第四篇:MapReduce计算模型
前言
本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路。
模型架构
在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角色:一个是JobTracker,一个是TaskTracker,前者用于管理和调度工作,后者用于执行工作。
一般来说,一个Hadoop集群由一个JobTracker和N个TaskTracker构成。
执行流程
每次计算任务都可以分为两个阶段,Map阶段和Reduce阶段。
其中,Map阶段接收一组键值对模式<key, Value>的输入并产生同样是键值对模式<key, Value>的中间输出;
Reduce阶段负责接收Map产生的中间输出<key, Value>,然后对这个结果进行处理并输出结果。
这里举个很简单的例子,有一个程序用来统计文本中各个单词出现的个数,那么每个Map任务可以负责提取出文本中的所有单词并产生n个<word, 1>这样的输出;
而Reduce任务可以负责对这些中间输出做出处理,转换成<word, n> 这样的输出。
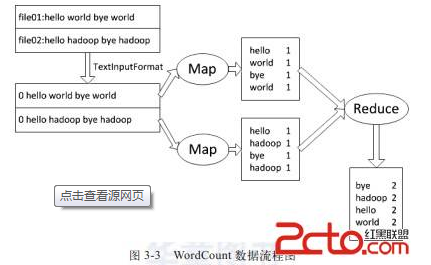
多说一句,Map产生的中间输出是直接放在本地磁盘,job完成后就会删除了。而Reduce产生的最终结果才会存放在Hdfs上。
编码框架说明
编码涉及到一些细节,建议结合具体代码进行分析,这里只给出一个框架性的说明。推荐阅读经典的wordcount程序。
1. 导入Hadoop开发需要用到的一些包
2. 定义一个需要用到分布式计算的类
3. 在此类中添加Map类,并使该类继承Mapper抽象类,然后实现该抽象类中的map方法。
4. 在此类中添加Reduce类,并使该类继承Reducer抽象类,然后实现该抽象类中的reduce方法。
5. 在类中定义一个成员函数并做如下操作:
a. 定义一个Job对象负责job调度
b. 往a中定义的job对象中注入2中定义的分布式类 (setJarByClass)
c. 定义分布式任务的名字 (setJobName)
d. 往a中定义的job对象中注入输出的key和value的类型 (setOutPutKeyClass,setOutPutKeyClass)
e. 往a中定义的job对象中注入3和4中定义的Map,Reduce类
f. 往a中定义的job对象中注入数据切分格式类 (setInputFormat,setOutputFormat)
g. 往a中定义的job对象中注入输出的路径地址 (setInputPaths,setOutputPath)
h. 启动计算任务 (waitForCompletion)
i. 返回布尔类型的执行结果
6. 在主函数中调用上述方法 (命令行方式)
运行方法
1. 执行以下格式的命令以编译分布式计算类
javac -classpath "hadoop目录下的core.jar" -d "结果输出目录" "分布式类文件名"
2. 执行以下格式的命令将该类打包成jar
jar -cvf "结果文件名(后缀.jar)" -C "目标目录" "结果输出目录"
3. 执行以下格式的命令将输入文件存入HDFS文件系统 (该命令将在HDFS上创建一个名为input的目录并将用户目录下input目录内前缀为file的文件导入进去):
dfs -mkdir input
dfs -put ~/input/file0* input
4. 执行以下格式的命令启动hadoop程序 (下面的参数一和二一般分别指输入和输出目录)
jar "分布式类jar包" "分布式类名" 参数一,参数二......
MapReduce的数据流和控制流
下面来讨论一下Hadoop程序的数据流和控制流的关系,首先请看下图:
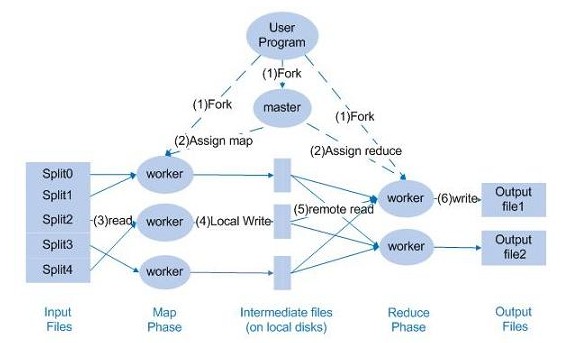
首先,由Master,也即JobTracker负责分派任务到下面的各个worker,也即TaskTracker。
某个worker在执行的时候,会返回进度报告,master负责记录进度的进行状况。
若某个worker失败,那么master会分派这个执行失败的任务给新的worker。
程序优化技巧
MapReduce程序的优化主要集中在两个方面:一个是运算性能方面的优化;另一个是IO操作方面的优化。
具体体现在以下的几个环节之上:
1. 任务调度
a. 尽量选择空闲节点进行计算
b. 尽量把任务分配给InputSplit所在机器
2. 数据预处理与InputSplit的大小
尽量处理少量的大数据;而不是大量的小数据。因此可以在处理前对数据进行一次预处理,将数据进行合并。
如果自己懒得合并,可以参考使用CombineFileInputFormat函数。具体用法请查阅相关函数手册。
3. Map和Reduce任务的数量
Map任务槽中任务的数量需要参考Map的运行时间,而Reduce任务的数量则只需要参考Map槽中的任务数,一般是0.95或1.75倍。
4. 使用Combine函数
该函数用于合并本地的数据,可以大大减少网络消耗。具体请参考函数手册。
5. 压缩
可以对一些中间数据进行压缩处理,达到减少网络消耗的目的。
6. 自定义comparator
可以自定义数据类型实现更复杂的目的。
小结
本文大致讲解了Hadoop的编程模型MapReduce,并大致介绍了如何在这个框架下进行简单的程序开发。
更复杂的框架剖析以及Hadoop高级程序开发,将在以后的文章中进行细致的探讨。
第四篇:MapReduce计算模型的更多相关文章
- MapReduce计算模型
MapReduce计算模型 MapReduce两个重要角色:JobTracker和TaskTracker. MapReduce Job 每个任务初始化一个Job,没个Job划分为两个阶段:Map和 ...
