字符串模式匹配算法--BF和KMP详解
1,问题描述
字符串模式匹配:串的模式匹配 ,是求第一个字符串(模式串:str2)在第二个字符串(主串:str1)中的起始位置。
注意区分:
- 子串:要求连续 (如:abc 是abcdef的子串)
- 子序列:可以不连续 (如:acd是abcdef的子序列)
2,简单字符串模式匹配(BF算法)
2.1 简单匹配思路描述
简单字符串模式匹配算法,也就是了BF(Brute Force 蛮力,暴力)算法,俗称暴力法。
基本思路:
- (1) 从主串S指定的字符开始(一般为第1个)和模式串P的第一个字符比较,若相等,则继续逐个比较后续字符,直到P中的每个字符依次和S中的一个连续字符序列相等,则称匹配成功;
- (2)如果比较过程中有某对字符串不相等,则从主串S的下一个字符起再重新和T的第一个字符比较。如果S中的字符都比完了仍然没有匹配 成功,则称匹配不成功。
简单模式匹配算法--举例:
主串str1: a b a b c a b c a c b a b
模式串str2: a b c a c (i=0
第一趟匹配:a b a b c a b c a c b a b
a b c
(j=2 (i=1
第二趟匹配: a b a b c a b c a c b a b
a
(j=0 (i=2
第三趟匹配: a b a b c a b c a c b a b
a b c a c
(j=4 (i=3
第四趟匹配:a b a b c a b c a c b a b
a
(j=0 (i=4
第五趟匹配:a b a b c a b c a c b a b
a
(j=0 (i=5 (i=10
第六趟匹配:a b a b c a b c a c b a b
a b c a c
(j=0 (j=5
2.2 时间复杂度
设串S和P的长度分别为m,n,则它在最坏情况下的时间复杂度是O(m*n)。BF算法的最坏时间复杂度虽然不好,但它易于理解和编程,在实际应用中,一般还能达到近似于O(m+n)的时间度(最坏情况不是那么容易出现的),因此,还在被大量使用。
2.3 BF代码实现
#include <iostream>
#include <vector> using namespace std; int BF_strMatch(vector<char> v1, vector<char> v2) {
//v1是主串,v2是模式串
//如果匹配成功,返回子串在主串中的起始位置;否则,返回-1;
int i = , j = ;
int n = v1.size(), m = v2.size();
while (i < n && j < m) {
if (v1[i] == v2[j]) {
++i;
++j;
}
else {
i = i - j + ;//通过观察下标变换的关系得出
j = ;
}
}
return (j == m) ? (i - m) : -;
} void main() {
vector<char> s1 = { 'a','b','a','b','c','a','b','c','a','c','b','a','b'};
vector<char> s2 = { 'a','b','c','a','c' };
cout << BF_strMatch(s1, s2) << endl;
}
3,经典KMP匹配算法
3.1 KMP算法基本思想
KMP算法可以在O(n+m)的时间数量级上完成串的模式匹配操作。其改进在于:每当一趟匹配过程中出现字符比较不等时,不需回溯 i 指针( i 只增不减),而是利用已经得到的“部分匹配”的结果将模式串向右滑动尽可能远一段距离后,继续进行比较。
3.2 KMP算法关键点
KMP算法加速原因:让前面匹配过的信息指导后面。
KMP算法理解的关键点:
- 1.求解最长公共子串(next数组),只跟模式串 str2 有关,而与主串 str1 无关(有的参考书没有讲解清楚这一点,导致容易混淆);
- 2.最长公共子串,大多数的参考书称为最长公共前缀,这里我称之为最长公共子串,是为了避免与下面两个概念混淆。这里对最长公共子串的定义:最长前缀和最长后缀的最长公共子串。
- 最长前缀:从第一个字符的起的连续一串字符,不含最后一个字符;
- 最长后缀:不含第一个字符,从中间某一个字符其到最后一个字符的连续一串字符;
例1:对于模式串“a b c a b c d”,求字符d的最长公共子串。
解:设length为字符d最长公共子串的长度,根据定义,length的可能取值为1~5:
a b c a b c d
length = 1 : a != c
length = 2 : ab != bc
length = 3 : abc == abc
length = 4 : abca != cabc
length = 5 : abcab != bcabc
