chapter02 K近邻分类器对Iris数据进行分类预测
寻找与待分类的样本在特征空间中距离最近的K个已知样本作为参考,来帮助进行分类决策。
与其他模型最大的不同在于:该模型没有参数训练过程。无参模型,高计算复杂度和内存消耗。
#coding=utf8 # 从sklearn.datasets 导入 iris数据加载器。 from sklearn.datasets import load_iris # 从sklearn.model_selection中导入train_test_split用于数据分割。 from sklearn.model_selection import train_test_split # 从sklearn.preprocessing里选择导入数据标准化模块。 from sklearn.preprocessing import StandardScaler # 从sklearn.neighbors里选择导入KNeighborsClassifier,即K近邻分类器。 from sklearn.neighbors import KNeighborsClassifier # 依然使用sklearn.metrics里面的classification_report模块对预测结果做更加详细的分析。 from sklearn.metrics import classification_report iris = load_iris() # 从使用train_test_split,利用随机种子random_state采样25%的数据作为测试集。 X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.25, random_state=33) # 对训练和测试的特征数据进行标准化。 ss = StandardScaler() X_train = ss.fit_transform(X_train) X_test = ss.transform(X_test) # 使用K近邻分类器对测试数据进行类别预测,预测结果储存在变量y_predict中。 knc = KNeighborsClassifier() knc.fit(X_train, y_train) y_predict = knc.predict(X_test) # 使用模型自带的评估函数进行准确性测评。 print 'The accuracy of K-Nearest Neighbor Classifier is', knc.score(X_test, y_test) print classification_report(y_test, y_predict, target_names=iris.target_names)
结果:
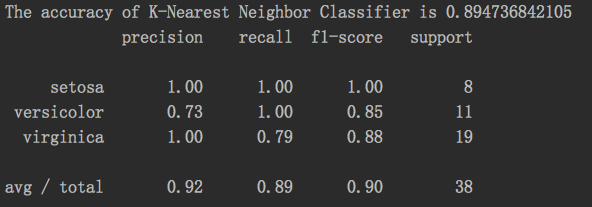
chapter02 K近邻分类器对Iris数据进行分类预测的更多相关文章
- 机器学习之路: python k近邻分类器 KNeighborsClassifier 鸢尾花分类预测
使用python语言 学习k近邻分类器的api 欢迎来到我的git查看源代码: https://github.com/linyi0604/MachineLearning from sklearn.da ...
- 机器学习 —— 基础整理(三)生成式模型的非参数方法: Parzen窗估计、k近邻估计;k近邻分类器
本文简述了以下内容: (一)生成式模型的非参数方法 (二)Parzen窗估计 (三)k近邻估计 (四)k近邻分类器(k-nearest neighbor,kNN) (一)非参数方法(Non-param ...
- 最近邻分类器,K近邻分类器,线性分类器
转自:https://blog.csdn.net/oldmao_2001/article/details/90665515 最近邻分类器: 通俗来讲,计算测试样本与所有样本的距离,将测试样本归为距离最 ...
- sklearn.neighbors.KNeighborsClassifier(k近邻分类器)
KNeighborsClassifier参数说明KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', lea ...
- Python机器学习(基础篇---监督学习(k近邻))
K近邻 假设我们有一些携带分类标记的训练样本,分布于特征空间中,对于一个待分类的测试样本点,未知其类别,按照‘近朱者赤近墨者黑’,我们需要寻找与这个待分类的样本在特征空间中距离最近的k个已标记样本作为 ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- 机器学习实战python3 K近邻(KNN)算法实现
台大机器技法跟基石都看完了,但是没有编程一直,现在打算结合周志华的<机器学习>,撸一遍机器学习实战, 原书是python2 的,但是本人感觉python3更好用一些,所以打算用python ...
- sklearn机器学习算法--K近邻
K近邻 构建模型只需要保存训练数据集即可.想要对新数据点做出预测,算法会在训练数据集中找到最近的数据点,也就是它的“最近邻”. 1.K近邻分类 #第三步导入K近邻模型并实例化KN对象 from skl ...
- 1. cs231n k近邻和线性分类器 Image Classification
第一节课大部分都是废话.第二节课的前面也都是废话. First classifier: Nearest Neighbor Classifier 在一定时间,我记住了输入的所有的图片.在再次输入一个图片 ...
随机推荐
- DataTable转化成实体对象
/// <summary> /// The data extension. /// </summary> public static class DataExtension { ...
- list_01
双向链表 不支持随机存取([?] / at(?)) A.头尾 添加/移除 A.1.list::push_back(elemValue); A.2.list::pop_back(); A.3.list: ...
- Spring AMQP 源码分析 05 - 异常处理
### 准备 ## 目标 了解 Spring AMQP Message Listener 如何处理异常 ## 前置知识 <Spring AMQP 源码分析 04 - MessageListene ...
- HDU2017新生赛 友好整数
思路: 很简单的一个状态压缩,比赛时没想出来. 最多只有2^10个状态,n^2暴力一下也就1e6. 代码: #include<bits/stdc++.h> using namespace ...
- [Android教程] Cordova开发App入门(二)使用热更新插件
前言 不知各位遇没遇到过,刚刚发布的应用,突然发现了一个隐藏极深的“碧油鸡(BUG)”,肿么办!肿么办!肿么办!如果被老板发现,一定会让程序员哥哥去“吃鸡”.但是想要修复这个“碧油鸡”,就必须要重新打 ...
- 快速搭建一个简易的KMS 服务
xu言: 之前,闹的沸沸扬扬的KMS激活工具自身都存在问题的事.让我们对以前的什么小马激活.kms激活.各种激活工具都去打了一个深深的“?”,到底哪些能用.哪些不能用.有些还注明的里面必须要关闭杀毒软 ...
- linux--多进程进行文件拷贝
学习IO的时候,我们都曾经利用文件IO函数,标准IO函数都实现了对文件的拷贝, 对某一个文件进行拷贝时,我们可以考虑一下几种方式: a.单进程拷贝: 假设某一文件需要拷贝100字节,每一个时间片可以完 ...
- Eclipse SVN修改用户名和密码
问题描述: Eclipse的SVN插件Subclipse做得很好,在svn操作方面提供了很强大丰富的功能.但到目前为止,该插件对svn用户的概念极为淡薄,不但不能方便地切换用户,而且一旦用户的 ...
- CSS3提供的transition动画
<!DOCTYPE html><html xmlns="http://www.w3.org/1999/xhtml"><head> < ...
- 线程的创建,pthread_create,pthread_self,pthread_once
typedef unsigned long int pthread_t; //come from /usr/include/bits/pthreadtypes.h int pthread_create ...