- MapReduce计算模型二
之前写过关于Hadoop方面的MapReduce框架的文章MapReduce框架Hadoop应用(一) 介绍了MapReduce的模型和Hadoop下的MapReduce框架,此文章将进一步介绍map ...
- 【CDN+】 Spark入门---Handoop 中的MapReduce计算模型
前言 项目中运用了Spark进行Kafka集群下面的数据消费,本文作为一个Spark入门文章/笔记,介绍下Spark基本概念以及MapReduce模型 Spark的基本概念: 官网: http://s ...
- MapReduce计算模型的优化
MapReduce 计算模型的优化涉及了方方面面的内容,但是主要集中在两个方面:一是计算性能方面的优化:二是I/O操作方面的优化.这其中,又包含六个方面的内容. 1.任务调度 任务调度是Hadoop中 ...
- MapReduce 计算模型
前言 本文讲解Hadoop中的编程及计算模型MapReduce,并将给出在MapReduce模型下编程的基本套路. 模型架构 在Hadoop中,用于执行计算任务(MapReduce任务)的机器有两个角 ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- 转载:Spark中文指南(入门篇)-Spark编程模型(一)
原文:https://www.cnblogs.com/miqi1992/p/5621268.html 前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apac ...
- MapReduce 编程模型
一.简单介绍 1.MapReduce 应用广泛的原因之中的一个在于它的易用性.它提供了一个因高度抽象化而变得异常简单的编程模型. 2.从MapReduce 自身的命名特点能够看出,MapReduce ...
- Hadoop入门第二篇-MapReduce学习
mapreduce是一种计算模型,是google的一篇论文向全世界介绍了MapReduce.MapReduce其实可以可以用多种语言编写Map或Reduce程序,因为hadoop是java写的,所以通 ...
随机推荐
- MySQL迁移数据库(mysqldump)
一.导出导入所有数据库的数据 1.导出 mysqldump -u root -p123456 --all-databases > all.sql 2.导入 mysql -u root -p123 ...
- 【未通过】LintCode #366 斐波纳契数列
实现: public class Solution { /** * @param n: an integer * @return: an ineger f(n) */ public int fibon ...
- HDU 5067 Harry And Dig Machine(状压DP)(TSP问题)
题目地址:pid=5067">HDU 5067 经典的TSP旅行商问题模型. 状压DP. 先分别预处理出来每两个石子堆的距离.然后将题目转化成10个城市每一个城市至少经过一次的最短时间 ...
- 联想服务器X3850 X6 配置RAID5
实验环境: 1. 服务器型号 联想 System X3850 X6 2. 四块300G SAS硬盘 实验目的: 配置RAID 5 ,搭建公司重要文件共享服务器使用. 标注:本教程四块硬盘全做RA ...
- PHI 数据库简介
PHI是一个致病菌的数据库,截止到2017年8月1号为止,最新的版本是4.3,数据库中收录了实验验证过的致病菌的信息,其中有176个来自动物的致病菌,227个来自植物的致病菌,3个来自真菌的致病菌; ...
- C# 大图片压缩算法,减少图片体积
声明: 图片压缩算法,不建议对小图片进行压缩,一般文件小于1m的,真心没必要压缩, 图片很小的,例如:几百KB的图片,有可能不会减少图片体积,反而压缩后更大,也很正常, 请大家合理使用,并不是,所有图 ...
- MAC算法
MAC算法 (Message Authentication Codes) 带秘密密钥的Hash函数:消息的散列值由只有通信双方知道的秘密密钥K来控制.此时Hash值称作MAC. 原理:在md与sha系 ...
- 同一个Tomcat部署两个project之间的通信问题
同一个tomcat下的两个project是无法通信的. 同一个tomcat中的project能互相调用吗 启动一个tomcat部署多个项目,那么每个项目算是一个线程还是进程呢? Tomcat中的pro ...
- Java JVM运行时数据区,内存管理和GC垃圾回收
一 . 运行时数据区 程序计数器是线程私有的,是一块很小的内存空间,是当前线程执行到字节码行号的计数指示器.每个CPU处理器核心 在任何一个时刻,都只可能运行着唯一的一个线程,执行着一条指令.所以在多 ...
- Effective STL读书笔记
Effective STL 读书笔记 本篇文字用于总结在阅读<Effective STL>时的笔记心得,只记录书上描写的,但自己尚未熟练掌握的知识点,不记录通用.常识类的知识点. STL按 ...