显然,字符d的最长公共子串的长度为3 例2:对于模式串“a a a a a b”,求字符b的最长公共子串。
同理,length可能的取值为1~4:
length = 1 : a == a
length = 2 : aa == aa
length = 3 : aaa == aaa
length = 4 : aaaa == aaaa
显然,字符b的最长公共子串的长度为4
3.3 求解next数组
next数组的求解,实际是对每个位置找到最长的公共子串:
一般地,对于模式串str2="P0P1P2…Pm-1",长度为m,其next数组的定义:
- 当j=0时,即str2中的第一个字符,其前没有字符,人为规定 next[0] = -1;
- 当j=1时,即str2中的第二字符,其前只有一个字符,人为规定 next[1] = 0;
- 当 2<= j =< m-1:
- Max{ k | 1<= k =< j-1 且 “P0…Pk-1” == "Pj-k…Pj-1"}不空时,next[j] = Max{ k | 1<= k =< j-1 且 “P0…Pk-1” == "Pj-k…Pj-1"},
- Max{ k | 1<= k =< j-1 且 “P0…Pk-1” == "Pj-k…Pj-1"}为空时,next[j] = 0 ;
求解next数组的代码:
vector<int> getNext(vector<char> v) {
//模式串str2 与 模式串str2 (自己跟自己) 做KMP匹配
int m = v.size();//v字符串长度
vector<int> next(m, );
int i = ;
int j = ;
if (m == ) return next;
next[] = -;
if (m == ) return next;
next[] = ;
while (i < m) {
if (v[i - ] == v[j]) {
++j;
next[i] = j;
++i;
}
else if(j>){
j = next[j];
}
else {
next[i++] = ;
}
}
return next;//放对位置
}
//test
void main() {
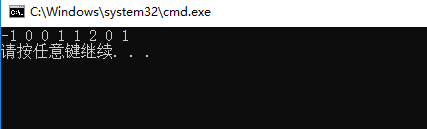
vector<char> s3 = { 'a','b','a','a','b','c','a','c' };
for (auto c : getNext(s3)) {
cout << c << " ";
}
cout << endl;
}
求解next数组的经典方法(最好理解记住):
# 获取next[]数组
def getNext(str):
next = [-1]*len(str) # next[0]=-1
if len(str)>=1:
next[1] = 0
i, j =1, 0
while(i<len(str)-1):
if j==-1 or str[i]==str[j]:
i += 1
j += 1
next[i] = j
else:
next[i] = next[j]
return next
3.4 完整的KMP算法代码
#include <iostream>
#include <vector> using namespace std; int KMP_strMatch(vector<char> v1, vector<char> v2,vector<int> next) {
//v1是主串,v2是模式串
//如果匹配成功,返回子串在主串中的起始位置;否则,返回-1;
int i = , j = ;
int n = v1.size(), m = v2.size();
while (i < n && j < m) {
if (v1[i] == v2[j]) {
++i;
++j;
}
else {
if (j == ) ++i; //j回到模式串头部还不匹配,i加1
j = next[j]; //使用next数组提供指导
}
}
return (j == m) ? (i - m) : -;
} vector<int> getNext(vector<char> v) {
//模式串str2 与 模式串str2 (自己跟自己) 做KMP匹配
int m = v.size();//v字符串长度
vector<int> next(m, );
int i = ;
int j = ; if (m == ) return next;
next[] = -;
if (m == ) return next;
next[] = ; while (i < m) {
if (v[i - ] == v[j]) {
++j;
next[i] = j;
++i;
}
else if(j>){
j = next[j];
}
else {
