使用Stanford Parser进行句法分析
一、句法分析
1、定义
句法分析判断输入的单词序列(一般为句子)的构成是否合乎给定的语法,并通过构造句法树来确定句子的结构以及各层次句法成分之间的关系,即确定一个句子中的哪些词构成一个短语,哪些词是动词的主语或宾语等问题。
2、主流技术
基于统计的方法是现阶段句法分析的主流技术。常见的概率句法分析模型包括概率上下文无关模型、基于历史的句法分析模型、层次化渐进式的句法分析模型和中心词驱动的句法分析模型。综合多种模型而实现的句法分析器种类繁多,目前在开源中文句法分析器中比较具有代表性有Stanford parser和 Berkeley parser。前者基于因子模型,后者基于非词汇化分析模型。
3、应用领域
随着自然语言应用的日益广泛,特别是对文本处理需求的进一步增加,句法分析的作用愈加突出,它在机器翻译、信息检索与抽取、问答系统、语音识别等研究领域中都有重要的应用价值。
二、Stanford Parser
1、简介
Stanford parser 是由斯坦福大学自然语言处理小组开发的开源句法分析器,是基于概率统计句法分析的一个 JAVA 实现。 分析器目前提供了5个中文文法。
2、优点
①既是一个高度优化的概率上下文无关文法和词汇化依存分析器,也是一个词汇化上下文无关文法分析器。
②基于权威可靠的宾州树库(Penn Treebank)作为分析器的训练数据,目前已面向英文、中文、德文、阿拉伯文、意大利文、保加利亚文、葡萄牙文等语种提供句法分析功能。
③提供了多样化的分析输出形式,除句法分析树输出外,还支持分词和词性标注文本输出、短语结构树输出、斯坦福依存关系输出等。
④分析器内置了分词工具、词性标注工具、基于自定义树库的分析器训练工具等句法分析辅助程序。
⑤通过设置不同的运行参数,可实现句法分析模型选择、自定义词性标记集、文本编码设置和转换、语法关系导入和导出等功能的定制。
三、使用Stanford Parser教程
(一)IDE中运行
1. 在Stanford官方网站下载最新安装包
http://nlp.stanford.edu/software/lex-parser.html#Download

2. 解压下载后的zip包 stanford-parser-full-2015-12-09.zip,里面会有数据,依赖包以及demo,还有相关的source code和java doc
3. 使用Eclipse创建项目,名为stanfordparser,在build path中引入stanford-parser-3.6.0-models.jar,stanford-parser.jar,slf4j-simple.jar, slf4j-api.jar
4.从步骤2中解压的文件中把ParserDemo.java和ParserDemo2.java和data文件夹都复制到Eclipse项目中。
5. 以ParserDemo.java为例,在Eclipse中右键点击ParserDemo.java文件,设置运行参数Arguments为:
edu/stanford/nlp/models/lexparser/englishPCFG.ser.gz data/english-onesent.txt
(注意gz和data之间有个空格,空格前是第一个参数,空格后是第二个参数。)
第一个参数是PCFG路径,models里已经提供,第二个参数是待分析的数据文件,在data文件夹中。
6.运行,输出的结果为:
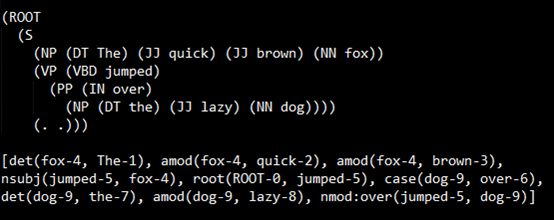
(二)命令行中运行
在已解压的stanford-parser-full-2015-12-09文件夹中,找到lexparser.bat文件。在命令窗口中运行这个文件,得到如下结果,即为命令行运行结果。

(三)可视化界面查看句法分析结果
1.在已解压的stanford-parser-full-2015-12-09文件夹中,找到lexparser-gui.bat文件。在命令窗口中运行这个文件,得到如下可视化界面。
2.点击Load File选择要进行句法分析的语料文件。点击Load Parser选择model文件,解析器选择英文。最后点击Parser>即可生成解析树。

