Scrapy简单入门及实例讲解-转载
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下
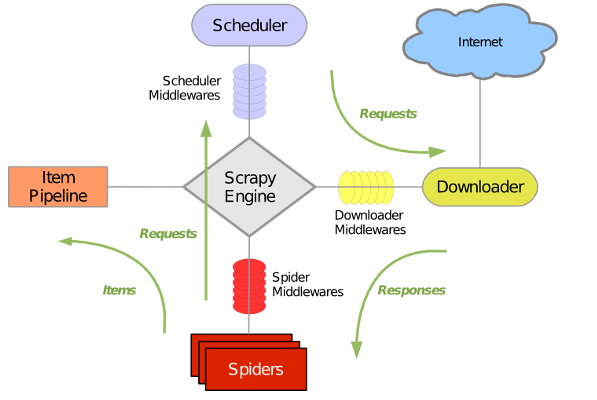
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
一、安装

1、安装wheel
pip install wheel
2、安装lxml
https://pypi.python.org/pypi/lxml/4.1.0
3、安装pyopenssl
https://pypi.python.org/pypi/pyOpenSSL/17.5.0
4、安装Twisted
https://www.lfd.uci.edu/~gohlke/pythonlibs/
5、安装pywin32
https://sourceforge.net/projects/pywin32/files/
6、安装scrapy
pip install scrapy
注:windows平台需要依赖pywin32,请根据自己系统32/64位选择下载安装,https://sourceforge.net/projects/pywin32/
二、爬虫举例
入门篇:美剧天堂前100最新(http://www.meijutt.com/new100.html)
1、创建工程
|
1
|
scrapy startproject movie |
2、创建爬虫程序
|
1
2
|
cd moviescrapy genspider meiju meijutt.com |
3、自动创建目录及文件
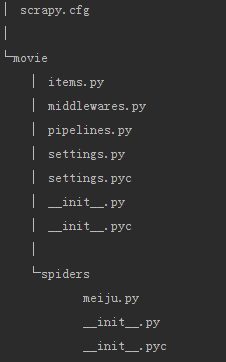
4、文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
5、设置数据存储模板
items.py
|
1
2
3
4
5
6
7
8
|
import scrapyclass MovieItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() name = scrapy.Field() |
6、编写爬虫
meiju.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# -*- coding: utf-8 -*-import scrapyfrom movie.items import MovieItemclass MeijuSpider(scrapy.Spider): name = "meiju" allowed_domains = ["meijutt.com"] start_urls = ['http://www.meijutt.com/new100.html'] def parse(self, response): movies = response.xpath('//ul[@class="top-list fn-clear"]/li') for each_movie in movies: item = MovieItem() item['name'] = each_movie.xpath('./h5/a/@title').extract()[0] yield item |
7、设置配置文件
settings.py增加如下内容
|
1
|
ITEM_PIPELINES = {'movie.pipelines.MoviePipeline':100} |
8、编写数据处理脚本
pipelines.py
|
1
2
3
4
|
class MoviePipeline(object): def process_item(self, item, spider): with open("my_meiju.txt",'a') as fp: fp.write(item['name'].encode("utf8") + '\n') |
9、执行爬虫
|
1
2
|
cd moviescrapy crawl meiju --nolog |
10、结果

进阶篇:爬取校花网(http://www.xiaohuar.com/list-1-1.html)
1、创建一个工程
|
1
|
scrapy startproject pic |
2、创建爬虫程序
|
1
2
|
cd picscrapy genspider xh xiaohuar.com |
3、自动创建目录及文件

4、文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
5、设置数据存储模板
|
1
2
3
4
5
6
7
8
|
import scrapyclass PicItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() addr = scrapy.Field() name = scrapy.Field() |
6、编写爬虫
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# -*- coding: utf-8 -*-import scrapyimport os# 导入item中结构化数据模板from pic.items import PicItemclass XhSpider(scrapy.Spider): # 爬虫名称,唯一 name = "xh" # 允许访问的域 allowed_domains = ["xiaohuar.com"] # 初始URL start_urls = ['http://www.xiaohuar.com/list-1-1.html'] def parse(self, response): # 获取所有图片的a标签 allPics = response.xpath('//div[@class="img"]/a') for pic in allPics: # 分别处理每个图片,取出名称及地址 item = PicItem() name = pic.xpath('./img/@alt').extract()[0] addr = pic.xpath('./img/@src').extract()[0] addr = 'http://www.xiaohuar.com'+addr item['name'] = name item['addr'] = addr # 返回爬取到的数据 yield item |