next[i++] = ;
} }
return next;//放对位置
} void main() {
vector<char> s1 = { 'a','b','a','b','c','a','b','c','a','c','b','a','b'};
vector<char> s2 = { 'a','b','c','a','c' }; for (auto c : getNext(s2)) {
cout << c << " ";
}
cout << endl;
cout << KMP_strMatch(s1, s2,getNext(s2)) << endl;
}
4,KMP算法进深理解
4.1 BF和KMP执行流程对比
- 当str1[i] == str2[j]时,操作一样,++i,++j;
- 当str1[i] != str2[j],即不匹配时:
- BF:i = i - j + 2, j = 0;
- KMP:i 不动(不回溯),j = next[j];
4.2 next数组要求最大公共子串的原因
str1:a b k a b a b k a b x
str2:a b k a b a b k a b y //i=10,j=10 不匹配,j=next[10]=5(不是j=0,减少了5次比较),继续比较
a b k a b a b k a b F //i=10,j=5 不匹配,j=next[5]=2(不是j=0,减少了2次比较),继续比较
a b k a b a b k a b F //i=10,j=2 不匹配,j=next[2]=0(才是j=0,较少了0次比较),继续比较
a b k a b a b k a b F //i=10,j=0 不匹配,++i(此时i才加1),j=0
分析:
(1)加速的原因:减少了不必要的比较次数。
(2)为什么模式串可以向右滑动尽可能远一段距离后,再继续比较: 正如上面的例子:前面都是相等的,到了x与y匹配时才不相等——
(W--------------Q)
[i|-----k---|j |x] //红色部分是滑过的距离,即不必要的比较次数,这里指的i……j之间的位置不可能匹配出str2
(-a-b-k-a-b)(-a-b-k-a-b) (W--------------Q)
(-a-b-k-a-b)(-a-b-k-a-b)
[0| |j |y] 假设从k字符起可以配出str2,那么必然会存在更长的子串(W-------Q)比y位置的最长子串(a-b-k-a-b)更长,如果next数组求解正确,这是不可能。出现矛盾,假设不成立。
因为next数组求的就是每一个字符的最长公共子串。
参考资料:
1.《数据结构考研复习指导》--王道单科书
2.https://www.cnblogs.com/zzqcn/p/3508442.html#_labelTop 字符串模式匹配算法1 - BF和KMP算法
3. https://www.nowcoder.com/courses/semester/senior 《牛客高级项目课——(牛客网)》--大牛·左程云
字符串模式匹配算法--BF和KMP详解的更多相关文章
- Aho-Corasick 多模式匹配算法、AC自动机详解
Aho-Corasick算法是多模式匹配中的经典算法,目前在实际应用中较多. Aho-Corasick算法对应的数据结构是Aho-Corasick自动机,简称AC自动机. 搞编程的一般都应该知道自动机 ...
- [转] 字符串模式匹配算法——BM、Horspool、Sunday、KMP、KR、AC算法一网打尽
字符串模式匹配算法——BM.Horspool.Sunday.KMP.KR.AC算法一网打尽 转载自:http://dsqiu.iteye.com/blog/1700312 本文内容框架: §1 Boy ...
- 字符串模式匹配算法——BM、Horspool、Sunday、KMP、KR、AC算法一网打尽
字符串模式匹配算法——BM.Horspool.Sunday.KMP.KR.AC算法一网打尽 本文内容框架: §1 Boyer-Moore算法 §2 Horspool算法 §3 Sunday算法 §4 ...
- 字符串模式匹配算法——BM、Horspool、Sunday、KMP、KR、AC算法
ref : https://dsqiu.iteye.com/blog/1700312 本文内容框架: §1 Boyer-Moore算法 §2 Horspool算法 §3 Sunday算法 §4 KMP ...
- Java经典设计模式之十一种行为型模式(附实例和详解)
Java经典设计模式共有21中,分为三大类:创建型模式(5种).结构型模式(7种)和行为型模式(11种). 本文主要讲行为型模式,创建型模式和结构型模式可以看博主的另外两篇文章:Java经典设计模式之 ...