上图用了stanford-parser-3.6.0-models.jar的model文件,用了english-onesent.txt作为要句法分析的语料文件。

上图用了stanford-chinese-corenlp-2016-01-19-models.jar的model文件,用了chinese-onesent-utf8.txt作为要句法分析的语料文件。
四、使用Stanford Parser的实例分析
Example :分词&词性标注、句法分析树、依存句法分析
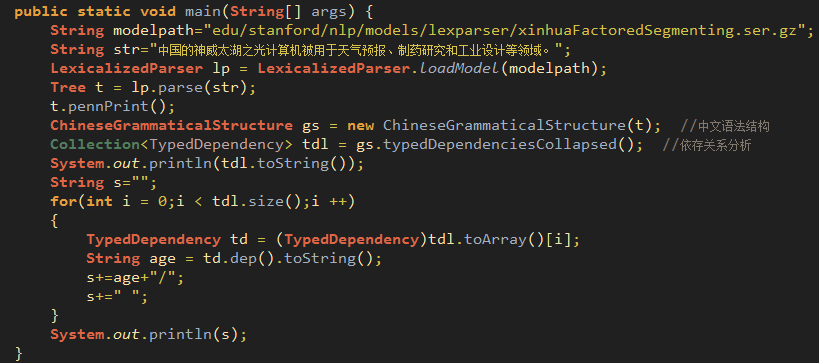
1、先贴全部代码
2、分析的句子
“中国的神威太湖之光计算机被用于天气预报、制药研究和工业设计等领域。”
3、运行结果
①分词并词性标注结果:

②句法分析树结果:

③依存句法分析结果:

4、代码分析
① 
定义modelpath用来存放模型文件。中文处理方面的模型文件有:chineseFactored.ser.gz、chinesePCFG.ser.gz、xinhuaFactored.ser.gz、xinhuaFactoredSegmenting.ser.gz、xinhuaPCFG.ser.gz等。其中factored包含词汇化信息,PCFG是更快更小的模板,xinhua是根据大陆的《新华日报》训练的语料,而chinese同时包含香港和台湾的语料,本程序使用的xinhuaFactoredSegmenting.ser.gz可以对未分词的句子进行句法解析。
② 
初始化用于句法分析的类LexicalizedParser,函数loadModel 加载模型文件。
③ 
调用ParserGrammar.class里的parse函数,该函数调用tokenize解析函数:首先初始化treebankLanguageBank抽象类的getTokenizerFactory方法,生成解析器tokenizer,将句子分词并进行词性标注,结果放在tokens然后返回。
④ 
调用Tree.class里的pennPrint方法打印句法分析树。
⑤ 
实例化ChineseGrammaticalStructure类。调用GrammaticalStructure类的typedDependenciesCollapsed函数,它会调用typedDependencies方法对句子进行依存句法分析。
例如:调试过程中,运行typedDependencies方法对句子进行依存句法分析中,过程变量elementData的第10个数据正在分析句子中“制药研究”的依赖关系,调试结果如下:
- “制药研究”的支配词(governor)是“研究”,词性是“NN”,即下图的gov-label-values[3]&[4]
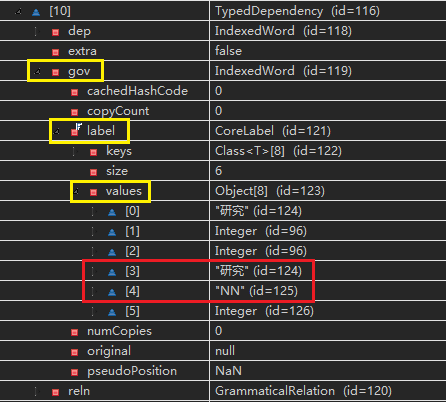
- “制药研究”的从属词(dependent)是“制药”,词性是“NN”,即下图的dep-label-values[3]&[4]