7、设置配置文件
|
1
2
|
# 设置处理返回数据的类及执行优先级ITEM_PIPELINES = {'pic.pipelines.PicPipeline':100} |
8、编写数据处理脚本
|
1
2
3
4
5
6
7
8
9
10
11
|
import urllib2import osclass PicPipeline(object): def process_item(self, item, spider): headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'} req = urllib2.Request(url=item['addr'],headers=headers) res = urllib2.urlopen(req) file_name = os.path.join(r'D:\my\down_pic',item['name']+'.jpg') with open(file_name,'wb') as fp: fp.write(res.read()) |
9、执行爬虫
|
1
2
|
cd picscrapy crawl xh --nolog |
结果:
终极篇:我想要所有校花图
注明:基于进阶篇再修改为终极篇
# xh.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
# -*- coding: utf-8 -*-import scrapyimport osfrom scrapy.http import Request# 导入item中结构化数据模板from pic.items import PicItemclass XhSpider(scrapy.Spider): # 爬虫名称,唯一 name = "xh" # 允许访问的域 allowed_domains = ["xiaohuar.com"] # 初始URL start_urls = ['http://www.xiaohuar.com/hua/'] # 设置一个空集合 url_set = set() def parse(self, response): # 如果图片地址以http://www.xiaohuar.com/list-开头,我才取其名字及地址信息 if response.url.startswith("http://www.xiaohuar.com/list-"): allPics = response.xpath('//div[@class="img"]/a') for pic in allPics: # 分别处理每个图片,取出名称及地址 item = PicItem() name = pic.xpath('./img/@alt').extract()[0] addr = pic.xpath('./img/@src').extract()[0] addr = 'http://www.xiaohuar.com'+addr item['name'] = name item['addr'] = addr # 返回爬取到的信息 yield item # 获取所有的地址链接 urls = response.xpath("//a/@href").extract() for url in urls: # 如果地址以http://www.xiaohuar.com/list-开头且不在集合中,则获取其信息 if url.startswith("http://www.xiaohuar.com/list-"): if url in XhSpider.url_set: pass else: XhSpider.url_set.add(url) # 回调函数默认为parse,也可以通过from scrapy.http import Request来指定回调函数 # from scrapy.http import Request # Request(url,callback=self.parse) yield self.make_requests_from_url(url) else: pass |
转载:https://www.cnblogs.com/kongzhagen/p/6549053.html
Scrapy简单入门及实例讲解-转载的更多相关文章
- [转]Scrapy简单入门及实例讲解
Scrapy简单入门及实例讲解 中文文档: http://scrapy-chs.readthedocs.io/zh_CN/0.24/ Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用 ...
- Scrapy简单入门及实例讲解
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- 10,Scrapy简单入门及实例讲解
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
- S3C2440上RTC时钟驱动开发实例讲解(转载)
嵌入式Linux之我行,主要讲述和总结了本人在学习嵌入式linux中的每个步骤.一为总结经验,二希望能给想入门嵌入式Linux的朋友提供方便.如有错误之处,谢请指正. 共享资源,欢迎转载:http:/ ...