- Java经典设计模式之七大结构型模式(附实例和详解)
博主在大三的时候有上过设计模式这一门课,但是当时很多都基本没有听懂,重点是也没有细听,因为觉得没什么卵用,硬是要搞那么复杂干嘛.因此设计模式建议工作半年以上的猿友阅读起来才会理解的比较深刻.当然,你没 ...
- Java设计模式之七大结构型模式(附实例和详解)
博主在大三的时候有上过设计模式这一门课,但是当时很多都基本没有听懂,重点是也没有细听,因为觉得没什么卵用,硬是要搞那么复杂干嘛.因此设计模式建议工作半年以上的猿友阅读起来才会理解的比较深刻.当然,你没 ...
- Java设计模式之十一种行为型模式(附实例和详解)
Java经典设计模式共有21中,分为三大类:创建型模式(5种).结构型模式(7种)和行为型模式(11种). 本文主要讲行为型模式,创建型模式和结构型模式可以看博主的另外两篇文章:J设计模式之五大创建型 ...
- (转)Java经典设计模式(3):十一种行为型模式(附实例和详解)
原文出处: 小宝鸽 Java经典设计模式共有21中,分为三大类:创建型模式(5种).结构型模式(7种)和行为型模式(11种). 本文主要讲行为型模式,创建型模式和结构型模式可以看博主的另外两篇文章:J ...
随机推荐
- BOM / URL编码解码 / 浏览器存储
BOM 浏览器对象模型 BOM(Browser Object Model) 是指浏览器对象模型,是用于描述这种对象与对象之间层次关系的模型,浏览器对象模型提供了独立于内容的.可以与浏览器窗口进行互动的 ...
- 基于AdaBoost算法——世纪晟结合Haar-like特征训练人脸检测识别
AdaBoost 算法是一种快速人脸检测算法,它将根据弱学习的反馈,适应性地调整假设的错误率,使在效率不降低的情况下,检测正确率得到了很大的提高. 系统在技术上的三个贡献: 1.用简单的Haa ...
- 4. hadoop启动脚本分析
4. hadoop启动脚本分析 1. hadoop的端口 ``` 50070 //namenode http port 50075 //datanode http port 50090 //2name ...
- 十六:The YARN Service Registry
yarn 服务注册功能是让长期运行的程序注册为服务一直运行. yarn中运行的程序分为两类,一类是短程序,一类一直运行的长程序.第二种也称为服务.yarn服务注册就是让应用程序能把自己注册为服务,如h ...
- Android中使用ViewPager制作广告栏效果 - 解决ViewPager占满全屏页面适配问题
. 参考界面 : 携程app首页的广告栏, 使用ViewPager实现 自制页面效果图 : 源码下载地址: http://download.csdn.net/detail/han1202 ...
- Linux 路由 学习笔记 之一 相关的数据结构
http://blog.csdn.net/lickylin/article/details/38326719 从现在开始学习路由相关的代码,在分析代码之前, 我们还是先分析数据结构,把数据结构之间的关 ...
- TCP系列13—重传—3、协议中RTO计算和RTO定时器维护
从上一篇示例中我们可以看到在TCP中有一个重要的过程就是决定何时进行超时重传,也就是RTO的计算更新.由于网络状况可能会受到路由变化.网络负载等因素的影响,因此RTO也必须跟随网络状况动态更新.如果T ...
- ubuntu软件管理apt与dpkg
目前ubuntu系统主要有dpkg和apt两种软件管理方式两种区别如下 1.dpkg是用来安装.deb文件,但不会解决模块的依赖关系,且不会关心ubuntu的软件仓库内的软件,可以用于安装本地的deb ...
- eclipse 创建并运行maven web项目
这两天想在eclipse上运行maven web项目,折腾了许久,总算success啦. 1,利用eclipse创建dynamic web project(eclipse需要安装m2eclipse). ...
- 原生js操作Dom节点:CRUD
知识点,依然会遗忘.我在思考到底是什么原因.想到研究生考试准备的那段岁月,想到知识体系的建立,知识体系分为正向知识体系和逆向知识体系:正向知识体系可以理解为教科书目录,逆向知识体系可以理解考试真题. ...