- “制药研究”的依存关系(reln)是“nn(名词组合形式)”,即下图的reln-shortName
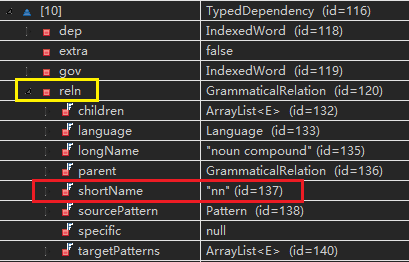
调试结果分析结束。
⑥ 
输出句子的词性标注结果。
参考资料
【1】《大规模语料库上的Stanford和Berkeley句法分析器性能对比分析》项炜,金澎;文献编号1009-3044(2013)08-1984-03
【2】Stanford Parser中标记的中文释义参考-《Stanford Parser学习入门(3)-标记》-http://www.cnblogs.com/csts/p/5445719.html
参考文件
使用Stanford Parser进行句法分析的更多相关文章
- 使用Berkeley Parser进行句法分析
一.句法分析 1.定义 句法分析判断输入的单词序列(一般为句子)的构成是否合乎给定的语法,并通过构造句法树来确定句子的结构以及各层次句法成分之间的关系,即确定一个句子中的哪些词构成一个短语,哪些词是动 ...
- 同时使用Twitter nlp 和stanford parser的解决方法
因为Twitter nlp中使用了较老版本的stanford parser,导致不能同时使用 解决方法是使用未集成其它jar包的Twitter nlp,关于这点Stanford FAQ中也有说明(在F ...
- Stanford parser:入门使用
一.stanford parser是什么? stanford parser是stanford nlp小组提供的一系列工具之一,能够用来完成语法分析任务.支持英文.中文.德文.法文.阿拉伯文等多种语言. ...
- Stanford Parser学习入门(3)-标记
以下是Stanford parser中的标记中文释义供参考. probabilistic context-free grammar(PCFG) ROOT:要处理文本的语句 IP:简单从句 NP ...
- Stanford Parser学习入门(2)-命令行运行
在Stanford parser目录中已经定义了一部分命令行工具以及图形界面,本文将介绍如何在windows使用这些工具进行语法分析,Linux下也有shell可以使用. 关于如何搭建环境请参考上一篇 ...
- Stanford Parser学习入门(1)-Eclipse中配置
Stanford Parser是斯坦福大学研发的用于语法分析的工具,属于stanford nlp系列工具之一.本文主要介绍Standfor Parser的入门用法. 在Stanford官方网站下载最新 ...
- Stanford parser学习:LexicalizedParser类分析
上次(http://www.cnblogs.com/stGeekpower/p/3457746.html)主要是对应于javadoc写了下LexicalizedParser类main函数的功能,这次看 ...
- 在 NLTK 中使用 Stanford NLP 工具包
转载自:http://www.zmonster.me/2016/06/08/use-stanford-nlp-package-in-nltk.html 目录 NLTK 与 Stanford NLP 安 ...
- Python自然语言处理工具小结
Python自然语言处理工具小结 作者:白宁超 2016年11月21日21:45:26 目录 [Python NLP]干货!详述Python NLTK下如何使用stanford NLP工具包(1) [ ...
随机推荐
- Win7下 OpenCV+Qt开发环境搭建
1.所需软件工具: (1)OpenCV开发库,2.4.9版:包括源文件(source文件夹)和编译后的文件(build文件夹),但最好自己使用CMake又一次编译.否则easy出错. (2)Qt Cr ...
- 【Android Studio】之构建项目报错
问题1: 报错: Could not download fastutil.jar (it.unimi.dsi:fastutil:7.2.0): No cached version available ...
- MVC模式中M,V,C每个代表意义,并简述在Struts中MVC的表现方式。
解答: MVC是Model-View-Controller 的缩写,Model代表的是应用的业务逻辑(通过JavaBean,EJB组件实现),View 是应用的表示层(由JSP页面产生)Control ...
- 20140710文安c++面试总结
这次去文安面试并未是我想象中的那个样子,可能有如下原因: 1.招聘旺季已过,仅剩下c++这个职位 2.并未做过面试前大公司的面试技巧-做面试题 面试过程基本就是先做面试题: 1.试题分布式-逻辑题.分 ...
- 【vijos】1882 石阶上的砖(中位数+特殊的技巧)
https://vijos.org/p/1882 这种题很赞.. 以后记得这些绝对值最小的优先想中位数啊orz 首先我们将所有的高度都减掉他们的高度差,那么得到的应该是一串高低不平的数列,那么题目转化 ...
- 【BZOJ】1680: [Usaco2005 Mar]Yogurt factory(贪心)
http://www.lydsy.com/JudgeOnline/problem.php?id=1680 看不懂英文.. 题意是有n天,第i天生产的费用是c[i],要生产y[i]个产品,可以用当天的也 ...
- java Thread方法解析: sleep join wait notify notifyAll
转载自: sleep(),yield(),wait()区别详解:http://dylanxu.iteye.com/blog/1322066 join方法详解:http://www.open-open. ...
- Asp.net中使用文本框的值动态生成控件的方法
这篇文章主要介绍了Asp.net中使用文本框的值动态生成控件的方法,非常不错,具有参考借鉴价值,需要的朋友可以参考下 看到一个网友,有论坛上问及,动态的生成checkbox控件,在文本框中输入一个“花 ...
- Mysql event时间触发器,实现定时修改某些符合某一条件的某一字段
我最近做项目遇到一个问题就是数据库的的订单需要定时检查自己的订单状态,如果到了endtime字段的时间订单状态还是2,就将订单状态修改为4 在网上找到类似的解决方法. 定时的关键是要结合mysql的某 ...
- AndroidManifest.xml文件详解(activity)(三)四种工作模式
android:launchMode 这个属性定义了应该如何启动Activity的一个指令.有四种工作模式会跟Intent对象中的Activity标记(FLAG_ACTIVITY_*常量)结合在一起用 ...