- TCP入门与实例讲解
内容简介 TCP是TCP/IP协议栈的核心组成之一,对开发者来说,学习.掌握TCP非常重要. 本文主要内容包括:什么是TCP,为什么要学习TCP,TCP协议格式,通过实例讲解TCP的生命周期(建立连接 ...
- 【智能算法】粒子群算法(Particle Swarm Optimization)超详细解析+入门代码实例讲解
喜欢的话可以扫码关注我们的公众号哦,更多精彩尽在微信公众号[程序猿声] 01 算法起源 粒子群优化算法(PSO)是一种进化计算技术(evolutionary computation),1995 年由E ...
- Nodejs进阶:核心模块net入门与实例讲解
模块概览 net模块是同样是nodejs的核心模块.在http模块概览里提到,http.Server继承了net.Server,此外,http客户端与http服务端的通信均依赖于socket(net. ...
- PHP中“简单工厂模式”实例讲解
原创文章,转载请注明出处:http://www.cnblogs.com/hongfei/archive/2012/07/07/2580776.html 简单工厂模式:①抽象基类:类中定义抽象一些方法, ...
- scrapy简单入门及选择器(xpath\css)
简介 scrapy被认为是比较简单的爬虫框架,资料比较齐全,网上也有很多教程.官网上介绍了它的四种安装方法,PyPI.Conda.APT.Source,我们只介绍最简单的安装方法. 安装 Window ...
随机推荐
- 常见企业IT支撑【6、跳板机Jumpserver】
Jumpserver是国内一款开源的轻便的跳板机系统,他们的官网:http://www.jumpserver.org/ 使用这款软件意在提高公司内部登录生产环境服务器的便捷性,权限分配细化,以及后台管 ...
- CentOS Linux解决Device eth0 does not seem to be present 但是没有发现eth1
http://www.linuxidc.com/Linux/2012-12/76248.htm 此标题已经是有人写过的了.但是为什么拿来重写? 我复制完,没有发现有eth1这个网卡 为什么呢?需要选中 ...
- ALGO-4_蓝桥杯_算法训练_结点选择
问题描述 有一棵 n 个节点的树,树上每个节点都有一个正整数权值.如果一个点被选择了,那么在树上和它相邻的点都不能被选择.求选出的点的权值和最大是多少? 输入格式 第一行包含一个整数 n . 接下来的 ...
- 解决Qt Creator下 undefined reference to 'qmain(int,char**)'的问题
Qt Creator运行以下程序: #include <QTextStream> #include <QList> int main(void) { QTextStream o ...
- bzoj1819 电子词典
Description 人们在英文字典中查找某个单词的时候可能不知道该单词的完整拼法,而只知道该单词的一个错误的近似拼法,这时人们可能陷入困境,为了查找一个单词而浪费大量的时间.带有模糊查询功能的电子 ...
- 有意思的bug
1. Xss攻击型的bug Xss攻击即跨站脚步攻击,通过插入恶意脚本 ,实现对用户浏览器的控制. Bug现象:新增物品时,物品名称输入一段JavaScript代码,在提交时此代码被执行.如:输入&l ...
- 制作jQuery文字提示插件
(functions($){ $.fn.colorTip=function(settings){ var defaultSettings={ color:'yellow', timeout:500 } ...
- HTC Vive前置摄像头API(未测试)
/*WebCamTexture:网络摄像头材质 WebCamTexture.Play() 播放: WebCamTexture.Pause() 暂停: WebCamTexture.Stop() 停止:* ...
- Linux 下的两种分层存储方案
背景介绍 随着固态存储技术 (SSD),SAS 技术的不断进步和普及,存储介质的种类更加多样,采用不同存储介质和接口的存储设备的性能出现了很大差异.SSD 相较于传统的机械硬盘,由于没有磁盘的机械转动 ...
- QT按键(Qbutton)改变颜色
第一种是按键上面的字颜色的改变: ui->motor1->setStyleSheet("color: red"); 效果: 第二种是背景改变: ui->mot ...