
Parameters:
- name (string) – the setting name
- default (any) – the value to return if no setting is found
getdict(name, default=None):
获取设置值作为字典。 如果设置原始类型是一个字典,它的副本将被返回。 如果它是一个字符串,它将被评估为一个JSON字典。 如果它是一个BaseSettings实例本身,它将被转换为一个字典,包含它所有的当前设置值,就像get()所返回的那样,但是会丢失关于优先级和可变性的所有信息。
Parameters:
- name (string) – the setting name
- default (any) – the value to return if no setting is found
getfloat(name, default=0.0):
获取setting的值,以float的形式表示。
| Parameters: |
|
|---|
getint(name, default=0):
以一个整数的形式获取setting的值。
| Parameters: |
|
|---|
getlist(name, default=None):
获取设置值作为列表。 如果设置原始类型是一个列表,它的副本将被返回。 如果它是一个字符串,它将被“,”拆分。
例如,使用此方法时,通过设置为“one,two”的环境变量填充的设置将返回列表['one','two']。
Parameters:
- name (string) – the setting name
- default (any) – the value to return if no setting is found
getpriority(name):
返回name的当前数字优先级值,如果给定name不存在,则返回None。
Parameters:name (string) – the setting name
getwithbase(name):
获取类似字典的设置和_BASE对应的组合。
| Parameters: | name (string) – name of the dictionary-like setting |
|---|
maxpriority():
返回所有设置中出现的最高优先级的数值,如果没有存储设置,则返回来自SETTINGS_PRIORITIES的默认数值。
set(name, value, priority='project'):
存储具有给定优先级的键/值属性。
在配置Crawler对象之前(通过configure()方法)调用set()填充设置,否则它们不会有任何影响。
| Parameters: |
|
|---|
setmodule(module, priority='project'):
以一个模块的方式存储设置。
这是一个帮助函数,它为每个具有优先级的设置的模块声明一个大写的全局变量,供set()f方法调用。
| Parameters: |
|
|---|
update(values, priority='project'):
存储具有给定优先级的键/值对。
这是一个帮助函数,它为每个具有提供的优先级的值项调用set()。
如果values是一个字符串,则假定它是JSON编码的,并且先用json.loads()解析成字典。 如果它是一个BaseSettings实例,则将使用每个按键优先级并忽略优先级参数。 这允许用单个命令插入/更新具有不同优先级的设置。
| Parameters: |
|
|---|
10.3 SpiderLoader API
class scrapy.loader.SpiderLoader
源码位于:scrapy.loader.__init__.py
这个类负责检索和处理整个项目中定义的蜘蛛类。
可以通过在SPIDER_LOADER_CLASS项目设置中指定它们的路径来使用自定义蜘蛛加载器。 他们必须完全实现scrapy.interfaces.ISpiderLoader接口来保证无误的执行。
from_settings(settings):
Scrapy使用这个类方法来创建类的一个实例。 这个方法由当前的项目的设置调用,它将SPIDER_MODULES设置的蜘蛛递归的调用。
Parameters:settings (Settings instance) – project settings
load(spider_name):
获取给定名称的蜘蛛类。 它会查看加载的名为spider_name的蜘蛛类的蜘蛛,如果找不到,将引发一个KeyError。
Parameters:spider_name (str) – spider class name
list():
获取项目中可用蜘蛛的名称。
find_by_request(request):
列出可以处理给定请求的蜘蛛的名字。 将尝试匹配请求的网址与蜘蛛的域名。
Parameters:request (Request instance) – queried request
10.4 Signals API
Scrapy广泛使用信号来通知特定事件发生的时间。 您可以捕捉Scrapy项目中的一些信号(例如,使用扩展)来执行其他任务或扩展。
class scrapy.signalmanager.SignalManager(sender=_Anonymous)
connect(receiver, signal, **kwargs):
将接收器功能连接到信号。
该信号可以是任何对象,Scrapy带有一些预定义的信号,记录在signals。
Parameters:
- receiver (callable) – the function to be connected
- signal (object) – the signal to connect to
disconnect(receiver, signal, **kwargs):
从信号中断开接收器功能。 这与connect()方法有相反的作用,参数是相同的。
disconnect_all(signal, **kwargs):
断开所以的接收器
| Parameters: | signal (object) – the signal to disconnect from |
|---|
send_catch_log(signal, **kwargs):
发送一个信号,捕捉异常并记录下来。
关键字参数传递给信号处理程序(通过connect()方法连接)。
send_catch_log_deferred(signal, **kwargs):
像send_catch_log(),但支持从信号处理程序返回延迟。
返回所有信号处理程序延迟后被触发的延迟。 发送一个信号,捕捉异常并记录下来。
关键字参数传递给信号处理程序(通过connect()方法连接)。
10.5 Stats Collector API
scrapy.statscollectors模块下有几个Stats Collector,它们都实现StatsCollector类定义的Stats Collector API(它们都是继承的)。
class scrapy.statscollectors.StatsCollector:
get_value(key,default = None)
返回给定统计键的值,如果不存在,则返回默认值。
get_stats()
从当前正在运行的蜘蛛获取所有统计作为字典。
set_value(key,value)
为给定的统计信息键设置给定的值。
set_stats(stats)
用stats参数中传递的字典覆盖当前的统计信息。
inc_value(key,count = 1,start = 0)
假定给定的起始值(未设置时),按给定的计数递增给定统计密钥的值。
max_value(key,value)
只有在同一个键的当前值小于值的情况下,才能为给定键设置给定值。如果给定键没有当前值,则始终设置该值。
min_value(key,value)
只有当同一个键的当前值大于值时,才为给定的键设定给定的值。如果给定键没有当前值,则始终设置该值。
clear_stats()
清除所有统计信息。
以下方法不是统计信息收集API的一部分,而是在实现自定义统计信息收集器时使用:
open_spider(spider)
打开给定的蜘蛛的统计收集。
close_spider(spider)
关闭给定的蜘蛛。在此之后,不能访问或收集更具体的统计数据。
scrapy结构及各部件介绍的更多相关文章
- linux下各文件夹的结构说明及用途介绍
linux下各文件夹的结构说明及用途介绍: /bin:二进制可执行命令. /dev:设备特殊文件. /etc:系统管理和配置文件. /etc/rc.d:启动的配 置文件和脚本. /ho ...
- 【转】linux下各文件夹的结构说明及用途介绍
linux下各文件夹的结构说明及用途介绍: /bin:二进制可执行命令. /dev:设备特殊文件. /etc:系统管理和配置文件. /etc/rc.d:启动的配 置文件和脚本. /home:用户主目录 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- Linux下各文件夹的结构说明及用途介绍(转载)
linux下各文件夹的结构说明及用途介绍: /bin:二进制可执行命令. /dev:设备特殊文件. /etc:系统管理和配置文件. /etc/rc.d:启动的配 置文件和脚本. /home:用户主目录 ...
- linux下各文件夹的结构说明及用途介绍:Linux目录结构介绍
linux下各文件夹的结构说明及用途介绍: /bin:二进制可执行命令. /dev:设备特殊文件. /etc:系统管理和配置文件. /etc/rc.d:启动的配 置文件和脚本. /home:用户主目录 ...
- 043 01 Android 零基础入门 01 Java基础语法 05 Java流程控制之循环结构 05 do-while循环介绍及应用
043 01 Android 零基础入门 01 Java基础语法 05 Java流程控制之循环结构 05 do-while循环介绍及应用 本文知识点:do-while循环介绍及应用 do-while循 ...
- SharePoint 内容编辑器部件介绍
前言 在SharePoint的使用过程中,我们经常会往页面中插入一些东西,这时候很可能就需要内容编辑器部件了.比如:插HTML.插样式.插脚本.插图片,统统都拿来,用内容编辑器部件. 正文 使用内容编 ...
- python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程 在pycharm中打开此工程目录:并在Run中选择Edit Configuration 点击+创建一个Pytho ...
- ffmpeg结构体以及函数介绍(一)
本文对在使用ffmpeg进行音视频编解码时使用到的一些函数做一个简单介绍,我当前使用的ffmpeg版本为:0.8.5,因为本人发现在不同的版本中,有些函数名称会有点小改动,所以在此有必要说明下ffmp ...
随机推荐
- 48dp rhythm
- Keras网络层之常用层Core
常用层 常用层对应于core模块,core内部定义了一系列常用的网络层,包括全连接.激活层等 Dense层 keras.layers.core.Dense(units, activation=None ...
- 编译原理课后习题答案令A,B和C是任意正规式,证明以下关系成立(A|B)*=(A*B*)*=(A*|B*)*
题目: 令A.B和C是任意正规式,证明以下关系成立: A∣A=A (A*)*= A* A*=ε∣A A* (AB)*A=A(BA)* (A∣B)*=(A*B ...
- effective C++ 条款25 swap
item 25:一个不抛异常的swap函数 标准库有一个swap用于交换两个对象值 namespace std{ template<typename T> void swap(T& ...
- java反射基础知识(四)反射应用实践
反射基础 p.s: 本文需要读者对反射机制的API有一定程度的了解,如果之前没有接触过的话,建议先看一下官方文档的Quick Start. 在应用反射机制之前,首先我们先来看一下如何获取一个对象对应的 ...
- 基本数据类型(Day4)
一 什么是数据? eg:x=10 则10是要存储的数据 二 为什么数据要分不同的类型? 数据是用来表示不同状态的,当然不同的状态可以用不同的数据表示 三 数据类型 1.数字(整型,长整型 ,浮 ...
- image_Magic图片处理功能
:] 来自为知笔记(Wiz)
- 笔记1:Jmeter工作原理及目录结构
1.基本工作原理 发送request请求到服务器——获取目标服务的统计信息——生成不同格式的报告 2.完整的工作原理 Jmeter模拟用户并发进行性能测试——发送request到目标服务器——服务器返 ...
- 【leetcode刷题笔记】Find Peak Element
A peak element is an element that is greater than its neighbors. Given an input array where num[i] ≠ ...
- MMU解读
转:https://blog.csdn.net/yueqian_scut/article/details/24816757 mmu页表也是放在内存中,mmu里有一个寄存器存放页表首地址,从而找到页表( ...